java大數據最全課程學習筆記(2)–Hadoop完全分散式運行模式
目前CSDN,部落格園,簡書同步發表中,更多精彩歡迎訪問我的gitee pages
Hadoop完全分散式運行模式
步驟分析:
-
準備3台客戶機(關閉防火牆、靜態ip、主機名稱)
vim /etc/sysconfig/network三台機器各自的配置分別為HOSTNAME=hadoop101;HOSTNAME=hadoop102;HOSTNAME=hadoop103
vim /etc/hosts三台機器都加入下面的映射關係
192.168.1.101 hadoop101 192.168.1.102 hadoop102 192.168.1.103 hadoop103 -
安裝JDK
-
配置環境變數
-
安裝Hadoop
-
配置環境變數
-
配置集群
-
單點啟動
-
配置ssh
-
群起並測試集群
由於在上一章節已經配置好環境並測試了hadoop偽分散式開發模式,所以在此不再贅述.
編寫集群分髮腳本xsync
-
scp(secure copy) 安全拷貝(全量複製)
-
scp定義
scp可以實現伺服器與伺服器之間的數據拷貝.(from server1 to server2)
-
基本語法
scp -r 源文件用戶名A@主機名1:path1 目標文件用戶名B@主機名2:path2
-
其他
- 如果從本機執行讀取或寫入,用戶名B@主機名2:可以省略!
- 在主機1上,使用A用戶讀取path1的文件,再使用用戶B登錄到主機2,在主機2的path2路徑執行寫入!
- 要求:
- 用戶名A@主機名1 對path1有讀許可權
- 用戶名B@主機名2 對path2有寫許可權
-
-
rsync 遠程同步工具
rsync主要用於備份和鏡像。具有速度快、避免複製相同內容和支援符號鏈接的優點。
rsync和scp區別:用rsync做文件的複製要比scp的速度快,rsync只對差異文件做更新。scp是把所有文件都複製過去。rsync -rvlt path1 目標文件用戶名B@主機名2:path2
選項 功能 -r 遞歸 -v 顯示複製過程 -l 拷貝符號連接 -t 基於文件的修改時間進行對比,只同步修改時間不同的文件 只能將本機的文件同步到其他機器!
注意:path1是個目錄,目錄以/結尾,只會同步目錄中的內容,不會同步目錄本身!目錄不以/結尾,同步目錄中的內容,也會同步目錄本身!
-
編寫xsync集群分髮腳本
-
需求:循環複製文件到所有節點的相同目錄下,即將當前機器的文件,同步到集群所有機器的相同路徑下!例如:hadoop102:/A/a , 執行腳本後,將此文件同步到集群中所有機器的 /A/a
-
需求分析:
- 用戶在使用xsync時,只需要傳入要同步的文件即可
xysnc a
不管a是一個相對路徑還是絕對路徑,都需要將a轉換為絕對路徑! - 文件的絕對路徑:
父路徑: dirpath=$(cddirname /home/atguigu/hi; pwd -P)
文件名: filename=basename hi
pwd -P為了避免軟鏈接無法獲取到真實的父路徑 - 核心命令:
for(())
do
rsync -rvlt path1
done - 說明:在/home/atguigu/bin這個目錄下存放的腳本,atguigu用戶可以在系統任何地方直接執行。
- 用戶在使用xsync時,只需要傳入要同步的文件即可
-
腳本實現:
[atguigu@hadoop102 ~]$ mkdir bin [atguigu@hadoop102 ~]$ cd bin/ [atguigu@hadoop102 bin]$ touch xsync [atguigu@hadoop102 bin]$ vi xsync-
在該文件中編寫如下程式碼
#!/bin/bash #校驗參數是否合法 if(($#==0)) then echo 請輸入要分發的文件! exit; fi #拼接要分發文件的絕對路徑 dirpath=$(cd `dirname $1`; pwd -P) filename=`basename $1` echo 要分發的文件的路徑是:$dirpath/$filename #循環執行rsync分發文件到集群的每台機器 for((i=101;i<=103;i++)) do echo --------------hadoop$i------------------- rsync -rvlt $dirpath/$filename atguigu@hadoop$i:$dirpath done -
修改腳本 xsync 具有執行許可權
[atguigu@hadoop102 bin]$ chmod 777 xsync或者
[atguigu@hadoop102 bin]$ chmod u+x xsync -
調用腳本形式:xsync 文件名稱
-
-
編寫批量執行同一命令的腳本
#!/bin/bash #在集群的所有機器上批量執行同一條命令 if(($#==0)) then echo 請輸入您要操作的命令! exit; fi echo 要執行的命令是$* #循環執行此命令 for((i=101;i<=103;i++)) do echo --------------hadoop$i------------------- ssh hadoop$i $* done
-
集群配置
集群部署規劃
| hadoop101 | hadoop102 | hadoop103 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
配置集群
-
核心配置文件
- 配置core-site.xml
[atguigu@hadoop102 hadoop]$ vi core-site.xml- 在該文件中編寫如下配置
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop101:9000</value> </property> <!-- 指定Hadoop運行時產生文件的存儲目錄 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property> -
HDFS配置文件
-
配置hadoop-env.sh
[atguigu@hadoop102 hadoop]$ vi hadoop-env.shexport JAVA_HOME=/opt/module/jdk1.8.0_144
-
配置hdfs-site.xml
[atguigu@hadoop102 hadoop]$ vi hdfs-site.xml -
在該文件中編寫如下配置
<property> <name>dfs.replication</name> <value>3</value> </property> <!-- 指定Hadoop輔助名稱節點主機配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop103:50090</value> </property>
-
-
YARN配置文件
-
配置yarn-env.sh
[atguigu@hadoop102 hadoop]$ vi yarn-env.shexport JAVA_HOME=/opt/module/jdk1.8.0_144
-
配置yarn-site.xml
[atguigu@hadoop102 hadoop]$ vi yarn-site.xml -
在該文件中增加如下配置
<!-- reducer獲取數據的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop101</value> </property>
-
-
MapReduce配置文件
-
配置mapred-env.sh
[atguigu@hadoop102 hadoop]$ vi mapred-env.shexport JAVA_HOME=/opt/module/jdk1.8.0_144
-
配置mapred-site.xml
[atguigu@hadoop102 hadoop]$ vi mapred-site.xml -
在該文件中增加如下配置
<!-- 指定mr運行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
-
-
在集群上分發配置好的Hadoop配置文件
[atguigu@hadoop102 hadoop]$ xsync /opt/module/hadoop-2.7.2/ -
查看文件分發情況
xcall cat /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
集群單點啟動
-
如果集群是第一次啟動,需要格式化NameNode
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop namenode -format -
在hadoop102上啟動NameNode
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop-daemon.sh start namenode [atguigu@hadoop102 hadoop-2.7.2]$ jps 8118 NameNode -
啟動hadoop101,hadoop102,hadoop103上的DataNode
[atguigu@hadoop102 hadoop-2.7.2]$ xcall hadoop-daemon.sh start datanode [atguigu@hadoop101 hadoop]$ xcall jps 要執行的命令是jps --------------hadoop101------------------- 8118 NameNode 13768 Jps 8238 DataNode --------------hadoop102------------------- 8072 DataNode 12959 Jps --------------hadoop103------------------- 7347 DataNode 13950 Jps
SSH無密登陸配置
-
免密登錄原理
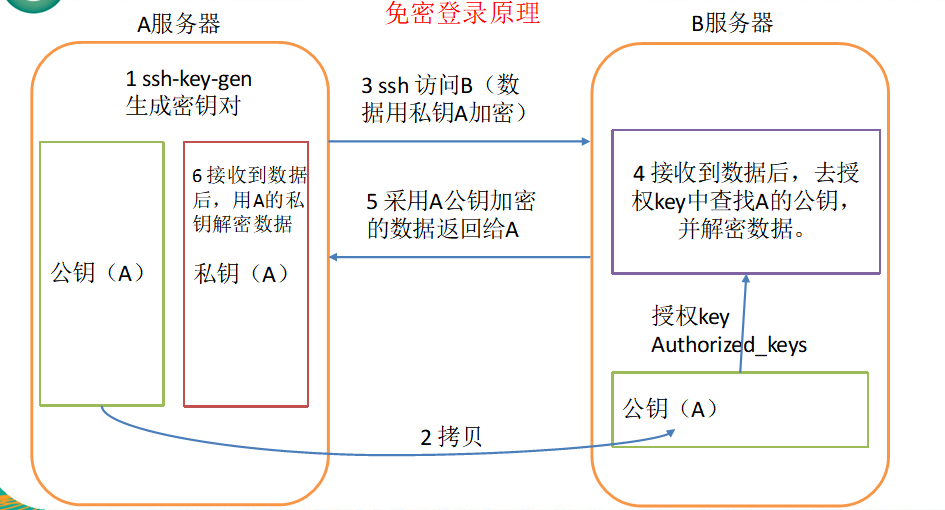
-
生成公鑰和私鑰
[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa然後敲(三個回車),就會生成兩個文件id_rsa(私鑰)、id_rsa.pub(公鑰)
-
將公鑰拷貝到要免密登錄的目標機器上的/home/atguigu/.ssh目錄下的authorized_keys中
以下命令可以直接完成上述操作
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop101 [atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102 [atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103 -
.ssh文件夾下(~/.ssh)的文件功能解釋
known_hosts 記錄ssh訪問過電腦的公鑰(public key) id_rsa 生成的私鑰 id_rsa.pub 生成的公鑰 authorized_keys 存放授權過得無密登錄伺服器公鑰

登錄狀態的環境變數
-
Login Shell
是指登錄時,需要提供用戶名密碼的shell,如:su – user1 , 圖形登錄, ctrl+alt+F2-6進入的登錄介面。
- 這種Login shell 執行腳本的順序:
- /etc/profile 【全局profile文件;它定義了LoginUser的 PATH, USER, LOGNAME(登錄使用者帳號)】
- /etc/profile.d/目錄下的腳本
- ~/.bash_profile 【搜索命令的路徑 ——————- 登錄級別 環境變數配置文件 】
- ~/.bashrc 【存儲用戶設定的別名和函數 ———- shell級別 環境變數配置文件】
- /etc/bashrc 【全局bashrc文件; 它主要定義一些 Function 和 Alias;更改/etc/bashrc會影響到所有用戶,由root用戶管理。】
- 這種Login shell 執行腳本的順序:
-
Non-Login shell
- 登錄終端後,使用ssh 登錄 其他機器!
- 非登錄shell指的是,不需要輸入用戶名密碼的shell,如圖形下 右鍵terminal,或ctrl+shift+T打開的shell
- 這種Non-Login shell 執行登錄腳本的順序:
- ~/.bashrc
- /etc/bashrc
- /etc/profile.d/目錄下的腳本
-
ssh 目標機器
登錄之後,執行某個命令!
屬於Login-shell,會自動讀取 /etc/profile文件中定義的所有的變數! -
ssh 目標機器 命令
屬於Non-Login-shell
不會讀取/etc/profile
如果在使用命令時,我們需要使用/etc/profile定義的一些變數,需要在目標機器的對應的用戶的家目錄/.bashrc中添加以下程式碼source /etc/profile如果不添加以上程式碼,在執行start-all.sh | stop-all.sh一定會報錯!
群起集群
群起腳本的原理是獲取集群中所有的節點的主機名
默認讀取當前機器 HADOOP_HOME/etc/hadoop/slaves,獲取集群中所有的節點的主機名
循環執行 ssh 主機名 hadoop-daemon.sh start xxx
保證當前機器到其他節點,已經配置了ssh免密登錄
保證集群中所有當前用戶的家目錄/.bashrc中,已經配置source /etc/profile
-
配置slaves
/opt/module/hadoop-2.7.2/etc/hadoop/slaves [atguigu@hadoop102 hadoop]$ vi slaves在文件中增加如下內容:
hadoop101 hadoop102 hadoop103注意:該文件中添加的內容結尾不允許有空格,文件中不允許有空行。
-
啟動集群
-
如果集群是第一次啟動,需要格式化NameNode
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs namenode -format -
啟動HDFS
[atguigu@hadoop101 hadoop]$ start-dfs.sh [atguigu@hadoop101 hadoop]$ xcall jps 要執行的命令是jps --------------hadoop101------------------- 8118 NameNode 13768 Jps 8238 DataNode --------------hadoop102------------------- 8072 DataNode 12959 Jps --------------hadoop103------------------- 7473 SecondaryNameNode 7347 DataNode 13950 Jps -
啟動YARN
[atguigu@hadoop103 hadoop-2.7.2]$ start-yarn.sh -
web端查看SecondaryNameNode
- 瀏覽器中輸入://hadoop103:50090/status.html
- 查看SecondaryNameNode資訊

-
-
集群基本測試
-
hadoop fs -mkdir /wcinput
-
hadoop fs -put hi /wcinput/
-
hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /wcinput/ /wcoutput
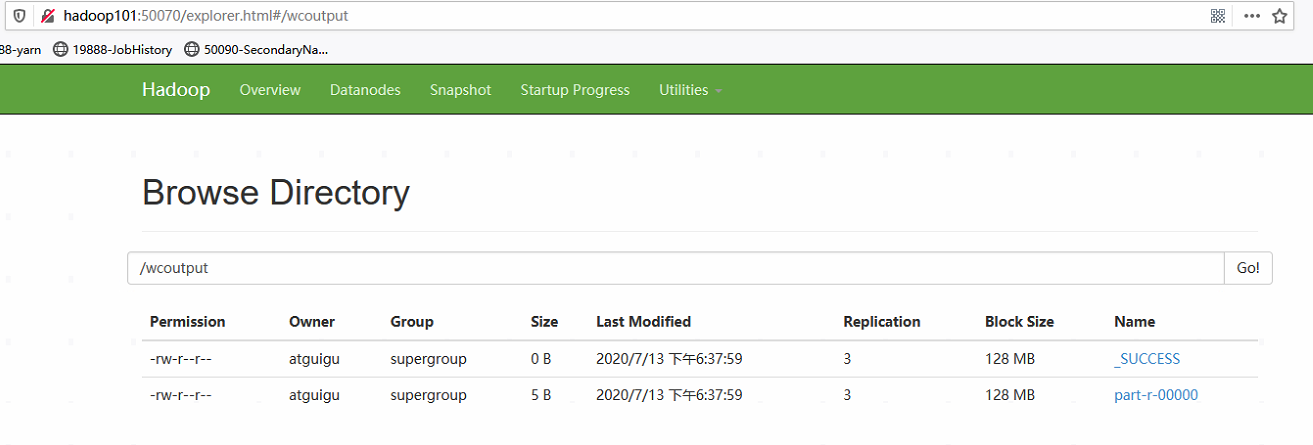
-


集群啟動/停止方式總結
-
各個服務組件逐一啟動/停止
-
分別啟動/停止HDFS組件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode -
啟動/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
-
-
各個模組分開啟動/停止(配置ssh是前提)
-
整體啟動/停止HDFS
start-dfs.sh / stop-dfs.sh -
整體啟動/停止YARN
start-yarn.sh / stop-yarn.sh
-
-
啟動歷史伺服器
mr-jobhistory-daemon.sh start historyserver
集群時間同步
每台虛擬機作如下設置即可保證時間同步
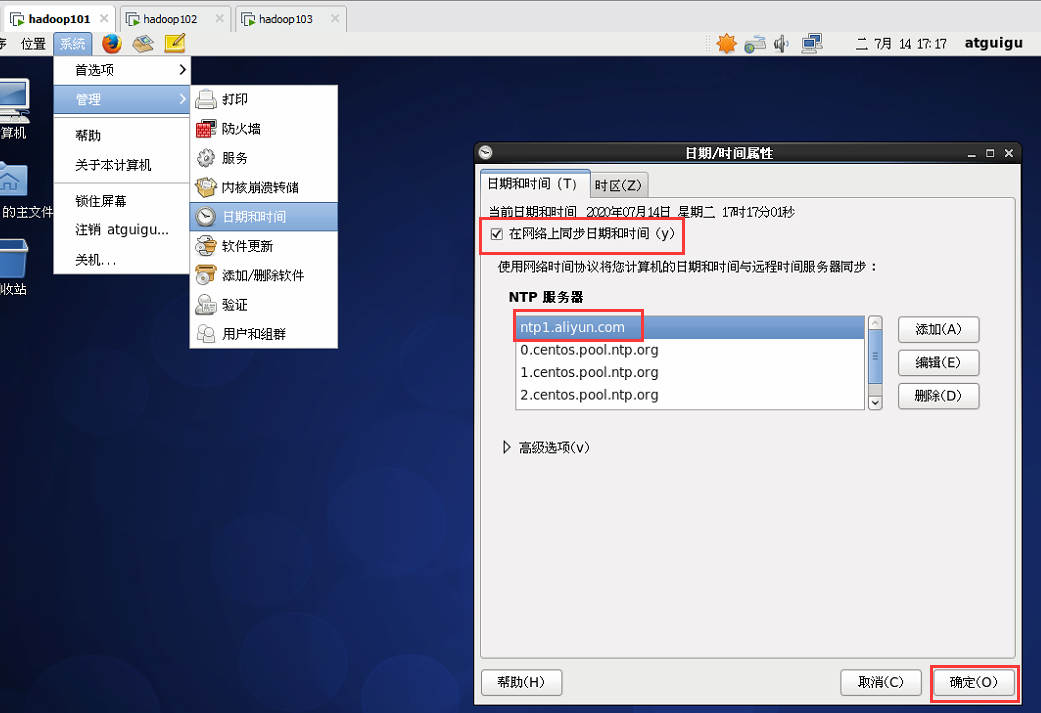
也可設置定時同步時間的任務
crontab -e
* */1 * * * ntpdate -u ntp7.aliyun.com
其他注意事項
- start-all.sh其實是分別調用了start-dfs.sh和start-yarn.sh,現已過時不建議使用.
- stop-all.sh同理.
- start-dfs.sh可以在集群的任意一台機器使用!可以啟動HDFS中的所有進程!
- start-yarn.sh在集群的非RM所在的機器使用,不會啟動resourcemanager!
建議:
只需要配置RM所在機器到其他機器的SSH免密登錄!
都在RM所在的機器執行群起和群停腳本!
xsync和xcall只放在RM所在的機器即可!


