第一天學習進度–文本處理基礎知識學習
參考教程–python機器學習基礎教程
首先在對應目錄創建一個文件夾,裡面放上對應分類名稱(非中文)的文件夾,這個步驟是要讀取對應類型的數據。
結構如下圖所示:
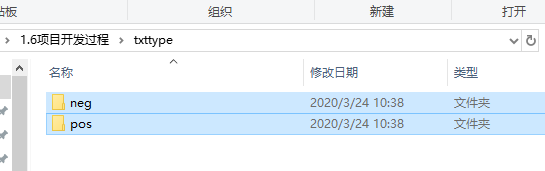
我在txttype中放置了兩個分類的文件夾,每個類別的文件夾中放置了對應類型的文本(數量不限),每個需要訓練的語句都單獨作為一個文本,文本的名稱不做具體要求。
在python中寫入對應的程式碼:
from sklearn.datasets import load_files import numpy as np
#載入數據集
reviews_train = load_files(r"C:\Users\Halo\Desktop\1.6項目開發過程\txttype")
# load_files返回一個Bunch對象,其中包含訓練文本和訓練標籤
text_train, y_train = reviews_train.data, reviews_train.target
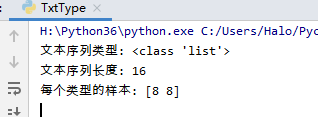
print("文本序列類型: {}".format(type(text_train)))
print("文本序列長度: {}".format(len(text_train)))
# print("text_train[1]:\n{}".format(text_train[1]))
#數據清洗
text_train = [doc.replace(b"<br />", b" ") for doc in text_train]
print("每個類型的樣本: {}".format(np.bincount(y_train)))
可以發現對應的文本文件已經被正確讀取
接著進行第二步,將文本數據轉化為詞袋
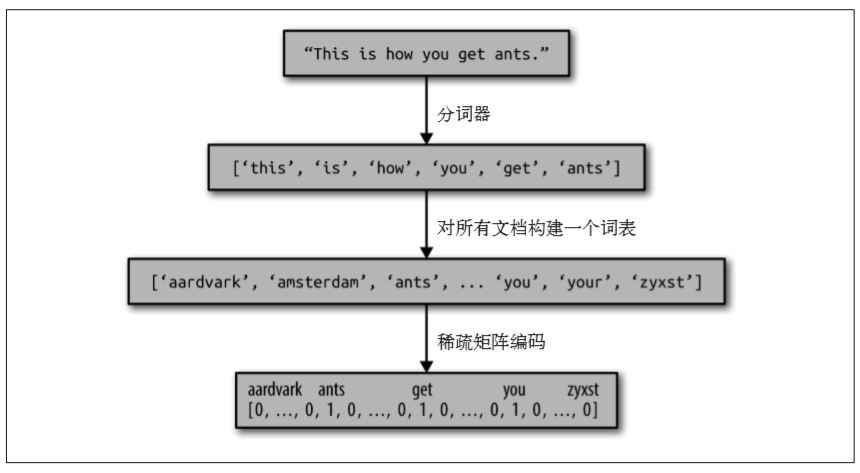
計算詞袋在書中的步驟原話為:
計算詞袋錶示包括以下三個步驟。
(1) 分詞(tokenization) 。將每個文檔劃分為出現在其中的單詞 [ 稱為詞例(token)],比如 按空格和標點劃分。
(2) 構建詞表(vocabulary building)。收集一個詞表,裡面包含出現在任意文檔中的所有詞, 並對它們進行編號(比如按字母順序排序)。
(3) 編碼(encoding)。對於每個文檔,計算詞表中每個單詞在該文檔中的出現頻次
將上述的過程合併之後:
from sklearn.feature_extraction.text import CountVectorizer bards_words =["The fool doth think he is wise,", "but the wise man knows himself to be a fool"] #切詞 vect = CountVectorizer() vect.fit(bards_words) print("Vocabulary size: {}".format(len(vect.vocabulary_))) print("Vocabulary content:\n {}".format(vect.vocabulary_)) #詞袋應用 bag_of_words = vect.transform(bards_words) print("bag_of_words: \n{}".format(repr(bag_of_words.toarray())))
上述是對於該用法的簡單應用,下面將配合參數調節對數據進行讀取。
可以先獲取前20個特徵
#切詞並獲得詞袋 vect = CountVectorizer().fit(text_train) #應用詞袋 X_train = vect.transform(text_train) print("X_train:\n{}".format(repr(X_train))) #獲得文本特徵 feature_names = vect.get_feature_names() print("特徵數量: {}".format(len(feature_names))) print("前20個特徵:\n{}".format(feature_names[:20]))
運行結果:

接著對模型進行評估:
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
#交叉驗證對LogisticRegression進行評估 scores = cross_val_score(LogisticRegression(), X_train, y_train, cv=5) print("平均交叉驗證精度: {:.2f}".format(np.mean(scores)))
運行結果:

在利用交叉驗證調節正則化參數C:
#交叉驗證調節正則化參數C from sklearn.model_selection import GridSearchCV param_grid = {'C': [0.001, 0.01, 0.1, 1, 10]} grid = GridSearchCV(LogisticRegression(), param_grid, cv=5) grid.fit(X_train, y_train) print("最好的交叉驗證分數: {:.2f}".format(grid.best_score_)) print("最好參數值: ", grid.best_params_)
運行結果:

接下來將數據應用到實際的測試集合上上看看該性能指標:
#載入測試集 reviews_test = load_files(r"C:\Users\Halo\Desktop\1.6項目開發過程\txttest") text_test, y_test = reviews_test.data, reviews_test.target print("測試集數量: {}".format(len(text_test))) print("文本序列長度: {}".format(np.bincount(y_test))) text_test = [doc.replace(b"<br />", b" ") for doc in text_test] #在測試集上評估參數泛化性能 X_test = vect.transform(text_test) print("測試集評估參數泛化性能:{:.2f}".format(grid.score(X_test, y_test)))
運行結果:

若數據過多,則可以對數據進行清洗:
#集合清洗 vect = CountVectorizer(min_df=5).fit(text_train) X_train = vect.transform(text_train) print("min_df: {}".format(repr(X_train))) feature_names = vect.get_feature_names() print("前50個特徵:\n{}".format(feature_names[:50])) #再次用玩個搜索看模型性能 grid = GridSearchCV(LogisticRegression(), param_grid, cv=5) grid.fit(X_train, y_train) print("最好交叉驗證分數: {:.2f}".format(grid.best_score_))
運行結果:



