圖文詳解Prometheus監控+Grafana+Alertmanager告警安裝使用
- 2020 年 7 月 7 日
- 筆記
- [05]架構-微服務, Prometheus, 監控
一:前言
一個服務上線了後,你想知道這個服務是否可用,需要監控。假如線上出故障了,你要先於顧客感知錯誤,你需要監控。還有對資料庫,伺服器的監控,等等各層面的監控。
近年來,微服務架構的流行,服務數越來越多,監控指標變得越來越多,所以監控也變得越來越複雜,需要新的監控系統適應這種變化。
以前我們用zabbix,StatsD監控,但是隨著容器化,微服務的流行,我們需要新的監控系統來適應這種變化。於是監控項目Prometheus就應運而生。
二:Prometheus介紹
介紹
-
網站地址://prometheus.io/
//prometheus.io/docs/introduction/overview/
//github.com/prometheus/docs -
github:github.com/prometheus
Prometheus是一款基於時序資料庫的開源監控告警系統,它是SoundCloud公司開源的,SoundCloud的服務架構是微服務架構,他們開發了很多微服務,由於服務太多,傳統的監控已經無法滿足它的監控需求,於是他們在2012就著手開發新的監控系統。Prometheus的原作者Matt T. Proud在2012年加入SoundCloud公司,他之前服務於Google公司,他從google的監控系統Borgmon中獲取靈感,與另外一名工程師Julius Volz合作開發了開源監控系統Prometheus。(總之感覺是因為有了這個前google工程師到來,才有能力開發了Prometheus)。後來其他開發人員陸續加入了這個項目,並在 SoundCloud 內部繼續開發,最終於 2015 年 1 月將其發布。後來在2016年,SoundCloud把它捐獻給了雲原生基金會(Cloud Native Computing Foundation),在它下面繼續孵化。
Prometheus是用go語言開發。它的很多理念跟google的SRE不謀而合。所以有時間,可以去看看google SRE那本書,可以更好的理解Prometheus。
主要特性(功能)
- 多維數據模型(時序由 metric 名字和 k/v 的labels構成)
- 靈活的查詢語言(PromQL)
- 無依賴的分散式存儲;單節點伺服器都是自治的
- 採用 http 協議,使用pull模式拉取數據,簡單易懂
- 監控目標,可以採用服務發現和靜態配置方式
- 支援多種統計數據模型和介面展示。可以和Grafana結合展示。
三:Prometheus架構原理
架構
來自官方的一張架構圖

主要模組:
- the main Prometheus Server,主要用於抓取數據和存儲時序數據,另外還提供查詢和 Alert Rule 配置管理。就是數據的採集和存儲,用PromQL查詢,報警配置。
- client libraries,用於對接Prometheus Server,用於對接Prometheus Server,可以查詢和上報數據。
- a push gateway,用於批量,短期的監控數據的彙報總節點,主要用於業務數據彙報等。
- 各種彙報數據的 exporters,例如彙報機器數據的node_exporter,彙報MondogDB資訊的 MongoDB_exporter 等等。
- 用於高級通知管理的 alertmanager 。
- 各種各樣的支援工具
怎麼採集監控數據
要採集目標的監控數據,首先就要在被採集目標地方安裝採集組件,這種採集組件被稱為Exporter。prometheus.io官網上有很多這種exporter,官方 exporter列表。
採集完了怎麼傳輸到Prometheus?
採集了數據,要傳輸給prometheus。怎麼做?
Exporter 會暴露一個HTTP介面,prometheus通過Pull模式的方式來拉取數據,會通過HTTP協議周期性抓取被監控的組件數據。
不過prometheus也提供了一種方式來支援Push模式,你可以將數據推送到Push Gateway,prometheus通過pull的方式從Push Gateway獲取數據。
主要流程
- Prometheus server定期從靜態配置的 targets 或者服務發現的 targets 拉取數據(zookeeper,consul,DNS SRV Lookup等方式)
- 當新拉取的數據大於配置記憶體快取區的時候,Prometheus會將數據持久化到磁碟,也可以遠程持久化到雲端。
- Prometheus通過PromQL、API、Console和其他可視化組件展示數據。Prometheus支援很多方式圖表可視化,比如Grafana,自帶的Promdash。它還提供HTTP API的查詢方式,自定義輸出。
- Prometheus 可以配置rules,然後定時查詢數據,當條件觸發的時候,會將alert推送到配置的Alertmanager。
- Alertmanager收到告警的時候,會根據配置,聚合,去重,降噪,最後發出警告。
四:安裝Prometheus
要整好prometheus監控系統,還是有很多軟體需要安裝。
安裝的主要組件如下:
- Prometheus Server
- 被監控對象exporter組件
- 數據可視化工具 Grafana
- 數據上報網關 push gateway
- 告警系統 Alertmanager
第1種:直接安裝
到官網下載最新版的Prometheus,下載地址。
因為它是用go開發的,可以做到開箱即用。
wget //github.com/prometheus/prometheus/releases/download/v2.19.2/prometheus-2.19.2.linux-amd64.tar.gz
解壓:
tar xvfz prometheus-2.19.2.linux-amd64.tar.gz
運行啟動:
cd ./prometheus-2.19.2.linux-amd64
./prometheus –version
./prometheus –config.file=prometheus.yml
第2種:docker鏡像安裝
- 先在本機 /etc/docker/prometheus/ 下創建一個配置文件 vim prometheus.yml
global:
scrape_interval: 15s
external_labels:
monitor: 'first-monitor'
scrape_configs:
- job_name: prometheus
scrape_interval: 5s
static_configs:
- targets: ['127.0.0.1:9090']
官方有一個模板:documentation/examples/prometheus.yml
配置參數可以參考這裡: configuration,選擇你安裝版本所對應的配置資訊。
- 執行下面docker命令:
提示:請提前安裝好docker。
docker run –name=prometheus -d -p 9090:9090 -v /etc/docker/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
上面的命令看起來有點不容易理解,重新排列格式後:
docker run –name=prometheus -d -p 9090:9090 \
-v /etc/docker/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus
說明:
- -p 9090:9090,用這個介面可以查看promethdus的web介面
- -v /etc/docker/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
,將伺服器本地的prometheus配置文件掛載到docker目錄 /etc/prometheus/ 下,這個就是prometheus在容器中默認載入配置文件位置。-v參數就是將本地的配置文件掛載到docker裡面。
用上面的命令安裝完後,會出來一個很長的id資訊:
# docker run –name=prometheus -d -p 9090:9090 -v /etc/docker/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
cddca15bad0eea0c249cb4a5dfe1a148d7779a00b0dd514c654c5cddce4e951d
可以用 docker inspect + id 前面部分資訊 這樣的命令來查看容器運行時默認配置參數有哪些,這個資訊內容很長,截取需要的部分來看:
# docker inspect cddc
[
{
“Id”: “cddca15bad0eea0c249cb4a5dfe1a148d7779a00b0dd514c654c5cddce4e951d”,
“Created”: “2020-07-04T10:10:33.792265269Z”,
“Path”: “/bin/prometheus”,
“Args”: [
“–config.file=/etc/prometheus/prometheus.yml”,
“–storage.tsdb.path=/prometheus”,
“–web.console.libraries=/usr/share/prometheus/console_libraries”,
“–web.console.templates=/usr/share/prometheus/consoles”
],
“State”: {
“Status”: “running”,
“Running”: true,
“Paused”: false,
“Restarting”: false,
“OOMKilled”: false,
“Dead”: false,
“Pid”: 18313,
“ExitCode”: 0,
“Error”: “”,
“StartedAt”: “2020-07-04T10:10:34.13215448Z”,
“FinishedAt”: “0001-01-01T00:00:00Z”
},
“Image”: “sha256:9f345bfa8fefdd9580d5bd951a99e105af38d6047878c4bfb7c5c0250f77998e”,
“ResolvConfPath”: “/var/lib/docker/containers/cddca15bad0eea0c249cb4a5dfe1a148d7779a00b0dd514c654c5cddce4e951d/resolv.conf”,
“HostnamePath”: “/var/lib/docker/containers/cddca15bad0eea0c249cb4a5dfe1a148d7779a00b0dd514c654c5cddce4e951d/hostname”,
“HostsPath”: “/var/lib/docker/containers/cddca15bad0eea0c249cb4a5dfe1a148d7779a00b0dd514c654c5cddce4e951d/hosts”,
可以看到上面的Args就是默認配置文件位置
配置文件
prometheus主配置文件
- prometheus.yml , 主配置文件,四大塊:global,alerting,rule_files,scrape_config
其實它還有很多其他配置文件,比如rules.yml,你可能會問,上面沒有看到rules.yml這個文件?是的上面沒有加。可以用這個命令加上:
-v /etc/docker/prometheus/rules.yml:/etc/prometheus/rules.yml
其實跟加上promethdus.yml命令是一樣的。
配置參數項以及說明可以參考這裡: configuration,選擇你安裝版本所對應的配置資訊。
配置說明:
global:
scrape_interval: 15s #默認採集監控數據時間間隔
external_labels:
monitor: 'first-monitor'
scrape_configs: #監控對象設置
- job_name: prometheus #任務名稱
scrape_interval: 5s #每隔5s獲取一次監控數據
static_configs: #監控對象地址
- targets: ['127.0.0.1:9090']
- job_name: server-redis # 還可以加其他監控對象
static_configs:
- targets: ['192.168.10.20:9100']
labels: # 標籤
instance: server-redis
查看web介面
在瀏覽器上輸入 //127.0.0.1:9090/ , 如果顯示下面的web介面,說明promethdus啟動成功:
五:Exporter採集監控資訊
前面已經講過,如果要監控伺服器或者應用程式的各種資訊,比如cpu、記憶體、網卡流量等等。就要在監控目標上安裝指標收集程式,並暴露HTTP介面供Prometheus拉取數據,這個指標收集程式就是Exporter。不同的指標需要不同的Exporter收集。
這種Exporter需要自己寫嗎?
一般不需要,官網上已經有大量的Exporter,上面我們已經列出過官網的Exporter清單 地址。
而且有的軟體已經集成了Prometheus的Exporter,也就是說軟體本身就提供了Prometheus需要的各種指標數據。最典型的就是k8s,他們是雲原生基金會的第一和第二個項目。
如果需要特殊的監控,可能就要你自己寫Exporter了。
實例: node-exporter監控伺服器
上面prometheus已經安裝好了,現在來安裝一個Exporter監控實例。
來安裝一個監控伺服器主機cpu、記憶體和磁碟等資訊的exporter,直接用node-exporter。它主要用於收集類 UNIX 系統的資訊。
步驟:
1.先修改prometheus.yml資訊,
global:
scrape_interval: 15s
external_labels:
monitor: 'first-monitor'
scrape_configs:
- job_name: prometheus
scrape_interval: 5s
static_configs:
- targets: ['127.0.0.1:9090']
- targets: ['127.0.0.1:9100'] # 這裡開始增加的監控資訊
labels:
group: 'local-node-exporter'
2.用docker安裝並啟動node-exporter:
docker run -d –name=node-exporter -p 9100:9100 prom/node-exporter
3.然後重啟docker prometheus,讓剛才修改的配置生效:
docker restart prometheus
4.在瀏覽器上直接輸入: //127.0.0.1:9090/targets。或者,你在介面上點擊 Status 菜單 -> Targets 菜單,來瀏覽metrics資訊。
如果你是在伺服器上安裝,那麼這裡的 127.0.0.1 就是伺服器IP地址,或者域名。
瀏覽器輸出的web介面如下:(我用的遠程伺服器測試,所以用了ip)

可以看到裡面有一個 9100 埠的 metrics 連接,點進去後,就可以看到一些採集資訊。
說明剛才配置的node-exporter已經加入到prometheus的targets中了。如下圖:

查看監控資訊
點擊web介面最上面的菜單 Graph

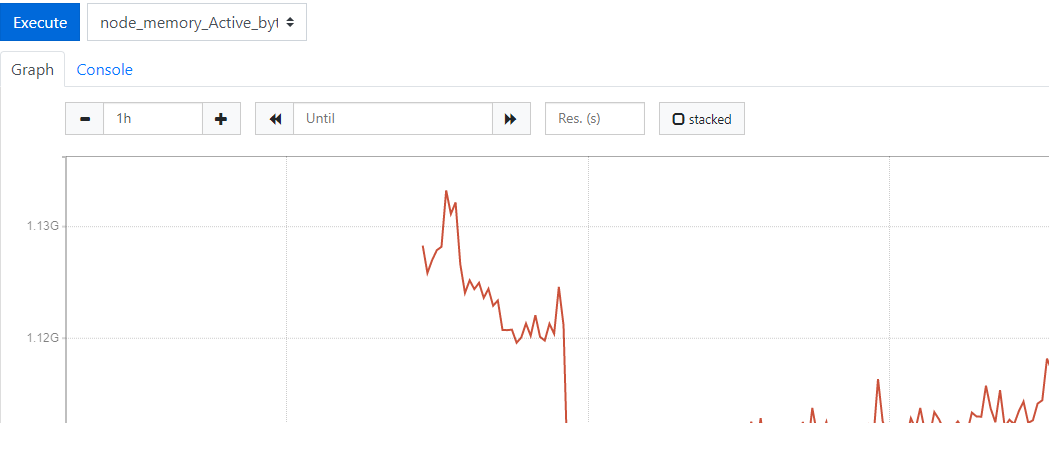
選擇下面的 Graph,然後我們選擇一個 node_memory_Active_bytes 來看一看,

然後點擊 Execute 按鈕 , 就會出來如下圖所示圖形:
六:可視化系統:Grafana
上面我們通過Prometheus自帶的UI,查看不同指標視圖,但是它的功能很簡單。如果需要強大的展示系統,能訂製不同指標的面板,支援不同類型的展示方式,如曲線圖、熱點圖,TopN等,那麼grafana比較合適。它可以對promethdus數據進行可視化的展示。
grafana是一個大型可視化系統,功能強大,可以創建自己的自定義面板,支援多種數據來源,
比如:OpenTSDB、Elasticsearch、Prometheus 等,可以到官網去查看支援的數據源種類,而且它插件也很多。
安裝
官網安裝文檔,它有不同平台安裝的Doc。
我選擇最簡單的一種,直接用docker安裝,命令如下:
docker run -d -p 3000:3000 –name=grafana grafana/grafana
Docker安裝完後,最後會出來一些提示資訊:
… …
Digest:sha256:0e8b556a7fc9b95c03669509ec50be19c16b82b9e9078f79fa35a71f484bc047
Status: Downloaded newer image for docker.io/grafana/grafana:latest 97d1c768ce6c541fa58790ec97fd06783633833cd9e74b12c16266dd264f8d0f
說明安裝成功了。我們在瀏覽器上看看介面,輸入下面地址:
//127.0.0.1:3000/login
然後輸入初始密碼 admin/admin 登錄進入。
我安裝的版本是:
Grafana v7.0.5
grafana設置
增加prometheus數據源並展示
1.點擊如下圖的Data Source:

2.點擊 Add data source 按鈕後,出來下面介面:

3.滑鼠移到 Prometheus 上,點擊 Select 按鈕:

4.prometheus相關設置:
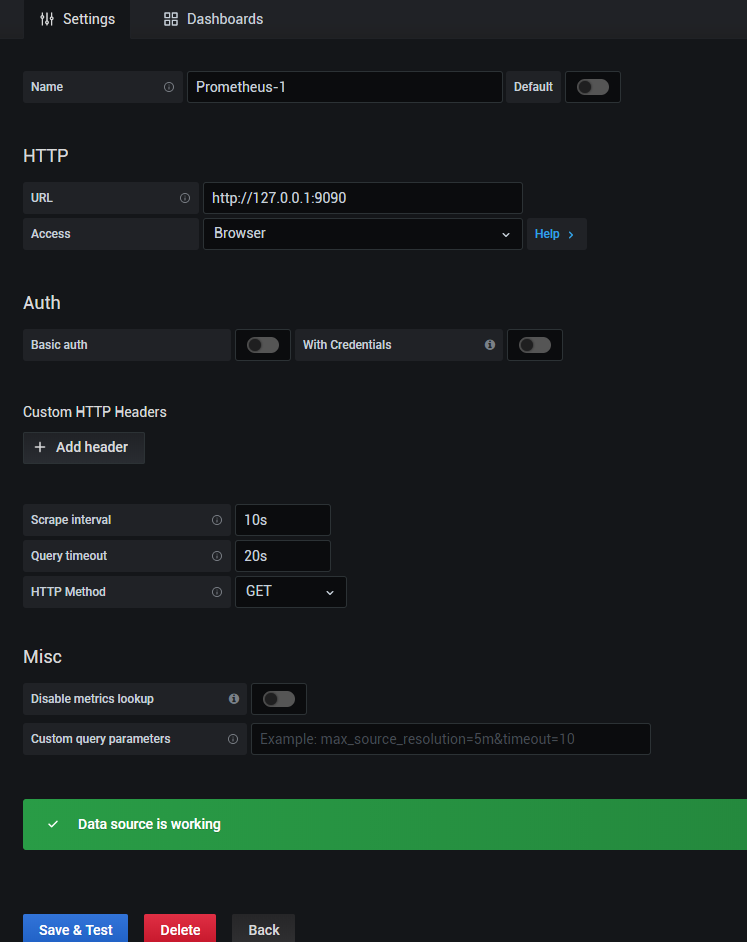
最主要設置獲取數據的HTTP URL。
5.點擊 save&test 按鈕,它會提示你是否設置成功。
6.設置Dashboards

7.回到home

8:點擊 prometheus

9:出來很多圖表展示

其他dashboard模板設置
grafana不僅有我們上面設置的那些圖表模板,它還有其他很多模板,我們也可以設置。
官方模板dashboard 地址。
比如我們查找node exportet的模板,//grafana.com/grafana/dashboards?search=node%20exporter,有一個模板 downloads 比較多,
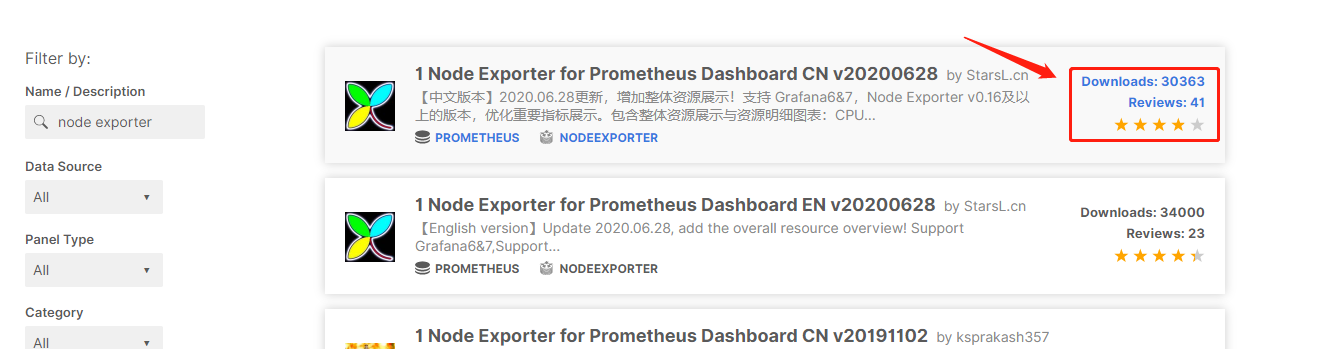
它的地址為:
//grafana.com/grafana/dashboards/8919
我們在grafana上來設置這個dashboard,import進來:

可以填寫id和url,我們填寫id,為 8919:
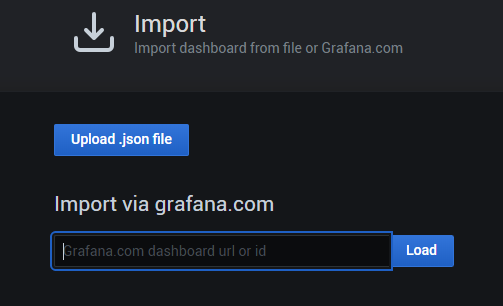
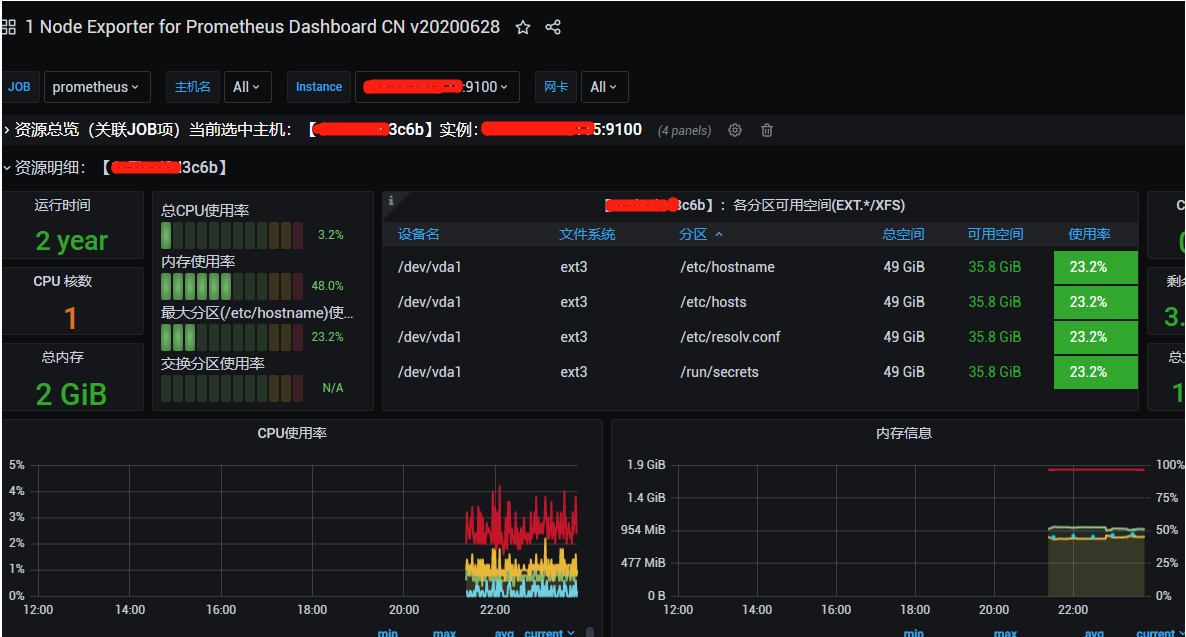
點擊 load 出來下面介面:

然後選擇prometheus-1,點擊 import, 出來如下圖的介面:
七、告警通知
我們已經能夠對收集的數據,通過grafana展示出來了,能查看數據。想一想,系統還缺失什麼功能?
監控最重要的目的是什麼?
- 第一:監控系統是否正常
- 第二:系統不正常時,可以告知相關人員及時的排查和解除問題,這就是告警通知。
所以,還缺一個告警通知的模組。
prometheus的告警機制由2部分組成:
- 告警規則
prometheus會根據告警規則rule_files,將告警發送給Alertmanager - 管理告警和通知
模組是Alertmanager。它負責管理告警,去除重複的數據,告警通知。通知方式有很多如Email、HipChat、Slack、WebHook等等。
配置
1.告警規則配置
告警文檔地址:告警規則官方文檔。
我們新創建一個規則文件:alert_rules.yml,把它和prometheus.yml放在一起,官方有一個模板 Templating,直接copy過來:
groups:
- name: example
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
# Alert for any instance that has a median request latency >1s.
- alert: APIHighRequestLatency
expr: api_http_request_latencies_second{quantile="0.5"} > 1
for: 10m
annotations:
summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
上面規則文件大意:就是創建了2條alert規則 alert: InstanceDown 和 alert: APIHighRequestLatency :
- InstanceDown 就是實例宕機(up==0)觸發告警,5分鐘後告警(for: 5m);
- APIHighRequestLatency 表示有一半的 API 請求延遲大於 1s 時(api_http_request_latencies_second{quantile=”0.5″} > 1)觸發告警
更多rules規則說明,請看這裡 recording_rules。
然後把alrt_rules.yml添加到prometheus.yml 里:

我們要把alert_rules.yml規則映射到docker里:
先用docker ps查看prometheus容器ID, CONTAINER ID: ac99a89d2db6, 停掉容器 docker stop ac99,然後刪掉這個容器 docker rm ac99。
重新啟動容器:
docker run –name=prometheus -d -p 9090:9090 -v /etc/docker/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml -v /etc/docker/prometheus/alert_rules.yml:/etc/prometheus/alert_rules.yml prom/prometheus
啟動時主要添加這個參數:-v /etc/docker/prometheus/alert_rules.yml:/etc/prometheus/alert_rules.yml
然後在瀏覽器上查看,rules是否添加成功,在瀏覽器上輸入地址 //127.0.0.1:9090/rules

也可以查看alers情況,點擊菜單 Alerts:

告警通知配置
alertmanager配置:
官方配置文檔,官方配置例子。
在上面我們可以看到alerts頁面的告警資訊,但是怎麼通知到研發和業務相關人員呢?這個就是由Alertmanager完成,先配置alertmanager文件 alertmanager.yml,:
global:
resolve_timeout: 5m
route:
group_by: ['example'] #與prometheus配置文件alert_rules.yml中配置規則名對應
group_wait: 10s #報警等待時間
group_interval: 10s #報警間隔時間
repeat_interval: 1m #重複報警間隔時間
receiver: 'web.hook' #告警處理方式,我們這裡通過web.hook方式,也可以配置成郵件等方式
receivers:
- name: 'web.hook'
webhook_configs:
- url: '//127.0.0.1:8080/example/test' #告警web.hook地址,告警資訊會post到該地址,需要編寫服務接收該告警數據
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning' #目標告警狀態
equal: ['alertname', 'dev', 'instance']
啟動alertmanager服務:
docker run -d -p 9093:9093 –name alertmanager -v /etc/docker/prometheus/alertmanager.yml:/etc/prometheus/alertmanager.yml prom/alertmanager
在瀏覽器上輸入 : //127.0.0.1:9093,出現下面介面:

prometheus配置:
在promethdus加上下面的配置,
alerting:
alertmanagers:
- static_configs:
- targets: ['127.0.0.1:9093']
配置說明:告訴prometheus,放生告警時,將告警資訊發送到Alertmanager,Alertmanager地址為 //127.0.0.1:9093
先docker rm 刪除掉原來容器,在運行:
docker run –name=prometheus -d -p 9090:9090 -v /etc/docker/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml -v /etc/docker/prometheus/alert_rules.yml:/etc/prometheus/alert_rules.yml prom/prometheus
再次運行//127.0.0.1:9093,正常說明配置成功
如果您看到這裡,覺得還可以的話,隨手點個 推薦,讓更多人看到
八:參考鏈接
- //prometheus.io/docs/introduction/overview/
- //github.com/prometheus/prometheus
- //www.aneasystone.com/archives/2018/11/prometheus-in-action.html
- //github.com/prometheus/alertmanager
- //github.com/songjiayang/prometheus_practice
- //prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
- //grafana.com/
- //grafana.com/plugins
- //hub.docker.com/r/prom/prometheus/
- //www.bookstack.cn/read/prometheus-manual/prometheus
[完]


