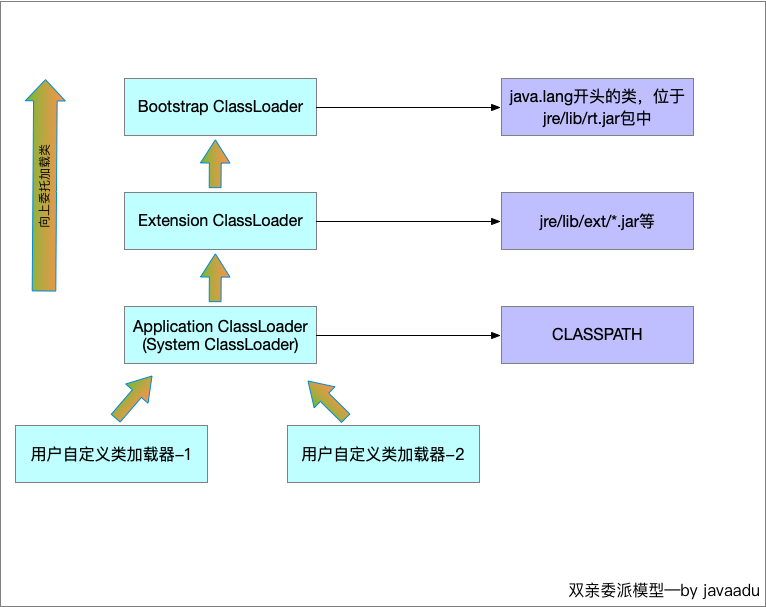
卷積神經網路CNN識別MNIST數據集
- 2019 年 10 月 13 日
- 筆記
這次我們將建立一個卷積神經網路,它可以把MNIST手寫字元的識別準確率提升到99%,讀者可能需要一些卷積神經網路的基礎知識才能更好的理解本節的內容。
程式的開頭是導入TensorFlow:
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data
接下來載入MNIST數據集,並建立佔位符。佔位符x的含義為訓練影像,y_為對應訓練影像的標籤。
# 讀入數據 mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) # x為訓練影像的佔位符,y_為訓練影像標籤的佔位符 x = tf.placeholder(tf.float32, [None, 784]) y_ = tf.placeholder(tf.float32, [None, 10])
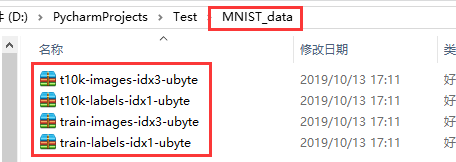
運行後會在當前目錄下得到一個名為MINST_data的數據集。如下圖所示
由於使用的是卷積神經網路對影像進行分類,所以不能再使用784維的向量表示輸入的x,而是將其還原為28*28的圖片形式。[-1,28,28,1]中的-1表示形狀第一維的大小是根據x自動確定的。
# 將單張圖片從784維向量重新還原為28*28的矩陣圖片 x_image = tf.reshape(x, [-1, 28, 28, 1])
x_image就是輸入的訓練影像,接下來,我們對訓練影像進行卷積計算,第一層卷積的程式碼如下:
def weight_variable(shape): initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial) def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial) def conv2d(x, W): return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') def max_pool_2x2(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') # 第一層卷積層 W_conv1 = weight_variable([5, 5, 1, 32]) b_conv1 = bias_variable([32]) h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) h_pool1 = max_pool_2x2(h_conv1)
首先定義了四個函數,函數weight_variable可以返回一個給定形狀的變數,並自動以截斷正態分布初始化,bias_variable同樣返回一個給定形狀的變數,初始化所有值是0.1,可分別用這兩個函數創建卷積的核(kernel)與偏置(bias)。h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)是真正進行卷積運算,卷積計算後選用ReLU作為激活函數。h_pool1 = max_pool_2x2(h_conv1)是調用函數max_pool_2x2進行一次池化操作。卷積、激活函數、池化,可以說是一個卷積層的“標配”,通常一個卷積層都會包含這三個步驟,有時也會去掉最後的池化操作。
對第一次卷積操作後產生的h_pool1再做一次卷積計算,使用的程式碼與上面類似。
# 第二層卷積 W_conv2 = weight_variable([5, 5, 32, 64]) b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) h_pool2 = max_pool_2x2(h_conv2)
兩層卷積層之後是全連接層:
# 全連接層,輸出為1024維的向量 W_fc1 = weight_variable([7 * 7 * 64, 1024]) b_fc1 = bias_variable([1024]) h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) # 使用Dropout,keep_prob是一個佔位符,訓練時為0.5,測試時為1 keep_prob = tf.placeholder(tf.float32) h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
在全連接層中加入了Dropout,它是防止神經網路過擬合的一種手段。在每一步訓練時,以一定概率“去掉”網路中的某些連接,但這種去除不是永久性的,只是在當前步驟中去除,並且每一步去除的連接都是隨機選擇的。在這個程式中,選擇的Dropout概率是0.5,也就是說訓練時每一個連接都有50%的概率被去除。在測試時保留所有連接。
最後,再加入一層全連接,把上一步得到的h_fc1_drop轉換為10個類別的打分。
# 把1024維的向量轉換為10維,對應10個類別 W_fc2 = weight_variable([1024, 10]) b_fc2 = bias_variable([10]) y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
y_conv相當於Softmax模型中的Logit,當然可以使用Softmax函數將其轉換為10個類別的概率,再定義交叉熵損失。但其實TensorFlow提供了一個更直接的tf.nn.softmax_cross_entropy_with_logits函數,它可以直接對Logit定義交叉熵損失,寫法為:
# 不採用先softmax再計算交叉熵的方法 # 而是採用tf.nn.softmax_cross_entropy_with_logits直接計算 cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv)) # 同樣定義train_step train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
定義測試的準確率
# 定義測試的準確率 correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
在控制台顯示在驗證集上訓練時模型的準確度,方便監控訓練的進度,也可以據此來調整模型的參數。
# 創建Session,對變數初始化 sess = tf.InteractiveSession() sess.run(tf.global_variables_initializer()) # 訓練20000步 for i in range(20000): batch = mnist.train.next_batch(50) # 每100步報告一次在驗證集上的準確率 if i % 100 == 0: train_accuracy = accuracy.eval(feed_dict={ x: batch[0], y_: batch[1], keep_prob: 1.0 }) print("step %d,training accuracy %g" % (i, train_accuracy)) train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
訓練結束後,列印在全體測試集上的準確率:
# 訓練結束後報告在測試集上的準確率 print("test accuracy %g" % accuracy.eval(feed_dict={ x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0 }))
最後得到的結果在控制台顯示為
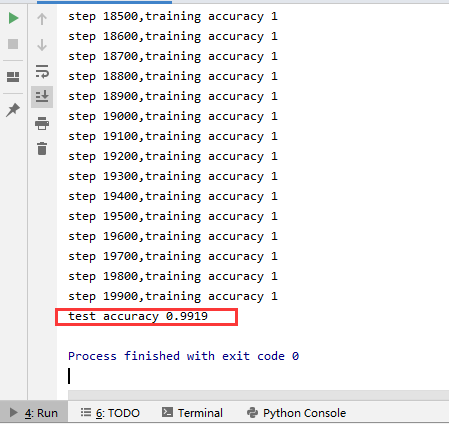
可以最終測試得到的準確率結果應該在99%左右。與Softmax回歸模型相比,使用兩層卷積的神經網路模型藉助了卷積的威力,準確率有非常大的提升。