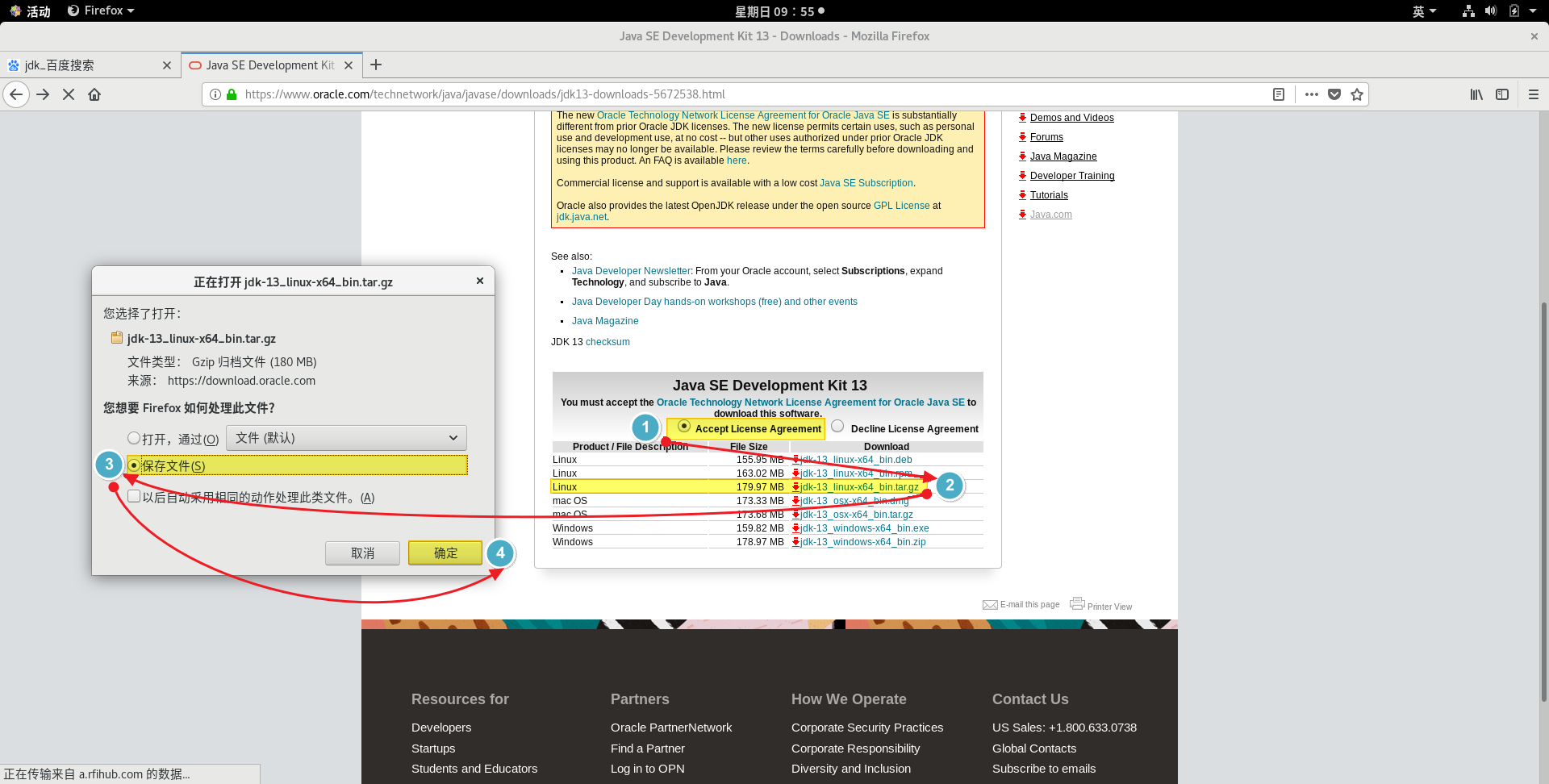
.Net Core下使用HtmlAgilityPack解析採集互聯網數據
- 2019 年 10 月 13 日
- 筆記
HtmlAgilityPack應該算是.Net下最好用的html解析庫了。
因為最近幫朋友採集一些數據,在nuget裡面搜索了好幾個庫,最後決定就用HtmlAgilityPack。並簡單的記錄下使用的姿勢。
直接使用nuget包安裝
Install-Package HtmlAgilityPack -Version 1.11.16
1.下載網頁
該庫提供了一個下載網頁的類:HtmlWeb
var webGet = new HtmlWeb(); var document = webGet.Load(url);
如果網路正常的話,就會拿到一個HtmlDocument的對象。後面我們所有的操作都是基於該類做的。
我個人更喜歡使用HttpClient來下載網頁,然後使用HtmlDocument來LoadHtml。因為自己使用HTMLClient可控性更高。比如要加代理IP,隨機設置UA等操作。
當然簡單的使用,使用HtmlWeb就差不多了。
2.解析網頁
第一步拿到的htmlDocument對象,裡面提供了很多操作。

舉個栗子,比如我們要獲取網頁的文章的作者,直接在Chrome中右鍵->審查元素->elements->右鍵->Copy->Copy Xpath
document.DocumentNode.SelectSingleNode("Chrome複製的xpath")?.InnerText
然後就成功採集到了作者名字
如何解析列表?
用部落格園舉栗子,首頁就是一個列表文章頁。我們如何獲取到這個列表所有的項呢?
var nodes = document.DocumentNode.SelectNodes("xpath表達式")
如果熟悉xpath的老哥們就知道使用雙斜杠開頭的,就可以獲取到多項節點的結果。比如部落格園的表達式為: //div[@class=’post_item’],然後獲取到HtmlDocument的一個集合,再解析集合的子節點,就行了!
如何刪除標籤?
有些文章中,會隱藏a標籤來給批量採集的人下毒。
可以直接使用Descendants方法找到所有的a標籤,然後刪除
var aNodes = 獲取到的HtmlDocument對象.DocumentNode.Descendants("a") foreach (var anode in aNodes.ToArray()) { anode.Remove(); }
如果要採集圖片呢?
一般圖片地址放在img的src屬性上,
var imgNodes = detail.DocumentNode.Descendants("img"); foreach (var img in imgNodes) { string imgurl = img.GetAttributeValue("src",""); }
獲取到地址,就可以使用HTTPClient來下載圖片並保存到文件夾中
如何修改節點屬性?
舉個栗子,如果我們把圖片上傳到我們的伺服器,然後要在文章中替換掉別人的圖片地址,那應該怎麼做呢?
var imgNodes = detail.DocumentNode.Descendants("img"); foreach (var img in imgNodes) { img.SetAttributeValue("src", "圖片地址"); }
基本上,掌握這幾點,就能到處去採集別人的網站了。
當然HtmlAgilityPack的功能遠遠不止本文所描述的這些,更多的功能,可能需要有更深入的需求才會用到,
有不懂或者需要交流的大佬們,可以加我的QQ:862640563 QQ群:545594312