【推薦演算法工程師技術棧系列】推薦系統–數據效果與評估
- 2019 年 10 月 13 日
- 筆記
推薦系統上線的基本條件
一個新的推薦演算法最終上線,需要完成上面所說的3個實驗:
(1)首先,需要通過離線實驗證明它在很多離線指標上優於現有的演算法;
(2)然後,需要通過用戶調查(或內部人工評測)確定它的用戶滿意度不低於現有的演算法;
(3)最後,通過在線等AB測試確定它在我們關心的指標上優於現有的演算法。
AB實驗
(1)AB test 的好處是顯而易見的,可以公平獲得不同演算法實際在線時的性能指標;
(2)AB test 和用戶調查一樣,同樣需要考慮到分布的隨機,盡量要將與最終指標有相關性的因素都列出來,總而言之就是切分流量是AB test 的關鍵;
(3)AB test 的一個重要缺點就是實驗周期長,這樣才能得到可靠的結果,因此AB test 不應該測試所有的演算法,而是只測試在離線實驗和用戶調查中表現很好的演算法;
(4)如果有用戶標籤庫的話,會極大的幫助在線實驗。
功能列表
| 功能 | 描述 |
|---|---|
| 分流 | 支援召回排序等指定方式分流,比如尾號哈希,或分層哈希 |
| 白名單 | 實驗開始前預置一些用戶白名單到實驗組 |
| 實驗管理 | 支援實驗創建,實驗列表,實驗修改等 |
| 指標管理 | 指標計算定義 |
| 效果圖表 | diff,AAdiff;以及對應圖表 |
| 可信度分析 | 根據實驗組的置信區間(95%置信區間)和p值(當p值小於等於0.05時,實驗結果是顯著的)判定實驗是否可信 |
數據指標
這裡對應到推薦的指標集一般包括點擊率(ctr),關注率,觀看時長,MAU/DAU等;
而線下一般採用(特徵/召回)覆蓋率,AUC,gAUC,相關性&準確率(人工評測)等指標;
覆蓋率
其中特徵覆蓋率(coverage = frac{N_1}{N} ; 其中N_1是特徵i中非空個數,N是總樣本數; 對應到召回覆蓋率,N_1是有召回結果的用戶數(或召回的內容數),N是總用戶數(或可推薦的內容數))
不得不提的是在項亮的《推薦系統實踐》中推薦系統的覆蓋率是度量一個推薦系統挖掘長尾商品的能力(曝光內容分散程度,越集中頭部效應/馬太效應越嚴重):
[ Coverage = frac{|cup_{u in U} R(u)|}{|I|} ;其中U是用戶集合,I是物品集合,R(u)是為用戶u推薦的N個物品的集合]
在度量推薦系統覆蓋率更科學的一個指標是基尼係數(Gini Index),因為其考慮了每個物品被推薦次數是否平均,係數越大,表示越不均等,係數越小,表示越均等。gini係數最開始是被用來量度貧富懸殊程度,具體推導見附錄洛倫茨曲線和基尼係數:
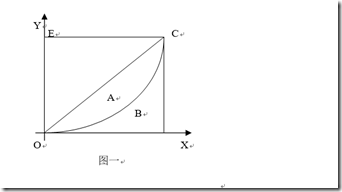
1905年,統計學家洛倫茨提出了洛倫茨曲線,如圖一。將社會總人口按收入由低到高的順序平均分為10個等級組,每個等級組均佔10%的人口,再計算每個組的收入佔總收入的比重。然後以人口累計百分比為橫軸,以收入累計百分比為縱軸,繪出一條反映居民收入分配差距狀況的曲線,即為洛倫茨曲線。
[ Gini = frac{1}{n-1} sum^n_{j=1} (2j-n-1)p(j) ;其中p(j)是從小到大排序的物品列表中第j個物品被推薦的比例,也即p(j)=frac{物品j被推薦次數}{sum^n_{j=1}物品j被推薦次數} ]
AUC及gAUC
AUC(Area under curve)是機器學習常用的二分類評測手段,直接含義是ROC曲線下的面積;進一步說其實就是隨機抽出一對樣本(一個正樣本,一個負樣本),然後用訓練得到的分類器來對這兩個樣本進行預測,預測得到正樣本的概率大於負樣本概率的概率。
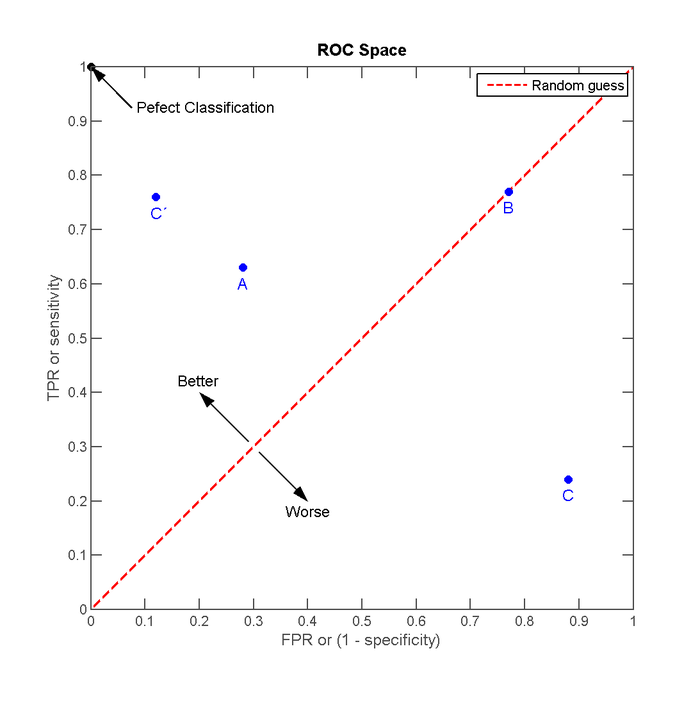
ROC曲線的橫軸為假正率(False Positive Rate,FPR);縱軸為「真正率」(True Positive Rate,TPR)
[ TPR = frac{fp}{p} ; FPR = frac{tp}{n} ; fp是實際為負預測為正的樣本個數;tp是實際為正預測也為正的個數;n是真實負樣本總數;p是真實正樣本總數 ]
[ AUC = frac{ sum_{i in postitiveClass} rank_i – frac{M(1+M)}{2}}{M+N} ;其中rank_i實代表了樣本i預測概率超過的樣本的數目(最高的概率的rank為n,第二高的為n-1);M是正樣本個數,N是負樣本個數]
AUC反映的是整體樣本間的一個排序能力,而實際用戶的結果是個性化的,我們更關注的是同一個用戶對不同物品間的排序能力,gAUC(group auc)實際是計算每個用戶的auc,然後加權平均,最後得到group auc,這樣就能減少不同用戶間的排序結果不太好比較這一影響。
[ gAUC = frac{sum_{(u,p)} w_{(u,p)} * AUC_{(u,p)}}{sum_{(u,p)} w_{(u,p)}} ]
實際處理時權重一般可以設為每個用戶view的次數,或click的次數,而且一般計算時,會過濾掉單個用戶全是正樣本或負樣本的情況。
但是實際上一般還是主要看auc這個指標,但是當發現auc不能很好的反映模型的好壞(比如auc增加了很多,實際效果卻變差了),這時候可以看一下gauc這個指標。
指標展示
這方面一般由數據平台的產品進行支援,簡單的也可以自己寫SQL跑數據;在此就不詳細展開了。
指標監控
這方面一般依託監控報警平台和數據平台;業務方也可以自己寫腳本監控;在此就不詳細展開了。
人工評測
數據指標和真實的用戶體驗存在差異,Bad case的回饋是優化推薦系統的一大途徑