MySQL 你可能忽視的選擇問題
我們在 MySQL 入門篇主要介紹了基本的 SQL 命令、數據類型和函數,在局部以上知識後,你就可以進行 MySQL 的開發工作了,但是如果要成為一個合格的開發人員,你還要具備一些更高級的技能,下面我們就來探討一下 MySQL 都需要哪些高級的技能
MySQL 存儲引擎
存儲引擎概述
資料庫最核心的一點就是用來存儲數據,數據存儲就避免不了和磁碟打交道。那麼數據以哪種方式進行存儲,如何存儲是存儲的關鍵所在。所以存儲引擎就相當於是數據存儲的發動機,來驅動數據在磁碟層面進行存儲。
MySQL 的架構可以按照三層模式來理解

存儲引擎也是 MySQL 的組建,它是一種軟體,它所能做的和支援的功能主要有
- 並發
- 支援事務
- 完整性約束
- 物理存儲
- 支援索引
- 性能幫助
MySQL 默認支援多種存儲引擎,來適用不同資料庫應用,用戶可以根據需要選擇合適的存儲引擎,下面是 MySQL 支援的存儲引擎
- MyISAM
- InnoDB
- BDB
- MEMORY
- MERGE
- EXAMPLE
- NDB Cluster
- ARCHIVE
- CSV
- BLACKHOLE
- FEDERATED
默認情況下,如果創建表不指定存儲引擎,會使用默認的存儲引擎,如果要修改默認的存儲引擎,那麼就可以在參數文件中設置 default-table-type,能夠查看當前的存儲引擎
show variables like 'table_type';

奇怪,為什麼沒有了呢?網上求證一下,在 5.5.3 取消了這個參數
可以通過下面兩種方法查詢當前資料庫支援的存儲引擎
show engines \g

在創建新表的時候,可以通過增加 ENGINE 關鍵字設置新建表的存儲引擎。
create table cxuan002(id int(10),name varchar(20)) engine = MyISAM;

上圖我們指定了 MyISAM 的存儲引擎。
如果你不知道表的存儲引擎怎麼辦?你可以通過 show create table 來查看

如果不指定存儲引擎的話,從MySQL 5.1 版本之後,MySQL 的默認內置存儲引擎已經是 InnoDB了。建一張表看一下

如上圖所示,我們沒有指定默認的存儲引擎,下面查看一下表

可以看到,默認的存儲引擎是 InnoDB。
如果你的存儲引擎想要更換,可以使用
alter table cxuan003 engine = myisam;
來更換,更換完成後回顯示 0 rows affected ,但其實已經操作成功

我們使用 show create table 查看一下表的 sql 就知道

存儲引擎特性
下面會介紹幾個常用的存儲引擎以及它的基本特性,這些存儲引擎是 **MyISAM、InnoDB、MEMORY 和 MERGE **
MyISAM
在 5.1 版本之前,MyISAM 是 MySQL 的默認存儲引擎,MyISAM 並發性比較差,使用的場景比較少,主要特點是
-
不支援
事務操作,ACID 的特性也就不存在了,這一設計是為了性能和效率考慮的。 -
不支援
外鍵操作,如果強行增加外鍵,MySQL 不會報錯,只不過外鍵不起作用。 -
MyISAM 默認的鎖粒度是
表級鎖,所以並發性能比較差,加鎖比較快,鎖衝突比較少,不太容易發生死鎖的情況。 -
MyISAM 會在磁碟上存儲三個文件,文件名和表名相同,擴展名分別是
.frm(存儲表定義)、.MYD(MYData,存儲數據)、MYI(MyIndex,存儲索引)。這裡需要特別注意的是 MyISAM 只快取索引文件,並不快取數據文件。 -
MyISAM 支援的索引類型有
全局索引(Full-Text)、B-Tree 索引、R-Tree 索引Full-Text 索引:它的出現是為了解決針對文本的模糊查詢效率較低的問題。
B-Tree 索引:所有的索引節點都按照平衡樹的數據結構來存儲,所有的索引數據節點都在葉節點
R-Tree索引:它的存儲方式和 B-Tree 索引有一些區別,主要設計用於存儲空間和多維數據的欄位做索引,目前的 MySQL 版本僅支援 geometry 類型的欄位作索引,相對於 BTREE,RTREE 的優勢在於範圍查找。
-
資料庫所在主機如果宕機,MyISAM 的數據文件容易損壞,而且難以恢復。
-
增刪改查性能方面:SELECT 性能較高,適用於查詢較多的情況
InnoDB
自從 MySQL 5.1 之後,默認的存儲引擎變成了 InnoDB 存儲引擎,相對於 MyISAM,InnoDB 存儲引擎有了較大的改變,它的主要特點是
- 支援事務操作,具有事務 ACID 隔離特性,默認的隔離級別是
可重複讀(repetable-read)、通過MVCC(並發版本控制)來實現的。能夠解決臟讀和不可重複讀的問題。 - InnoDB 支援外鍵操作。
- InnoDB 默認的鎖粒度
行級鎖,並發性能比較好,會發生死鎖的情況。 - 和 MyISAM 一樣的是,InnoDB 存儲引擎也有
.frm文件存儲表結構定義,但是不同的是,InnoDB 的表數據與索引數據是存儲在一起的,都位於 B+ 數的葉子節點上,而 MyISAM 的表數據和索引數據是分開的。 - InnoDB 有安全的日誌文件,這個日誌文件用於恢復因資料庫崩潰或其他情況導致的數據丟失問題,保證數據的一致性。
- InnoDB 和 MyISAM 支援的索引類型相同,但具體實現因為文件結構的不同有很大差異。
- 增刪改查性能方面,果執行大量的增刪改操作,推薦使用 InnoDB 存儲引擎,它在刪除操作時是對行刪除,不會重建表。
MEMORY
MEMORY 存儲引擎使用存在記憶體中的內容來創建表。每個 MEMORY 表實際只對應一個磁碟文件,格式是 .frm。 MEMORY 類型的表訪問速度很快,因為其數據是存放在記憶體中。默認使用 HASH 索引。
MERGE
MERGE 存儲引擎是一組 MyISAM 表的組合,MERGE 表本身沒有數據,對 MERGE 類型的表進行查詢、更新、刪除的操作,實際上是對內部的 MyISAM 表進行的。MERGE 表在磁碟上保留兩個文件,一個是 .frm 文件存儲表定義、一個是 .MRG 文件存儲 MERGE 表的組成等。
選擇合適的存儲引擎
在實際開發過程中,我們往往會根據應用特點選擇合適的存儲引擎。
- MyISAM:如果應用程式通常以檢索為主,只有少量的插入、更新和刪除操作,並且對事物的完整性、並發程度不是很高的話,通常建議選擇 MyISAM 存儲引擎。
- InnoDB:如果使用到外鍵、需要並發程度較高,數據一致性要求較高,那麼通常選擇 InnoDB 引擎,一般互聯網大廠對並發和數據完整性要求較高,所以一般都使用 InnoDB 存儲引擎。
- MEMORY:MEMORY 存儲引擎將所有數據保存在記憶體中,在需要快速定位下能夠提供及其迅速的訪問。MEMORY 通常用於更新不太頻繁的小表,用於快速訪問取得結果。
- MERGE:MERGE 的內部是使用 MyISAM 表,MERGE 表的優點在於可以突破對單個 MyISAM 表大小的限制,並且通過將不同的表分布在多個磁碟上, 可以有效地改善 MERGE 表的訪問效率。
選擇合適的數據類型
我們會經常遇見的一個問題就是,在建表時如何選擇合適的數據類型,通常選擇合適的數據類型能夠提高性能、減少不必要的麻煩,下面我們就來一起探討一下,如何選擇合適的數據類型。
CHAR 和 VARCHAR 的選擇
char 和 varchar 是我們經常要用到的兩個存儲字元串的數據類型,char 一般存儲定長的字元串,它屬於固定長度的字元類型,比如下面
| 值 | char(5) | 存儲位元組 |
|---|---|---|
| ” | ‘ ‘ | 5個位元組 |
| ‘cx’ | ‘cx ‘ | 5個位元組 |
| ‘cxuan’ | ‘cxuan’ | 5個位元組 |
| ‘cxuan007’ | ‘cxuan’ | 5個位元組 |
可以看到,不管你的值寫的是什麼,一旦指定了 char 字元的長度,如果你的字元串長度不夠指定字元的長度的話,那麼就用空格來填補,如果超過字元串長度的話,只存儲指定字元長度的字元。
這裡注意一點:如果 MySQL 使用了非
嚴格模式的話,上面表格最後一行是可以存儲的。如果 MySQL 使用了嚴格模式的話,那麼表格上面最後一行存儲會報錯。
如果使用了 varchar 字元類型,我們來看一下例子
| 值 | varchar(5) | 存儲位元組 |
|---|---|---|
| ” | ” | 1個位元組 |
| ‘cx’ | ‘cx ‘ | 3個位元組 |
| ‘cxuan’ | ‘cxuan’ | 6個位元組 |
| ‘cxuan007’ | ‘cxuan’ | 6個位元組 |
可以看到,如果使用 varchar 的話,那麼存儲的位元組將根據實際的值進行存儲。你可能會疑惑為什麼 varchar 的長度是 5 ,但是卻需要存儲 3 個位元組或者 6 個位元組,這是因為使用 varchar 數據類型進行存儲時,默認會在最後增加一個字元串長度,佔用1個位元組(如果列聲明的長度超過255,則使用兩個位元組)。varchar 不會填充空餘的字元串。
一般使用 char 來存儲定長的字元串,比如身份證號、手機號、郵箱等;使用 varchar 來存儲不定長的字元串。由於 char 長度是固定的,所以它的處理速度要比 VARCHAR 快很多,但是缺點是浪費存儲空間,但是隨著 MySQL 版本的不斷演進,varchar 數據類型的性能也在不斷改進和提高,所以在許多應用中,VARCHAR 類型更多的被使用。
在 MySQL 中,不同的存儲引擎對 CHAR 和 VARCHAR 的使用原則也有不同
- MyISAM:建議使用固定長度的數據列替代可變長度的數據列,也就是 CHAR
- MEMORY:使用固定長度進行處理、CHAR 和 VARCHAR 都會被當作 CHAR 處理
- InnoDB:建議使用 VARCHAR 類型
TEXT 與 BLOB
一般在保存較少的文本的時候,我們會選擇 CHAR 和 VARCHAR,在保存大數據量的文本時,我們往往選擇 TEXT 和 BLOB;TEXT 和 BLOB 的主要差別是 BLOB 能夠保存二進位數據;而 TEXT 只能保存字元數據,TEXT 往下細分有
- TEXT
- MEDIUMTEXT
- LONGTEXT
BLOB 往下細分有
- BLOB
- MEDIUMBLOB
- LONGBLOB
三種,它們最主要的區別就是存儲文本長度不同和存儲位元組不同,用戶應該根據實際情況選擇滿足需求的最小存儲類型,下面主要對 BLOB 和 TEXT 存在一些問題進行介紹
TEXT 和 BLOB 在刪除數據後會存在一些性能上的問題,為了提高性能,建議使用 OPTIMIZE TABLE 功能對錶進行碎片整理。
也可以使用合成索引來提高文本欄位(BLOB 和 TEXT)的查詢性能。合成索引就是根據大文本(BLOB 和 TEXT)欄位的內容建立一個散列值,把這個值存在對應列中,這樣就能夠根據散列值查找到對應的數據行。一般使用散列演算法比如 md5() 和 SHA1() ,如果散列演算法生成的字元串帶有尾部空格,就不要把它們存在 CHAR 和 VARCHAR 中,下面我們就來看一下這種使用方式
首先創建一張表,表中記錄 blob 欄位和 hash 值

向 cxuan005 中插入數據,其中 hash 值作為 info 的散列值。

然後再插入兩條數據

插入一條 info 為 cxuan005 的數據

如果想要查詢 info 為 cxuan005 的數據,可以通過查詢 hash 列來進行查詢

這是合成索引的例子,如果要對 BLOB 進行模糊查詢的話,就要使用前綴索引。
其他優化 BLOB 和 TEXT 的方式:
- 非必要的時候不要檢索 BLOB 和 TEXT 索引
- 把 BLOB 或 TEXT 列分離到單獨的表中。
浮點數和定點數的選擇
浮點數指的就是含有小數的值,浮點數插入到指定列中超過指定精度後,浮點數會四捨五入,MySQL 中的浮點數指的就是 float 和 double,定點數指的是 decimal,定點數能夠更加精確的保存和顯示數據。下面通過一個示例講解一下浮點數精確性問題
首先創建一個表 cxuan006 ,只為了測試浮點數問題,所以這裡我們選擇的數據類型是 float

然後分別插入兩條數據

然後執行查詢,可以看到查詢出來的兩條數據執行的舍入不同

為了清晰的看清楚浮點數與定點數的精度問題,再來看一個例子

先修改 cxuan006 的兩個欄位為相同的長度和小數位數
然後插入兩條數據

執行查詢操作,可以發現,浮點數相較於定點數來說,會產生誤差

日期類型選擇
在 MySQL 中,用來表示日期類型的有 DATE、TIME、DATETIME、TIMESTAMP,在
這篇文中介紹過了日期類型的區別,我們這裡就不再闡述了。下面主要介紹一下選擇
- TIMESTAMP 和時區相關,更能反映當前時間,如果記錄的日期需要讓不同時區的人使用,最好使用 TIMESTAMP。
- DATE 用於表示年月日,如果實際應用值需要保存年月日的話就可以使用 DATE。
- TIME 用於表示時分秒,如果實際應用值需要保存時分秒的話就可以使用 TIME。
- YEAR 用於表示年份,YEAR 有 2 位(最好使用4位)和 4 位格式的年。 默認是4位。如果實際應用只保存年份,那麼用 1 bytes 保存 YEAR 類型完全可以。不但能夠節約存儲空間,還能提高表的操作效率。
MySQL 字符集
下面來認識一下 MySQL 字符集,簡單來說字符集就是一套文字元號和編碼、比較規則的集合。1960 年美國標準化組織 ANSI 發布了第一個電腦字符集,就是著名的 ASCII(American Standard Code for Information Interchange) 。自從 ASCII 編碼後,每個國家、國際組織都研究了一套自己的字符集,比如 ISO-8859-1、GBK 等。
但是每個國家都使用自己的字符集為移植性帶來了很大的困難。所以,為了統一字元編碼,國際標準化組織(ISO) 指定了統一的字元標準 – Unicode 編碼,它容納了幾乎所有的字元編碼。下面是一些常見的字元編碼
| 字符集 | 是否定長 | 編碼方式 |
|---|---|---|
| ASCII | 是 | 單位元組 7 位編碼 |
| ISO-8859-1 | 是 | 單位元組 8 位編碼 |
| GBK | 是 | 雙位元組編碼 |
| UTF-8 | 否 | 1 – 4 位元組編碼 |
| UTF-16 | 否 | 2 位元組或 4 位元組編碼 |
| UTF-32 | 是 | 4 位元組編碼 |
對資料庫來說,字符集是很重要的,因為資料庫存儲的數據大多數都是各種文字,字符集對資料庫的存儲、性能、系統的移植來說都非常重要。
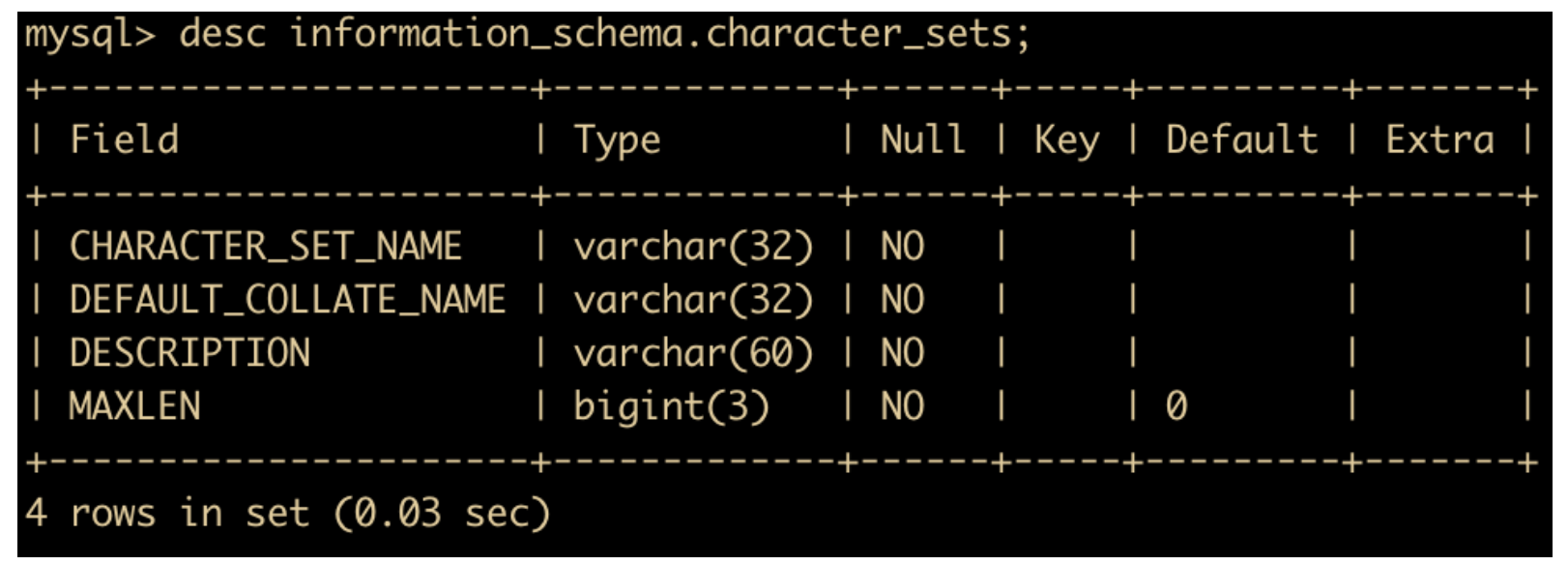
MySQL 支援多種字符集,可以使用 show character set; 來查看所有可用的字符集

或者使用
select character_set_name, default_collate_name, description, maxlen from information_schema.character_sets;
來查看。
使用 information_schema.character_set 來查看字符集和校對規則。