深入理解React:diff 演算法
目錄
- 序言
- React 的核心思想
- 傳統 diff 演算法
- React diff
- 兩個假設
- 三個策略
- diff 具體優化
- tree diff
- component diff
- element diff
- 小結
- 參考
1.序言
此篇文章所討論的是 React 16 以前的 Diff 演算法。而 React 16 啟用了全新的架構 Fiber,相應的 Diff 演算法也有所改變,不在這篇文章的討論範圍內。研究 React 的 Diff 演算法重在理解其思想,具體實現其次。
2.React 的核心思想
React 最為核心的就是 Virtual DOM 和 Diff 演算法。React 在記憶體中維護一顆虛擬 DOM 樹,當數據發生改變時(state & props),會自動的更新虛擬 DOM,獲得一個新的虛擬 DOM 樹,然後通過 Diff 演算法,比較新舊虛擬 DOM 樹,找出最小的有變化的部分,將這個變化的部分(Patch)加入隊列,最終批量的更新這些 Patch 到實際的 DOM 中。
3.傳統 diff 演算法
將一顆 Tree 通過最小操作步數映射為另一顆 Tree,這種演算法稱之為 Tree Edit Distance(樹編輯距離)。如圖:
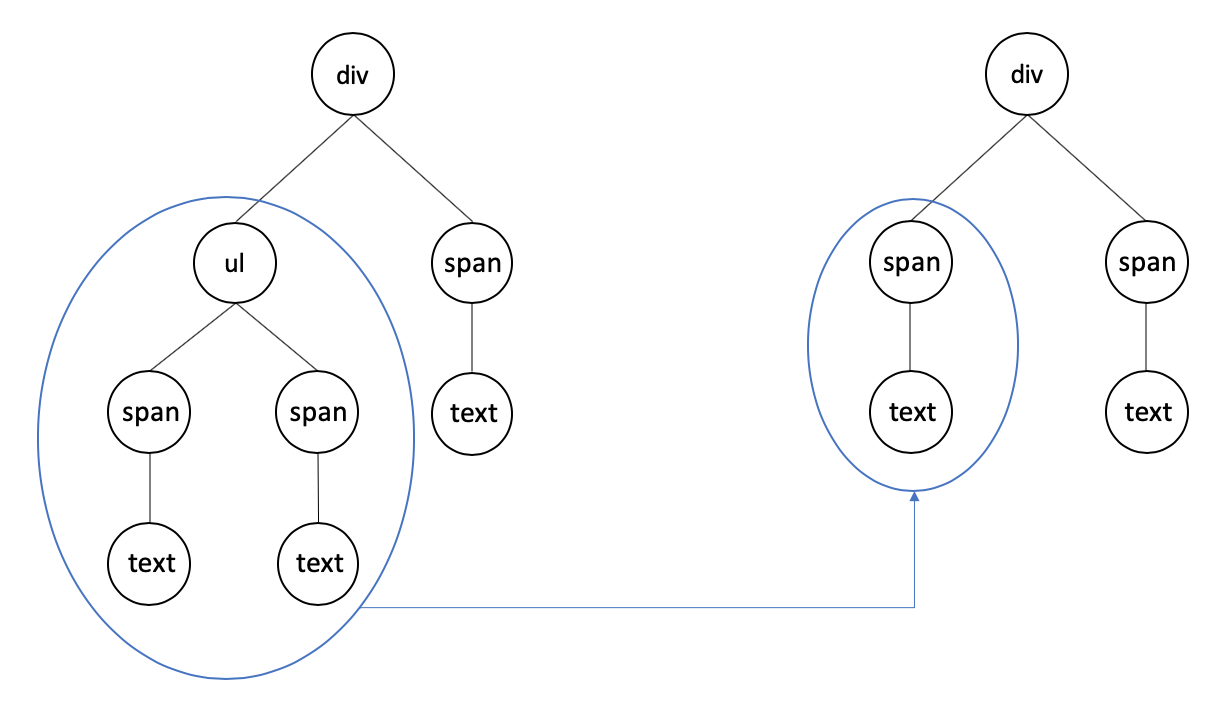
上圖中,最小操作步數(編輯距離)為 3:
- 刪除 ul 節點
- 添加 span 節點
- 添加 text 節點
而 Tree Edit Distance 演算法從 1979 年到 2011年,經過了30多年的發展演變,其時間複雜度最終被優化到 O(n^3),其發展歷程大致如下(n 是樹中節點的總數):
- 1979年,Tai 提出了次個非冪級複雜度演算法,時間複雜度為 O(m3*n3)
- 1989年,Zhang and Shasha 將 Tai 的演算法進行優化,時間複雜度為 O(m2*n2)
- 1998年,Klein 將 Zhang and Shasha 的演算法再次優化,時間複雜度為 O(n^2*m*log(m))
- 2009年,Demiane 提出最壞情況下的計算公式,將時間複雜度控制在 O(n^2*m*(1+log(m/n)))
- 2011年,Pawlik and N.Augsten 提出適用於所有形狀的樹的演算法,並將時間複雜度控制在 O(n^3)
這裡不會展開討論 Tree Edit Distance 演算法的具體實現和原理,有興趣可以直接看這篇論文 A Robust Algorithm for the Tree Edit Distance
4.React diff
傳統 diff 演算法其時間複雜度最優解是 O(n^3),那麼如果有 1000 個節點,則一次 diff 就將進行 10 億次比較,這顯然無法達到高性能的要求。而 React 通過大膽的假設,並基於假設提出相關策略,成功的將 O(n^3) 複雜度的問題轉化為 O(n) 複雜度的問題。
(1)兩個假設
為了優化 diff 演算法,React 提出了兩個假設:
- 兩個不同類型的元素會產生出不同的樹
- 開發者可以通過
keyprop 來暗示哪些子元素在不同的渲染下能保持穩定
(2)三個策略
基於這上述兩個假設,React 針對性的提出了三個策略以對 diff 演算法進行優化:
- Web UI 中 DOM 節點跨層級的移動操作特別少,可以忽略不計
- 擁有相同類型的兩個組件將會生成相似的樹形結構,擁有不同類型的兩個組件將會生成不同樹形結構
- 對於同一層級的一組子節點,它們可以通過唯一 key 進行區分
(3)diff 具體優化
基於上述三個策略,React 分別對以下三個部分進行了 diff 演算法優化
- tree diff
- component diff
- element diff
tree diff
React 只對虛擬 DOM 樹進行分層比較,不考慮節點的跨層級比較。如下圖:
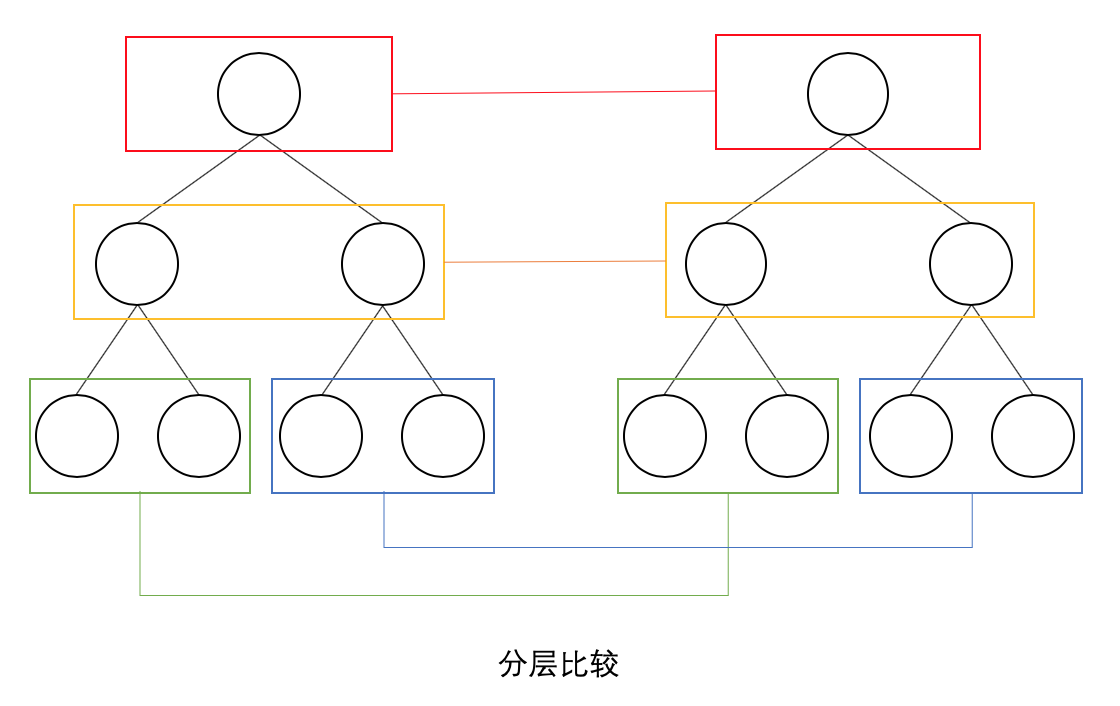
如上圖,React 通過 updateDepth 對虛擬 Dom 樹進行層級控制,只會對相同顏色框內的節點進行比較,根據對比結果,進行節點的新增和刪除。如此只需要遍歷一次虛擬 Dom 樹,就可以完成整個的對比。
如果發生了跨層級的移動操作,如下圖:
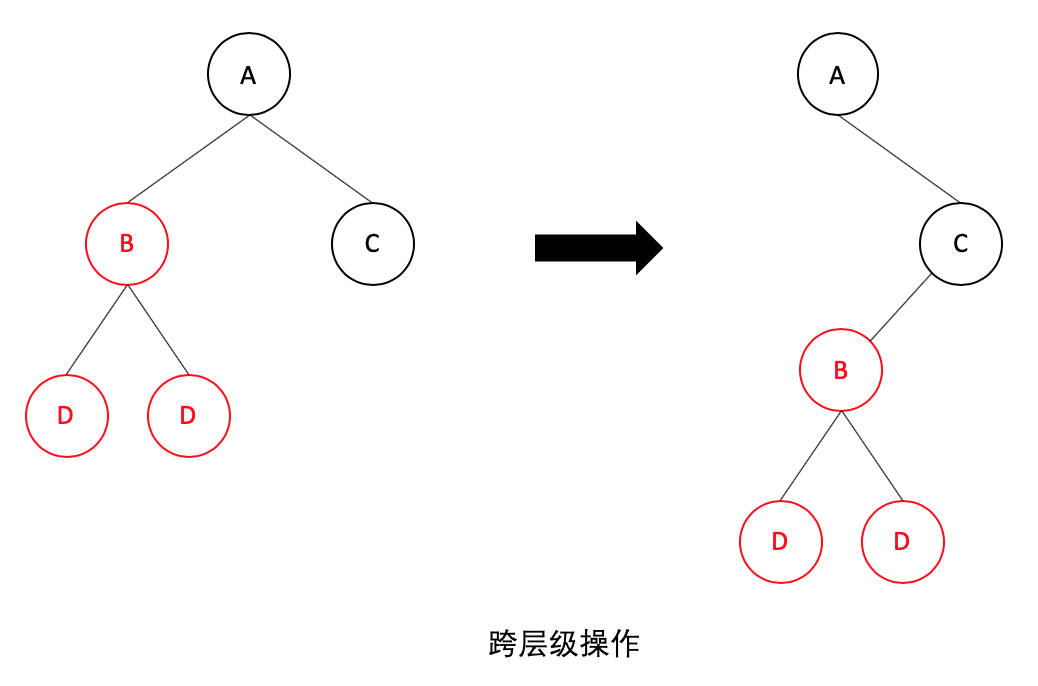
通過分層比較可知,React 並不會復用 B 節點及其子節點,而是會直接刪除 A 節點下的 B 節點,然後再在 C 節點下創建新的 B 節點及其子節點。因此,如果發生跨級操作,React 是不能復用已有節點,可能會導致 React 進行大量重新創建操作,這會影響性能。所以 React 官方推薦盡量避免跨層級的操作。
component diff
React 是基於組件構建的,對於組件間的比較所採用的策略如下:
- 如果是同類型組件,首先使用
shouldComponentUpdate()方法判斷是否需要進行比較,如果返回true,才比較對應的虛擬 DOM 節點,否則不需要比較 - 如果是不同類型的組件,則將該組件判斷為 dirty component,從而替換整個組件下的所有子節點

如上圖,雖然組件 C 和組件 H 結構相似,但類型不同,React 不會進行比較,會直接刪除組件 C,創建組件 H。
從上述 component diff 策略可以知道:
- 對於不同類型的組件,默認不需要進行比較操作,直接重新創建。
- 對於同類型組件, 通過讓開發人員自定義
shouldComponentUpdate()方法來進行比較優化,減少組件不必要的比較。如果沒有自定義,shouldComponentUpdate()方法默認返回true,默認每次組件發生數據(state & props)變化時,都會進行比較。
element diff
element diff 涉及三種操作:移動、創建、刪除。對於同一層級的子節點,對於是否使用 key 分別進行討論。
對於不使用 key 的情況,如下圖:

React 對新老同一層級的子節點對比,發現新集合中的 B 不等於老集合中的 A,於是刪除 A,創建 B,依此類推,直到刪除 D,創建 C。這會使得相同的節點不能復用,出現頻繁的刪除和創建操作,從而影響性能。
對於使用 key 的情況,如下圖:
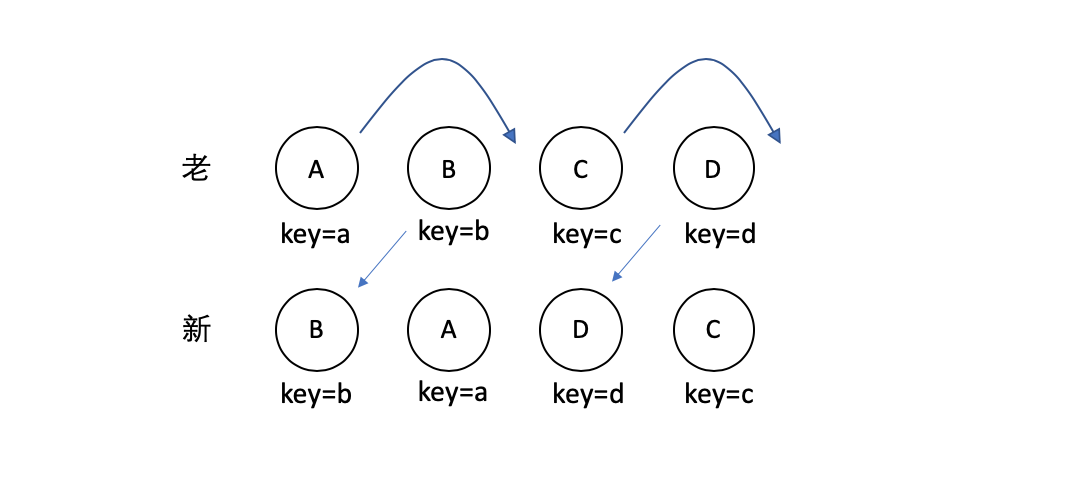
React 首先會對新集合進行遍歷,通過唯一 key 來判斷老集合中是否存在相同的節點,如果沒有則創建,如果有的,則判斷是否需要進行移動操作。並且 React 對於移動操作也採用了比較高效的演算法,使用了一種順序優化手段,這裡不做詳細討論。
從上述可知,element diff 就是通過唯一 key 來進行 diff 優化,通過復用已有的節點,減少節點的刪除和創建操作。
5.小結
React 通過大膽的假設,制定對應的 diff 策略,將 O(n3) 複雜度的問題轉換成 O(n) 複雜度的問題
- 通過分層對比策略,對 tree diff 進行演算法優化
- 通過相同類生成相似樹形結構,不同類生成不同樹形結構以及
shouldComponentUpdate策略,對 component diff 進行演算法優化 - 通過設置唯一 key 策略,對 element diff 進行演算法優化
6.參考
Deep In React之淺談 React Fiber 架構(一)
react16的diff演算法相比於react15有什麼改動?
React 源碼剖析系列 - 不可思議的 react diff


