Mysql高手系列 – 第22篇:mysql索引原理詳解(高手必備技能)
- 2019 年 10 月 12 日
- 筆記
Mysql系列的目標是:通過這個系列從入門到全面掌握一個高級開發所需要的全部技能。
歡迎大家加我微信itsoku一起交流java、演算法、資料庫相關技術。
這是Mysql系列第22篇。
背景
使用mysql最多的就是查詢,我們迫切的希望mysql能查詢的更快一些,我們經常用到的查詢有:
- 按照id查詢唯一一條記錄
- 按照某些個欄位查詢對應的記錄
- 查找某個範圍的所有記錄(between and)
- 對查詢出來的結果排序
mysql的索引的目的是使上面的各種查詢能夠更快。
預備知識
什麼是索引?
上一篇中有詳細的介紹,可以過去看一下:什麼是索引?
索引的本質:通過不斷地縮小想要獲取數據的範圍來篩選出最終想要的結果,同時把隨機的事件變成順序的事件,也就是說,有了這種索引機制,我們可以總是用同一種查找方式來鎖定數據。
磁碟中數據的存取
以機械硬碟來說,先了解幾個概念。
扇區:磁碟存儲的最小單位,扇區一般大小為512Byte。
磁碟塊:文件系統與磁碟交互的的最小單位(電腦系統讀寫磁碟的最小單位),一個磁碟塊由連續幾個(2^n)扇區組成,塊一般大小一般為4KB。
磁碟讀取數據:磁碟讀取數據靠的是機械運動,每次讀取數據花費的時間可以分為尋道時間、旋轉延遲、傳輸時間三個部分,尋道時間指的是磁臂移動到指定磁軌所需要的時間,主流磁碟一般在5ms以下;旋轉延遲就是我們經常聽說的磁碟轉速,比如一個磁碟7200轉,表示每分鐘能轉7200次,也就是說1秒鐘能轉120次,旋轉延遲就是1/120/2 = 4.17ms;傳輸時間指的是從磁碟讀出或將數據寫入磁碟的時間,一般在零點幾毫秒,相對於前兩個時間可以忽略不計。那麼訪問一次磁碟的時間,即一次磁碟IO的時間約等於5+4.17 = 9ms左右,聽起來還挺不錯的,但要知道一台500 -MIPS的機器每秒可以執行5億條指令,因為指令依靠的是電的性質,換句話說執行一次IO的時間可以執行40萬條指令,資料庫動輒十萬百萬乃至千萬級數據,每次9毫秒的時間,顯然是個災難。
mysql中的頁
mysql中和磁碟交互的最小單位稱為頁,頁是mysql內部定義的一種數據結構,默認為16kb,相當於4個磁碟塊,也就是說mysql每次從磁碟中讀取一次數據是16KB,要麼不讀取,要讀取就是16KB,此值可以修改的。
數據檢索過程
我們對數據存儲方式不做任何優化,直接將資料庫中表的記錄存儲在磁碟中,假如某個表只有一個欄位,為int類型,int佔用4個byte,每個磁碟塊可以存儲1000條記錄,100萬的記錄需要1000個磁碟塊,如果我們需要從這100萬記錄中檢索所需要的記錄,需要讀取1000個磁碟塊的數據(需要1000次io),每次io需要9ms,那麼1000次需要9000ms=9s,100條數據隨便一個查詢就是9秒,這種情況我們是無法接受的,顯然是不行的。
我們迫切的需求是什麼?
我們迫切需要這樣的數據結構和演算法:
- 需要一種數據存儲結構:當從磁碟中檢索數據的時候能,夠減少磁碟的io次數,最好能夠降低到一個穩定的常量值
- 需要一種檢索演算法:當從磁碟中讀取磁碟塊的數據之後,這些塊中可能包含多條記錄,這些記錄被載入到記憶體中,那麼需要一種演算法能夠快速從記憶體多條記錄中快速檢索出目標數據
我們來找找,看是否能夠找到這樣的演算法和數據結構。
我們看一下常見的檢索演算法和數據結構。
循環遍歷查找
從一組無序的數據中查找目標數據,常見的方法是遍歷查詢,n條數據,時間複雜度為O(n),最快需要1次,最壞的情況需要n次,查詢效率不穩定。
二分法查找
二分法查找也稱為折半查找,用於在一個有序數組中快速定義某一個需要查找的數據。
原理是:
先將一組無序的數據排序(升序或者降序)之後放在數組中,此處用升序來舉例說明:用數組中間位置的數據A和需要查找的數據F對比,如果A=F,則結束查找;如果A<F,則將查找的範圍縮小至數組中A數據右邊的部分;如果A>F,則將查找範圍縮小至數組中A數據左邊的部分,繼續按照上面的方法直到找到F為止。
示例:
從下列有序數字中查找數字9,過程如下
[1,2,3,4,5,6,7,8,9]
第1次查找:[1,2,3,4,5,6,7,8,9]中間位置值為5,9>5,將查找範圍縮小至5右邊的部分:[6、7、8、9]
第2次查找:[6、7、8、9]中間值為8,9>8 ,將範圍縮小至8右邊部分:[9]
第3次查找:在[9]中查找9,找到了。
可以看到查找速度是相當快的,每次查找都會使範圍減半,如果我們採用順序查找,上面數據最快需要1次,最多需要9次,而二分法查找最多只需要3次,耗時時間也比較穩定。
二分法查找時間複雜度是:O(logN)(N為數據量),100萬數據查找最多只需要20次(2^20=1048576)
二分法查找數據的優點:定位數據非常快,前提是:目標數組是有序的。
有序數組
如果我們將mysql中表的數據以有序數組的方式存儲在磁碟中,那麼我們定位數據步驟是:
- 取出目標表的所有數據,存放在一個有序數組中
- 如果目標表的數據量非常大,從磁碟中載入到記憶體中需要的記憶體也非常大
步驟取出所有數據耗費的io次數太多,步驟2耗費的記憶體空間太大,還有新增數據的時候,為了保證數組有序,插入數據會涉及到數組內部數據的移動,也是比較耗時的,顯然用這種方式存儲數據是不可取的。
鏈表
鏈表相當於在每個節點上增加一些指針,可以和前面或者後面的節點連接起來,就像一列火車一樣,每節車廂相當於一個節點,車廂內部可以存儲數據,每個車廂和下一節車廂相連。
鏈表分為單鏈表和雙向鏈表。
單鏈表
每個節點中有持有指向下一個節點的指針,只能按照一個方向遍歷鏈表,結構如下:
//單項鏈表 class Node1{ private Object data;//存儲數據 private Node1 nextNode;//指向下一個節點 }雙向鏈表
每個節點中兩個指針,分別指向當前節點的上一個節點和下一個節點,結構如下:
//雙向鏈表 class Node2{ private Object data;//存儲數據 private Node1 prevNode;//指向上一個節點 private Node1 nextNode;//指向下一個節點 }鏈表的優點:
- 可以快速定位到上一個或者下一個節點
- 可以快速刪除數據,只需改變指針的指向即可,這點比數組好
鏈表的缺點:
- 無法向數組那樣,通過下標隨機訪問數據
- 查找數據需從第一個節點開始遍歷,不利於數據的查找,查找時間和無需數據類似,需要全遍歷,最差時間是O(N)
二叉查找樹
二叉樹是每個結點最多有兩個子樹的樹結構,通常子樹被稱作「左子樹」(left subtree)和「右子樹」(right subtree)。二叉樹常被用於實現二叉查找樹和二叉堆。二叉樹有如下特性:
1、每個結點都包含一個元素以及n個子樹,這裡0≤n≤2。
2、左子樹和右子樹是有順序的,次序不能任意顛倒,左子樹的值要小於父結點,右子樹的值要大於父結點。
數組[20,10,5,15,30,25,35]使用二叉查找樹存儲如下:
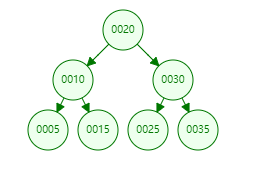
每個節點上面有兩個指針(left,rigth),可以通過這2個指針快速訪問左右子節點,檢索任何一個數據最多只需要訪問3個節點,相當於訪問了3次數據,時間為O(logN),和二分法查找效率一樣,查詢數據還是比較快的。
但是如果我們插入數據是有序的,如[5,10,15,20,30,25,35],那麼結構就變成下面這樣:
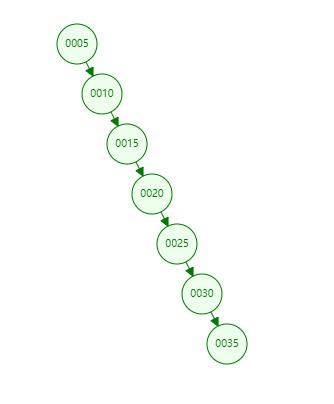
二叉樹退化為了一個鏈表結構,查詢數據最差就變為了O(N)。
二叉樹的優缺點:
- 查詢數據的效率不穩定,若樹左右比較平衡的時,最差情況為O(logN),如果插入數據是有序的,退化為了鏈表,查詢時間變成了O(N)
- 數據量大的情況下,會導致樹的高度變高,如果每個節點對應磁碟的一個塊來存儲一條數據,需io次數大幅增加,顯然用此結構來存儲數據是不可取的
平衡二叉樹(AVL樹)
平衡二叉樹是一種特殊的二叉樹,所以他也滿足前面說到的二叉查找樹的兩個特性,同時還有一個特性:
它的左右兩個子樹的高度差的絕對值不超過1,並且左右兩個子樹都是一棵平衡二叉樹。
平衡二叉樹相對於二叉樹來說,樹的左右比較平衡,不會出現二叉樹那樣退化成鏈表的情況,不管怎麼插入數據,最終通過一些調整,都能夠保證樹左右高度相差不大於1。
這樣可以讓查詢速度比較穩定,查詢中遍歷節點控制在O(logN)範圍內
如果數據都存儲在記憶體中,採用AVL樹來存儲,還是可以的,查詢效率非常高。不過我們的數據是存在磁碟中,用過採用這種結構,每個節點對應一個磁碟塊,數據量大的時候,也會和二叉樹一樣,會導致樹的高度變高,增加了io次數,顯然用這種結構存儲數據也是不可取的。
B-樹
B杠樹,千萬不要讀作B減樹了,B-樹在是平衡二叉樹上進化來的,前面介紹的幾種樹,每個節點上面只有一個元素,而B-樹節點中可以放多個元素,主要是為了降低樹的高度。
一棵m階的B-Tree有如下特性【特徵描述的有點繞,看不懂的可以跳過,看後面的圖】:
- 每個節點最多有m個孩子,m稱為b樹的階
- 除了根節點和葉子節點外,其它每個節點至少有Ceil(m/2)個孩子
- 若根節點不是葉子節點,則至少有2個孩子
- 所有葉子節點都在同一層,且不包含其它關鍵字資訊
- 每個非終端節點包含n個關鍵字(健值)資訊
- 關鍵字的個數n滿足:ceil(m/2)-1 <= n <= m-1
- ki(i=1,…n)為關鍵字,且關鍵字升序排序
- Pi(i=1,…n)為指向子樹根節點的指針。P(i-1)指向的子樹的所有節點關鍵字均小於ki,但都大於k(i-1)
B-Tree結構的數據可以讓系統高效的找到數據所在的磁碟塊。為了描述B-Tree,首先定義一條記錄為一個二元組[key, data] ,key為記錄的鍵值,對應表中的主鍵值,data為一行記錄中除主鍵外的數據。對於不同的記錄,key值互不相同。
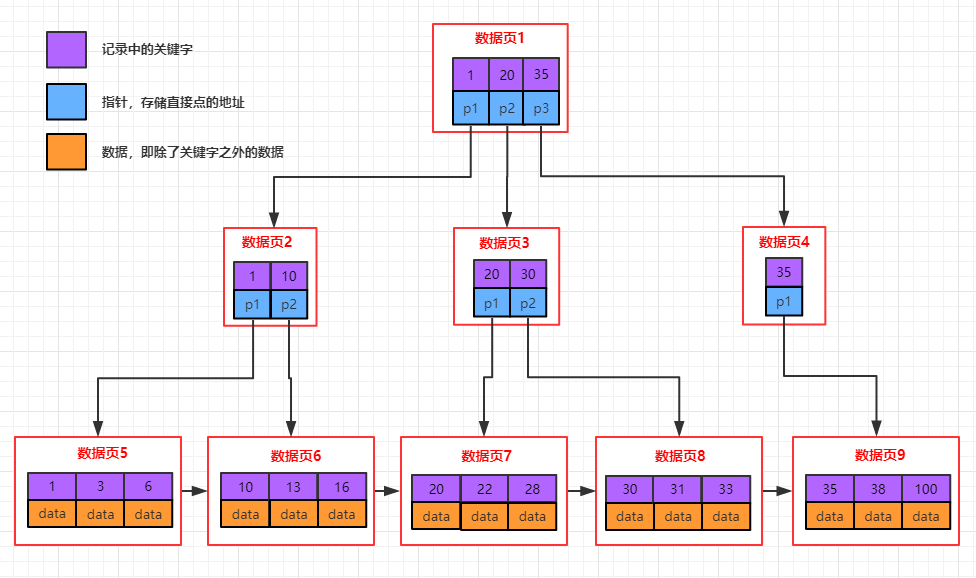
B-Tree中的每個節點根據實際情況可以包含大量的關鍵字資訊和分支,如下圖所示為一個3階的B-Tree:

每個節點佔用一個盤塊的磁碟空間,一個節點上有兩個升序排序的關鍵字和三個指向子樹根節點的指針,指針存儲的是子節點所在磁碟塊的地址。兩個鍵將數據劃分成的三個範圍域,對應三個指針指向的子樹的數據的範圍域。以根節點為例,關鍵字為17和35,P1指針指向的子樹的數據範圍為小於17,P2指針指向的子樹的數據範圍為17~35,P3指針指向的子樹的數據範圍為大於35。
模擬查找關鍵字29的過程:
- 根據根節點找到磁碟塊1,讀入記憶體。【磁碟I/O操作第1次】
- 比較關鍵字29在區間(17,35),找到磁碟塊1的指針P2
- 根據P2指針找到磁碟塊3,讀入記憶體。【磁碟I/O操作第2次】
- 比較關鍵字29在區間(26,30),找到磁碟塊3的指針P2
- 根據P2指針找到磁碟塊8,讀入記憶體。【磁碟I/O操作第3次】
- 在磁碟塊8中的關鍵字列表中找到關鍵字29
分析上面過程,發現需要3次磁碟I/O操作,和3次記憶體查找操作,由於記憶體中的關鍵字是一個有序表結構,可以利用二分法快速定位到目標數據,而3次磁碟I/O操作是影響整個B-Tree查找效率的決定因素。
B-樹相對於avl樹,通過在節點中增加節點內部數據的個數來減少磁碟的io操作。
上面我們說過mysql是採用頁方式來讀寫數據,每頁是16KB,我們用B-樹來存儲mysql的記錄,每個節點對應mysql中的一頁(16KB),假如每行記錄加上樹節點中的1個指針佔160Byte,那麼每個節點可以存儲1000(16KB/160byte)條數據,樹的高度為3的節點大概可以存儲(第一層1000+第二層1000^2+第三層1000^3)10億條記錄,是不是非常驚訝,一個高度為3個B-樹大概可以存儲10億條記錄,我們從10億記錄中查找數據只需要3次io操作可以定位到目標數據所在的頁,而頁內部的數據又是有序的,然後將其載入到記憶體中用二分法查找,是非常快的。
可以看出使用B-樹定位某個值還是很快的(10億數據中3次io操作+記憶體中二分法),但是也是有缺點的:B-不利於範圍查找,比如上圖中我們需要查找[15,36]區間的數據,需要訪問7個磁碟塊(1/2/7/3/8/4/9),io次數又上去了,範圍查找也是我們經常用到的,所以b-樹也不太適合在磁碟中存儲需要檢索的數據。
b+樹
先看個b+樹結構圖:
b+樹的特徵
- 每個結點至多有m個子女
- 除根結點外,每個結點至少有[m/2]個子女,根結點至少有兩個子女
- 有k個子女的結點必有k個關鍵字
- 父節點中持有訪問子節點的指針
- 父節點的關鍵字在子節點中都存在(如上面的1/20/35在每層都存在),要麼是最小值,要麼是最大值,如果節點中關鍵字是升序的方式,父節點的關鍵字是子節點的最小值
- 最底層的節點是葉子節點
- 除葉子節點之外,其他節點不保存數據,只保存關鍵字和指針
- 葉子節點包含了所有數據的關鍵字以及data,葉子節點之間用鏈表連接起來,可以非常方便的支援範圍查找
b+樹與b-樹的幾點不同
- b+樹中一個節點如果有k個關鍵字,最多可以包含k個子節點(k個關鍵字對應k個指針);而b-樹對應k+1個子節點(多了一個指向子節點的指針)
- b+樹除葉子節點之外其他節點值存儲關鍵字和指向子節點的指針,而b-樹還存儲了數據,這樣同樣大小情況下,b+樹可以存儲更多的關鍵字
- b+樹葉子節點中存儲了所有關鍵字及data,並且多個節點用鏈表連接,從上圖中看子節點中數據從左向右是有序的,這樣快速可以支撐範圍查找(先定位範圍的最大值和最小值,然後子節點中依靠鏈表遍歷範圍數據)
B-Tree和B+Tree該如何選擇?
- B-Tree因為非葉子結點也保存具體數據,所以在查找某個關鍵字的時候找到即可返回。而B+Tree所有的數據都在葉子結點,每次查找都得到葉子結點。所以在同樣高度的B-Tree和B+Tree中,B-Tree查找某個關鍵字的效率更高。
- 由於B+Tree所有的數據都在葉子結點,並且結點之間有指針連接,在找大於某個關鍵字或者小於某個關鍵字的數據的時候,B+Tree只需要找到該關鍵字然後沿著鏈表遍歷就可以了,而B-Tree還需要遍歷該關鍵字結點的根結點去搜索。
- 由於B-Tree的每個結點(這裡的結點可以理解為一個數據頁)都存儲主鍵+實際數據,而B+Tree非葉子結點只存儲關鍵字資訊,而每個頁的大小有限是有限的,所以同一頁能存儲的B-Tree的數據會比B+Tree存儲的更少。這樣同樣總量的數據,B-Tree的深度會更大,增大查詢時的磁碟I/O次數,進而影響查詢效率。
Mysql的存儲引擎和索引
mysql內部索引是由不同的引擎實現的,主要說一下InnoDB和MyISAM這兩種引擎中的索引,這兩種引擎中的索引都是使用b+樹的結構來存儲的。
InnoDB中的索引
Innodb中有2種索引:主鍵索引(聚集索引)、輔助索引(非聚集索引)。
主鍵索引:每個表只有一個主鍵索引,葉子節點同時保存了主鍵的值也數據記錄。
輔助索引:葉子節點保存了索引欄位的值以及主鍵的值。
MyISAM引擎中的索引
不管是主鍵索引還是輔助索引結構都是一樣的,葉子節點保存了索引欄位的值以及數據記錄的地址。
如下圖:
有一張表,Id作為主索引,Name作為輔助索引。
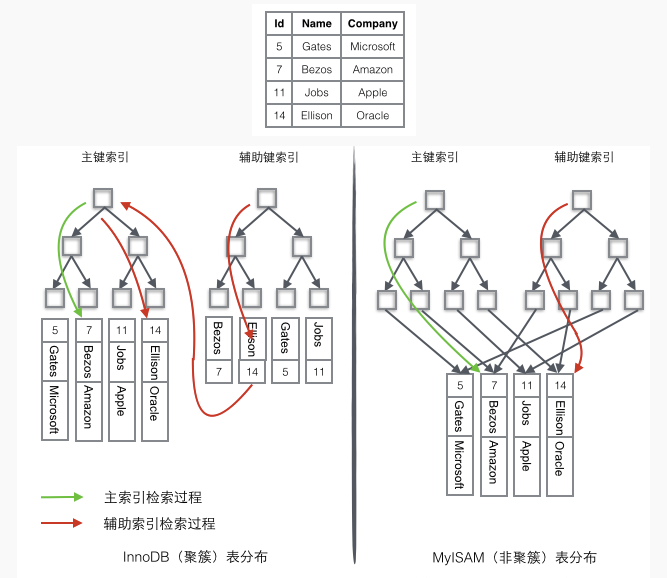
InnoDB數據檢索過程
如果需要查詢id=14的數據,只需要在左邊的主鍵索引中檢索就可以了。
如果需要搜索name=’Ellison’的數據,需要2步:
- 先在輔助索引中檢索到name=’Ellison’的數據,獲取id為14
- 再到主鍵索引中檢索id為14的記錄
輔助索引這個查詢過程在mysql中叫做回表。
MyISAM數據檢索過程
- 在索引中找到對應的關鍵字,獲取關鍵字對應的記錄的地址
- 通過記錄的地址查找到對應的數據記錄
我們用的最多的是innodb存儲引擎,所以此處主要說一下innodb索引的情況,innodb中最好是採用主鍵查詢,這樣只需要一次索引,如果使用輔助索引檢索,涉及到回表操作,比主鍵查詢要耗時一些。
innodb中輔助索引為什麼不像myisam那樣存儲記錄的地址?
表中的數據發生變更的時候,會影響其他記錄地址的變化,如果輔助索引中記錄數據的地址,此時會受影響,而主鍵的值一般是很少更新的,當頁中的記錄發生地址變更的時候,對輔助索引是沒有影響的。
我們來看一下mysql中頁的結構,頁是真正存儲記錄的地方,對應B+樹中的一個節點,也是mysql中讀寫數據的最小單位,頁的結構設計也是相當有水平的,能夠加快數據的查詢。
頁結構
mysql中頁是innodb中存儲數據的基本單位,也是mysql中管理數據的最小單位,和磁碟交互的時候都是以頁來進行的,默認是16kb,mysql中採用b+樹存儲數據,頁相當於b+樹中的一個節點。
頁的結構如下圖:
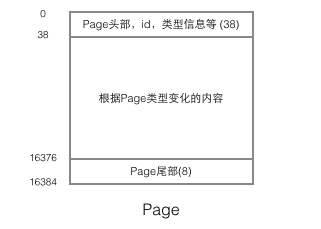
每個Page都有通用的頭和尾,但是中部的內容根據Page的類型不同而發生變化。Page的頭部里有我們關心的一些數據,下圖把Page的頭部詳細資訊顯示出來:
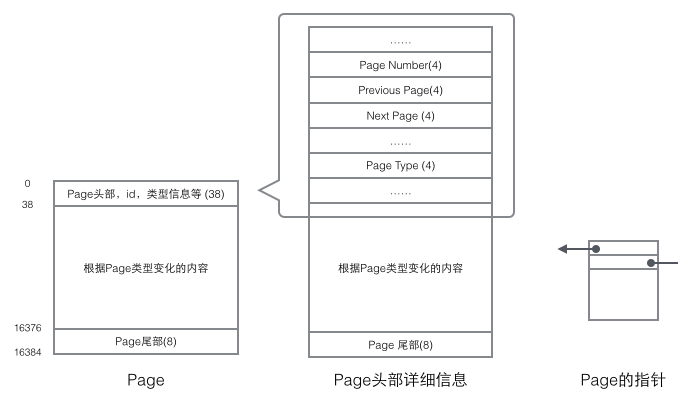
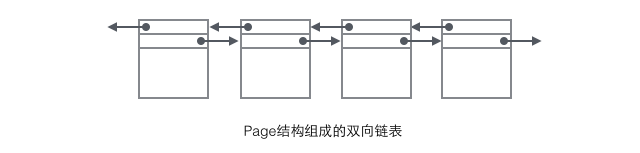
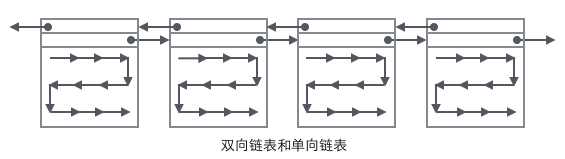
我們重點關注和數據組織結構相關的欄位:Page的頭部保存了兩個指針,分別指向前一個Page和後一個Page,根據這兩個指針我們很容易想像出Page鏈接起來就是一個雙向鏈表的結構,如下圖:
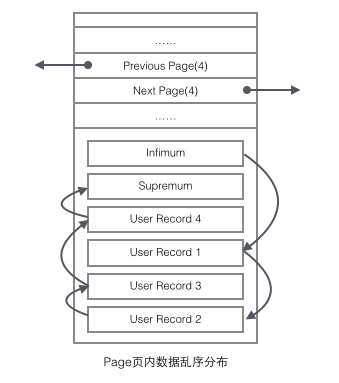
再看看Page的主體內容,我們主要關注行數據和索引的存儲,他們都位於Page的User Records部分,User Records佔據Page的大部分空間,User Records由一條一條的Record組成。在一個Page內部,單鏈表的頭尾由固定內容的兩條記錄來表示,字元串形式的"Infimum"代表開頭,"Supremum"代表結尾,這兩個用來代表開頭結尾的Record存儲在System Records的,Infinum、Supremum和User Records組成了一個單向鏈表結構。最初數據是按照插入的先後順序排列的,但是隨著新數據的插入和舊數據的刪除,數據物理順序會變得混亂,但他們依然通過鏈表的方式保持著邏輯上的先後順序,如下圖:
把User Record的組織形式和若干Page組合起來,就看到了稍微完整的形式。
innodb為了快速查找記錄,在頁中定義了一個稱之為page directory的目錄槽(slots),每個槽位佔用兩個位元組(用於保存指向記錄的地址),page directory中的多個slot組成了一個有序數組(可用於二分法快速定位記錄,向下看),行記錄被Page Directory邏輯的分成了多個塊,塊與塊之間是有序的,能夠加速記錄的查找,如下圖:
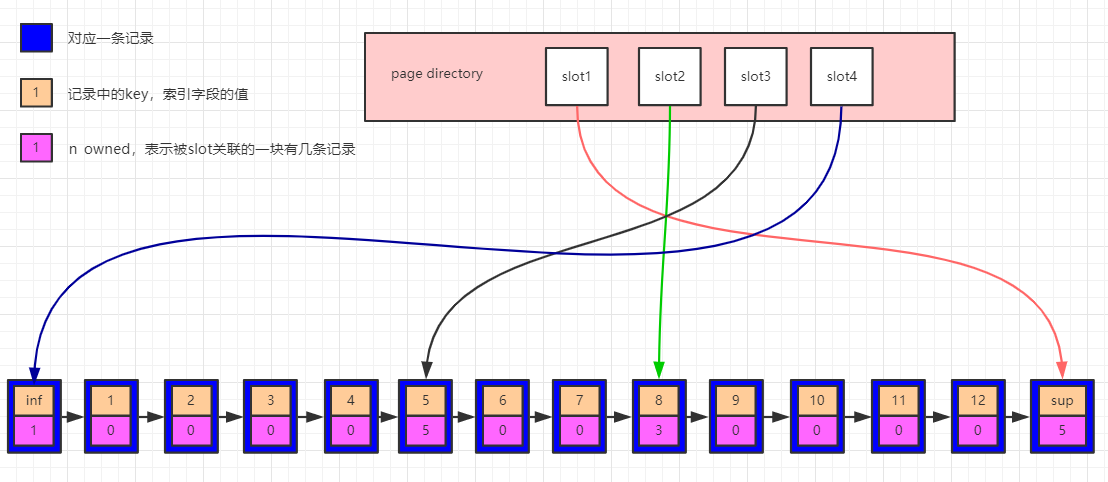
看上圖,每個行記錄的都有一個n_owned的區域(圖中粉色區域),n_owned標識所屬的slot這個這個塊有多少條數據,偽記錄Infimum的n_owned值總是1,記錄Supremum的n_owned的取值範圍為[1,8],其他用戶記錄n_owned的取值範圍[4,8],並且只有每個塊中最大的那條記錄的n_owned才會有值,其他的用戶記錄的n_owned為0。
數據檢索過程
在page中查詢數據的時候,先通過b+樹中查詢方法定位到數據所在的頁,然後將頁內整體載入到記憶體中,通過二分法在page directory中檢索數據,縮小範圍,比如需要檢索7,通過二分法查找到7位於slot2和slot3所指向的記錄中間,然後從slot3指向的記錄5開始向後向後一個個找,可以找到記錄7,如果裡面沒有7,走到slot2向的記錄8結束。
n_owned範圍控制在[4,8]內,能保證每個slot管轄的範圍內數據量控制在[4,8]個,能夠加速目標數據的查找,當有數據插入的時候,page directory為了控制每個slot對應塊中記錄的個數([4,8]),此時page directory中會對slot的數量進行調整。
對page的結構總結一下
- b+樹中葉子頁之間用雙向鏈表連接的,能夠實現範圍查找
- 頁內部的記錄之間是採用單向鏈表連接的,方便訪問下一條記錄
- 為了加快頁內部記錄的查詢,對頁內記錄上加了個有序的稀疏索引,叫頁目錄(page directory)
整體上來說mysql中的索引用到了b+樹,鏈表,二分法查找,做到了快速定位目標數據,快速範圍查找。
本篇到此,下一篇實戰篇對mysql索引使用上面做詳細介紹,喜歡的關注一下,謝謝!
Mysql系列目錄
- 第1篇:mysql基礎知識
- 第2篇:詳解mysql數據類型(重點)
- 第3篇:管理員必備技能(必須掌握)
- 第4篇:DDL常見操作
- 第5篇:DML操作匯總(insert,update,delete)
- 第6篇:select查詢基礎篇
- 第7篇:玩轉select條件查詢,避免采坑
- 第8篇:詳解排序和分頁(order by & limit)
- 第9篇:分組查詢詳解(group by & having)
- 第10篇:常用的幾十個函數詳解
- 第11篇:深入了解連接查詢及原理
- 第12篇:子查詢
- 第13篇:細說NULL導致的神坑,讓人防不勝防
- 第14篇:詳解事務
- 第15篇:詳解視圖
- 第16篇:變數詳解
- 第17篇:存儲過程&自定義函數詳解
- 第18篇:流程式控制制語句
- 第19篇:游標詳解
- 第20篇:異常捕獲及處理詳解
- 第21篇:什麼是索引?
- 第22篇:mysql索引原理詳解
mysql系列大概有20多篇,喜歡的請關注一下,歡迎大家加我微信itsoku或者留言交流mysql相關技術!

