【主動學習】Variational Adversarial Active Learning
- 2019 年 10 月 12 日
- 筆記
本文記錄了部落客閱讀ICCV2019一篇關於主動學習論文的筆記,第一篇部落格,以後持續更新哈哈
論文題目:《Variational AdVersarial Active Learning》
原文地址:https://arxiv.org/pdf/1904.00370
開源地址:https://github.com/sinhasam/vaal
·摘要
主動學習旨在形成有效標記的演算法,通過取樣最有代表性的查詢結果去使用標註專家標記。本文描述了一種基於池的半監督主動學習演算法,以對抗的方式學習取樣機制。通過使用一個變分自編碼器學習一個潛碼空間,然後使用對抗網路訓練判別器區分數據是否被標記。VAE和判別器之間進行對抗學習:VAE的目標是讓判別器預測所有的數據點都是來自於標記池的,判別器的目標是為了更好的區分是否是標記數據。對抗網路學習如何判斷潛碼空間的不相似性。作者在影像分類數據集(CIFAR10/100,Caltech-256,ImageNet)和分割數據集(Cityscapes,BDD100K)上進行評價。結果表明,本文對抗自編碼器的方法可以學習一個有效的低維的潛碼空間並提供一個計算高效的取樣方法。
介紹
最近基於學習的電腦視覺方法取得的很大成功嚴重依賴於標註訓練樣本,可能需要花費很高的標註代價。為了解決這個問題,主動學習演算法旨在增量的挑選注釋的樣本,使用儘可能少的標註樣本得到更高的分類性能。主動學習需要的訓練數據相對較少,可以用在影像分類和分割任務中。本文介紹了一個基於池的主動學習策略,通過使用變分自編碼器從標記和未標記的數據中學習一個低維的潛碼空間。
相關工作
主動學習:當前的方法主要分為基於池(查詢獲取)或查詢合成方法。查詢合成方法使用生成模型生成更具有資訊的樣本,然而查詢獲取使用不同的取樣策略確定如何挑選最有資訊量的樣本,本文的方法就是基於查詢獲取的主動學習,主要介紹在這方面的相關工作。
基於池的方法分為三類:
1)基於不確定的方法:
2)基於表示的模型
3)二者相結合
變分自編碼器:自編碼器在特徵空間和表示中廣泛使用。
主動學習在語義分割方面的工作
Suggestive Annotation, Core-Sets,
方法概括
變分自編碼器對抗學習的主動學習:
(XL,YL)表示標記池中的標記數據, (XU)表示未標記池中的數據。主動學習者的目標是訓練最label-efficient的模型,通過迭代的查詢一個固定的取樣預算,從未標記池中挑選出最有代表性的b個樣本,查詢結束後使用oracle進行標註。
轉導表示學習
本文使用β變分自編碼器進行表示學習,編碼器使用高斯先驗可以學習一個潛在分布的低維空間,解碼器可以重建輸入的數據。為了捕捉有標記的數據在表示學習過程中丟失的特徵,作者提出使用轉導學習。這個目標函數β-VAE最小化樣本邊緣分布的變分下界,具體形式如下:

其中q和p分別表示編碼器和解碼器,p(z)是一個先驗,β是優化問題的拉格朗日參數,同時為了更好的進行梯度優化使用了重新參數化技巧。
對抗表示學習
VAE的表徵學習是一個關於標記數據和未標記數據潛在編碼特徵的混合。一個理想的主動學習方法假設有一個完美的取樣策略能夠將最有資訊量的未標記樣本發送給Oracle。大多數的取樣策略依賴模型的不確定性,例如:模型對預測越不確定,未標記樣本包含的資訊越多。恰恰相反,本文通過訓練一個對抗網路對於取樣機制去學習如何區分在潛在空間的編碼特徵。主動學習中,對抗網路中將輸入映射到潛碼空間並且給一個標籤,若樣本來自標記數據,則為1,如果為未標記數據,則為0。本文的關鍵是使用對抗的方式。然而VAE匹配標記和未標記的數據到相同的具有相似概率分布的潛碼空間,騙過判別器去分類所有的輸入是標記的。另一方面,判別器嘗試高效建立標記數據和未標記數據的分布。公式化如下:
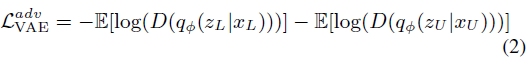
判別器的目標函數如下:

結合等式1和等式2,得到VAE的整個目標函數:
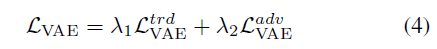
Lamda1和lamda2是兩個超參數確定各個分量學習有效變分表示的效果
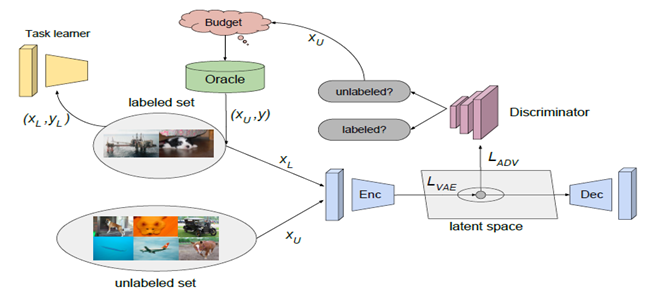
如上圖所示,任務模組用T表示,學習主動學習者正在學習的任務。作者在影像分類和分割任務上做了對比試驗,使用帶有一個無權交叉熵損失函數的VGG16和DRN膨脹殘差網路結構演算法的流程如下:

取樣策略和帶雜訊的Oracles
Oracle提供的標籤的準確度取決於可利用的人類資源的素質。例如,醫學影像注釋被人類專家,專家是更準確的比非專家人員。本文的作者考慮了兩種類型的Oracle:一個理想的Oracle,總是為主動學習者提供正確的標籤,還有一個帶有雜訊的Oracle,非對抗的提供有錯誤的標籤對於某些特定的類別,這可能發生由於一些類之間有很強的相似性,從而造成標註者是模糊的。為了呈現Oracle實際的效果,作者應用一個有針對性的雜訊在一些容易混淆的類別上。VAAL取樣策略的演算法如下:使用與鑒別器的預測作為收集b個樣本的分數,每個batch都挑選b個最低的自信度送給Oracle D判斷出來越小的,越可能是未標記池中的數據。

實驗
作者進行試驗使用最初10%的標記數據的訓練集,每個batch的b是整個訓練集的5%。未標記數據的池中包含剩下的訓練集。一旦被標記他們將被添加到初始的訓練集並且在新的訓練集上重複訓練。我們認為Oracle是理想的(標註無誤)
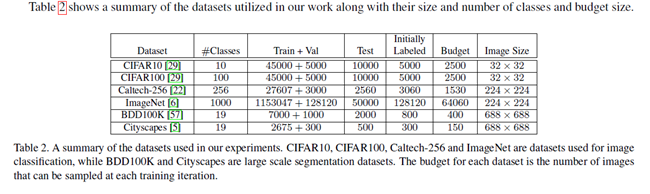
數據集:作者評價本文的方法在兩個普通的視覺任務,影像分類中,使用CIFAR10和CIFAR100,都包含6萬張32*32的影像,並且Caltech-256有30607張224*224的影像,包含256個類別。為了更好的驗證VAAL的可擴展性,作者也在ImageNet上進行了實驗,一共擁有1000類。在語義分割任務,在BDD100K和CityScapes中進行實驗,都擁有19類。BDD100K是自動駕駛影片的數據集擁有10K影像。本文中用到的數據集統計如下圖所示:
性能評價:影像分類中使用準確率,影像分割中使用平均交並比。T訓練用訓練集所有數目的10%,15%,20%,25%,30%,35%,40%。除了ImageNet上的實驗,其它所有的實驗都是平均運行5次。ImageNet上的實驗是使用訓練集的10%,15%,20%,25%,30%重複訓練兩次平均的結果。
性能比較
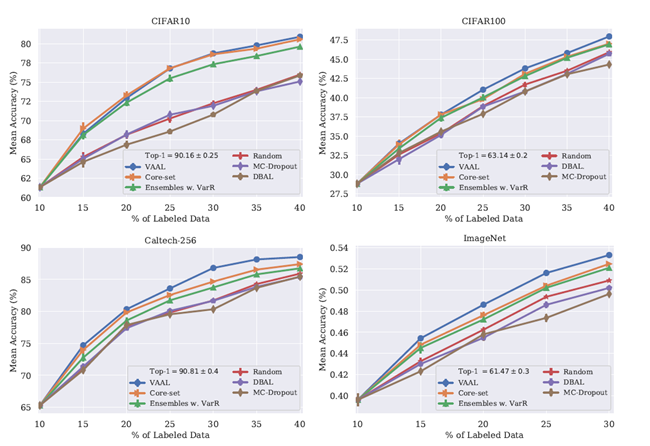
在分類任務上的結果
Baselines:在影像分類任務上與Core-set,Monte-Carlo Dropout和Ensembles using Variation Ratios進行比較。也展示了深度貝葉斯AL的表現性能並且使用其所提出的最大熵策略測量不確定性。我們展示了結果在未標記的池中隨機均勻取樣。這個方法仍然是一個比較有競爭力的baseline在主動學習中,此外,使用在整個數據集上的平均準確率作為上限,不符合主動學習情境。
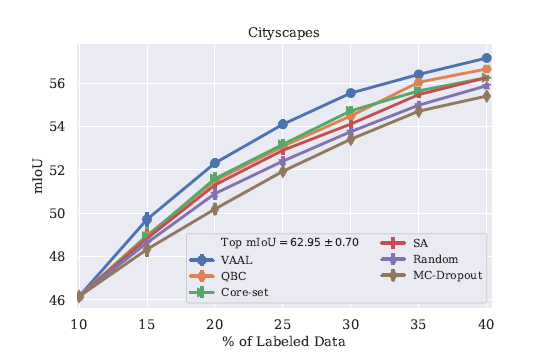
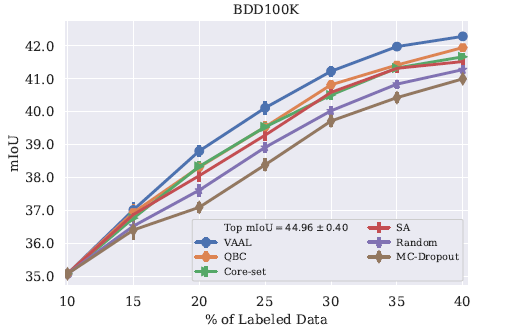
在分割任務上的結果
Baselines:Core-set,MC-Dropout,QBC,SA(suggest annotation)
分析VAAL:
消融實驗

如上圖所示表示在BDD100K上進行消融實驗,驗證VAAL中關鍵模組的貢獻,包括VAE,D。消融實驗主要考慮:a)消除VAE;b)固定VAE,同時使用D;c)消除D
在a)中,通過僅僅使用判別器在影像空間訓練區分標記和未標記數據來探索VAE在表示學習中的效果,如圖所示,結果表明判別器僅僅記住了數據,並且產生了最低的性能。同時它表明VAE不僅僅是學習一個豐富的潛碼空間,而且也會與判別器進行博弈,避免過擬合。
在b)中,作者為了訓練D添加一個VAE在低維空間中編碼和解碼。然而,不訓練VAE只是作為一個自編碼器。這個結果是更好的比單獨的D在影像空間上訓練。但是仍然是更差的比隨機取樣,表明判別器失敗學習未標記池的樣本表示。
在c)中,作者驗證判別器的效果,通過僅僅使用VAE訓練,使用Wasserstein距離基於標記數據集的聚類中心測量不確定度;;兩個分布的Wassertein距離公式如下:

在這個實驗的效果比隨機取樣效果好,清楚的表明了在潛碼空間測量不確定性的有效性。然而,VAAL通過在判別器和VAE之間的對抗學習清楚的學習了不確定性,效果遠超過這三個方案
VAAL的魯棒性
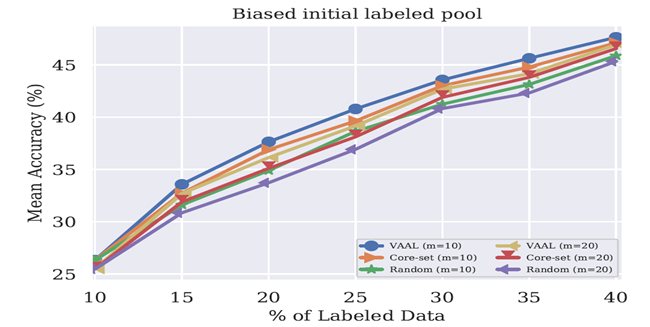
初始標記池中有偏差的標籤效果:作者為了調查在初始標記池中偏置如何影響VAAL的性能,在CIFAR100上進行了實驗。直覺上,偏置可以影響訓練,因為他造成了最初的標記樣本是沒有代表性的,不足以代表潛在數據的分布,是不充足去涵蓋潛碼空間的大多數區域。作者模擬了一個可能的情況:對於m個隨機選擇的類,標記池中不提供這樣標籤的數據。與在所有的類別中隨機取樣進行對比。作者研究了m=10和m=20是如何影響模型的效果。如下如所示。
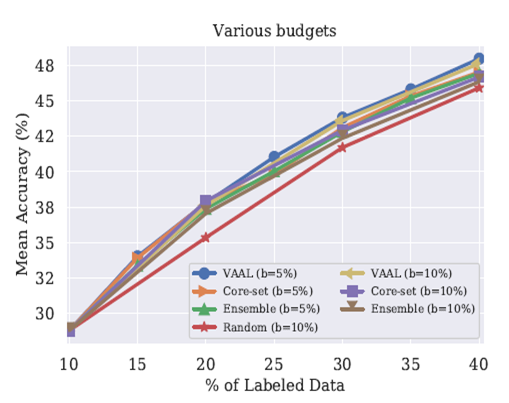
預算大小對性能的影響
如下圖所示,與大多數Baseline比較的結果在CIFAR100上。主要比較了b=5%和b=10%的效果。
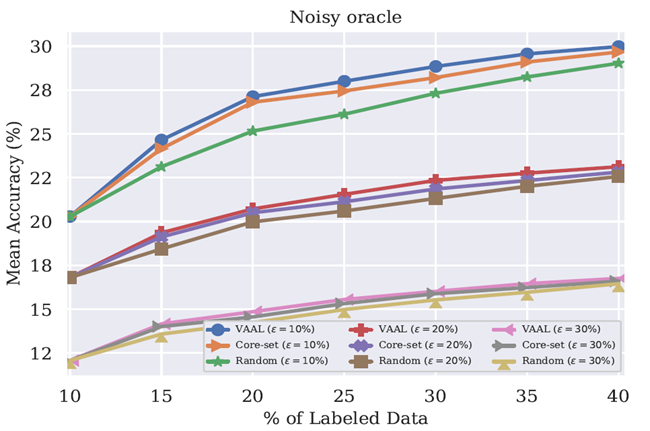
有噪音的Oracle
在這個分析中作者調查了由於不準確的Oracle導致有雜訊的數據存在是如何影響VAAL的結果。作者認為錯誤的標籤是因為一些類之間不容易區分,而不是對抗攻擊。作者模仿在明確的類別上雜訊,等同於人類錯誤的標記了一些容易混淆的類別。使用CIFAR100分析,由於100個類的層次結構,100個類別被分組成了20個超類。每個影像有一個超類和一個子類。作者通過隨機的改變標籤的真實值對於10%,20%,30%的訓練集在相同的超類下有一定的錯誤標籤。下圖展示了有雜訊的標記是如何影響演算法的性能的。
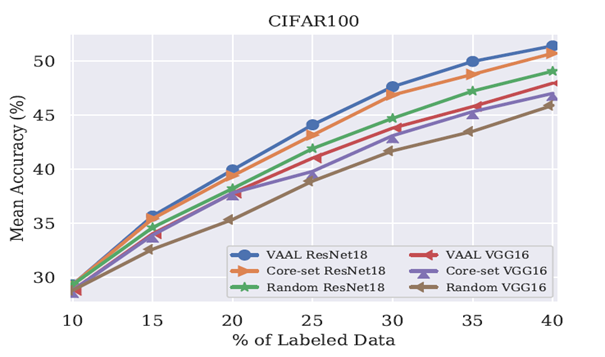
T中網路結構的選擇
在分類的任務中,為了確保VAAL對VGG16的結構不敏感,作者也是用ResNet18進行實驗。如圖6所示。
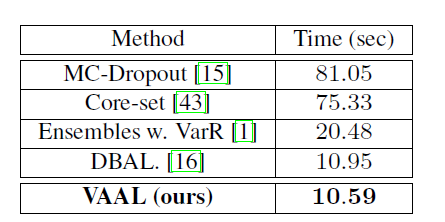
取樣時間的分析
主動學習者的取樣策略必須以快速的時間選擇樣本,考慮到隨機取樣仍然是一個有效的Baseline,它挑選樣本的時間應該與隨機取樣比較接近。下面的表格展示了VAAL與Baseline的對比在CFFAR10上。
總結
這篇文章主要提出了一個批處理的主動學習演算法,通過VAE與判別器之間的對抗學習來學習標記數據和未標記數據的潛碼錶示。同時,這篇文章做了大量的實驗(我認為中oral的一部分原因)來驗證VAAL的性能。
