圖
圖(Graph)和樹比起來,是一種更為複雜的非線性表結構
一 頂點&邊
在樹中的元素稱為節點,而在圖中的元素叫作頂點(vertex)。
圖中一個頂點可以與任意其他頂點建立連接關係,這種建立的關係叫邊(edge)。

跟頂點相連接的邊的條數, 叫作頂點的度(degree)。
二、有向圖&無向圖
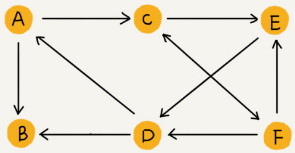
這種邊有方向的圖叫作「有向圖」。邊沒有方向的圖就叫作「無向圖」。
在有向圖中度分為入度(In-degree)和出度(Out-degree)。
-
頂點的入度,表示有多少條邊指向這個頂點
-
頂點的出度,表示有多少條邊是以這個頂點為起點指向其他頂點。
對應到微博的例子,入度就表示有多少粉絲,出度就表示關注了多少人。
三、帶權圖
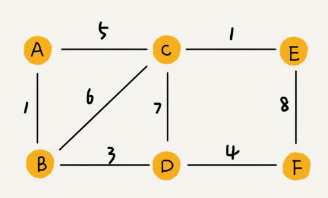
在帶權圖(weighted graph)中,每條邊都有一個權重(weight),可以通過這個權重來表示 QQ 好友間的親密度。
一、鄰接表存儲方法
鄰接表的每個頂點對應一條鏈表,鏈表中存儲的是與這個頂點相連接的其他頂點。
無向圖可以看作每條邊都是雙方向的有向圖。

鄰接矩陣存儲起來比較浪費空間,但是使用起來比較節省時間。相反,鄰接表存儲起來比較節省空間,但是使用起來就比較耗時間。這是時間、空間複雜度互換的設計思想,前者是空間換時間,後者是時間換空間。
上圖鄰接表的例子中,如果要確定是否存在一條從頂點 2 到頂點 4 的邊,就要遍歷頂點 2 對應的那條鏈表,看鏈表中是否存在頂點 4。當然如果鏈過長,可以將鏈表換成紅黑樹、散列表等來提高查找效率,還可以將鏈表改成有序動態數組,通過二分查找的方法來快速定位兩個頂點之間否存在邊。
二、如何存儲微博、微信等社交網路中的好友關係?
基本實現思想
用兩個鄰接表來存儲
- 一個鄰接表存儲某個用戶關注了哪些用戶,即用戶的關注關係
- 另一個鄰接表稱為逆鄰接表存儲某個用戶被哪些用戶關注,即用戶的粉絲列表
如果要查找某個用戶關注了哪些用戶,在鄰接表中查找即可;如果要查找某個用戶被哪些用戶關注了,從逆鄰接表中查找即可。

較大數據量實現方案
如果對於小規模的數據,可以將整個社交關係存儲在記憶體中。
如果對於大規模的數據,可以通過哈希演算法等數據分片方式,將鄰接表存儲在不同的機器上。
例如:
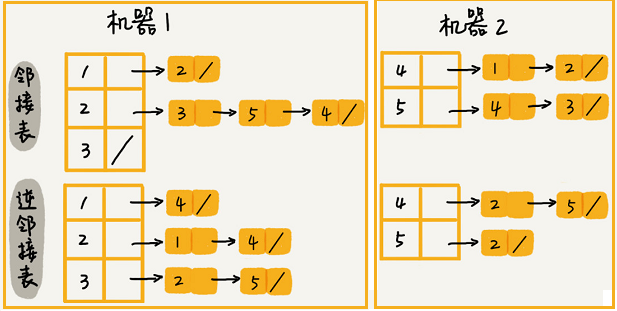
當要查詢頂點與頂點關係的時候,就利用同樣的哈希演算法,先定位頂點所在的機器再在相應的機器上查找。
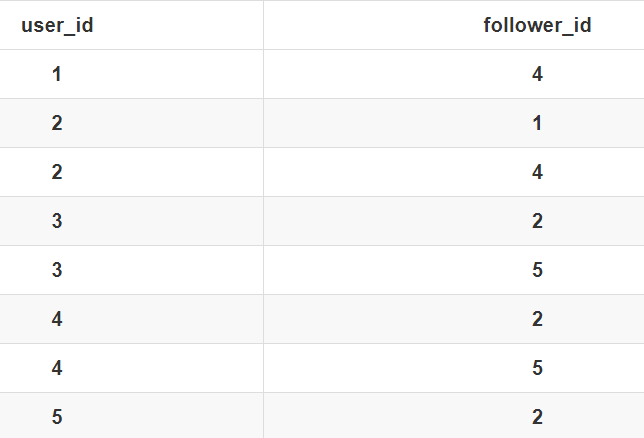
另外一種解決思路,就是利用外部存儲(比如硬碟),資料庫是經常用來持久化存儲關係數據的
用下面這張表來存儲這樣一個圖。為了高效地支援前面定義的操作,可以在表上建立這兩列都建立索引。
BFS&DFS
圖的遍歷:依次把圖中所有的頂點都訪問一次。
圖上的搜索演算法有
- 深度優先搜索演算法
- 廣度優先搜索演算法
廣度優先搜索和深度優先搜索是圖上的兩種最常用、最基本的搜索演算法,僅適用於狀態空間不大的搜索。
廣度優先搜索,採用地毯式層層推進,從起始頂點開始,依次往外遍歷。廣度優先搜索需要藉助隊列來實現,遍歷得到的路徑就是起始頂點到終止頂點的最短路徑。
深度優先搜索,採用回溯思想,適合用遞歸或棧來實現。遍歷得到的路徑並不是最短路徑。
一、深度優先搜索(DFS)
深度優先搜索(Depth-First-Search),簡稱 DFS。
最直觀的例子就是「走迷宮」。假設你站在迷宮的某個岔路口,然後想找到出口。你隨意選擇一個岔路口來走,走著走著發現走不通的時候,你就回退到上一個岔路口,重新選擇一條路繼續走,直到最終找到出口。這種走法就是一種深度優先搜索策略。
下圖中,搜索的起始頂點是 s,終止頂點是 t,希望在圖中尋找一條從頂點 s 到頂點 t 的路徑。如果映射到迷宮那個例子,s 就是你起始所在的位置,t 就是出口。
下圖標記了遞歸演算法的搜索的過程,裡面實線箭頭表示遍歷,虛線箭頭表示回退。但深度優先搜索最先找出來的路徑,並不是頂點 s 到頂點 t 的最短路徑。
深度優先搜索的過程類似於樹的先序遍歷,首先從例子中體會深度優先搜索。
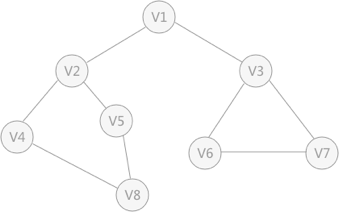
例如圖 1 是一個無向圖,採用深度優先演算法遍歷這個圖的過程為:
- 首先任意找一個未被遍歷過的頂點,例如從 V1 開始,由於 V1 率先訪問過了,所以,需要標記 V1 的狀態為訪問過;
- 然後遍歷 V1 的鄰接點,例如訪問 V2 ,並做標記,然後訪問 V2 的鄰接點,例如 V4 (做標記),然後 V8 ,然後 V5 ;
- 當繼續遍歷 V5 的鄰接點時,根據之前做的標記顯示,所有鄰接點都被訪問過了。此時,從 V5 回退到 V8 ,看 V8 是否有未被訪問過的鄰接點,如果沒有,繼續回退到 V4 , V2 , V1 ;
- 通過查看 V1 ,找到一個未被訪問過的頂點 V3 ,繼續遍歷,然後訪問 V3 鄰接點 V6 ,然後 V7 ;
- 由於 V7 沒有未被訪問的鄰接點,所有回退到 V6 ,繼續回退至 V3 ,最後到達 V1 ,發現沒有未被訪問的;
- 最後一步需要判斷是否所有頂點都被訪問,如果還有沒被訪問的,以未被訪問的頂點為第一個頂點,繼續依照上邊的方式進行遍歷。
根據上邊的過程,可以得到圖 1 通過深度優先搜索獲得的頂點的遍歷次序為:
V1 -> V2 -> V4 -> V8 -> V5 -> V3 -> V6 -> V7
所謂深度優先搜索,是從圖中的一個頂點出發,每次遍歷當前訪問頂點的臨界點,一直到訪問的頂點沒有未被訪問過的臨界點為止。然後採用依次回退的方式,查看來的路上每一個頂點是否有其它未被訪問的臨界點。訪問完成後,判斷圖中的頂點是否已經全部遍歷完成,如果沒有,以未訪問的頂點為起始點,重複上述過程。
深度優先搜索是一個不斷回溯的過程。
二、廣度優先搜索(BFS)
廣度優先搜索(Breadth-First-Search),簡稱 BFS。它是一種「地毯式」層層推進的搜索策略,即先查找離起始頂點最近的,然後是次近的,依次往外搜索
廣度優先搜索類似於樹的層次遍歷。從圖中的某一頂點出發,遍歷每一個頂點時,依次遍歷其所有的鄰接點,然後再從這些鄰接點出發,同樣依次訪問它們的鄰接點。按照此過程,直到圖中所有被訪問過的頂點的鄰接點都被訪問到。
最後還需要做的操作就是查看圖中是否存在尚未被訪問的頂點,若有,則以該頂點為起始點,重複上述遍歷的過程。

以上面的無向圖為例,假設 V1 作為起始點,遍歷其所有的鄰接點 V2 和 V3 ,以 V2 為起始點,訪問鄰接點 V4 和 V5 ,以 V3 為起始點,訪問鄰接點 V6 、 V7 ,以 V4 為起始點訪問 V8 ,以 V5 為起始點,由於 V5 所有的起始點已經全部被訪問,所有直接略過, V6 和 V7 也是如此。 以 V1 為起始點的遍歷過程結束後,判斷圖中是否還有未被訪問的點,由於圖 1 中沒有了,所以整個圖遍歷結束。遍歷頂點的順序為:
V1 -> V2 -> v3 -> V4 -> V5 -> V6 -> V7 -> V8