常見的索引模型淺析
- 自適應哈希索引(AHI)
哈希表是一種常見的數據結構,即通過哈希演算法計算出一個數字在表中的位置,並將數字存入該表。哈希索引就是通過哈希表來實現的,一般情況下查找時間複雜度為O(1)。InnoDB會監控對錶上各索引頁的查詢,會自動根據訪問的頻率和模式為某些熱點頁建立哈希索引,所以又叫自適應哈希索引,訪問模式一樣指查詢的條件一樣。
比如我們維護一張身份證資訊和用戶姓名的表,需要根據身份證號查詢姓名,哈希索引大概是這樣的:

哈希索引適合只有等值查詢的場景,例如select * from T where index_col = ‘##’。哈希索引是無序的,如果需要區間查詢,那就要把所有數據掃描一遍。
- 有序數組索引
有序數組在等值查詢和區間查詢場景中效率都很高,同樣用上面的表舉例,索引大概是這樣的:
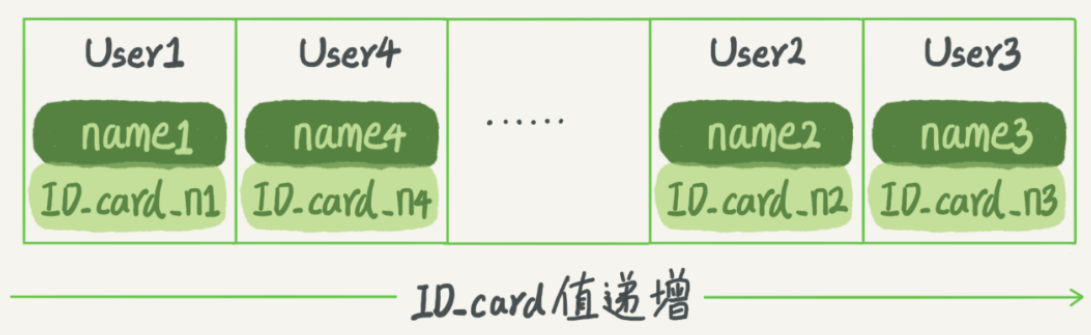
要查詢某條數據或者區間的時候,使用二分法時間複雜度為O(logN)。但如果需要在中間更新數據時,那麼就要移動後面所有的數據。有序數組索引只適用於靜態存儲引擎,比如保存2019年度學校所有學生資訊。
B+樹是為磁碟或其他直接存取輔助設備設計的一種平衡查找樹。下面是一顆高度為2的B+樹,所有記錄都在葉子結點上順序存放,葉子結點通過指針相連。
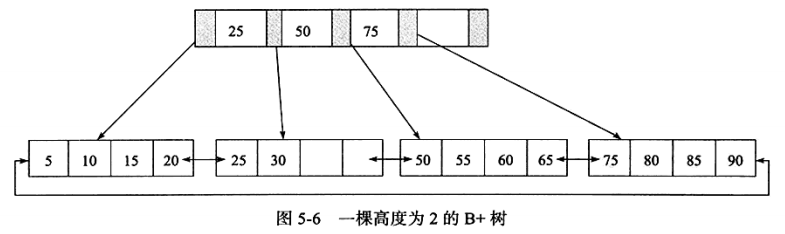
B+樹索引就是B+樹在資料庫中的實現,B+索引在資料庫中具有高扇出性,在資料庫中B+樹的高度一般為2~4層。查找某一鍵值的行記錄時最多只需要2~4次IO。以InnoDB的一個整數欄位索引為例,這顆B+樹大概是1200叉樹。樹高度為4的時候就可以存1200的3次方個值,大概為17億。考慮到樹根的數據塊總是在記憶體中,一個10億行的表上一個整數欄位的索引,查找一個值最多只需要訪問3次磁碟。
在InnoDB存儲引擎中,表是根據主鍵順序存放的。根據葉子結點內容,B+樹索引又分為聚簇索引和輔助索引。
-
- 聚簇索引:按照每張表的主鍵構造一顆B+樹,葉子結點存放的是整張表的行記錄數據,也將聚簇索引的葉子結點稱為數據頁。
-
-
輔助索引:葉子結點的內容是主鍵的值。
-
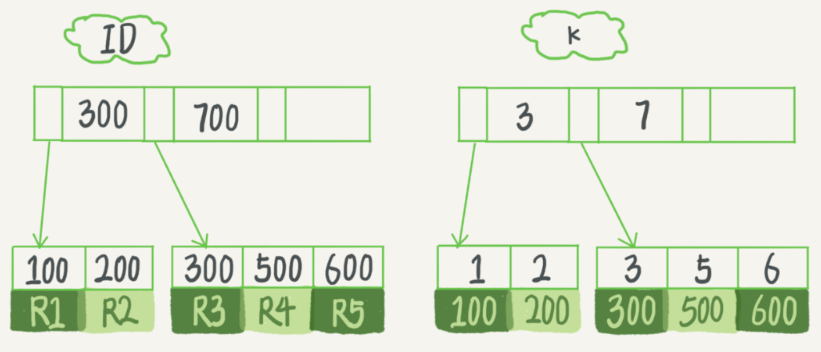
我們用一個例子來說明上面的概念,創建一張表,在欄位k上有索引:
create table T( id int primary key, k int not null, name varchar(16), index (k))engine=InnoDB;
表中R1~R5的(ID,k)值分別為(100,1)、(200,2)、(300,3)、(500,5)和(600,6),兩顆B+樹如下,可以明顯看到這兩個顆樹的區別。