手把手教你使用Python抓取QQ音樂數據(第二彈)
- 2020 年 6 月 26 日
- 筆記
- Python3, Python入門, Python基礎, Python庫, Python應用, Python開發, Python網路爬蟲, 數據分析, 數據挖掘, 網路爬蟲
【一、項目目標】
通過Python爬取QQ音樂數據(一)我們實現了獲取 QQ 音樂指定歌手單曲排行指定頁數的歌曲的歌名、專輯名、播放鏈接。
此次我們在之前的基礎上獲取QQ音樂指定歌曲的歌詞及前15個精彩評論。
【二、需要的庫】
主要涉及的庫有:requests、json、html
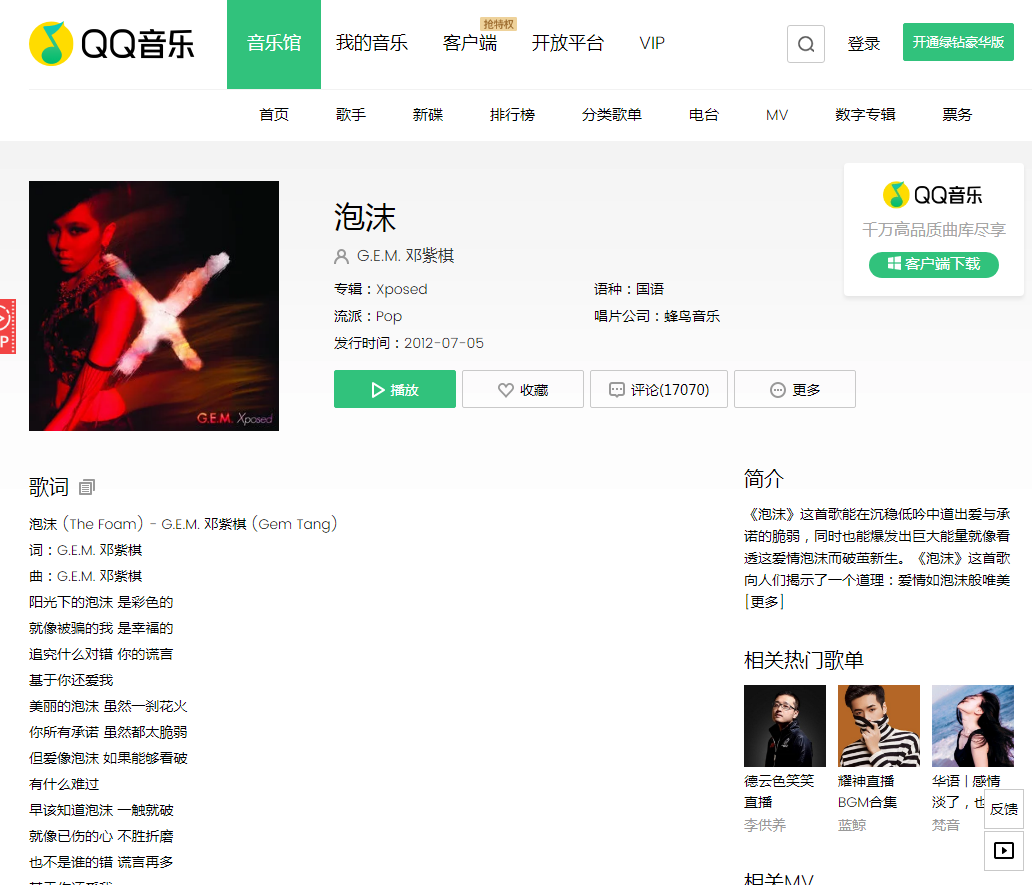
【三、項目實現】
1.以歌曲「泡沫」為例,查看該介面的XHR
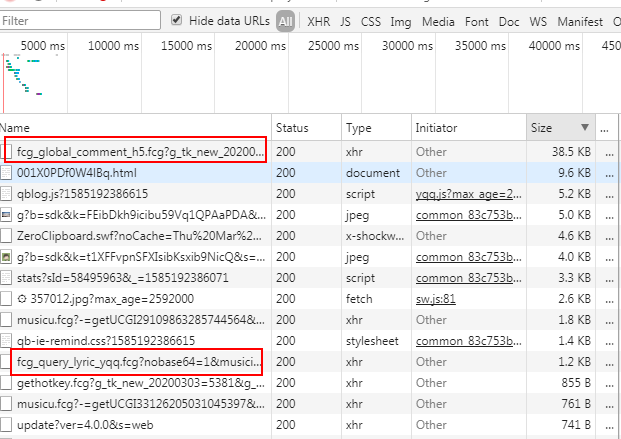
2.通過對XHR的Size進行排序,逐個查看(參考英文含義),我們看到第一個紅框內是歌曲評論,第二個框內是歌詞!
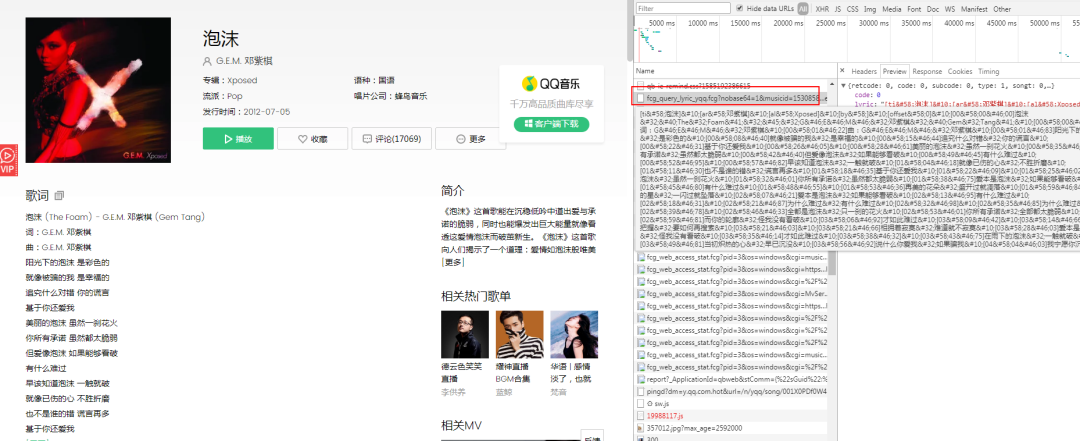
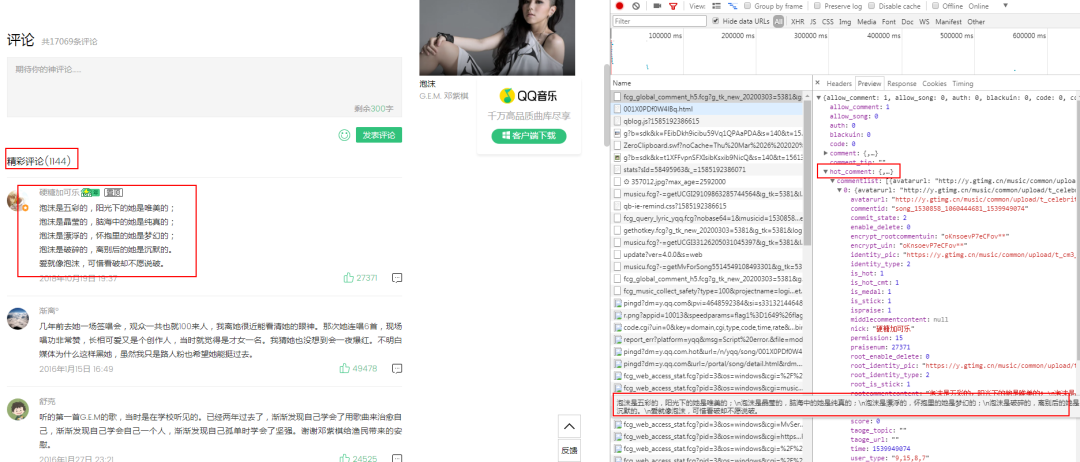
3.分別查看這兩條數據Headers裡面Parms參數。
4.發現這幾個參數可能會代表不同的歌曲,那到底是哪個呢,我們在代開另一首歌對比一下。

5.發現只有這個topid不同,其他都一樣,這就代表topid代表不同歌曲的id,同理我們看一下歌詞。
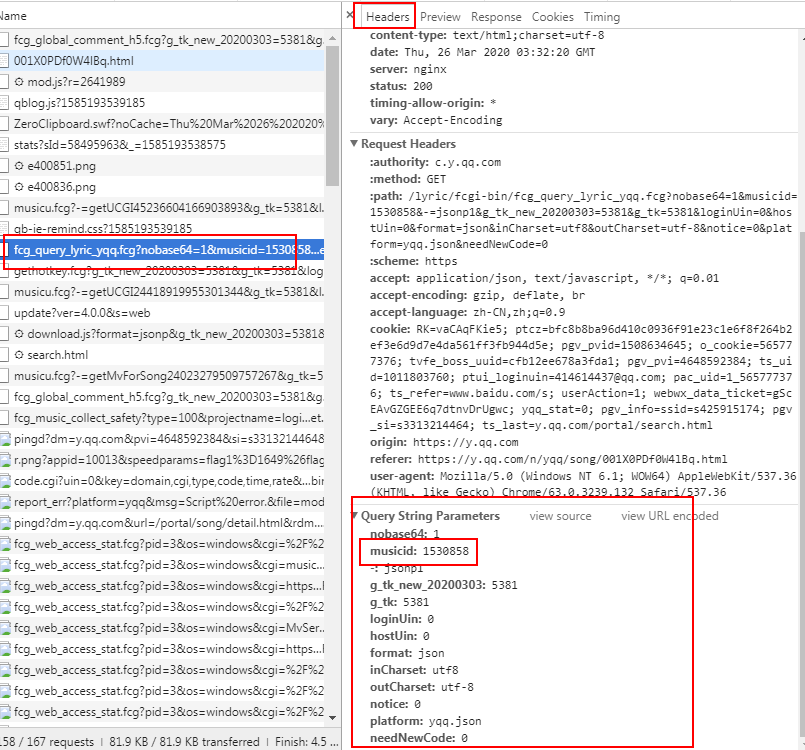
6、確定下來:musicid= topid = 歌曲的id,接下來我們的任務是找到這個id。
7.返回以下介面,也就是我們上一個項目的主戰場。
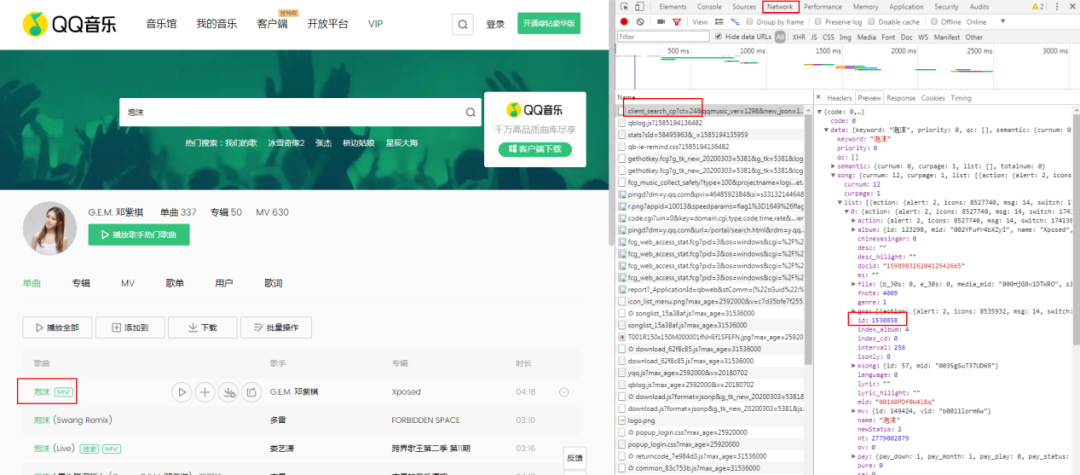
參考上一個項目,很容易找到「id」的值就是我們要尋找的id。
所以思路確定下來:先通過input()輸入歌名生成url_1找到該歌曲的「id」參數,再生成url_2獲取歌詞和評論。
8.程式碼實現:獲取歌曲id,如下所示:
import requests,html,json
url_1 = ‘//c.y.qq.com/soso/fcgi-bin/client_search_cp‘
headers = {
‘user-agent’:’Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36′,
/# 標記了請求從什麼設備,什麼瀏覽器上發出
}
i = input(‘請輸入需要查詢歌詞的歌曲名稱:’)
params = {‘ct’: ’24’, ‘qqmusic_ver’: ‘1298’, ‘new_json’: ‘1’, ‘remoteplace’: ‘txt.yqq.song’, ‘searchid’: ‘71600317520820180’, ‘t’: ‘0’, ‘aggr’: ‘1’, ‘cr’: ‘1’, ‘catZhida’: ‘1’, ‘lossless’: ‘0’, ‘flag_qc’: ‘0’, ‘p’: ‘1’, ‘n’: ’10’, ‘w’: i, ‘g_tk’: ‘5381’, ‘loginUin’: ‘0’, ‘hostUin’: ‘0’, ‘format’: ‘json’, ‘inCharset’: ‘utf8’, ‘outCharset’: ‘utf-8’, ‘notice’: ‘0’, ‘platform’: ‘yqq.json’, ‘needNewCode’: ‘0’}
res_music = requests.get(url_1,headers=headers,params=params)
/# 發起請求
json_music = res_music.json()
id = json_music[‘data’][‘song’][‘list’][0][‘id’]
print(id)
9.程式碼實現:獲取歌詞
實現方法如下:
url_2 = ‘//c.y.qq.com/lyric/fcgi-bin/fcg_query_lyric_yqq.fcg‘
headers = {
‘user-agent’:’Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36′,
/# 標記了請求從什麼設備,什麼瀏覽器上發出
}
params = {
‘nobase64′:’1’,
‘musicid’:id, /#用上面獲取到的id
‘-‘:’jsonp1’,
‘g_tk’:’5381′,
‘loginUin’:’0′,
‘hostUin’:’0′,
‘format’:’json’,
‘inCharset’:’utf8′,
‘outCharset’:’utf-8′,
‘notice’:’0′,
‘platform’:’yqq.json’,
‘needNewCode’:’0′,
}
res_music = requests.get(url_2,headers=headers,params=params)
/# 發起請求
js = res_music.json()
lyric = js[‘lyric’]
lyric_html = html.unescape(lyric) /#用了轉義字元html.unescape方法
/# print(lyric_html)
f1 = open(i+’歌詞.txt’,’a’,encoding=’utf-8′)
f1.writelines(lyric_html)
f1.close() /#存儲到txt中
input(‘下載成功,按回車鍵退出!’)
- 程式碼實現:獲取評論。
url_3 = ‘//c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg‘
headers = {
‘user-agent’:’Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36′,
/# 標記了請求從什麼設備,什麼瀏覽器上發出
}
params = {‘g_tk_new_20200303’: ‘5381’, ‘g_tk’: ‘5381’, ‘loginUin’: ‘0’, ‘hostUin’: ‘0’, ‘format’: ‘json’, ‘inCharset’: ‘utf8’, ‘outCharset’: ‘GB2312’, ‘notice’: ‘0’, ‘platform’: ‘yqq.json’, ‘needNewCode’: ‘0’, ‘cid’: ‘205360772’, ‘reqtype’: ‘2’, ‘biztype’: ‘1’, ‘topid’: id, ‘cmd’: ‘8’, ‘needmusiccrit’: ‘0’, ‘pagenum’: ‘0’, ‘pagesize’: ’25’, ‘lasthotcommentid’: ”, ‘domain’: ‘qq.com’, ‘ct’: ’24’, ‘cv’: ‘10101010’}
res_music = requests.get(url_3,headers=headers,params=params)
/# 發起請求
js = res_music.json()
comments = js[‘hot_comment’][‘commentlist’]
f2 = open(i+’評論.txt’,’a’,encoding=’utf-8′) /#存儲到txt中
for i in comments:
comment = i[‘rootcommentcontent’] + ‘\n——————————————————————————————————\n’
f2.writelines(comment)
/# print(comment)
f2.close()
input(‘下載成功,按回車鍵退出!’)
- 封裝函數
11.結果展示
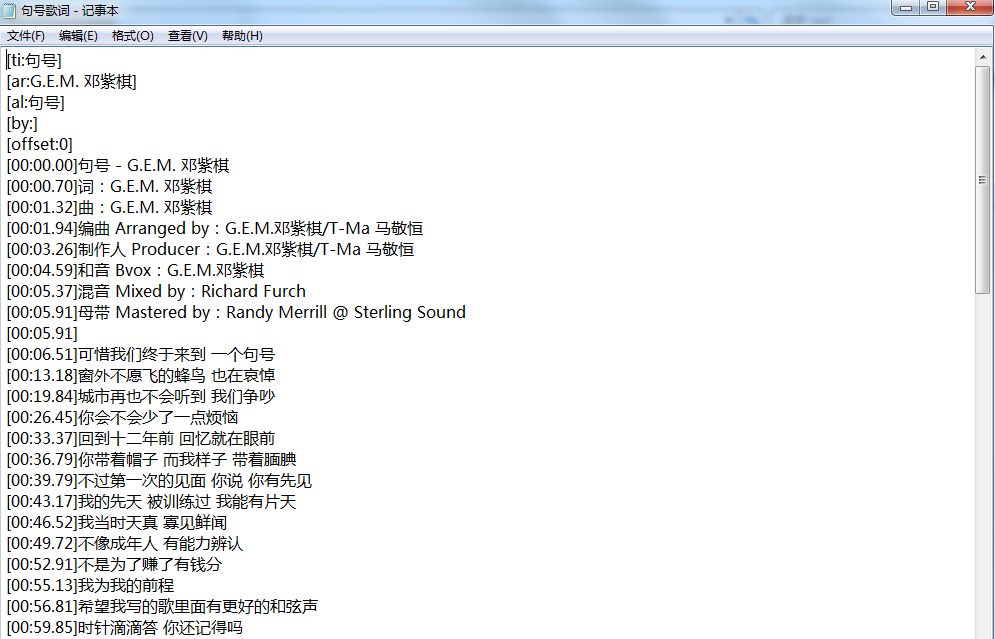
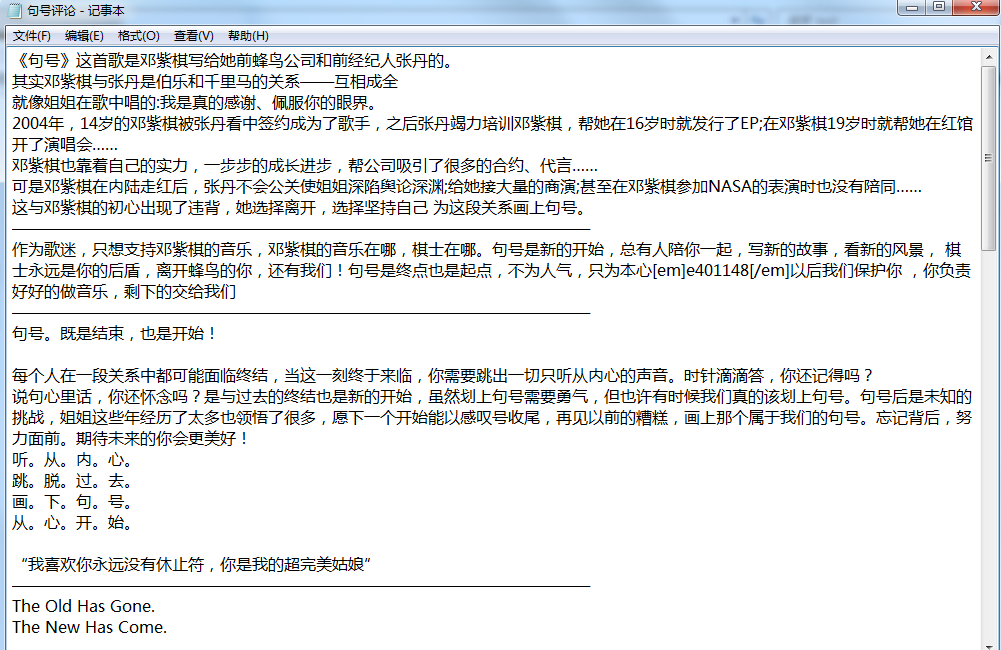
【四、總結】
1.項目二比項目一稍複雜一點,多了一步獲取歌曲id的步驟;
2.通過XHR爬取數據一般要使用json,格式為:
res =requests.get(url)
json =res.json()
list = json[『』][『』]…
3.學習了轉義字元html.unescape方法;
4.保存到txt還可以用 with open() as的方法;
5.Python爬取QQ音樂數據(第三彈)將為大家帶來如何爬取更多評論,並生成詞雲圖(wordcloud)。
6.需要本文源碼的話,請在公眾號後台回復「QQ音樂」四個字進行獲取。
看完本文有收穫?請轉發分享給更多的人
IT共享之家
入群請在微信後台回復【入群】

想學習更多Python網路爬蟲與數據挖掘知識,可前往專業網站://pdcfighting.com/


