互聯網公司面試經——你不得不知道的哈希表
- 2019 年 10 月 3 日
- 筆記
文章導航-readme
前言
哈希表,又名散列表。是非常常用的一種數據結構,C#的Hashtable、字典,Java的HashMap,Redis的Hash,其底層實現都是散列表。而在一些互聯網公司的面試中,更是技術面試官們必問的一道題目。本文將簡單了解哈希表(散列表)這種數據結構。
一、散列表
1.1 散列表
散列表(哈希表),其思想主要是基於數組支援按照下標隨機訪問數據時間複雜度為O(1)的特性。可是說是數組的一種擴展。假設,我們為了方便記錄某高校數學專業的所有學生的資訊。要求可以按照學號(學號格式為:入學時間+年級+專業+專業內自增序號,如2011 1101 0001)能夠快速找到某個學生的資訊。這個時候我們可以取學號的自增序號部分,即後四位作為數組的索引下標,把學生相應的資訊存儲到對應的空間內即可。
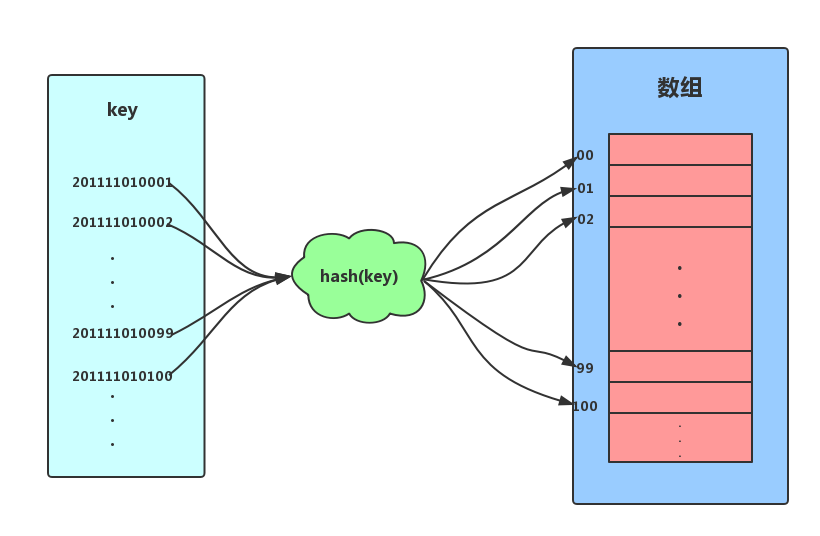
如上圖所示,我們把學號作為key,通過截取學號後四位的函數後計算後得到索引下標,將數據存儲到數組中。當我們按照鍵值(學號)查找時,只需要再次計算出索引下標,然後取出相應數據即可。以上便是散列思想。
1.2 散列函數
上面的例子中,截取學號後四位的函數即是一個簡單的散列函數。
//散列函數 偽程式碼 int Hash(string key) { // 獲取後四位字元 string hashValue =int.parse(key.Substring(key.Length-4, 4)); // 將後兩位字元轉換為整數 return hashValue; }在這裡散列函數的作用就是講key值映射成數組的索引下標。關於散列函數的設計方法有很多,如:直接定址法、數字分析法、隨機數法等等。但即使是再優秀的設計方法也不能避免散列衝突。在散列表中散列函數不應設計太複雜。
1.3 散列衝突
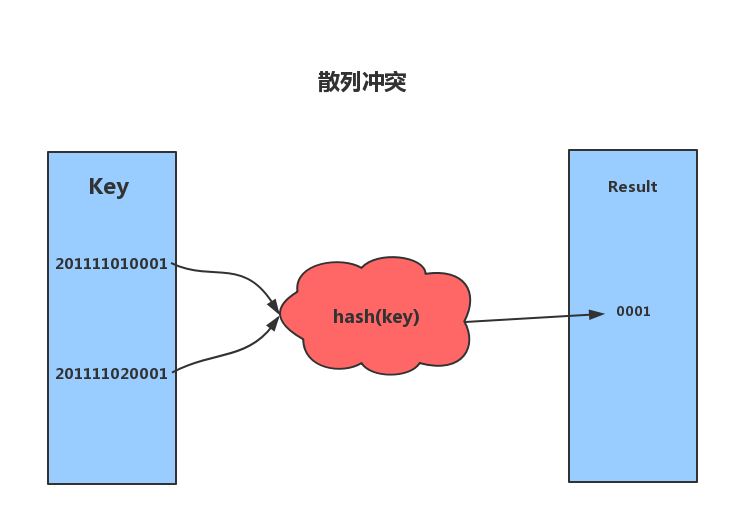
散列函數具有確定性和不確定性。
- 確定性:哈希的散列值不同,那麼哈希的原始輸入也就不同。即:key1=key2,那麼hash(key1)=hash(key2)。
- 不確定性:同一個散列值很有可能對應多個不同的原始輸入。即:key1≠key2,hash(key1)=hash(key2)。
散列衝突,即key1≠key2,hash(key1)=hash(key2)的情況。散列衝突是不可避免的,如果我們key的長度為100,而數組的索引數量只有50,那麼再優秀的演算法也無法避免散列衝突。關於散列衝突也有很多解決辦法,這裡簡單複習兩種:開放定址法和鏈表法。
1.3.1 開放定址法
開放定址法的核心思想是,如果出現了散列衝突,我們就重新探測一一個空閑位置,將其插入。比如,我們可以使用線性探測法。當我們往散列表中插入數據時,如果某個數據經過散列函數散列之後,存儲位置已經被佔用了,我們就從當前位置開始,依次往後查找,看是否有空閑位置,如果遍歷到尾部都沒有找到空閑的位置,那麼我們就再從表頭開始找,直到找到為止。
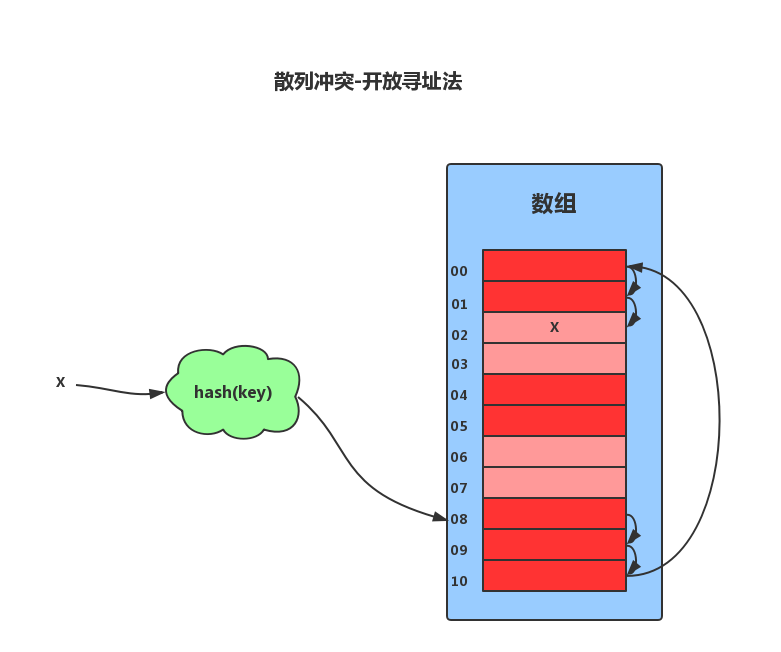
散列表中查找元素的時候,我們通過散列函數求出要查找元素的鍵值對應的散列值,然後比較數組中下標為散列值的元素和要查找的元素。如果相等,則說明就是我們要找的元素;否則就順序往後依次查找。如果遍歷到數組中的空閑位置還沒有找到,就說明要查找的元素並沒有在散列表中。
對於刪除操作稍微有些特別,不能單純地把要刪除的元素設置為空。因為在查找的時候,一旦我們通過線性探測方法,找到一個空閑位置,我們就可以認定散列表中不存在這個數據。但是,如果這個空閑位置是我們後來刪除的,就會導致原來的查找演算法失效。這裡我們可以將刪除的元素,特殊標記為 deleted。當線性探測查找的時候,遇到標記為 deleted 的空間,並不是停下來,而是繼續往下探測。
線性探測法存在很大問題。當散列表中插入的數據越來越多時,其散列衝突的可能性就越大,極端情況下甚至要探測整個散列表,因此最壞時間複雜度為O(N)。在開放定址法中,除了線性探測法,我們還可以二次探測和雙重散列等方式。
1.3.2 鏈表法(拉鏈法)
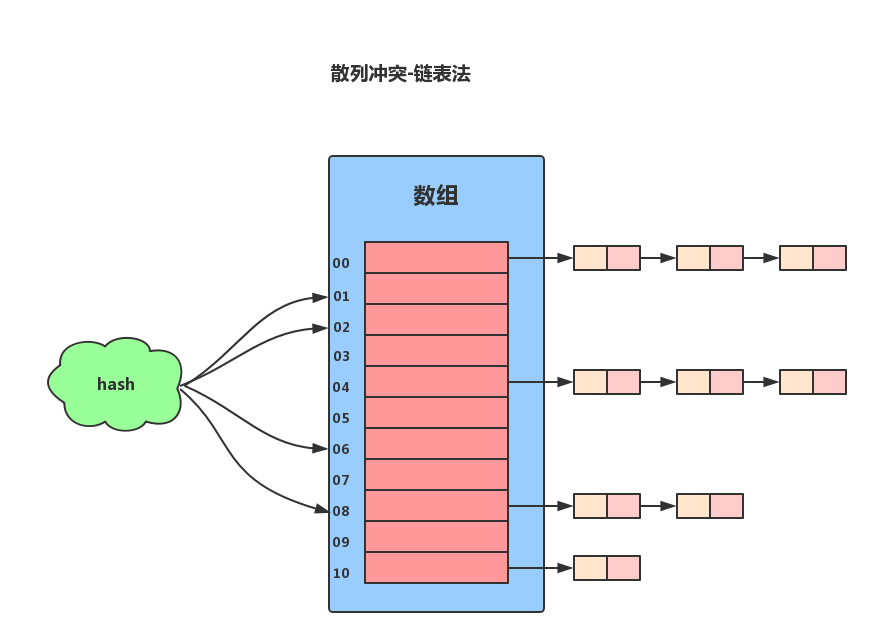
簡單來講就是在衝突的位置拉一條鏈表來存儲數據。
鏈表法是一種比較常用的散列衝突解決辦法,Redis使用的就是鏈表法來解決散列衝突。鏈表法的原理是:如果遇到衝突,他就會在原地址新建一個空間,然後以鏈表結點的形式插入到該空間。當插入的時候,我們只需要通過散列函數計算出對應的散列槽位,將其插入到對應鏈表中即可。
1.3.3 負載因子與rehash
我們可以使用裝載因子來衡量散列表的「健康狀況」。
散列表的負載因子 = 填入表中的元素個數/散列表的長度散列表負載因子越大,代表空閑位置越少,衝突也就越多,散列表的性能會下降。
對於散列表來說,負載因子過大或過小都不好,負載因子過大,散列表的性能會下降。而負載因子過小,則會造成記憶體不能合理利用,從而形成記憶體浪費。因此我們為了保證負載因子維持在一個合理的範圍內,要對散列表的大小進行收縮或擴展,即rehash。散列表的rehash過程類似於數組的收縮與擴容。
1.3.4 開放定址法與鏈表法比較
對於開放定址法解決衝突的散列表,由於數據都存儲在數組中,因此可以有效地利用 CPU 快取加快查詢速度(數組佔用一塊連續的空間)。但是刪除數據的時候比較麻煩,需要特殊標記已經刪除掉的數據。而且,在開放定址法中,所有的數據都存儲在一個數組中,比起鏈表法來說,衝突的代價更高。所以,使用開放定址法解決衝突的散列表,負載因子的上限不能太大。這也導致這種方法比鏈表法更浪費記憶體空間。
對於鏈表法解決衝突的散列表,對記憶體的利用率比開放定址法要高。因為鏈表結點可以在需要的時候再創建,並不需要像開放定址法那樣事先申請好。鏈表法比起開放定址法,對大裝載因子的容忍度更高。開放定址法只能適用裝載因子小於1的情況。接近1時,就可能會有大量的散列衝突,性能會下降很多。但是對於鏈表法來說,只要散列函數的值隨機均勻,即便裝載因子變成10,也就是鏈表的長度變長了而已,雖然查找效率有所下降,但是比起順序查找還是快很多。但是,鏈表因為要存儲指針,所以對於比較小的對象的存儲,是比較消耗記憶體的,而且鏈表中的結點是零散分布在記憶體中的,不是連續的,所以對CPU快取是不友好的,這對於執行效率有一定的影響。
小結
對於一些一線城市的互聯網公司,技術面試官比較喜歡考察一個人的基礎,像哈希這種經典而又應用廣泛的數據結構更是老生常談之題目。大致提問方式無非以下幾種
- C#字典(java hashmap或者Redis hash)的底層實現方式
- 說一下什麼是哈希表(散列表)
- 哈希如何解決碰撞(散列如何解決衝突)
—–END—–
感謝大家閱讀,如有問題可在文章下方留言,我會在第一時間回復!
