手把手教你使用Python抓取QQ音樂數據(第一彈)
- 2020 年 6 月 22 日
- 筆記
- Python3, Python入門, Python基礎, Python庫, Python應用, Python開發, Python網路爬蟲, 數據分析, 數據挖掘, 網路爬蟲
【一、項目目標】
獲取 QQ 音樂指定歌手單曲排行指定頁數的歌曲的歌名、專輯名、播放鏈接。
由淺入深,層層遞進,非常適合剛入門的同學練手。
【二、需要的庫】
主要涉及的庫有:requests、json、openpyxl
【三、項目實現】
1.了解 QQ 音樂網站的 robots 協議

只禁止播放列表,可以操作。
2.進入 QQ 音樂主頁 //y.qq.com/
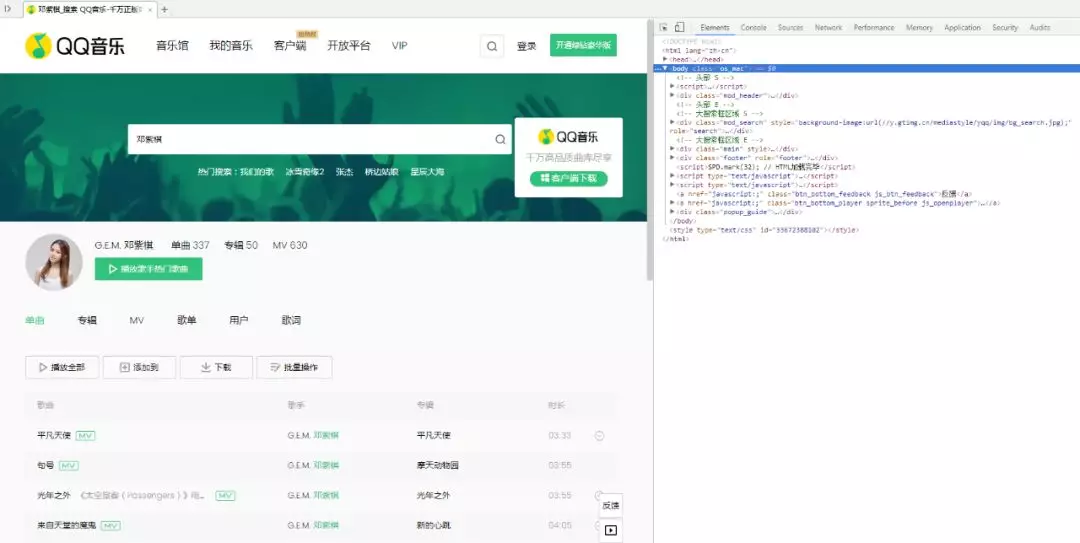
3.輸入任意歌手,比如鄧紫棋
4.打開審查元素(快捷鍵 Ctrl+Shift+I)
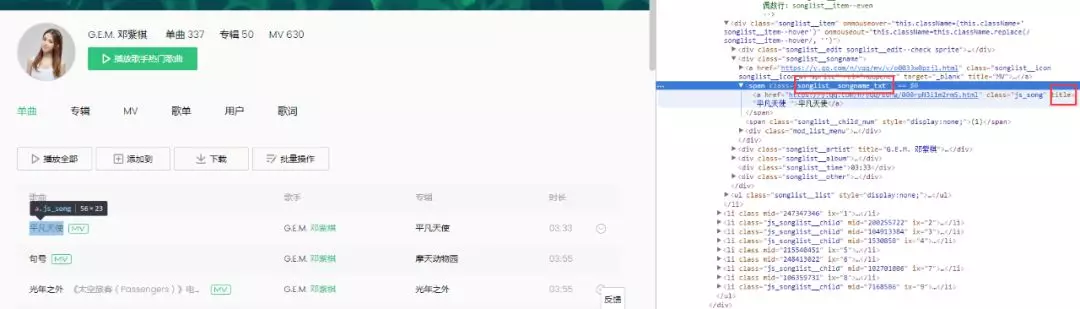
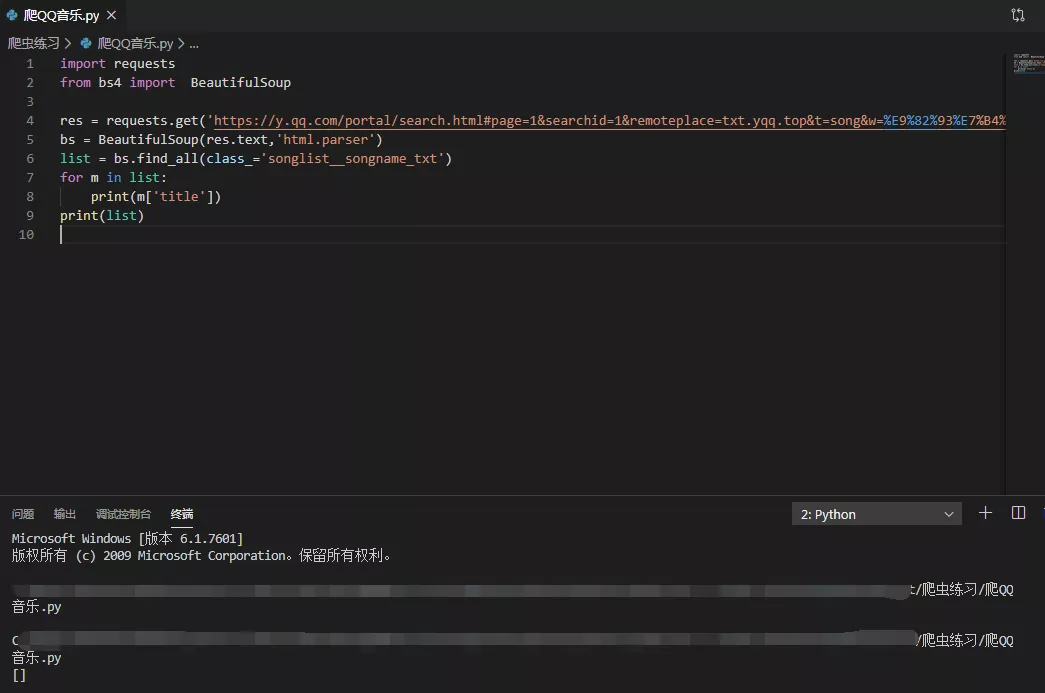
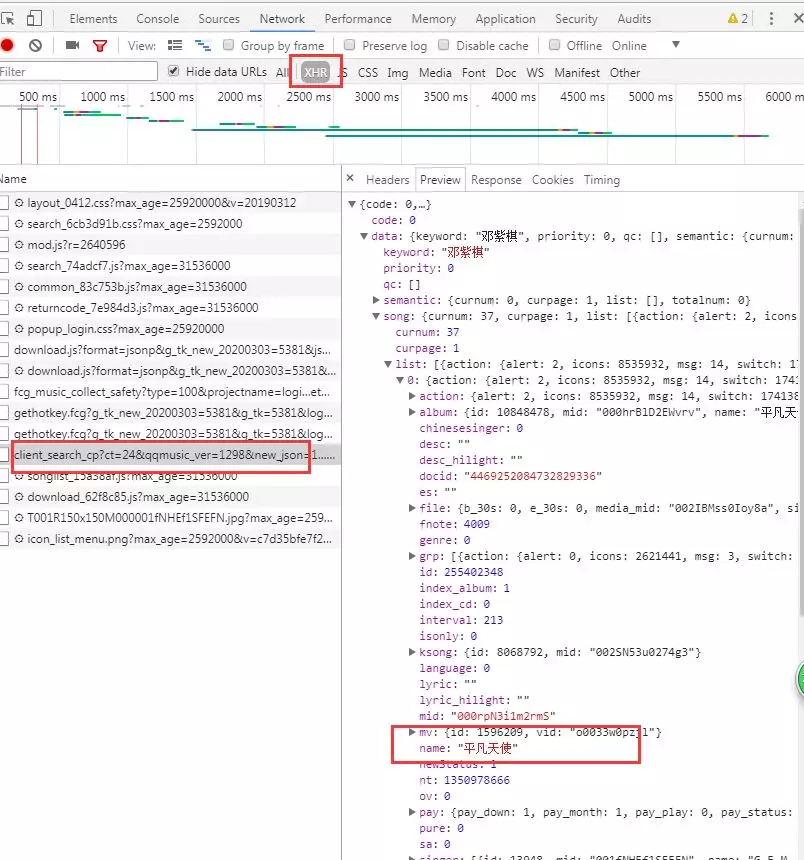
5.分析網頁源程式碼 Elements,發現無歌曲資訊,無法使用 BeautifulSoup,如下圖所示,結果為空。
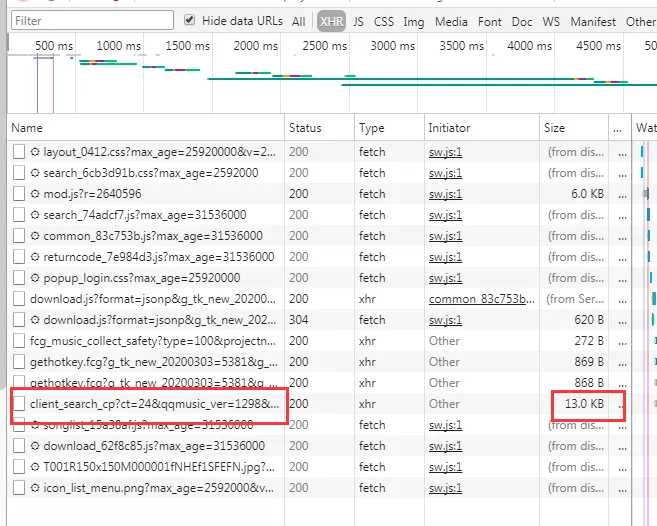
6.點擊 Network,看數據在不在 XHR(無刷新更新頁
面),我的經驗是先看 Size 最大的,然後分析 Name,
查看 Preview,果然在裡面!
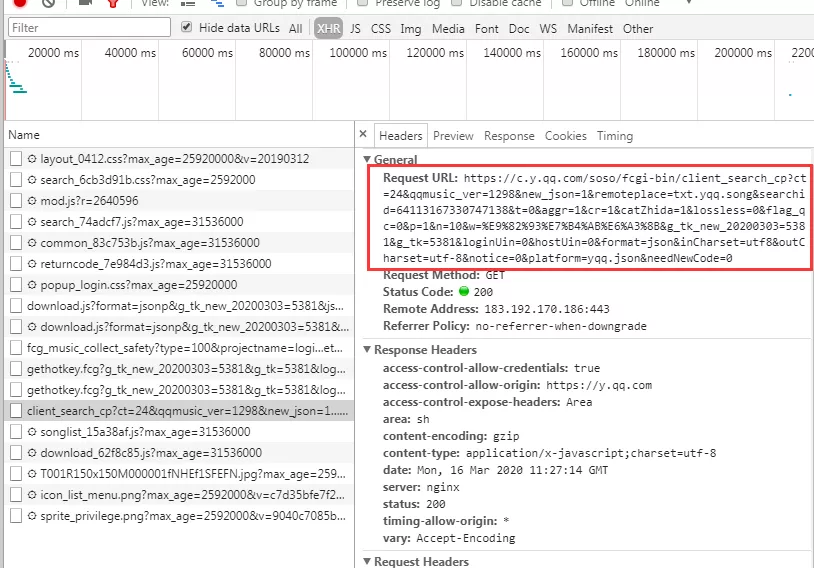
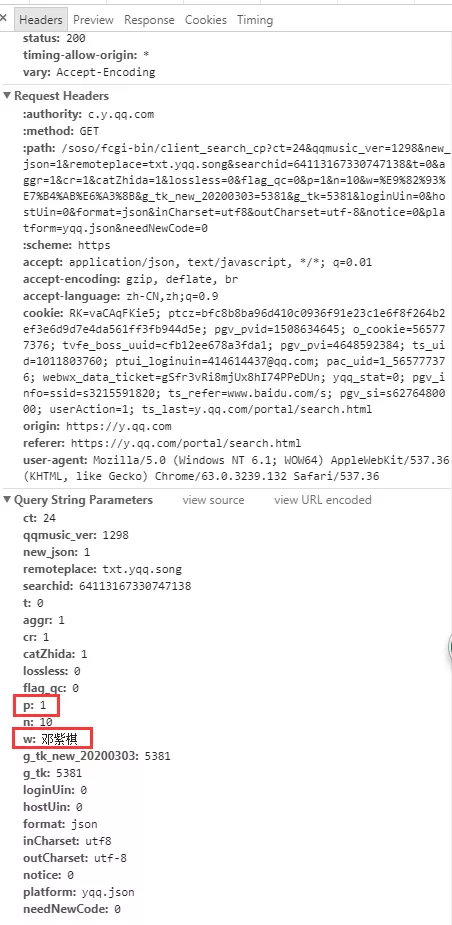
7.點擊 Headers,拿到相關參數。如下圖,仔細觀察
url 與 Query String Parameters 參數的關係,發現
url 中的 w 代表歌手名,p 代表頁數。
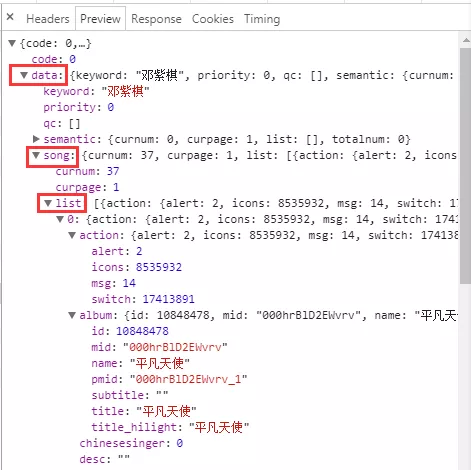
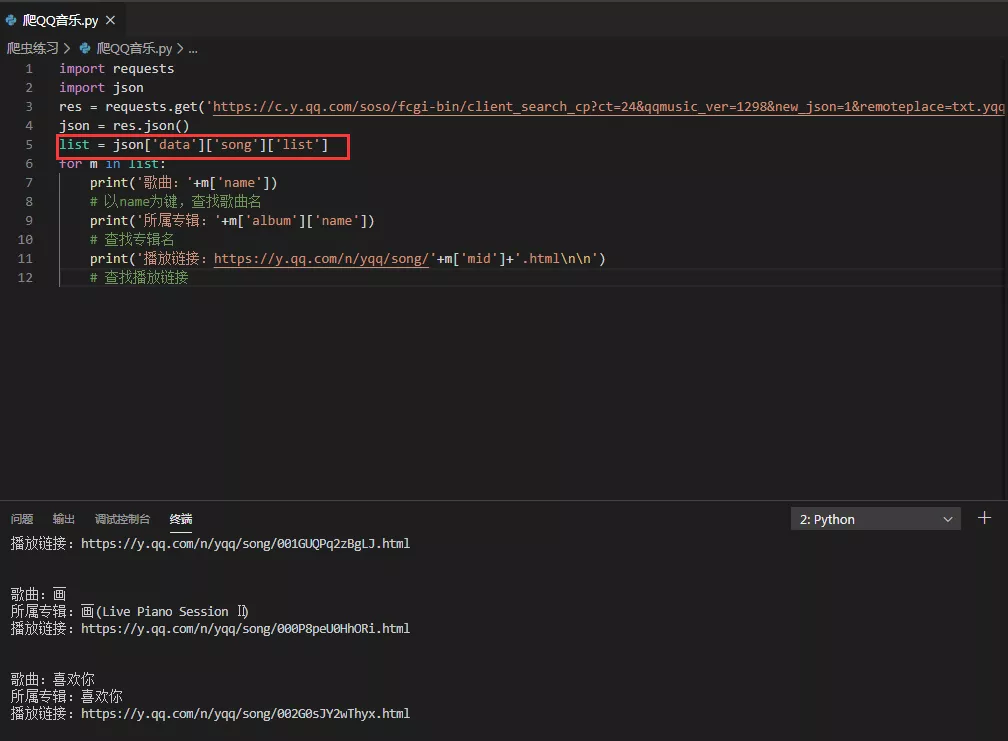
8.通過 json 程式碼實現,首先小試牛刀,爬取第一頁
的數據,url 直接複製過來。成功!
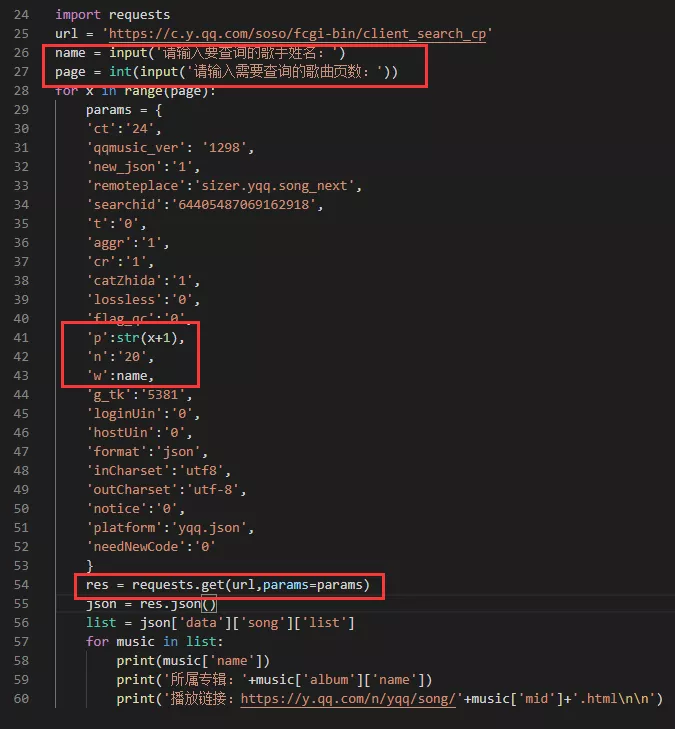
9.引入 params 參數,實現指定歌手、指定頁數的查詢。
注意程式碼url為上一步url中「?」之前的部分, params兩邊的參數都需要加 』』,requests.get 添加 params,參數(也可順便添加 headers 參數)
- 添加存儲功能,保存到本地(Excel)。也可保存為 csv 格式或存入資料庫,操作類似。


【四、總結】
1.爬取 QQ 音樂比爬取豆瓣等網站稍難,所需資訊不在網頁源程式碼,需查看 XHR;
2.通過 XHR 爬取數據一般要使用 json,格式為:
res = requests.get(url)
json = res.json()
list = json[『』][『』]…
3.僅供練手參考,不建議爬取太多數據,給伺服器增大負載;
4.Python 爬取 QQ 音樂數據(二)將為大家帶來如何爬取指定歌曲的歌詞及評論(selenium),並生成詞雲圖(wordcloud),敬請期待。
5.需要本文源碼的話,請在公眾號後台回復「QQ音樂」四個字進行獲取。
看完本文有收穫?請轉發分享給更多的人
IT共享之家
入群請在微信後台回復【入群】

想學習更多Python網路爬蟲與數據挖掘知識,可前往專業網站://pdcfighting.com/

