人聲提取工具Spleeter安裝教程(linux)
在安裝之前,要確保運行Spleeter的電腦系統是64位,Spleeter不支援32位的系統。如何查看?
因為在linux環境下安裝spleeter相對要簡單很多,這篇教程先以Ubuntu20.04系統介紹安裝教程。(在win系統下可以使用VMware虛擬機安裝Ubuntu,之前永恆君也寫過教程。)
在安裝好Ubuntu20.04系統之後,就可以開始下面的步驟了。
安裝步驟
1、下載並安裝Anaconda
1-1 下載
Spleeter是基於python語言的工具,而Anaconda就是可以便捷獲取python包且對包能夠進行管理,同時對環境可以統一管理的發行版本,可以大大減少因為包等依賴項的問題而造成的困擾,提升效率。可以簡單理解,Anaconda可以更方便的進行安裝Spleeter。
進入官網//www.anaconda.com/products/individual

選擇linux – Python 3.7 – 64-Bit (x86) Installer
如果上面的網站訪問慢的話,可以試試這個清華大學的鏡像站//mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
選擇linux的即可
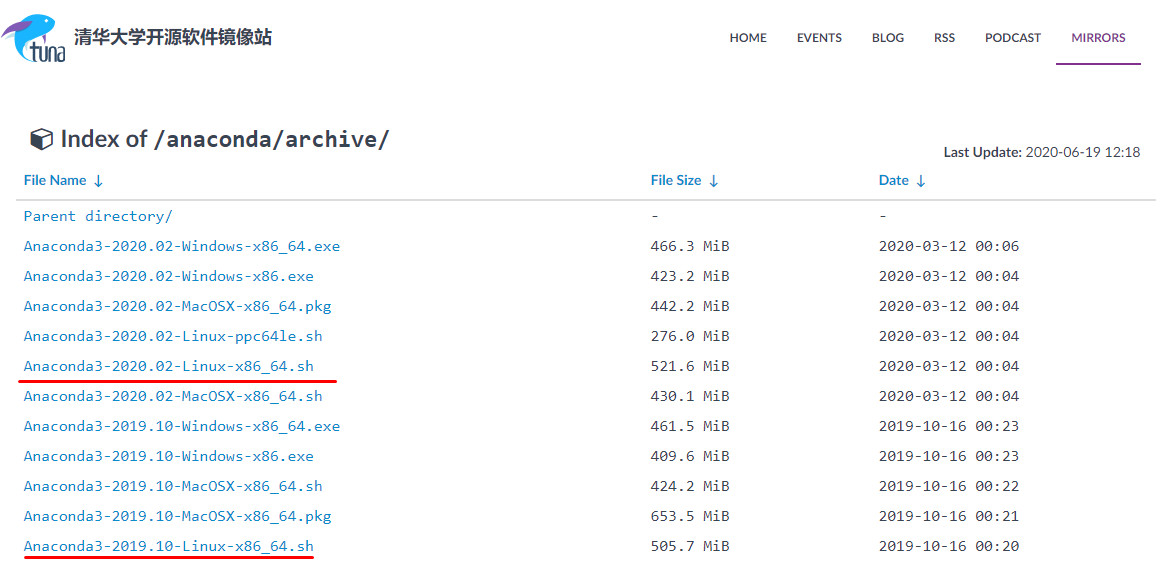
下載下來是一個以.sh結尾的文件,這個是在linux系統中的腳本文件,類似於windows系統中的.exe文件。

1-2 安裝
1)在.sh所在的文件夾點擊右鍵,打開終端,輸入命令 bash + sh文件名,.sh文件名字要換成你自己的,如:
bash Anaconda3-2019.10-Linux-x86_64.sh

2)按照提示,需要看一些條款,一路回車即可。
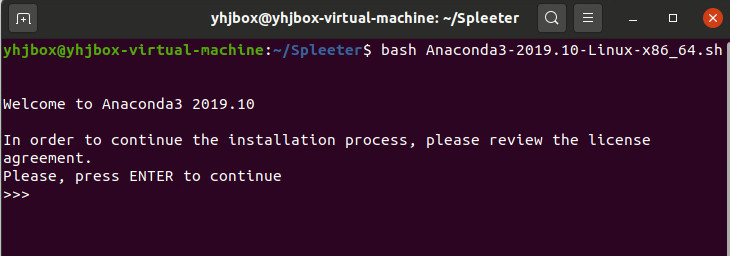
然後會問你是否同意條款,當然輸入yes,不然呢?

系統提示安裝的默認位置,一般直接回車即可
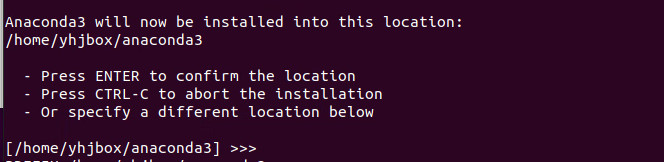
然後就進入安裝的過程,稍等一會

接下來提示是否要初始化,一般輸入yes

到這個介面,就說明安裝成功了。

1-3 修改配置文件condarc
這樣下載比較快。(因為源文件都在國外的伺服器上,速度經常會不穩定)。
在終端裡面輸入命令:
sudo gedit ~/.condarc
或者在主目錄下面,找到.condarc文件並打開

將下面的內容粘貼進去:
channels:
- defaults
show_channel_urls: true
channel_alias: //mirrors.tuna.tsinghua.edu.cn/anaconda
default_channels:
- //mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- //mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- //mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- //mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
- //mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: //mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: //mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: //mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: //mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: //mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: //mirrors.tuna.tsinghua.edu.cn/anaconda/cloud

2、安裝Spleeter
2-1 建議為Spleeter創建單獨的運行環境,名稱取為music,並激活。(這一步非必須,可直接進行步驟2-2安裝Spleeter)
為了程式的穩定性,建議先通過Anaconda創建一個環境專門用來運行Spleeter,這個永恆君命名為music,使用python3.7。
打開終端,輸入
conda activate base
conda create -n music python=3.7 #創建一個python3.7的環境,名字為music

完成之後,激活music環境,終端輸入
conda activate music

2-2 終端輸入下面的命令,安裝Spleeter,這個過程視網路情況,可能需要耐心等待一會。
conda install -c conda-forge spleeter
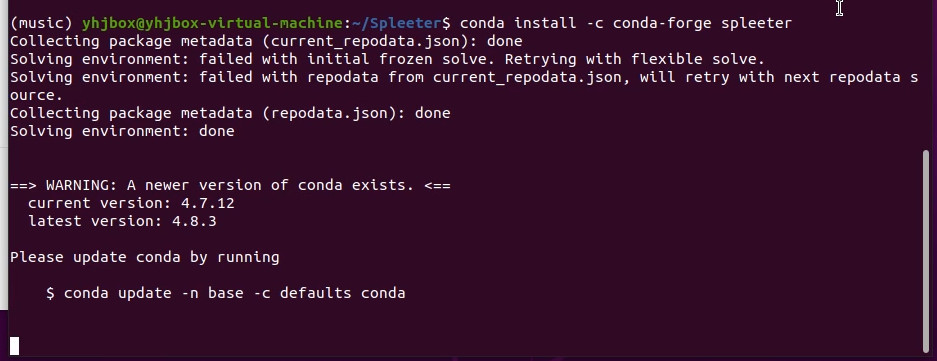
出現下面的提示,就說明安裝完成了。

3、下載訓練模型(一定要注意存放的路徑)
第一次分離音軌前需要給Spleeter一個「示範」,需要有個pretrained models(預訓練模組)。
下載地址:
//github.com/deezer/spleeter/releases

下載圖上2stems,分離人聲的話一般只需要2軌即可。
在主目錄下面新建pretrained_models\2stems路徑文件夾,將下載的模型文件解壓到文件夾裡面。
如果你使用的是4stems、5stems,則要相對應的在pretrained_models文件夾下面建立4stems、5stems文件夾。
4、分離提取人聲
把需要分離的原始音樂文件 ppxhn.mp3 放在主目錄,然後終端鍵入命令運行:
spleeter separate -i ppxhn.mp3 -p spleeter:2stems -o output
使用的是4stems、5stems的話,只需要把上面命令2stems改成4stems或者5stems即可。
出現下面的字樣就說明提取成功了,在主目錄下面會生成一個output\ppxhn的文件夾


accompaniment.wav是提取的背景
vocals.wav是提取的人聲

小結一下
1、安裝Anaconda,修改配置文件condarc。
2、安裝Spleeter
3、下載訓練模型
4、分離提取人聲
其它問題:
1、32位win系統無法使用,64位系統可以使用,建議搭配64位的Python程式或者Anaconda。
2、模型文件始終下載不下來,手動下載並放置到指定文件夾
模型下載地址://github.com/deezer/spleeter/releases
特別地,一般模型下載很慢而且不容易成功完成,可以建議使用GitHub文件加速下載地址轉換://shrill-pond-3e81.hunsh.workers.dev/
轉換後使用idm等下載即可。
下載成功後在主目錄下依次建立文件夾 pretrained_models\2stems,將2stems.tar.gz解壓縮後放置到這個文件夾中即可。
類似地也可建立文件夾並放置模型文件:
pretrained_models\2stems-finetune
pretrained_models\4stems
pretrained_models\4stems-finetune
pretrained_models\5stems
pretrained_models\5stems-finetune
-finetune這種是更為精確的高品質模型,使用方法也一樣。
3、拆分類型選項
4stems、4stems、5stems三種分別對應分成2軌、4軌和5軌
人聲(歌聲)、伴奏分離 (2個音軌)
人聲、鼓、貝斯、其他分離 (4個音軌)
人聲、鼓、貝斯、鋼琴、其他分離 (5個音軌)
4、支援的音頻文件有mp3、wav、ogg
5、一次分離多個文件(比較費資源,不推薦)
spleeter separate \
-i <path/to/audio1.mp3> <path/to/audio2.wav> <path/to/audio3.ogg> \
-o audio_output

