記錄一次Flink作業異常的排查過程
- 2020 年 6 月 17 日
- 筆記
最近2周開始接手apache flink全鏈路監控數據的作業,包括指標統計,業務規則匹配等邏輯,計算結果實時寫入elasticsearch. 昨天遇到生產環境有作業無法正常重啟的問題,我負責對這個問題進行排查跟進。
第一步,基礎排查
首先拿到jobmanager和taskmanager的日誌,我從taskmanager日誌中很快發現2個基礎類型的報錯,一個是npe,一個是索引找不到的異常
elasticsearch sinker在執行寫入數據的前後提供回調介面讓作業開發人員對異常或者成功寫入進行處理,如果在處理異常過程中有異常拋出,那麼框架會讓該task失敗,導致作業重啟。
npe很容易修復,索引找不到是創建索引的服務中的一個小bug,這些都是小問題。
重點是在日誌中我看到另一個錯誤:
java.lang.OutOfMemoryError: unable to create new native thread at java.lang.Thread.start0(Native Method) at java.lang.Thread.start(Unknown Source) at org.apache.flink.runtime.io.network.api.writer.RecordWriter.<init>(RecordWriter.java:122) at org.apache.flink.runtime.io.network.api.writer.RecordWriter.createRecordWriter(RecordWriter.java:321) at org.apache.flink.streaming.runtime.tasks.StreamTask.createRecordWriter(StreamTask.java:1202) at org.apache.flink.streaming.runtime.tasks.StreamTask.createRecordWriters(StreamTask.java:1170) at org.apache.flink.streaming.runtime.tasks.StreamTask.<init>(StreamTask.java:212) at org.apache.flink.streaming.runtime.tasks.StreamTask.<init>(StreamTask.java:190) at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.<init>(OneInputStreamTask.java:52) at sun.reflect.GeneratedConstructorAccessor4.newInstance(Unknown Source) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(Unknown Source) at java.lang.reflect.Constructor.newInstance(Unknown Source) at org.apache.flink.runtime.taskmanager.Task.loadAndInstantiateInvokable(Task.java:1405) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:689) at java.lang.Thread.run(Unknown Source)
這種異常,一般是nproc設置太小導致的,或者物理記憶體耗盡,檢查完ulimit和記憶體,發現都很正常,這就比較奇怪了。
第二步、分析jstack和jmap
perfma有一個產品叫xland,我也是第一次使用,不得不說,確實牛逼,好用!
首先把出問題的taskmanager的執行緒棧資訊和記憶體dump出來,具體命令:
jstatck pid > 生成的文件名 jmap -dump:format=b,file=生成的文件名 進程號
接著把這兩個文件導入xland,xland可以直接看到執行緒總數,可以方便搜索統計執行緒數、實例個數等等
最先發現的問題是這個taskmanager 執行緒總數竟然有17000+,這個數字顯然有點大,這個時候我想看一下,哪一種類型的執行緒比較大,xland可以很方便的搜索,統計,這時候我注意到有一種類型的執行緒非常多,總數15520
更上層的調用資訊看不到了,只看到來自apache http client,根據作業流程,首先想到的就是es sinker的RestHighLevelClient用到這個東西
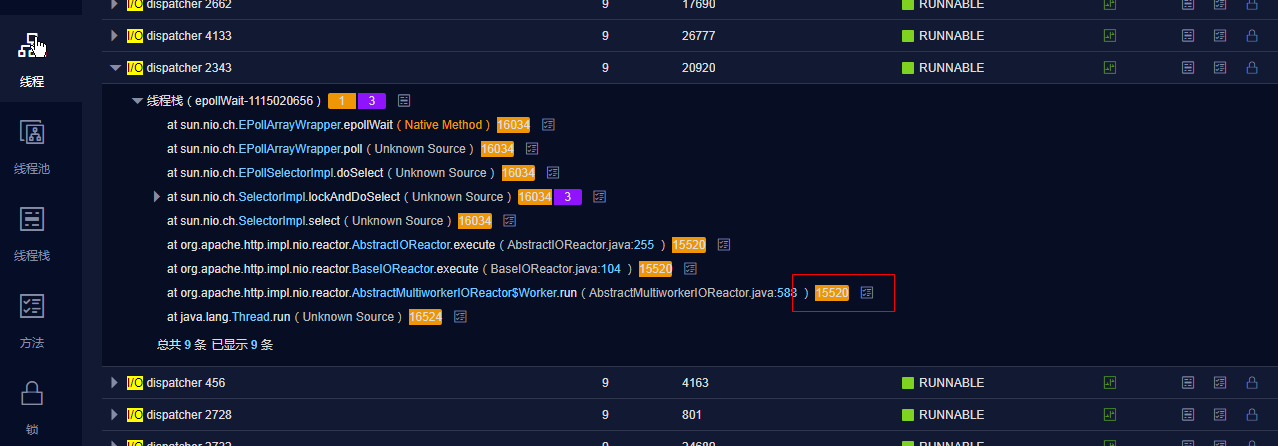
那麼我們在xland中統計RestHighLevelClient對象個數,發現有幾百個,很顯然這裡有問題
第三步、定位具體問題
有了前面xland的幫助,我們很容易定位到是esclient出了問題
在我們的作業裡面有2個地方用到了es client,一個是es sinker,es sinker使用的就是RestHighLevelClient,另一個是我們同學自己寫的一個es client,同樣是使用RestHighLevelClient,在es sinker的ElasticsearchSinkFunction中單獨構造,用於在寫入es前,先搜索一些東西拿來合併,還做了cache
1、懷疑RestHighLevelClient bug
我們通過一個測試,來驗證是不是RestHighLevelClient的問題
啟動一個單純使用es sinker的job,調整並發度,觀察前面出現較多的
I/O dispatcher執行緒的個數,最後發現單個es sinker也會有240+個
I/O dispatcher執行緒,通過調整並發,所有taskmanager的
I/O dispatcher執行緒總數基本和並發成正向比例
停掉寫es作業,此時所有taskmanager是不存在I/O dispatcher執行緒的
看起來I/O dispatcher那種執行緒數量大,似乎是「正常的」
2、殺掉作業,觀察執行緒是否被正常回收
殺掉作業,I/O dispatcher執行緒變成0了,看起來es sinker使用是正常的
這時候基本上可以判斷是我們自己寫的es client的問題。到底是什麼問題呢?
我們再做一個測試進一步確認
3、啟動問題作業,殺死job後,觀察I/O dispatcher執行緒個數
重啟flink的所有taskmanager,給一個「純凈」的環境,發現殺死作業後,還有I/O dispatcher執行緒。
這個測試可以判斷是我們的es client存在執行緒泄漏
四、背後的原理
es sinker本質上是一個RichSinkFunction,RichSinkFunction帶了open 和close 方法,在close方法中,es sinker正確關閉了http client
@Override
public void close() throws Exception {
if (bulkProcessor != null) {
bulkProcessor.close();
bulkProcessor = null;
}
if (client != null) {
client.close();
client = null;
}
callBridge.cleanup();
// make sure any errors from callbacks are rethrown
checkErrorAndRethrow();
}
而我們的es client是沒有被正確關閉的。
具體原理應該是是這樣的,當es sinker出現npe或者寫es rejected等異常時,job會被flink重啟,es sinker這種RichSinkFunction類型的運算元會被flink 調用close關閉釋放掉一些資源,而我們寫在ElasticsearchSinkFunction中es client,是不會被框架關照到的,而這種寫法我們自己也無法預先定義重啟後關閉client的邏輯.
如果在構造時使用單例,理論上應該是可以避免作業反覆重啟時es client不斷被構造導致執行緒泄漏和記憶體泄漏的,但是編寫單例寫法有問題,雖然有double check,但是沒加volatile,同時鎖的是this, 而不是類。
五、小結
1、xland確實好用,排查問題幫助很大
2、flink作業用到的外部客戶端不要單獨構造,要使用類似RichFunction這種方式,提供open,close方法,確保讓資源能夠被flink正確釋放掉。
3、用到的對象,創建的執行緒,執行緒池等等最好都起一個名字,方便使用xland事後排查問題,如果有經驗的話,應該一開始就統計下用於構造es client的那個包裝類對象個數。
一起來學習吧:
PerfMa KO 系列課之 JVM 參數【Memory篇】


