一篇文章教會你使用Python定時抓取微博評論
- 2020 年 6 月 17 日
- 筆記
- Python3, Python入門, Python基礎, Python庫, Python應用, Python開發, Python網路爬蟲, 數據分析, 數據挖掘, 網路爬蟲
【Part1——理論篇】
試想一個問題,如果我們要抓取某個微博大V微博的評論數據,應該怎麼實現呢?最簡單的做法就是找到微博評論數據介面,然後通過改變參數來獲取最新數據並保存。首先從微博api尋找抓取評論的介面,如下圖所示。
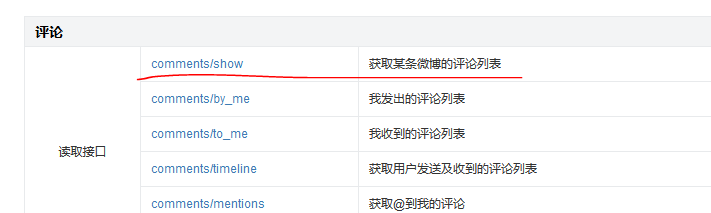
但是很不幸,該介面頻率受限,抓不了幾次就被禁了,還沒有開始起飛,就涼涼了。
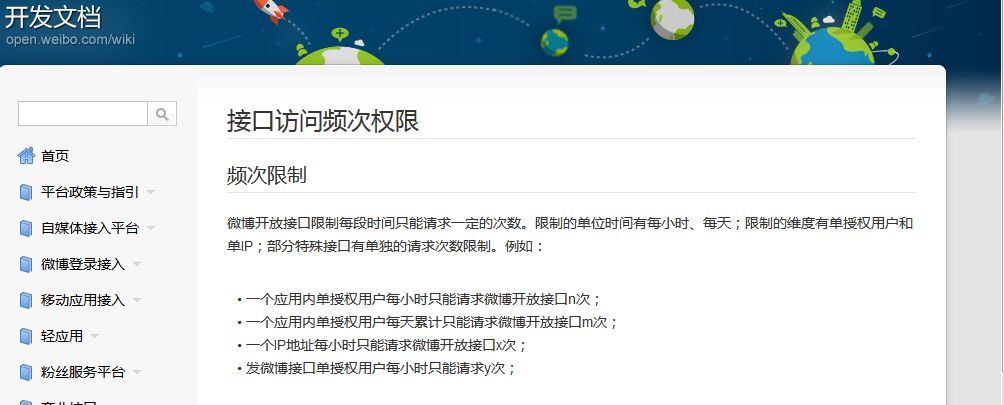
接下來小編又選擇微博的移動端網站,先登錄,然後找到我們想要抓取評論的微博,打開瀏覽器自帶流量分析工具,一直下拉評論,找到評論數據介面,如下圖所示。
之後點擊「參數」選項卡,可以看到參數為下圖所示的內容:

可以看到總共有4個參數,其中第1、2個參數為該條微博的id,就像人的身份證號一樣,這個相當於該條微博的「身份證號」,max_id是變換頁碼的參數,每次都要變化,下次的max_id參數值在本次請求的返回數據中。

【Part2——實戰篇】
有了上文的基礎之後,下面我們開始擼程式碼,使用Python進行實現。

1、首先區分url,第一次不需要max_id,第二次需要用第一次返回的max_id。

2、請求的時候需要帶上cookie數據,微博cookie的有效期比較長,足夠抓一條微博的評論數據了,cookie數據可以從瀏覽器分析工具中找到。

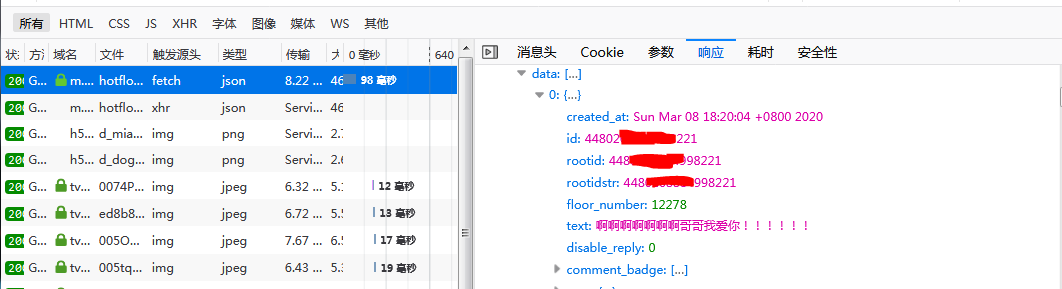
3、然後將返回數據轉換成json格式,取出評論內容、評論者昵稱和評論時間等數據,輸出結果如下圖所示。

4、為了保存評論內容,我們要將評論中的表情去掉,使用正則表達式進行處理,如下圖所示。

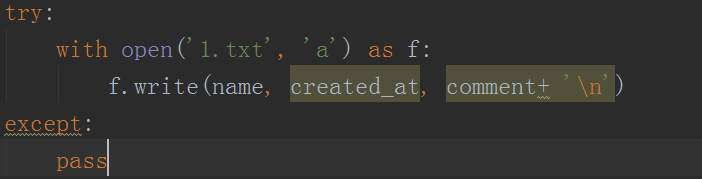
5、之後接著把內容保存到txt文件中,使用簡單的open函數進行實現,如下圖所示。
6、重點來了,通過此介面最多只能返回16頁的數據(每頁20條),網上也有說返回50頁的,但是介面不同、返回的數據條數也不同,所以我加了個for循環,一步到位,遍歷還是很給力的,如下圖所示。

7、這裡把函數命名為job。為了能夠一直取出最新的數據,我們可以用schedule給程式加個定時功能,每隔10分鐘或者半個小時抓1次,如下圖所示。

8、對獲取到的數據,做去重處理,如下圖所示。如果評論已經在裡邊的話,就直接pass掉,如果沒有的話,繼續追加即可。
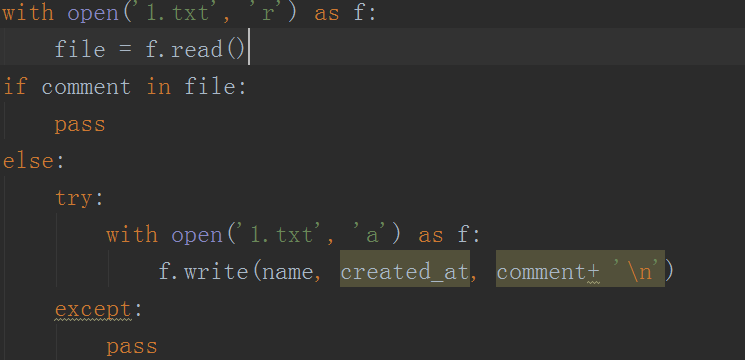
這項工作到此就基本完成了。
【Part3——總結篇】
這種方法雖然抓不全數據,但在這種微博的限制條件下,也是一種比較有效的方法。
最後如果您需要本文程式碼的話,請在後台回復「微博」二字,覺得不錯,記得給個star噢~
看完本文有收穫?請轉發分享給更多的人
IT共享之家
入群請在微信後台回復【入群】

想學習更多Python網路爬蟲與數據挖掘知識,可前往專業網站://pdcfighting.com/

