『圖論』LCA 最近公共祖先
概述篇
LCA (Least Common Ancestors) ,即最近公共祖先,是指這樣的一個問題:在一棵有根樹中,找出某兩個節點 u 和 v 最近的公共祖先。
LCA 可分為在線演算法與離線演算法
- 在線演算法:指程式可以以序列化的方式一個一個處理輸入,也就是說在一開始並不需要知道所有的輸入。
- 離線演算法:指一開始就需要知道問題的所有輸入數據,而在解決一個問題後立即輸出結果。
演算法篇
對於該問題,很容易想到的做法是從 u、v 分別回溯到根節點,然後這兩條路徑中的第一個交點即為 u、v 的最近公共祖先,在一棵平衡二叉樹中,該演算法的時間複雜度可以達到 O(logn)O(logn) ,但是對於某些退化為鏈狀的樹來說,演算法的時間複雜度最壞為 O(n)O(n) ,顯然無法滿足更高頻率的查詢。
本節將介紹幾種比較高效的演算法來解決這一問題,常見的演算法有三種:在線 DFS + ST 演算法、倍增演算法、離線 Tarjan 演算法。
接下來我們來一一解釋這三種 /* 看似高深,其實也不簡單 */ 的演算法。
在線 DFS + ST 演算法
首先看到 ST 你會想到什麼呢?(腦補許久都沒有想到它會是哪個單詞的縮寫)
看過前文 『數據結構』RMQ 問題 的話你便可以明白 ST演算法 的思路啦~
So ,關於 LCA 的這種在線演算法也是可以建立在 RMQ 問題的基礎上咯~
我們設 LCA(T,u,v) 為在有根樹 T 中節點 u、v 的最近公共祖先, RMQ(A,i,j) 為線性序列 A 中區間 [i,j] 上的最小(大)值。
如下圖這棵有根樹:

我們令節點編號滿足父節點編號小於子節點編號(編號條件)
可以看出 LCA(T,4,5) = 2, LCA(T,2,8) = 1, LCA(T,3,9) = 3 。
設線性序列 A 為有根樹 T 的中序遍歷,即 A = [4,2,5,1,8,6,9,3,7] 。
由中序遍歷的性質我們可以知道,任意兩點 u、v 的最近公共祖先總在以該兩點所在位置為端點的區間內,且編號最小。
舉個栗子:
假設 u = 8, v = 7 ,則該兩點所確定的一段區間為 [8,6,9,3,7] ,而區間最小值為 3 ,也就是說,節點 3 為 u、v 的最近公共祖先。
解決區間最值問題我們可以採用 RMQ 問題中的 ST 演算法 。
但是在有些問題中給出的節點並不一定滿足我們所說的父節點編號小於子節點編號,因此我們可以利用節點間的關係建圖,然後採用前序遍歷來為每一個節點重新編號以生成線性序列 A ,於是問題又被轉化為了區間最值的查詢,和之前一樣的做法咯~
時間複雜度: n×O(logn)n×O(logn) 預處理 + O(1)O(1) 查詢
想了解 RMQ 問題 的解法可以戳上面的鏈接哦~
以上部分介紹了 LCA 如何轉化為 RMQ 問題,而在實際中這兩種方案之間可以相互轉化
類比之前的做法,我們如何將一個線性序列轉化為滿足編號條件的有根樹呢?
- 設序列中的最小值為 AkAk ,建立優先順序為 AkAk 的根節點 TkTk
- 將 A[1…k−1]A[1…k−1] 遞歸建樹作為 TkTk 的左子樹
- 將 A[k+1…n]A[k+1…n] 遞歸建樹作為 TkTk 的右子樹
讀者可以試著利用此方法將之前的線性序列 A = [4,2,5,1,8,6,9,3,7] 構造出有根樹 T ,結果一定滿足之前所說的編號條件,但卻不一定唯一。
離線 Tarjan 演算法
Tarjan 演算法是一種常見的用於解決 LCA 問題的離線演算法,它結合了深度優先搜索與並查集,整個演算法為線性處理時間。
首先來介紹一下 Tarjan 演算法的基本思路:
- 任選一個節點為根節點,從根節點開始
- 遍歷該點 u 的所有子節點 v ,並標記 v 已經被訪問過
- 若 v 還有子節點,返回 2 ,否則下一步
- 合併 v 到 u 所在集合
- 尋找與當前點 u 有詢問關係的點 e
- 若 e 已經被訪問過,則可以確定 u、e 的最近公共祖先為 e 被合併到的父親節點
偽程式碼:
Tarjan(u) // merge 和 find 為並查集合併函數和查找函數
{
for each(u,v) // 遍歷 u 的所有子節點 v
{
Tarjan(v); // 繼續往下遍歷
merge(u,v); // 合併 v 到 u 這一集合
標記 v 已被訪問過;
}
for each(u,e) // 遍歷所有與 u 有查詢關係的 e
{
if (e 被訪問過)
u, e 的最近公共祖先為 find(e);
}
}
C++
感覺講到這裡已經沒有其它內容了,但是一定會有好多人沒有理解怎麼辦呢?
我們假設在如下樹中模擬 Tarjan 過程(節點數量少一點可以畫更少的圖o( ̄▽ ̄)o)
存在查詢: LCA(T,3,4)、LCA(T,4,6)、LCA(T,2,1) 。
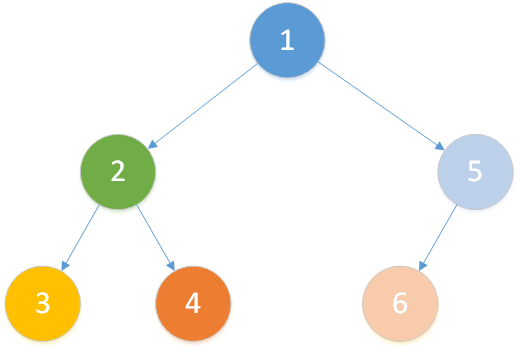
注意:每個節點的顏色代表它當前屬於哪一個集合,橙色線條為搜索路徑,黑色線條為合併路徑。
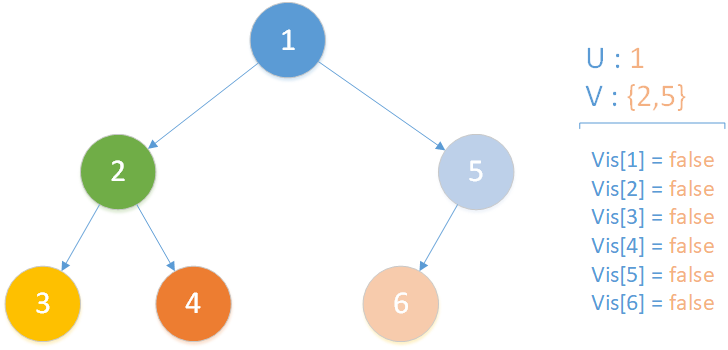
當前所在位置為 u = 1 ,未遍歷孩子集合 v = {2,5} ,向下遍歷。
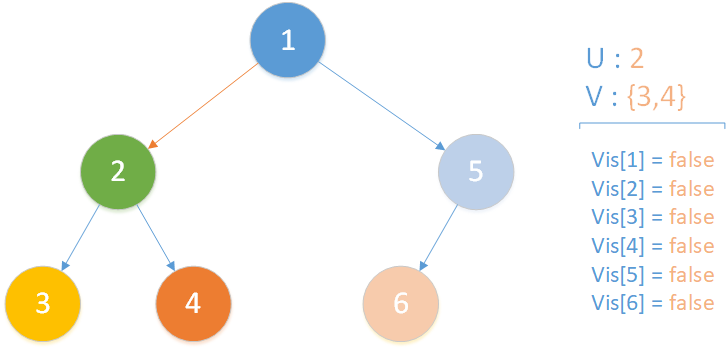
當前所在位置為 u = 2 ,未遍歷孩子集合 v = {3,4} ,向下遍歷。
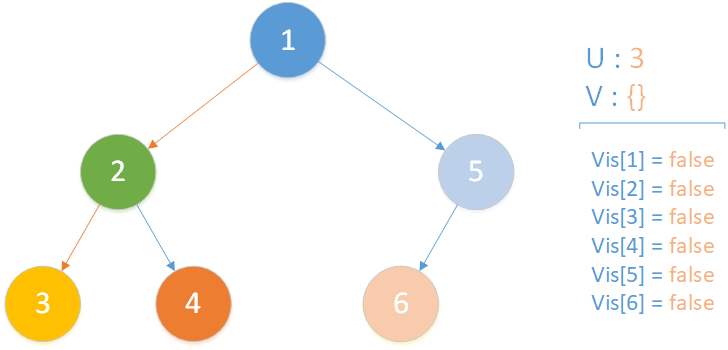
當前所在位置為 u = 3 ,未遍歷孩子集合 v = {} ,遞歸到達最底層,遍歷所有相關查詢發現存在 LCA(T,3,4) ,但是節點 4 此時標記未訪問,因此什麼也不做,該層遞歸結束。
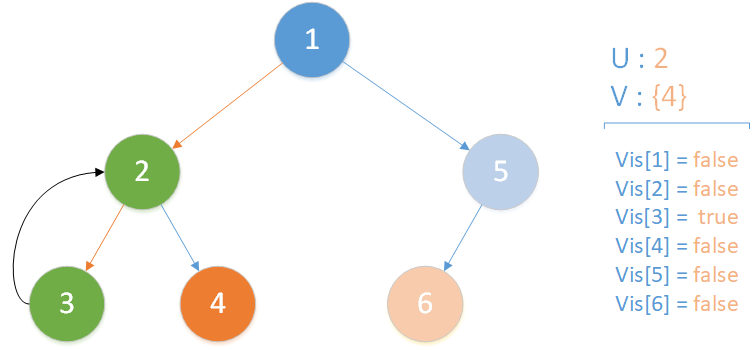
遞歸返回,當前所在位置 u = 2 ,合併節點 3 到 u 所在集合,標記 vis[3] = true ,此時未遍歷孩子集合 v = {4} ,向下遍歷。
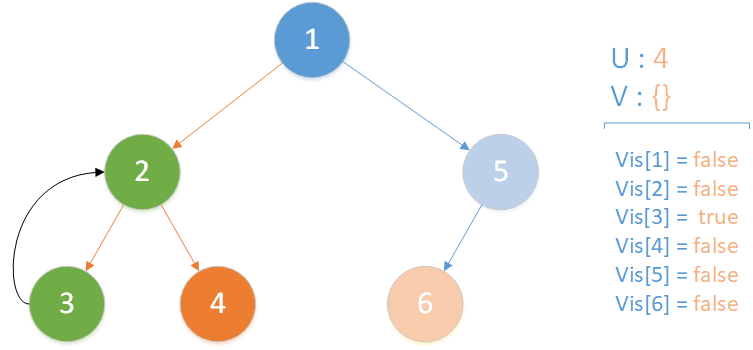
當前所在位置 u = 4 ,未遍歷孩子集合 v = {} ,遍歷所有相關查詢發現存在 LCA(T,3,4) ,且 vis[3] = true ,此時得到該查詢的解為節點 3 所在集合的首領,即 LCA(T,3,4) = 2 ;又發現存在相關查詢 LCA(T,4,6) ,但是節點 6 此時標記未訪問,因此什麼也不做。該層遞歸結束。
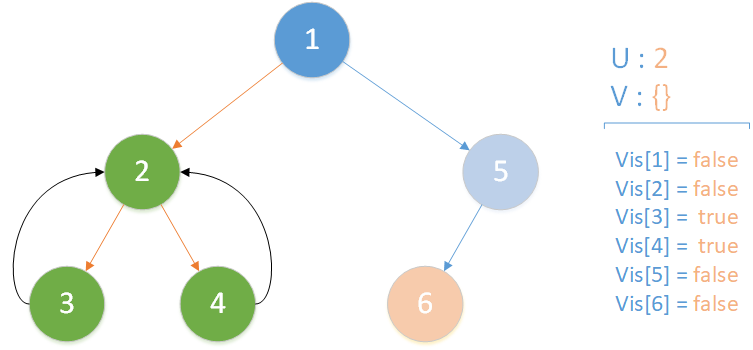
遞歸返回,當前所在位置 u = 2 ,合併節點 4 到 u 所在集合,標記 vis[4] = true ,未遍歷孩子集合 v = {} ,遍歷相關查詢發現存在 LCA(T,2,1) ,但是節點 1 此時標記未訪問,因此什麼也不做,該層遞歸結束。
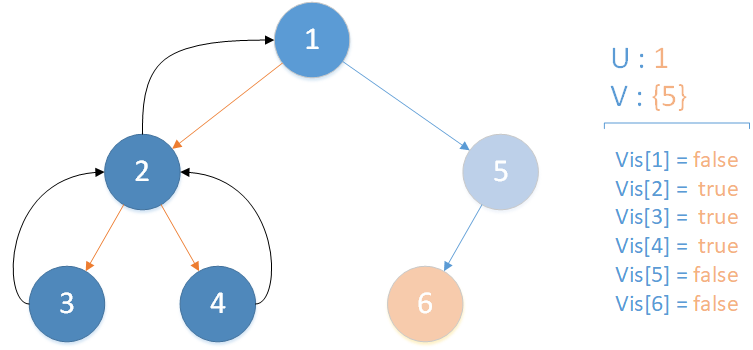
遞歸返回,當前所在位置 u = 1 ,合併節點 2 到 u 所在集合,標記 vis[2] = true ,未遍歷孩子集合 v = {5} ,繼續向下遍歷。
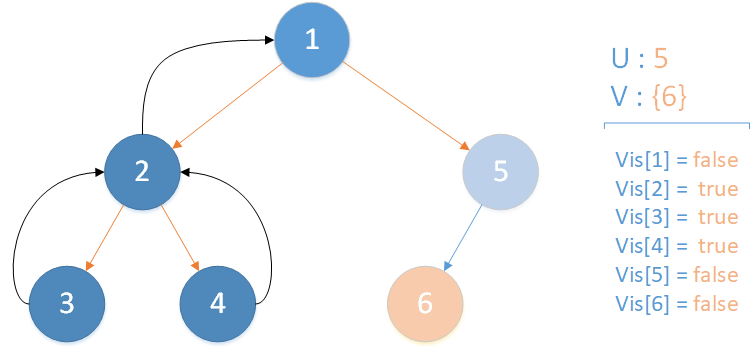
當前所在位置 u = 5 ,未遍歷孩子集合 v = {6} ,繼續向下遍歷。
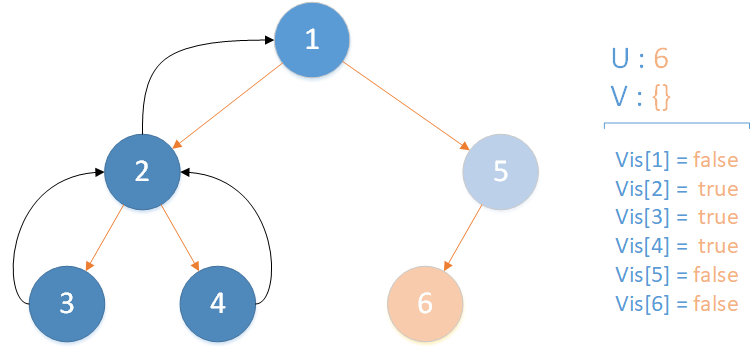
當前所在位置 u = 6 ,未遍歷孩子集合 v = {} ,遍歷相關查詢發現存在 LCA(T,4,6) ,且 vis[4] = true ,因此得到該查詢的解為節點 4 所在集合的首領,即 LCA(T,4,6) = 1 ,該層遞歸結束。
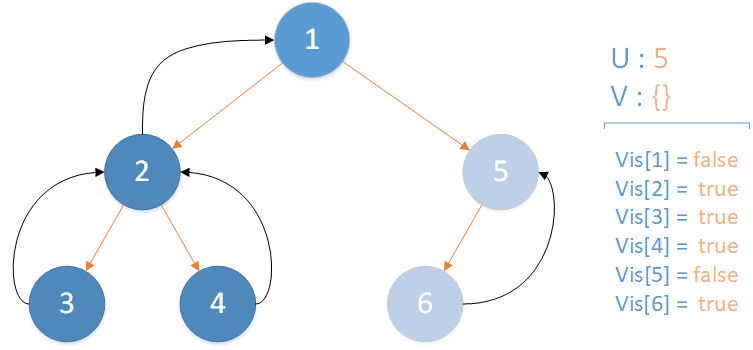
遞歸返回,當前所在位置 u = 5 ,合併節點 6 到 u 所在集合,並標記 vis[6] = true ,未遍歷孩子集合 v = {} ,無相關查詢因此該層遞歸結束。
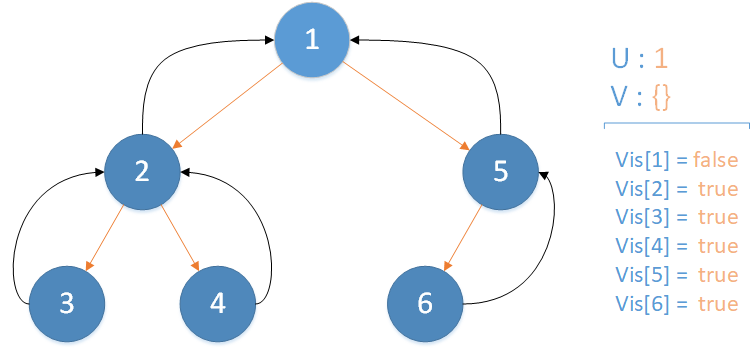
遞歸返回,當前所在位置 u = 1 ,合併節點 5 到 u 所在集合,並標記 vis[5] = true ,未遍歷孩子集合 v = {} ,遍歷相關查詢發現存在 LCA(T,2,1) ,此時該查詢的解便是節點 2 所在集合的首領,即 LCA(T,2,1) = 1 ,遞歸結束。
至此整個 Tarjan 演算法便結束啦~
PS:不要在意最終根節點的顏色和其他節點顏色有一點點小小差距,可能是在染色的時候沒仔細看,總之就這樣咯~
PPS:所謂的首領就是、就是首領啦~
倍增演算法
哇!還有一個倍增演算法以後繼續補充吧!
總結篇
對於不同的 LCA 問題我們可以選擇不同的演算法。
假若一棵樹存在動態更新,此時離線演算法就顯得有點力不從心了,但是在其他情況下,離線演算法往往效率更高(雖然不能保證得到解的順序與輸入一致,不過我們有 sort 呀)
總之,喜歡哪種風格的 code 是我們自己的意願咯~
另外, LCA 和 RMQ 問題是兩個非常基礎的問題,很多複雜問題都可以轉化為這兩類問題來解決。(當然這兩類問題之間也可以相互轉化啦~)
參考資料
OI wiki //oi-wiki.org/graph/lca/
//blog.csdn.net/my_sunshine26/article/details/72717112
//wizardforcel.gitbooks.io/the-art-of-programming-by-july/content/03.03.html

