如何用互動式特徵工程工具進行數據分析處理
【摘要】 根據業界知名分析機構的調查發現,在機器學習日常開發工作中,數據預處理和特徵工程(涉及數據的分析和處理)約佔工作量的60%以上,對於機器學習來說至關重要。
數據分析和處理的問題與挑戰
近年來,越來越多的企業使用機器學習技術進行智慧化的決策支援。機器學習通過使用演算法來識別數據中的模式,並使用這些模式創建一個可以進行預測的數據模型,這個流程通常包含數據預處理,特徵工程,演算法開發,模型評估等多個環節。根據業界知名分析機構的調查發現,在機器學習日常開發工作中,數據預處理和特徵工程(涉及數據的分析和處理)約佔工作量的60%以上,對於機器學習來說至關重要。
1.1品質參差不齊的數據
數據品質是數據管理中的一個非常重要的問題,因為臟數據通常會導致不精確的數據分析,從而引發不正確的業務決策。臟數據通常來源於數據錄入過程中的人工錯誤或系統資訊變化數據未及時更新的一些過期數據。多項調查顯示臟數據是數據科學家普遍面臨的障礙,毫無疑問,提供有效的數據清洗解決方案十分具有挑戰,往往需要較深的理論知識和工程經驗。
1.2 數據的可視化探索分析
相比於原始的數據,數據的可視化的圖表可以更好的提供解釋和理解。數據的可視化不僅可以提供快速清晰的資訊理解,還可以用於識別數據變化的趨勢及數據資產之間的關係和模式。雖然數據可視化十分有用,手工構建圖表往往十分耗時和繁瑣。
1.3 多樣化的特徵工程
特徵工程是將原始數據轉換成特徵的數據處理過程,其目的是為了更好的表徵數據和模型,提升模型預測和評估的精度。轉換形成的特徵好壞與數據/模型密切相關,由於數據和模型的多樣性,因此很難提取出通用的特徵工程技術,適用於所有的項目。數據科學家往往需要結合應用領域及數據的特點,反覆不斷的迭代開發,驗證,形成特定於具體數據和模型的特徵工程。
1.4 容納大規模的數據分析處理平台
隨著數據規模的不斷擴大,現有的數據分析和處理能力受限於單機的記憶體容量,很難進行伸縮。如何將開發探索階段的小樣本數據分析和處理能力伸縮到產品化場景下的大數據樣本,是越來越多企業面臨的巨大的挑戰。
NAIE互動式特徵工程介紹
為了應對數據分析和處理的挑戰,華為NAIE產品基於開源jupyterlab項目,沉澱內部多年的數據分析和處理經驗,打造了NAIE互動式特徵工程。NAIE互動式特徵工程旨在降低數據分析處理的門檻,提升數據分析處理的效率。
2.1 零編碼的數據可視化探索
數據探索部分主要包含數據的描述性統計分析,數據的可視化圖表分析,數據的特徵關係分析三大部分。
通過數據的描述性統計分析可以進行數據的基礎統計量分析,數據的空值和無效值的分布分析,原始數據的表格預覽。
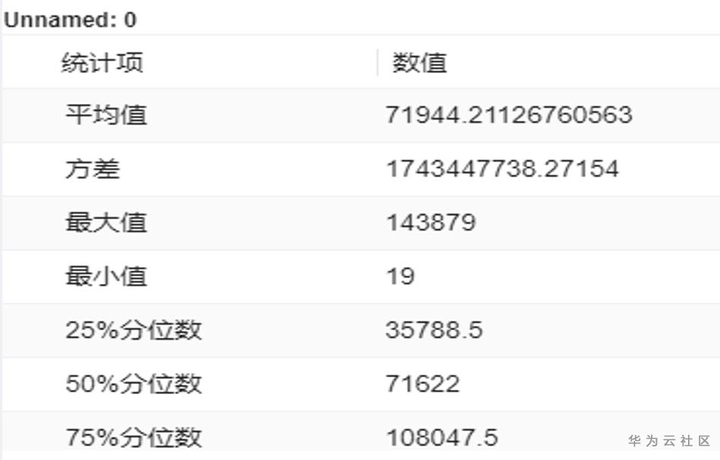 基礎統計量分析
基礎統計量分析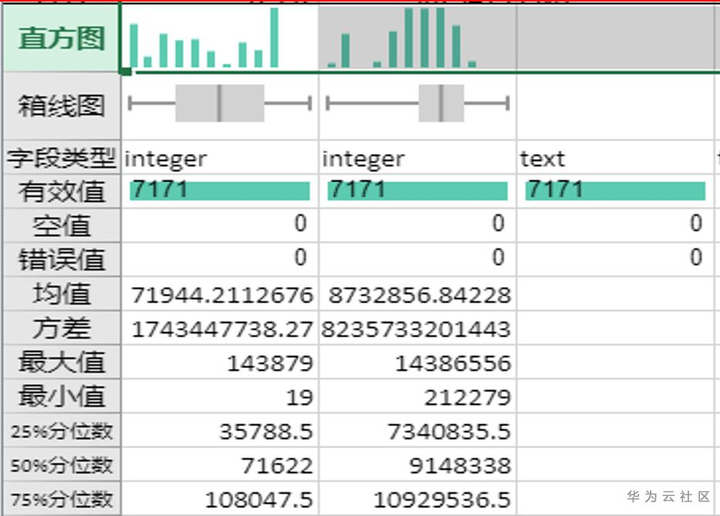 數據空值無效值分布分析
數據空值無效值分布分析 原始數據在線表格預覽
原始數據在線表格預覽
通過數據的可視化圖表分析可以根據數據一鍵式生成散點圖,折線圖,直方圖,箱線圖等多種圖表,通過圖表直觀輔助分析。
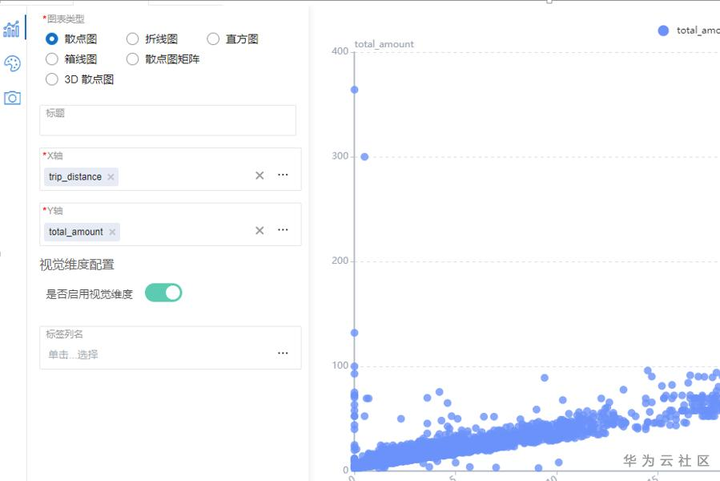 可視化圖表分析
可視化圖表分析
通過數據的特徵關係分析可以使用卡方檢測,F檢驗,資訊增益,遞歸消除特徵等多種演算法進行特徵選擇分析,通過ACE演算法分析特徵和標籤之間的非線性關係。
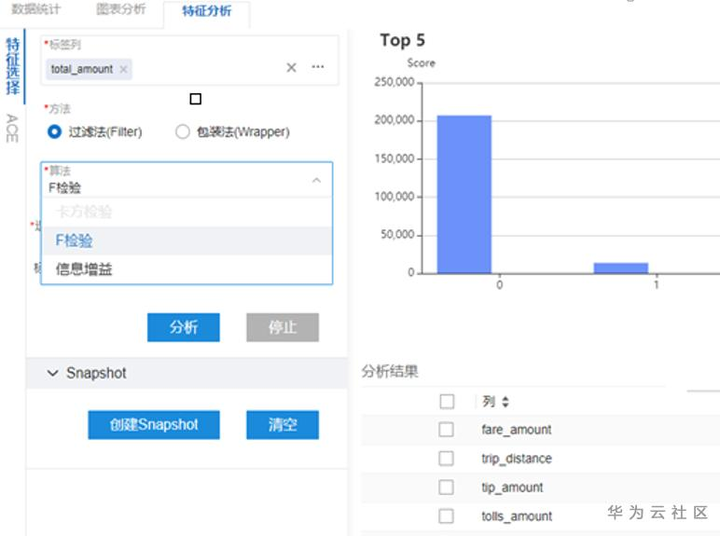 特徵關係分析
特徵關係分析
2.2 豐富多樣的數據處理能力
NAIE互動式特徵工程內置了數據取樣,數據增強,數據清洗,特徵轉換,特徵選擇,特徵提取等常用的數據處理運算元,用戶可以根據需要通過介面點擊操作即可完成常用的數據處理。
通過數據取樣在不引入外部數據的情況下調整數據樣本數目和類分布。

通過數據增強引入外部數據擴展當前數據集的樣本數目或欄位數目。
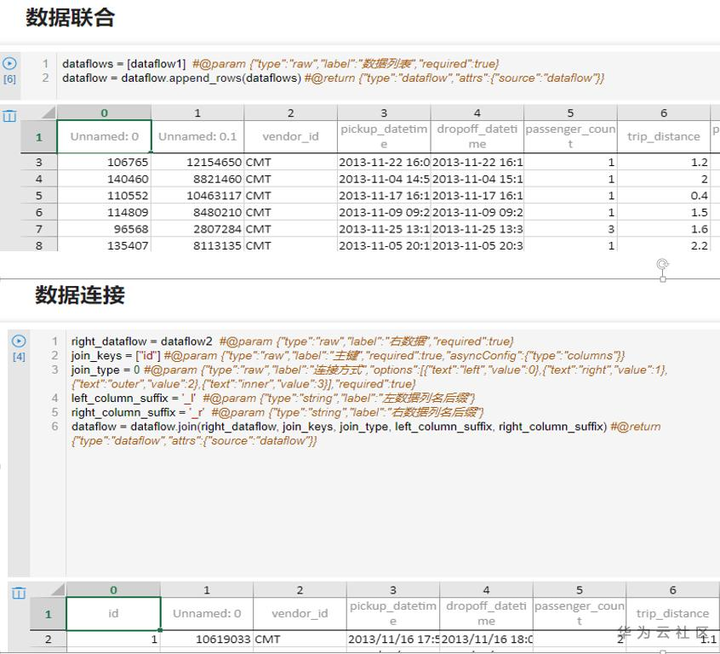
通過數據清洗對數據進行審查和校驗,刪除重複資訊,糾正錯誤,處理無效值和缺失值,提供數據的一致性。

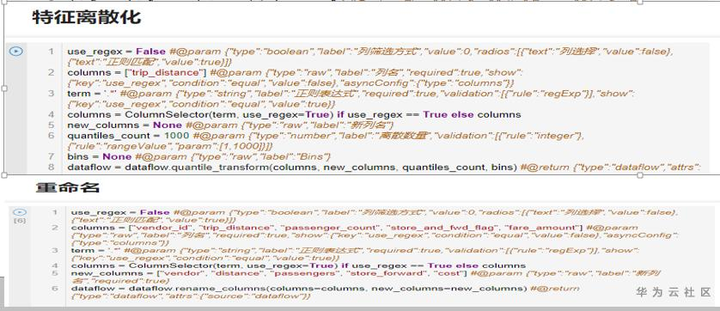
通過特徵轉換對現有的特徵進行歸一化或編碼等變換操作,便於更好的表徵學習的問題。

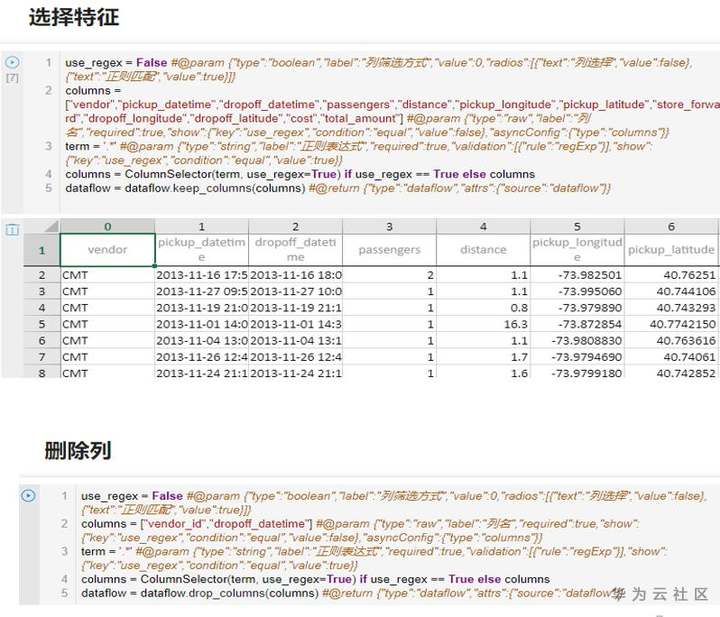
通過特徵選擇剔除不相關或冗餘的特徵,提高模型精度,減少模型運行時間,增強模型的可解釋性。
通過特徵提取從原始數據中構建出富含資訊且不冗餘的特徵。
2.3 可伸縮的數據處理引擎
NAIE互動式特徵工程預置python3和pyspark兩種數據處理引擎,python3引擎使用開源pandas數據處理框架進行數據處理,一般用於中小規模(10G以下)的數據處理。pyspark使用開源spark大規模數據(10G-500G)處理引擎進行數據處理,通過分散式數據處理能力,支援可伸縮的大數據處理。NAIE特徵工程內置的數據處理運算元使用統一的對外SDK,適配不同的數據處理實現,可以滿足在探索階段使用python處理引擎,在產品階段大數據場景下程式碼不做任何修改無縫適配到spark處理引擎下進行大規模可伸縮的數據處理。
NAIE互動式特徵工程的應用
在日常出行時,當打開某款打車軟體的時候,輸入起始地點和結束地點,打車軟體系統會自動估算出一個價格,用戶可以根據價格選擇是否乘坐或選擇乘坐哪種類型。
車費除了依賴於乘車距離,還與乘車時間,乘車地點等多種因素有關,沒有一個精確的公式可以計算。
通過機器學習學習歷史數據訓練模型進行預測是越來越流行的做法,通常的機器學習工作流中包含數據的預處理,模型訓練,模型評估,模型部署預測等幾個環節,其中數據預處理環節對於整個過程來說至關重要,以下展示如何使用NAIE互動式特徵工程進行計程車乘車記錄數據的預處理過程。
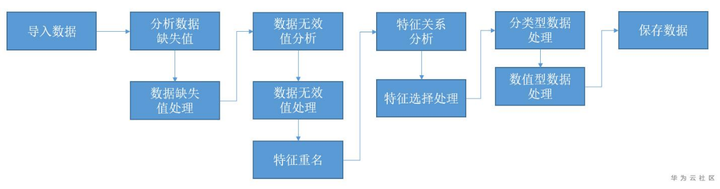
通過使用NAIE互動式特徵工程,用戶可以通過介面操作一鍵式完成數據的可視化探索,了解數據的統計分布,品質情況,特徵間的關係等,從而直觀的獲取數據的洞察結果。結合NAIE互動式特徵工程沉澱的多種開箱即用的數據處理能力,用戶只需要通過菜單選擇相關的數據處理運算元,即可完成複雜的數據處理任務。相比於傳統的開發程式碼進行數據分析和處理方式,NAIE互動式特徵工程極大的降低了數據分析處理的門檻,通過復用華為工程師在此領域沉澱的專家經驗,對數據分析和處理的效率也有極大的提升。



