數據湖&數據倉庫,別再傻傻分不清了
摘要:什麼是數據湖?它有什麼作用?今天將由華為雲技術專家從理論出發,將問題抽絲剝繭,從技術維度娓娓道來。
什麼是數據湖
如果需要給數據湖下一個定義,可以定義為這樣:數據湖是一個存儲企業的各種各樣原始數據的大型倉庫,其中的數據可供存取、處理、分析及傳輸。
數據湖從企業的多個數據源獲取原始數據,並且針對不同的目的,同一份原始數據還可能有多種滿足特定內部模型格式的數據副本。因此,數據湖中被處理的數據可能是任意類型的資訊,從結構化數據到完全非結構化數據。
企業對數據湖寄予厚望,希望它能幫助用戶快速獲取有用資訊,並能將這些資訊用於數據分析和機器學習演算法,以獲得與企業運行相關的洞察力。
數據湖與企業的關係
數據湖能給企業帶來多種能力,例如,能實現數據的集中式管理,在此之上,企業能挖掘出很多之前所不具備的能力。
另外,數據湖結合先進的數據科學與機器學習技術,能幫助企業構建更多優化後的運營模型,也能為企業提供其他能力,如預測分析、推薦模型等,這些模型能刺激企業能力的後續增長。
企業數據中隱藏著多種能力,然而,在重要數據能夠被具備商業數據洞察力的人使用之前,人們無法利用它們來改善企業的商業表現。
數據湖如何幫助企業
長期以來,企業一直試圖找到一個統一的模型來表示企業中所有實體。這個任務有極大的挑戰性,原因有很多,下面列舉了其中的一部分:
1. 一個實體在企業中可能有多種表示形式,因此可能不存在某個完備的模型來統一表示實體。
2. 不同的企業應用程式可能會基於特定的商業目標來處理實體,這意味著處理實體時會採用或排斥某些企業流程。
3. 不同應用程式可能會對每個實體採用不同的訪問模式及存儲結構。
這些問題已困擾企業多年,並阻礙了業務處理、服務定義及術語命名等事務的標準化。
從數據湖的角度來看,我們正在以另外一種方式來看待這個問題。使用數據湖,隱式實現了一個較好的統一數據模型,而不用擔心對業務程式產生實質性影響。這些業務程式則是解決具體業務問題的「專家」。數據湖基於從實體所有者相關的所有系統中捕獲的全量數據來儘可能「豐滿」地表示實體。
因為在實體表示方面更優且更完備,數據湖確實給企業數據處理與管理帶來了巨大的幫助,使得企業具備更多關於企業增長方面的洞察力,幫助企業達成其商業目標。
數據湖的優點
企業會在其多個業務系統中產生海量數據,隨著企業體量增大,企業也需要更智慧地處理這些橫跨多個系統的數據。
一種最基本的策略是採用一個單獨的領域模型,它能精準地描述數據並能代表對總體業務最有價值的那部分數據。這些數據指的是前面提到的企業數據。
對企業數據進行了良好定義的企業當然也有一些管理數據的方法,因此企業數據定義的更改能保持一致性,企業內部也很清楚系統是如何共享這些資訊的。
在這種案例中,系統被分為數據擁有者(data owner)及數據消費者(data consumer)。對於企業數據來說,需要有對應的擁有者,擁有者定義了數據如何被其他消費系統獲取,消費系統扮演著消費者的角色。
一旦企業有了對數據和系統的明晰定義,就可以通過該機制利用大量的企業資訊。該機制的一種常見實現策略是通過構建企業級數據湖來提供統一的企業數據模型,在該機制中,數據湖負責捕獲數據、處理數據、分析數據,以及為消費者系統提供數據服務。
數據湖能從以下方面幫助到企業:
1. 實現數據治理(data governance)與數據世系。
2. 通過應用機器學習與人工智慧技術實現商業智慧。
3. 預測分析,如領域特定的推薦引擎。
4. 資訊追蹤與一致性保障。
5. 根據對歷史的分析生成新的數據維度。
6. 有一個集中式的能存儲所有企業數據的數據中心,有利於實現一個針對數據傳輸優化的數據服務。
7. 幫助組織或企業做出更多靈活的關於企業增長的決策。
在本節中,我們討論數據湖應該具備哪些能力。後續將會討論和評述數據湖是如何工作的,以及應該如何去理解其工作機制。
數據湖是如何工作的
為了準確理解數據湖能給企業帶來哪些好處,理解數據湖的工作機制以及構建功能齊全的數據湖需要哪些組件就顯得尤為重要了。在一頭扎進數據湖架構細節之前,不妨先來了解數據湖背景中的數據生命周期。
在一個較高的層面來看,數據湖中數據生命周期如圖所示。

上述生命周期也可稱為數據在數據湖中的多個不同階段。每個階段所需的數據和分析方法也有所不同。數據處理與分析既可按批量(batch)方式處理,也可以按近實時(near-real-time)方式處理。
數據湖的實現需要同時支援這兩種處理方式,因為不同的處理方式服務於不同的場景。處理方式(批處理或近實時處理)的選擇也依賴數據處理或分析任務的計算量,因為很多複雜計算不可能在近實時處理模式中完成,而在一些案例中,則不能接受較長的處理周期。
同樣,存儲系統的選擇還依賴於數據訪問的要求。例如,如果希望存儲數據時便於通過SQL查詢訪問數據,則選擇的存儲系統必須支援SQL介面。
如果數據訪問要求提供數據視圖,則涉及將數據存儲為對應的形式,即數據可以作為視圖對外提供,並提供便捷的可管理性和可訪問性。
最近出現的一個日漸重要的趨勢是通過服務(service)來提供數據,它涉及在輕量級服務層上對外公開數據。每個對外公開的服務必須準確地描述服務功能並對外提供數據。此模式還支援基於服務的數據集成,這樣其他系統可以消費數據服務提供的數據。
當數據從採集點流入數據湖時,它的元數據被捕獲,並根據其生命周期中的數據敏感度從數據可追溯性、數據世系和數據安全等方面進行管理。
數據世系被定義為數據的生命周期,包括數據的起源以及數據是如何隨時間移動的。它描述了數據在各種處理過程中發生了哪些變化,有助於提供數據分析流水線的可見性,並簡化了錯誤溯源。可追溯性是通過標識記錄來驗證數據項的歷史、位置或應用的能力。——維基百科
數據湖與數據倉庫的區別
很多時候,數據湖被認為與數據倉庫是等同的。實際上數據湖與數據倉庫代表著企業想達成的不同目標。
下表中顯示了兩者的關鍵區別。
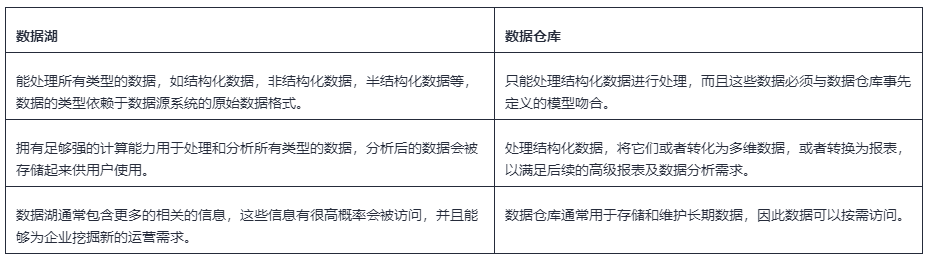
從圖表來看,數據湖與數據倉庫的差別很明顯。然而,在企業中兩者的作用是互補的,不應認為數據湖的出現是為了取代數據倉庫,畢竟兩者的作用是截然不同的。
數據湖的構建方法
不同的組織有不同的偏好,因此它們構建數據湖的方式也不一樣。構建方法與業務、處理流程及現存系統等因素有關。
簡單的數據湖實現幾乎等價於定義一個中心數據源,所有的系統都可以使用這個中心數據源來滿足所有的數據需求。雖然這種方法可能很簡單,也很划算,但它可能不是一個非常實用的方法,原因如下:
1. 只有當這些組織重新開始構建其資訊系統時,這種方法才可行。
2. 這種方法解決不了與現存系統相關的問題。
3. 即使組織決定用這種方法構建數據湖,也缺乏明確的責任和關注點隔離(responsibility and separation of concerns)。
4. 這樣的系統通常嘗試一次性完成所有的工作,但是最終會隨著數據事務、分析和處理需求的增加而分崩離析。
更好的構建數據湖的策略是將企業及其資訊系統作為一個整體來看待,對數據擁有關係進行分類,定義統一的企業模型。
這種方法雖然可能存在流程相關的挑戰,並且可能需要花費更多的精力來對系統元素進行定義,但是它仍然能夠提供所需的靈活性、控制和清晰的數據定義以及企業中不同系統實體之間的關注點隔離。
這樣的數據湖也可以有獨立的機制來捕獲、處理、分析數據,並為消費者應用程式提供數據服務。



