結合中斷上下文切換和進程上下文切換分析Linux內核的一般執行過程
結合中斷上下文切換和進程上下文切換分析Linux內核的一般執行過程
一. 實驗準備
- 詳細要求
結合中斷上下文切換和進程上下文切換分析Linux內核一般執行過程
- 以fork和execve系統調用為例分析中斷上下文的切換
- 分析execve系統調用中斷上下文的特殊之處
- 分析fork子進程啟動執行時進程上下文的特殊之處
- 以系統調用作為特殊的中斷,結合中斷上下文切換和進程上下文切換分析Linux系統的一般執行過程
完成一篇部落格總結分析Linux系統的一般執行過程,以期對Linux系統的整體運作形成一套邏輯自洽的模型,並能將所學的各種OS和Linux內核知識/原理融通進模型中
- 實驗環境
發行版本:Ubuntu 18.04.4 LTS
處理器:Intel® Core™ i7-8850H CPU @ 2.60GHz × 3
圖形卡:Parallels using AMD® Radeon pro 560x opengl engine
GNOME:3.28.2
二. 實驗過程
I 分析中斷上下文的切換
中斷髮生以後,CPU跳到內核設置好的中斷處理程式碼中去,由這部分內核程式碼來處理中斷。這個處理過程中的上下文就是中斷上下文。
幾乎所有的體系結構,都提供了中斷機制。當硬體設備想和系統通訊的時候,它首先發出一個非同步的中斷訊號去打斷處理器的執行,繼而打斷內核的執行。中斷通常對應著一個中斷號,內核通過這個中斷號找到中斷服務程式,調用這個程式響應和處理中斷。當你敲擊鍵盤時,鍵盤控制器發送一個中斷訊號告知系統,鍵盤緩衝區有數據到來,內核收到這個中斷號,調用相應的中斷服務程式,該服務程式處理鍵盤數據然後通知鍵盤控制器可以繼續輸入數據了。為了保證同步,內核可以使用中止—既可以停止所有的中斷也可以有選擇地停止某個中斷號對應的中斷,許多作業系統的中斷服務程式都不在進程上下文中執行,它們在一個與所有進程無關的、專門的中斷上下文中執行。之所以存在這樣一個專門的執行環境,為了保證中斷服務程式能夠在第一時間響應和處理中斷請求,然後快速退出。
對同一個CPU來說,中斷處理比進程擁有更高的優先順序,所以中斷上下文切換並不會與進程上下文切換同時發生。由於中斷程式會打斷正常進程的調度和運行,大部分中斷處理程式都短小精悍,以便儘可能快的執行結束。
一個進程的上下文可以分為三個部分:用戶級上下文、暫存器上下文以及系統級上下文。
用戶級上下文: 正文、數據、用戶堆棧以及共享存儲區;
暫存器上下文: 通用暫存器、程式暫存器(IP)、處理器狀態暫存器(EFLAGS)、棧指針(ESP);
系統級上下文: 進程式控制制塊task_struct、記憶體管理資訊(mm_struct、vm_area_struct、pgd、pte)、內核棧。
當發生進程調度時,進行進程切換就是上下文切換(context switch)。作業系統必須對上面提到的全部資訊進行切換,新調度的進程才能運行。而系統調用進行的是模式切換(mode switch)。模式切換與進程切換比較起來,容易很多,而且節省時間,因為模式切換最主要的任務只是切換進程暫存器上下文的切換。
II 分析fork子進程啟動執行時進程上下文及其特殊之處
fork()系統調用會通過複製一個現有進程來創建一個全新的進程. 進程被存放在一個叫做任務隊列的雙向循環鏈表當中。鏈表當中的每一項都是類型為task_struct成為進程描述符的結構。
首先我們來看一段程式碼
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(){
pid_t pid;
char *message;
int n;
pid = fork();
if(pid<0){
perror("fork failed");
exit(1);
}
if (pid == 0){
message = "this is the child \n";
n=6;
}else {
message = "this is the parent \n";
n=3;
}
for(;n>0;n--){
printf("%s",message);
sleep(1);
}
return 0;
}
在Linux環境中編寫和執行
# 創建一個C文件,名為t.c,將上面的程式碼拷貝進去
touch t.c
# 進行編譯
gcc t.c
# 執行
./a.out

之所以輸出是這樣的結果,是因為程式的執行流程如下圖所示:
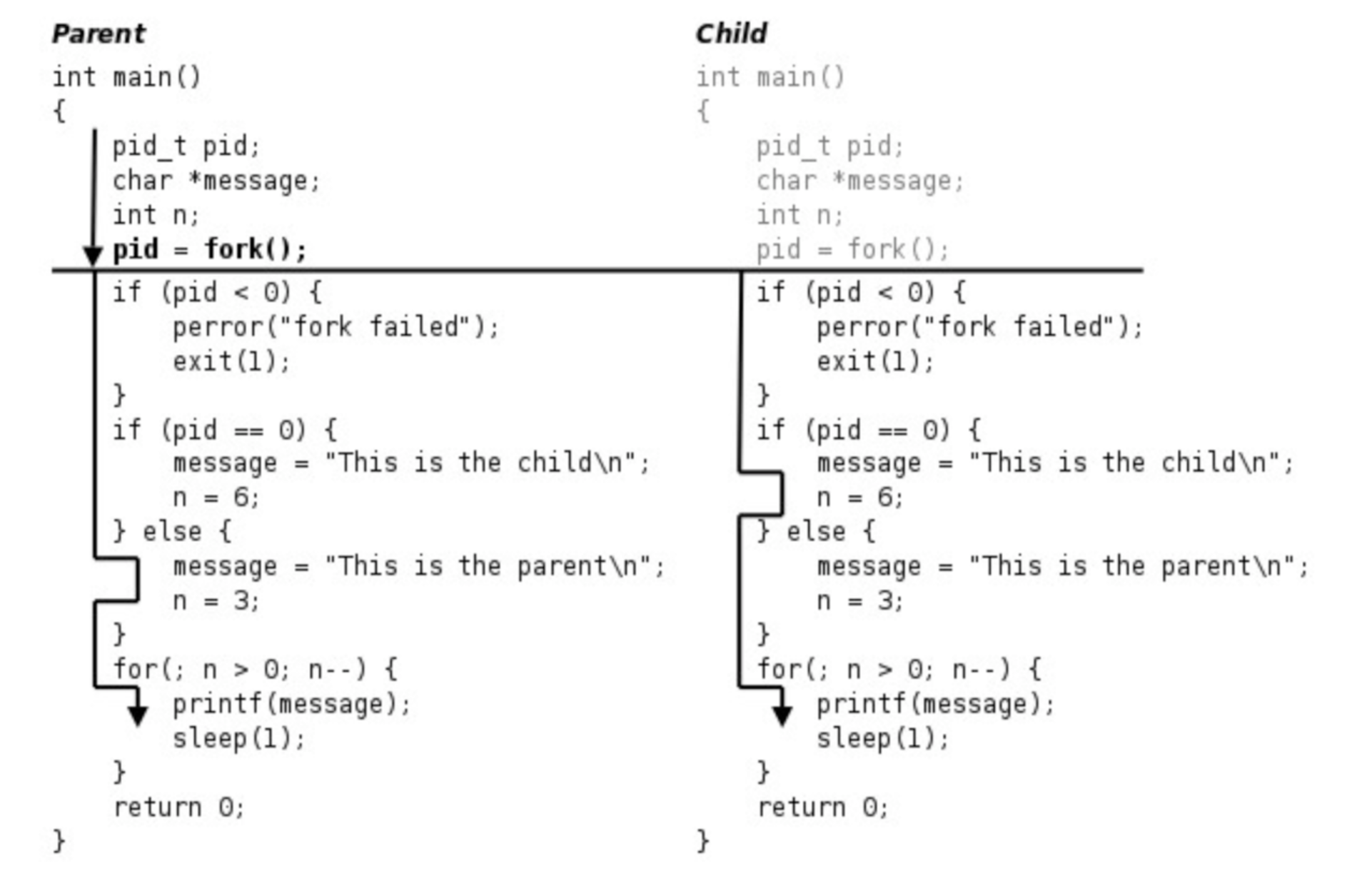
以上的fork()例子的執行流程大致如下:
- 父進程初始化。
- 父進程調用
fork,這是一個系統調用,因此進入內核。 - 內核根據父進程複製出一個子進程,父進程和子進程的PCB資訊相同,用戶態程式碼和數據也相同。因此,子進程現在的狀態看起來和父進程一樣,做完了初始化,剛調用了
fork進入內核,還沒有從內核返回。 - 現在有兩個一模一樣的進程看起來都調用了
fork進入內核等待從內核返回(實際上fork只調用了一次),此外系統中還有很多別的進程也等待從內核返回。是父進程先返回還是子進程先返回,還是這兩個進程都等待,先去調度執行別的進程,這都不一定,取決於內核的調度演算法。 - 如果某個時刻父進程被調度執行了,從內核返回後就從
fork函數返回,保存在變數pid中的返回值是子進程的id,是一個大於0的整數,因此執下面的else分支,然後執行for循環,列印"This is the parent\n"三次之後終止。 - 如果某個時刻子進程被調度執行了,從內核返回後就從
fork函數返回,保存在變數pid中的返回值是0,因此執行下面的if (pid == 0)分支,然後執行for循環,列印"This is the child\n"六次之後終止。fork調用把父進程的數據複製一份給子進程,但此後二者互不影響,在這個例子中,fork調用之後父進程和子進程的變數message和n被賦予不同的值,互不影響。 - 父進程每列印一條消息就睡眠1秒,這時內核調度別的進程執行,在1秒這麼長的間隙里(對於電腦來說1秒很長了)子進程很有可能被調度到。同樣地,子進程每列印一條消息就睡眠1秒,在這1秒期間父進程也很有可能被調度到。所以程式運行的結果基本上是父子進程交替列印,但這也不是一定的,取決於系統中其它進程的運行情況和內核的調度演算法,如果系統中其它進程非常繁忙則有可能觀察到不同的結果。另外,讀者也可以把
sleep(1);去掉看程式的運行結果如何。 - 這個程式是在Shell下運行的,因此Shell進程是父進程的父進程。父進程運行時Shell進程處於等待狀態,當父進程終止時Shell進程認為命令執行結束了,於是列印Shell提示符,而事實上子進程這時還沒結束,所以子進程的消息列印到了Shell提示符後面。最後游標停在
This is the child的下一行,這時用戶仍然可以敲命令,即使命令不是緊跟在提示符後面,Shell也能正確讀取。
fork()最特殊之處在於:成功調用後返回兩個值,是由於在複製時複製了父進程的堆棧段,所以兩個進程都停留在fork函數中,等待返回。所以fork函數會返回兩次,一次是在父進程中返回,另一次是在子進程中返回,這兩次的返回值不同,
其中父進程返回子進程pid,這是由於一個進程可以有多個子進程,但是卻沒有一個函數可以讓一個進程來獲得這些子進程id,那談何給別人你創建出來的進程。而子進程返回0,這是由於子進程可以調用getppid獲得其父進程進程ID,但這個父進程ID卻不可能為0,因為進程ID0總是有內核交換進程所用,故返回0就可代表正常返回了。
從fork函數開始以後的程式碼父子共享,既父進程要執行這段程式碼,子進程也要執行這段程式碼.(子進程獲得父進程數據空間,堆和棧的副本. 但是父子進程並不共享這些存儲空間部分. (即父,子進程共享程式碼段.)。現在很多實現並不執行一個父進程數據段,堆和棧的完全複製. 而是採用寫時拷貝技術。這些區域有父子進程共享,而且內核地他們的訪問許可權改為只讀的.如果父子進程中任一個試圖修改這些區域,則內核值為修改區域的那塊記憶體製作一個副本, 也就是如果你不修改我們一起用,你修改了之後對於修改的那部分內容我們分開各用個的。
再一個就是,在重定向父進程的標準輸出時,子進程標準輸出也被重定向。這就源於父子進程會共享所有的打開文件。 因為fork的特性就是將父進程所有打開文件描述符複製到子進程中。當父進程的標準輸出被重定向,子進程本是寫到標準輸出的時候,此時自然也改寫到那個對應的地方;與此同時,在父進程等待子進程執行時,子進程被改寫到文件show.out中,然後又更新了與父進程共享的該文件的偏移量;那麼在子進程終止後,父進程也寫到show.out中,同時其輸出還會追加在子進程所寫數據之後。
在fork之後處理文件描述符一般有以下兩種情況:
- 父進程等待子進程完成。此種情況,父進程無需對其描述符作任何處理。當子進程終止後,它曾進行過讀,寫操作的任一共享描述符的文件偏移已發生改變。
- 父子進程各自執行不同的程式段。這樣fork之後,父進程和子進程各自關閉它們不再使用的文件描述符,這樣就避免干擾對方使用的文件描述符了。這類似於網路服務進程。
同時父子進程也是有區別的:它們不僅僅是兩個返回值不同;它們各自的父進程也不同,父進程的父進程是ID不變的;還有子進程不繼承父進程設置的文件鎖,子進程未處理的訊號集會設置為空集等不同
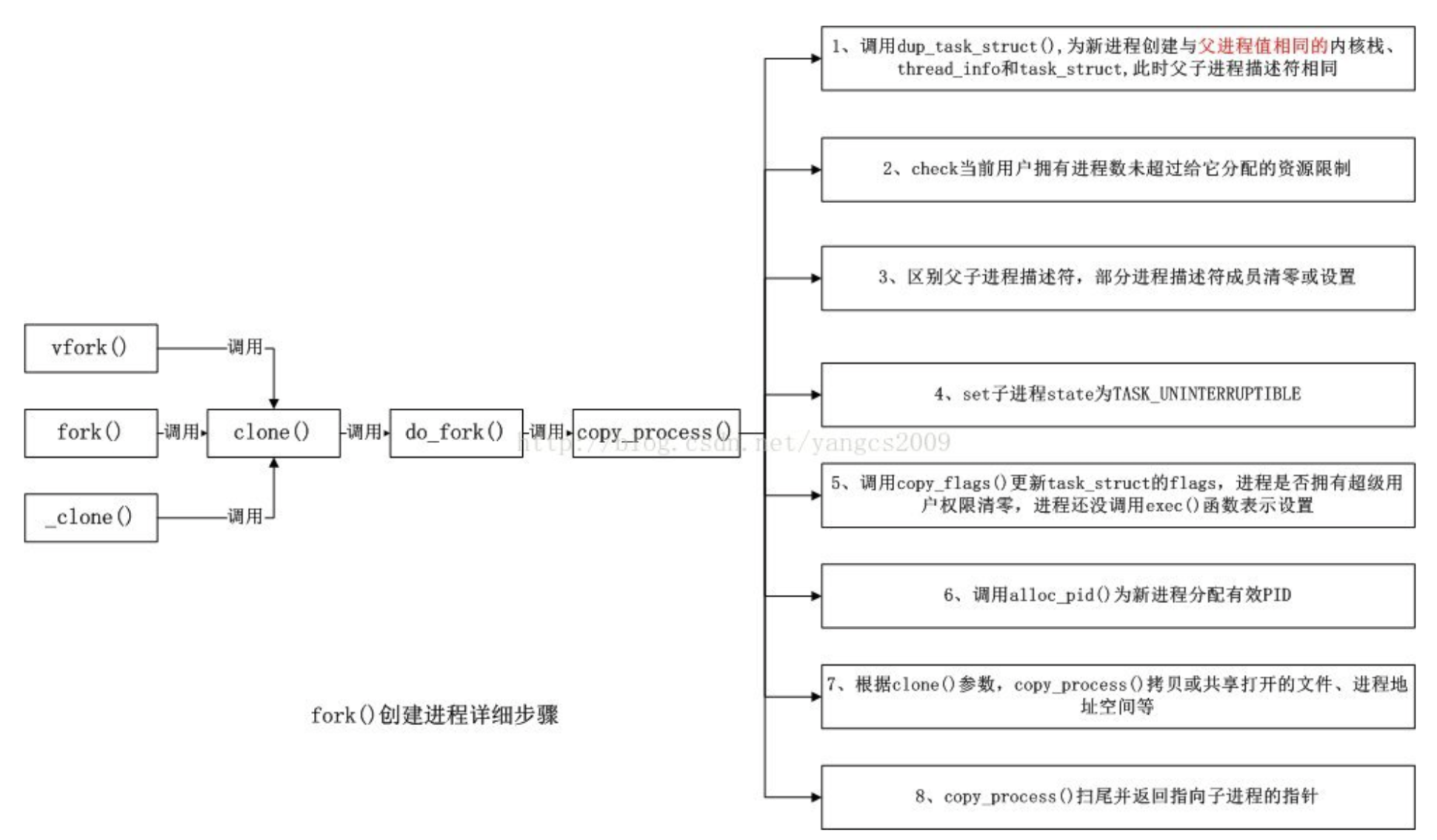
事實上linux平台通過clone()系統調用實現fork()。fork(),vfork()和clone()庫函數都根據各自需要的參數標誌去調用clone(),然後由clone()去調用do_fork(). 再然後do_fork()完成了創建中的大部分工作,他定義在kernel/fork.c當中.該函數調用copy_process()。
具體的流程可以參考下圖:
III 分析execve系統調用中斷上下文及其特殊之處
execve() 系統調用的作用是運行另外一個指定的程式。它會把新程式載入到當前進程的記憶體空間內,當前的進程會被丟棄,它的堆、棧和所有的段數據都會被新進程相應的部分代替,然後會從新程式的初始化程式碼和 main 函數開始運行。同時,進程的 ID 將保持不變。
execve() 系統調用通常與 fork() 系統調用配合使用。從一個進程中啟動另一個程式時,通常是先 fork() 一個子進程,然後在子進程中使用 execve() 變身為運行指定程式的進程。 例如,當用戶在 Shell 下輸入一條命令啟動指定程式時,Shell 就是先 fork() 了自身進程,然後在子進程中使用 execve() 來運行指定的程式。
Linux提供了execl、execlp、execle、execv、execvp和execve等六個用以執行一個可執行文件的函數(統稱為exec函數,其間的差異在於對命令行參數和環境變數參數的傳遞方式不同)。這些函數的第一個參數都是要被執行的程式的路徑,第二個參數則向程式傳遞了命令行參數,第三個參數則向程式傳遞環境變數。以上函數的本質都是調用在arch/i386/kernel/process.c文件中實現的系統調用sys_execve來執行一個可執行文件。
asmlinkage int sys_execve(struct pt_regs regs)
{
int error;
char * filename;
//將可執行文件的名稱裝入到一個新分配的頁面中
filename = getname((char __user *) regs.ebx);
error = PTR_ERR(filename);
if (IS_ERR(filename))
goto out;
//執行可執行文件
error = do_execve(filename,
(char __user * __user *) regs.ecx,
(char __user * __user *) regs.edx,
®s);
if (error == 0) {
task_lock(current);
current->ptrace &= ~PT_DTRACE;
task_unlock(current);
set_thread_flag(TIF_IRET);
}
putname(filename);
out:
return error;
}
該系統調用所需要的參數pt_regs在include/asm-i386/ptrace.h文件中定義。該參數描述了在執行該系統調用時,用戶態下的CPU暫存器在核心態的棧中的保存情況。通過這個參數,sys_execve可以獲得保存在用戶空間的以下資訊:可執行文件路徑的指針(regs.ebx中)、命令行參數的指針(regs.ecx中)和環境變數的指針(regs.edx中)。
struct pt_regs {
long ebx;
long ecx;
long edx;
long esi;
long edi;
long ebp;
long eax;
int xds;
int xes;
long orig_eax;
long eip;
int xcs;
long eflags;
long esp;
int xss;
};
regs.ebx保存著系統調用execve的第一個參數,即可執行文件的路徑名。因為路徑名存儲在用戶空間中,這裡要通過getname拷貝到內核空間中。getname在拷貝文件名時,先申請了一個page作為緩衝,然後再從用戶空間拷貝字元串。為什麼要申請一個頁面而不使用進程的系統空間堆棧?首先這是一個絕對路徑名,可能比較長,其次進程的系統空間堆棧大約為7K,比較緊缺,不宜濫用。用完文件名後,在函數的末尾調用putname釋放掉申請的那個頁面。
sys_execve的核心是調用do_execve函數,傳給do_execve的第一個參數是已經拷貝到內核空間的路徑名filename,第二個和第三個參數仍然是系統調用execve的第二個參數argv和第三個參數envp,它們代表的傳給可執行文件的參數和環境變數仍然保留在用戶空間中。簡單分析一下這個函數的思路:先通過open_err()函數找到並打開可執行文件,然後要從打開的文件中將可執行文件的資訊裝入一個數據結構linux_binprm,do_execve先對參數和環境變數的技術,並通過prepare_binprm讀入開頭的128個位元組到linux_binprm結構的bprm緩衝區,最後將執行的參數從用戶空間拷貝到數據結構bprm中。內核中有一個formats隊列,該隊列的每個成員認識並只處理一種格式的可執行文件,bprm緩衝區中的128個位元組中有格式資訊,便要通過這個隊列去辨認。do_execve()中的關鍵是最後執行一個search_binary_handler()函數,找到對應的執行文件格式,並返回一個值,這樣程式就可以執行了。
do_execve 定義在 <fs/exec.c> 中,關鍵程式碼解析如下。
int do_execve(char * filename, char __user *__user *argv,
char __user *__user *envp, struct pt_regs * regs)
{
struct linux_binprm *bprm; //保存要執行的文件相關的數據
struct file *file;
int retval;
int i;
retval = -ENOMEM;
bprm = kzalloc(sizeof(*bprm), GFP_KERNEL);
if (!bprm)
goto out_ret;
//打開要執行的文件,並檢查其有效性(這裡的檢查並不完備)
file = open_exec(filename);
retval = PTR_ERR(file);
if (IS_ERR(file))
goto out_kfree;
//在多處理器系統中才執行,用以分配負載最低的CPU來執行新程式
//該函數在include/linux/sched.h文件中被定義如下:
// #ifdef CONFIG_SMP
// extern void sched_exec(void);
// #else
// #define sched_exec() {}
// #endif
sched_exec();
//填充linux_binprm結構
bprm->p = PAGE_SIZE*MAX_ARG_PAGES-sizeof(void *);
bprm->file = file;
bprm->filename = filename;
bprm->interp = filename;
bprm->mm = mm_alloc();
retval = -ENOMEM;
if (!bprm->mm)
goto out_file;
//檢查當前進程是否在使用LDT,如果是則給新進程分配一個LDT
retval = init_new_context(current, bprm->mm);
if (retval 0)
goto out_mm;
//繼續填充linux_binprm結構
bprm->argc = count(argv, bprm->p / sizeof(void *));
if ((retval = bprm->argc) 0)
goto out_mm;
bprm->envc = count(envp, bprm->p / sizeof(void *));
if ((retval = bprm->envc) 0)
goto out_mm;
retval = security_bprm_alloc(bprm);
if (retval)
goto out;
//檢查文件是否可以被執行,填充linux_binprm結構中的e_uid和e_gid項
//使用可執行文件的前128個位元組來填充linux_binprm結構中的buf項
retval = prepare_binprm(bprm);
if (retval 0)
goto out;
//將文件名、環境變數和命令行參數拷貝到新分配的頁面中
retval = copy_strings_kernel(1, &bprm->filename, bprm);
if (retval 0)
goto out;
bprm->exec = bprm->p;
retval = copy_strings(bprm->envc, envp, bprm);
if (retval 0)
goto out;
retval = copy_strings(bprm->argc, argv, bprm);
if (retval 0)
goto out;
//查詢能夠處理該可執行文件格式的處理函數,並調用相應的load_library方法進行處理
retval = search_binary_handler(bprm,regs);
if (retval >= 0) {
free_arg_pages(bprm);
//執行成功
security_bprm_free(bprm);
acct_update_integrals(current);
kfree(bprm);
return retval;
}
out:
//發生錯誤,返回inode,並釋放資源
for (i = 0 ; i MAX_ARG_PAGES ; i++) {
struct page * page = bprm->page;
if (page)
__free_page(page);
}
if (bprm->security)
security_bprm_free(bprm);
out_mm:
if (bprm->mm)
mmdrop(bprm->mm);
out_file:
if (bprm->file) {
allow_write_access(bprm->file);
fput(bprm->file);
}
out_kfree:
kfree(bprm);
out_ret:
return retval;
}
該函數用到了一個類型為linux_binprm的結構體來保存要執行的文件相關的資訊,該結構體在include/linux/binfmts.h文件中定義:
struct linux_binprm{
char buf[BINPRM_BUF_SIZE]; //保存可執行文件的頭128位元組
struct page *page[MAX_ARG_PAGES];
struct mm_struct *mm;
unsigned long p; //當前記憶體頁最高地址
int sh_bang;
struct file * file; //要執行的文件
int e_uid, e_gid; //要執行的進程的有效用戶ID和有效組ID
kernel_cap_t cap_inheritable, cap_permitted, cap_effective;
void *security;
int argc, envc; //命令行參數和環境變數數目
char * filename; //要執行的文件的名稱
char * interp; //要執行的文件的真實名稱,通常和filename相同
unsigned interp_flags;
unsigned interp_data;
unsigned long loader, exec;
};
在該函數的最後,又調用了fs/exec.c文件中定義的search_binary_handler函數來查詢能夠處理相應可執行文件格式的處理器,並調用相應的load_library方法以啟動進程。這裡,用到了一個在include/linux/binfmts.h文件中定義的linux_binfmt結構體來保存處理相應格式的可執行文件的函數指針如下:
struct linux_binfmt {
struct linux_binfmt * next;
struct module *module;
// 載入一個新的進程
int (*load_binary)(struct linux_binprm *, struct pt_regs * regs);
// 動態載入共享庫
int (*load_shlib)(struct file *);
// 將當前進程的上下文保存在一個名為core的文件中
int (*core_dump)(long signr, struct pt_regs * regs, struct file * file);
unsigned long min_coredump;
};
Linux內核允許用戶通過調用在include/linux/binfmt.h文件中定義的register_binfmt和unregister_binfmt函數來添加和刪除linux_binfmt結構體鏈表中的元素,以支援用戶特定的可執行文件類型。
在調用特定的load_binary函數載入一定格式的可執行文件後,程式將返回到sys_execve函數中繼續執行。該函數在完成最後幾步的清理工作後,將會結束處理並返回到用戶態中,最後,系統將會將CPU分配給新載入的程式。
execve系統調用的過程總結如下:
- execve系統調用陷入內核,並傳入命令行參數和shell上下文環境
- execve陷入內核的第一個函數:do_execve,該函數封裝命令行參數和shell上下文
- do_execve調用do_execveat_common,後者進一步調用__do_execve_file,打開ELF文件並把所有的資訊一股腦的裝入linux_binprm結構體
- do_execve_file中調用search_binary_handler,尋找解析ELF文件的函數
- search_binary_handler找到ELF文件解析函數load_elf_binary
- load_elf_binary解析ELF文件,把ELF文件裝入記憶體,修改進程的用戶態堆棧(主要是把命令行參數和shell上下文加入到用戶態堆棧),修改進程的數據段程式碼段
- load_elf_binary調用start_thread修改進程內核堆棧(特別是內核堆棧的ip指針)
- 進程從execve返回到用戶態後ip指向ELF文件的main函數地址,用戶態堆棧中包含了命令行參數和shell上下文環境
IV 以系統調用作為特殊的中斷,結合中斷上下文切換和進程上下文切換分析Linux系統的一般執行過程
Linux系統的一般執行過程
正在運行的用戶態進程X切換到運行用戶態進程Y的過程
-
發生中斷 ,完成以下步驟:
save cs:eip/esp/eflags(current) to kernel stack
load cs:eip(entry of a specific ISR) and ss:esp(point to kernel stack) -
SAVE_ALL //保存現場,這裡是已經進入內核中斷處里過程
-
中斷處理過程中或中斷返回前調用了schedule(),其中的switch_to做了關鍵的進程上下文切換
-
標號1之後開始運行用戶態進程Y(這裡Y曾經通過以上步驟被切換出去過因此可以從標號1繼續執行)
-
restore_all //恢復現場
-
繼續運行用戶態進程Y
進程間的特殊情況
- 通過中斷處理過程中的調度時機,用戶態進程與內核執行緒之間互相切換和內核執行緒之間互相切換
- 與最一般的情況非常類似,只是內核執行緒運行過程中發生中斷沒有進程用戶態和內核態的轉換;
- 內核執行緒主動調用schedule(),只有進程上下文的切換,沒有發生中斷上下文的切換,與最一般“的情況略簡略;
- 創建子進程的系統調用在子進程中的執行起點及返回用戶態,如fork;
- 載入一個新的可執行程式後返回到用戶態的情況,如execve;0-3G內核態和用戶態都可以訪問,3G以上只能內核態訪問。內核是所有進程共享的。內核是各種中斷處理過程和內核執行緒的集合。
三. 總結
這次實驗主要做了如下的事情:
- 學習並完成實驗環境的配置的搭建
- 學習並了解Linux內核中系統調用相關知識
- 學習了中斷相關的知識
- 學習並實踐了fork()與execve()系統調用的知識
- 思考程式碼執行的流程與原理

