用Springboot幹掉IBM的WAS-為公司省點錢
1 那一夜,你傷害了我
今夜的雨下得涼快,小南睡得正香,突然收到遠洋運維小周的電話:Hello, Are you OK? WAS有issue,快起來help me!

只見小南登陸WAS機,查看了機器日誌、應用日誌,終於定位了問題,登上WAS管理介面,一頓操作猛如虎,應用終於恢復了。但不記得這是第幾次新人不懂WAS而向小南求救了。
第二天,小南向領導呈上《替換WAS表》,開始了一場浩蕩的伺服器之戰。其文曰:
先弟修bug未半,而中道離職。今WAS已老,Springboot又新,此誠用Boot換WAS之秋也。
……
今當替換,臨碼涕零,不知所言。
所謂WAS,即IBM的WebSphere Application Server,是一種Java應用伺服器。相對Tomcat等,會更重型,更複雜;更重要的是價格昂貴。得益於IBM及它一整套的企業開發套件,也還是有一定的市場佔有率,特別是在傳統行業里。
隨著技術向前發展與之前轟轟烈烈的去IOE運動,用WAS的人越來越少了,許多新人更是完全沒有接觸過,又因其價格昂貴且不利於DevOps,我司決定要替換掉它。經討論,代替它上場的就是現在紅紅火火的Springboot,原因眾多,如開源免費、開箱即用、利於發布、容易運維等。
2 大刀闊斧還是小打小鬧
硬體、軟體同時替換,就必須謹慎小心,主要方案如下:
(1)硬體上從裝有WAS機器的Linux轉移到普通的Linux機器,但需要注意關鍵指標如處理器、記憶體、硬碟等。
(2)軟體上從之前打成war包,現改為jar包,包結構完全改變,引入Springboot後,Spring容器和bean要對應調整、資料庫池化也對應調整。原來WAS跑的是SOAP Webservice,現通過Springboot整合cxf-spring-boot-starter-jaxws實現。
(3)網路上依然是https協議,但以前WEB伺服器為IHS,現在直接使用Springboot,證書需要重新生成和導入。客戶端證書要先從IHS伺服器的密鑰文件導出,需要查看IBM官網資料。
關於https的內容可參考:HTTPS專題。
同時引入新的負載均衡器F5,且需要在上線當天更新DNS到新F5上。結構圖如下:
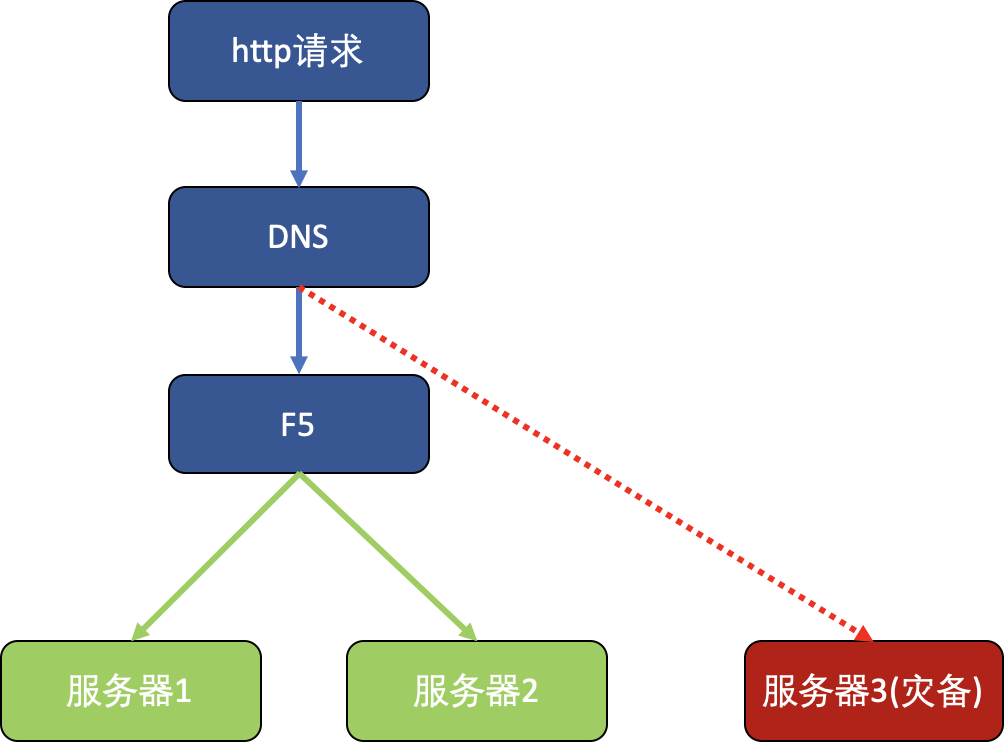
伺服器1與伺服器2在同一個數據中心,正常運行時處於工作狀態。如果該數據中心發生災難(如地震等),就會啟用伺服器3,並把DNS更新到災備伺服器的地址。
(4)發布上由手工發布改為Ansible發布,可減少人力和錯誤風險。
(5)監測上有日誌監控,但Springboot日誌文件更少更集中,同時Springboot可整合Springboot Admin,可參考:用Springboot Admin監控你的微服務應用。
(6)UAT需要實現多環境部署,可通過maven實現。
3 測試
任何變更都有可能出錯,都會引入風險。由墨菲定律可知,凡是可能出錯的事就一定會出錯。所以測試變得極為重要。在整個項目的測試中,功能測試和端到端測試都發現了問題,所以不要放過可以發現問題的機會,不然上了生產再出現,成本可太高了。
所謂君子不立危牆之下,讓我們看看都怎麼測試。
3.1 單元測試
單元測試在開發階段就要完成,特別要關注測試覆蓋率、圈複雜度等指標。可以使用Sonar、Findbugs等工具進行檢測,可以參考下面的文章:
Maven整合JaCoCo和Sonar,看看你的測試寫夠了沒
Docker搭建程式碼檢測平台SonarQube並檢測maven項目
3.2 功能測試
根據業務定義測試場景,盡量全面。特別是基準線用例,必須覆蓋。可以增加異常場景的用例,保證服務不會受影響,依然保持可用;錯誤場景是否有合理的告警,也是很關鍵的。
3.3 性能與壓力測試
測試出關鍵性能指標,看是否能滿足現在的生產需求,要特別注意測試環境與生產環境的差異有多大,測試報告有多大的參考價值。壓力測試可以分為兩類,大請求和高並發,大請求是一個請求數據量很大,高並發是指多個請求同時產生。
3.4 端到端測試
聯繫其它相關團隊(客戶端,即請求端)進行端到端的測試,在測試環境發送正式的請求。
4 上線
領導說過,生產是最好的測試環境,哈哈,測試差不多了,就該上生產了。
但上生產不是那麼容易的事,首先要確保發布的這個downtime沒有客戶端發請求過來,需要和其它團隊約定好時間停服。更重要的是,因為希望只是自己做變更,不能要求別人做變更,所以域名不能變,就需要找網路團隊更新DNS到新服務上。
為了縮短停服時間,提前把Springboot部署到新伺服器上,並把新伺服器配置在新的F5上,發布那天直接更新DNS到F5上即可。DNS更新完成後,找客戶端發送請求進行測試,沒有問題即大功告成了!
雖然已經成功上線,但舊伺服器還是要並行一段時間,萬一新服務出問題,緊急情況難以修復,還可以回滾。
5 還能再做什麼
雖然已經上線了,但還是有更多東西可以做的。
文檔:人的記憶都是不可靠的,同時也要減少人員流動的風險,需要通過文檔把相關內容記錄下來,並分享到整個團隊。主要內容有開發過程、架構原理、生產環境運維指南、測試環境使用、關鍵知識索引等。
災備測試:做了災備,但並沒有測試。還好公司要求定期要做災備測試,到時可以覆蓋,現在沒做會增大風險。
ELK:日誌收集沒有統一到日誌平台,需要登陸到指定機器查看。幸好所用的機器不多。
Metric指標:可以收集JVM記憶體、CPU、GC等資訊,以便定位問題,可以展示到Grafana上。
OpenTracing:可以記錄每次請求的詳細情況。可參考:實例講解Springboot整合OpenTracing分散式鏈路追蹤系統(Jaeger和Zipkin)
REST/RPC改造:現在的服務為XML格式的WebService,可改造為RESTful+Json或gRPC。
最後,並不是引入新技術就是好的,有時候需要KISS(Keep it simple and stupid),簡單能用就是好的,不要想著搞些大新聞,這樣有時間還是很naive的。
6 總結
小南獨立完成了這次改造後,去了趟黃山修練內功,修仙成果如下:黃山徽州五日行-最美風景與攻略獻給你。
回來後,又開始新的征程,這次要改造整箇舊系統:System Entire Rebuild (SER)。後續如何,請聽下回糞解。
歡迎訪問南瓜慢說 www.pkslow.com獲取更多精彩文章!
歡迎關注微信公眾號<南瓜慢說>,將持續為你更新…

多讀書,多分享;多寫作,多整理。
