「中高級前端」窺探數據結構的世界- ES6版
- 2019 年 10 月 10 日
- 筆記
1. 什麼是數據結構?
數據結構是在電腦中組織和存儲數據的一種特殊方式,使得數據可以高效地被訪問和修改。更確切地說,數據結構是數據值的集合,表示數據之間的關係,也包括了作用在數據上的函數或操作。
1.1 為什麼我們需要數據結構?
- 數據是電腦科學當中最關鍵的實體,而數據結構則可以將數據以某種組織形式存儲,因此,數據結構的價值不言而喻。
- 無論你以何種方式解決何種問題,你都需要處理數據——無論是涉及員工薪水、股票價格、購物清單,還是只是簡單的電話簿問題。
- 數據需要根據不同的場景,按照特定的格式進行存儲。有很多數據結構能夠滿足以不同格式存儲數據的需求。
1.2 八大常見的數據結構
- 數組:
Array - 堆棧:
Stack - 隊列:
Queue - 鏈表:
Linked Lists - 樹:
Trees - 圖:
Graphs - 字典樹:
Trie - 散列表(哈希表):
Hash Tables
在較高的層次上,基本上有三種類型的數據結構:
- 堆棧和隊列是類似於數組的結構,僅在項目的插入和刪除方式上有所不同。
- 鏈表,樹,和圖 結構的節點是引用到其他節點。
- 散列表依賴於散列函數來保存和定位數據。
在複雜性方面:
- 堆棧和隊列是最簡單的,並且可以從中構建鏈表。
- 樹和圖 是最複雜的,因為它們擴展了鏈表的概念。
- 散列表和字典樹 需要利用這些數據結構來可靠地執行。
就效率而已:
- 鏈表是記錄和存儲數據的最佳選擇
- 而哈希表和字典樹 在搜索和檢索數據方面效果最佳。
2.數組 – 知識補充
數組是最簡單的數據結構,這裡就不講過多了。 貼一張每個函數都運行10,000次迭代:
- 10,000個隨機密鑰在10,000個對象的數組中查找的執行效率對比圖:
[ { id: "key0", content: "I ate pizza 0 times" }, { id: "key1", content: "I ate pizza 1 times" }, { id: "key2", content: "I ate pizza 2 times" }, ... ] ["key284", "key958", "key23", "key625", "key83", "key9", ... ]

2.1 for...in為何這麼慢?
for...in語法令人難以置信的緩慢。在測試中就已經比正常情況下慢近9倍的循環。
這是因為 for...in語法是第一個能夠迭代對象鍵的JavaScript語句。
循環對象鍵( {})與在數組( [])上進行循環不同,
因為引擎會執行一些額外的工作來跟蹤已經迭代的屬性。
3. 堆棧: Stack

堆棧是元素的集合,可以在頂部添加項目,我們有幾個實際的堆棧示例:
- 瀏覽器歷史記錄
- 撤消操作
- 遞歸以及其它。
三句話解釋堆棧:
- 兩個原則操作:
push和pop。Push將元素添加到數組的頂部,而Pop將它們從同一位置刪除。 - 遵循"
Last In,First Out",即:LIFO,後進先出。 - 沒了。
3.1 堆棧的實現。
請注意,下方例子中,我們可以顛倒堆棧的順序:底部變為頂部,頂部變為底部。
因此,我們可以分別使用數組 unshift和 shift方法代替 push和 pop。
class Stack { constructor(...items) { this.reverse = false; this.stack = [...items]; } push(...items) { return this.reverse ? this.stack.unshift(...items) : this.stack.push(...items); } pop() { return this.reverse ? this.stack.shift() : this.stack.pop(); } } const stack = new Stack(4, 5); stack.reverse = true; console.log(stack.push(1, 2, 3) === 5) // true console.log(stack.stack ===[1, 2, 3, 4, 5]) // true
4. 隊列: Queue
在電腦科學中,一個隊列(queue)是一種特殊類型的抽象數據類型或集合。集合中的實體按順序保存。

而在前端開發中,最著名的隊列使用當屬瀏覽器/NodeJs中 關於宏任務與微任務,任務隊列的知識。這裡就不再贅述了。
在後端領域,用得最廣泛的就是消息隊列: Messagequeue:如 RabbitMQ、 ActiveMQ等。
以編程思想而言, Queue可以用兩句話描述:
- 只是具有兩個主要操作的數組:
unshift和pop。 - 遵循
"Fist In,first out"即:FIFO,先進先出。

4.1 隊列的實現
請注意,下方例子中,我們可以顛倒堆隊列的順序。
因此,我們可以分別使用數組 unshift和 shift方法代替 push和 pop。
class Queue { constructor(...items) { this.reverse = false; this.queue = [...items]; } enqueue(...items) { return this.reverse ? this.queue.push(...items) : this.queue.unshift(...items); } dequeue() { return this.reverse ? this.queue.shift() : this.queue.pop(); } }
5. 鏈表: LinkedLists
與數組一樣,鏈表是按順序存儲數據元素。
鏈表不是保留索引,而是指向其他元素。

第一個節點稱為頭部( head),而最後一個節點稱為尾部( tail)。
單鏈表與雙向鏈表:
- 單鏈表是表示一系列節點的數據結構,其中每個節點指向列表中的下一個節點。
- 鏈表通常需要遍歷整個操作列表,因此性能較差。
- 提高鏈表性能的一種方法是在每個節點上添加指向列表中上一個節點的第二個指針。
- 雙向鏈表具有指向其前後元素的節點。
鏈表的優點:
- 鏈接具有常量時間 插入和刪除,因為我們可以只更改指針。
- 與數組一樣,鏈表可以作為堆棧運行。
鏈表的應用場景:
鏈接列表在客戶端和伺服器上都很有用。
- 在客戶端上,像
Redux就以鏈表方式構建其中的邏輯。 React核心演算法React Fiber的實現就是鏈表。

-
React Fiber之前的Stack Reconciler,是自頂向下的遞歸mount/update,無法中斷(持續佔用主執行緒),這樣主執行緒上的布局、動畫等周期性任務以及交互響應就無法立即得到處理,影響體驗。
-
React Fiber解決過去Reconciler存在的問題的思路是把渲染/更新過程(遞歸diff)拆分成一系列小任務,每次檢查樹上的一小部分,做完看是否還有時間繼續下一個任務,有的話繼續,沒有的話把自己掛起,主執行緒不忙的時候再繼續。
- 在伺服器上,像
Express這樣的Web框架也以類似的方式構建其中間件邏輯。當請求被接收時,它從一個中間件管道輸送到下一個,直到響應被發出。
5.1 單鏈表實現
單鏈表的操作核心有:
push(value)– 在鏈表的末尾/頭部添加一個節點pop()– 從鏈表的末尾/頭部刪除一個節點get(index)– 返回指定索引處的節點delete(index)– 刪除指定索引處的節點isEmpty()– 根據列表長度返回true或falseprint()– 返回鏈表的可見表示
class Node { constructor(data) { this.data = data this.next = null } } class LinkedList { constructor() { this.head = null this.tail = null // 長度非必要 this.length = 0 } push(data) { // 創建一個新節點 const node = new Node(data) // 檢查頭部是否為空 if (this.head === null) { this.head = node this.tail = node } this.tail.next = node this.tail = node this.length++ } pop(){ // 先檢查鏈表是否為空 if(this.isEmpty()) { return null } // 如果長度為1 if (this.head === this.tail) { this.head = null this.tail = null this.length-- return this.tail } let node = this.tail let currentNode = this.head let penultimate while (currentNode) { if (currentNode.next === this.tail) { penultimate = currentNode break } currentNode = currentNode.next } penultimate.next = null this.tail = penultimate this.length -- return node } get(index){ // 處理邊界條件 if (index === 0) { return this.head } if (index < 0 || index > this.length) { return null } let currentNode = this.head let i = 0 while(i < index) { i++ currentNode = currentNode.next } return currentNode } delete(index){ let currentNode = this.head if (index === 0) { let deletedNode currentNode.next = this.head deletedNode = currentNode this.length-- return deletedNode } if (index < 0 || index > this.length) { return null } let i = 0 let previous while(i < index) { i++ previous = currentNode currentNode = currentNode.next } previous.next = currentNode.next this.length-- return currentNode } isEmpty() { return this.length === 0 } print() { const list = [] let currentNode = this.head while(currentNode){ list.push(currentNode.data) currentNode = currentNode.next } return list.join(' => ') } }
測試一下:
const l = new LinkedList() // 添加節點 const values = ['A', 'B', 'C'] values.forEach(value => l.push(value)) console.log(l) console.log(l.pop()) console.log(l.get(1)) console.log(l.isEmpty()) console.log(l.print())

5.2 雙向鏈表實現
1. 雙向鏈表的設計
類似於單鏈表,雙向鏈表由一系列節點組成。每個節點包含一些數據以及指向列表中下一個節點的指針和指向前一個節點的指針。這是 JavaScript中的簡單表示:
class Node { constructor(data) { // data 包含鏈表項應存儲的值 this.data = data; // next 是指向列表中下一項的指針 this.next = null; // prev 是指向列表中上一項的指針 this.prev = null; } }

還是敲一遍吧:
class DoublyLinkedList { constructor() { this.head = null; this.tail = null; } // 各種操作方法 // ... }
2. 雙向鏈表的操作方法

Append & AppendAt: 在鏈表的尾部/ 指定位置添加節點
append( item ) { let node = new Node( item ); if(!this.head) { this.head = node; this.tail = node; } else { node.prev = this.tail; this.tail.next = node; this.tail = node } }

appendAt( pos, item ) { let current = this.head; let counter = 1; let node = new Node( item ); if( pos == 0 ) { this.head.prev = node node.next = this.head this.head = node } else { while(current) { current = current.next; if( counter == pos ) { node.prev = current.prev current.prev.next = node node.next = current current.prev = node } counter++ } } }

Remove & RemoveAt: 在鏈表的尾部/ 指定位置刪除節點
remove( item ) { let current = this.head; while( current ) { if( current.data === item ) { if( current == this.head && current == this.tail ) { this.head = null; this.tail = null; } else if ( current == this.head ) { this.head = this.head.next this.head.prev = null } else if ( current == this.tail ) { this.tail = this.tail.prev; this.tail.next = null; } else { current.prev.next = current.next; current.next.prev = current.prev; } } current = current.next } }

removeAt( pos ) { let current = this.head; let counter = 1; if( pos == 0 ) { this.head = this.head.next; this.head.prev = null; } else { while( current ) { current = current.next if ( current == this.tail ) { this.tail = this.tail.prev; this.tail.next = null; } else if( counter == pos ) { current.prev.next = current.next; current.next.prev = current.prev; break; } counter++; } } }

Reverse: 翻轉雙向鏈表
reverse(){ let current = this.head; let prev = null; while( current ){ let next = current.next current.next = prev current.prev = next prev = current current = next } this.tail = this.head this.head = prev }

Swap:兩節點間交換。
swap( nodeOne, nodeTwo ) { let current = this.head; let counter = 0; let firstNode; while( current !== null ) { if( counter == nodeOne ){ firstNode = current; } else if( counter == nodeTwo ) { let temp = current.data; current.data = firstNode.data; firstNode.data = temp; } current = current.next; counter++; } return true }

IsEmpty & Length:查詢是否為空或長度。
length() { let current = this.head; let counter = 0; while( current !== null ) { counter++ current = current.next } return counter; } isEmpty() { return this.length() < 1 }

Traverse: 遍歷鏈表
traverse( fn ) { let current = this.head; while( current !== null ) { fn(current) current = current.next; } return true; }

每一項都加10
Search:查找節點的索引。
search( item ) { let current = this.head; let counter = 0; while( current ) { if( current.data == item ) { return counter } current = current.next counter++ } return false; }

6. 樹: Tree
電腦中經常用到的一種非線性的數據結構——樹(Tree),由於其存儲的所有元素之間具有明顯的層次特性,因此常被用來存儲具有層級關係的數據,比如文件系統中的文件;也會被用來存儲有序列表等。
- 在樹結構中,每一個結點只有一個父結點,若一個結點無父節點,則稱為樹的根結點,簡稱樹的根(root)。
- 每一個結點可以有多個子結點。
- 沒有子結點的結點稱為葉子結點。
- 一個結點所擁有的子結點的個數稱為該結點的度。
- 所有結點中最大的度稱為樹的度。樹的最大層次稱為樹的深度。
6.1 樹的分類
常見的樹分類如下,其中我們掌握二叉搜索樹即可。
- 二叉樹:
Binary Search Tree - AVL樹:
AVL Tree - 紅黑樹:
Red-Black Tree - 線段樹:
Segment Tree– with min/max/sum range queries examples - 芬威克樹:
Fenwick Tree(Binary Indexed Tree)
6.2 樹的應用
DOM樹。每個網頁都有一個樹數據結構。

Vue和React的Virtual DOM也是樹。

6.3 二叉樹: BinarySearchTree
- 二叉樹是一種特殊的樹,它的子節點個數不超過兩個。
- 且分別稱為該結點的左子樹(left subtree)與右子樹(right subtree)。
- 二叉樹常被用作二叉查找樹和二叉搜索樹、或是二叉排序樹(BST)。

6.4 二叉樹的遍歷
按一定的規則和順序走遍二叉樹的所有結點,使每一個結點都被訪問一次,而且只被訪問一次,這個操作被稱為樹的遍歷,是對樹的一種最基本的運算。
由於二叉樹是非線性結構,因此,樹的遍歷實質上是將二叉樹的各個結點轉換成為一個線性序列來表示。
按照根節點訪問的順序不同,二叉樹的遍歷分為以下三種:前序遍歷,中序遍歷,後序遍歷;
前序遍歷: Pre-Order
根節點->左子樹->右子樹

中序遍歷: In-Order
左子樹->根節點->右子樹

後序遍歷: Post-Order
左子樹->右子樹->根節點

因此我們可以得之上面二叉樹的遍歷結果如下:
- 前序遍歷:ABDEFGC
- 中序遍歷:DEBGFAC
- 後序遍歷:EDGFBCA
6.5 二叉樹的實現
class Node { constructor(data) { this.left = null this.right = null this.value = value } } class BST { constructor() { this.root = null } // 二叉樹的各種操作 // insert(value) {...} // insertNode(root, newNode) {...} // ...
1. insertNode& insert:插入新子節點/節點
insertNode(root, newNode) { if (newNode.value < root.value) { // 先執行無左節點操作 (!root.left) ? root.left = newNode : this.insertNode(root.left, newNode) } else { (!root.right) ? root.right = newNode : this.insertNode(root.right, newNode) } } insert(value) { let newNode = new Node(value) // 如果沒有根節點 if (!this.root) { this.root = newNode } else { this.insertNode(this.root, newNode) } }
2. removeNode& remove:移除子節點/節點
removeNode(root, value) { if (!root) { return null } // 從該值小於根節點開始判斷 if (value < root.value) { root.left = this.removeNode(root.left, value) return root } else if (value > root.value) { root.right = tis.removeNode(root.right, value) return root } else { // 如果沒有左右節點 if (!root.left && !root.right) { root = null return root } // 存在左節點 if (root.left) { root = root.left return root // 存在右節點 } else if (root.right) { root = root.right return root } // 獲取正確子節點的最小值以確保我們有有效的替換 let minRight = this.findMinNode(root.right) root.value = minRight.value // 確保刪除已替換的節點 root.right = this.removeNode(root.right, minRight.value) return root } } remove(value) { if (!this.root) { return 'Tree is empty!' } else { this.removeNode(this.root, value) } }
3. findMinNode:獲取子節點的最小值
findMinNode(root) { if (!root.left) { return root } else { return this.findMinNode(root.left) } }
4. searchNode & search:查找子節點/節點
searchNode(root, value) { if (!root) { return null } if (value < root.value) { return this.searchNode(root.left, value) } else if (value > root.value) { return this.searchNode(root.right, value) } return root } search(value) { if (!this.root) { return 'Tree is empty' } else { return Boolean(this.searchNode(this.root, value)) } }
Pre-Order:前序遍歷
preOrder(root) { if (!root) { return 'Tree is empty' } else { console.log(root.value) this.preOrder(root.left) this.preOrder(root.right) } }
In-Order:中序遍歷
inOrder(root) { if (!root) { return 'Tree is empty' } else { this.inOrder(root.left) console.log(root.value) this.inOrder(root.right) } }
Post-Order:後序遍歷
postOrder(root) { if (!root) { return 'Tree is empty' } else { this.postOrder(root.left) this.postOrder(root.right) console.log(root.value) } }
7. 圖: Graph
圖是由具有邊的節點集合組成的數據結構。圖可以是定向的或不定向的。
圖的介紹普及,找了一圈文章,還是這篇最佳:
Graphs—-A Visual Introduction for Beginners

7.1 圖的應用
在以下場景中,你都使用到了圖:
- 使用搜索服務,如
Google,百度。 - 使用
LBS地圖服務,如高德,Google地圖。 - 使用社交媒體網站,如微博,
Facebook。

圖用於不同的行業和領域:
GPS系統和Google地圖使用圖表來查找從一個目的地到另一個目的地的最短路徑。- 社交網路使用圖表來表示用戶之間的連接。
Google搜索演算法使用圖 來確定搜索結果的相關性。- 運營研究是一個使用圖 來尋找降低運輸和交付貨物和服務成本的最佳途徑的領域。
- 甚至化學使用圖 來表示分子!
圖,可以說是應用最廣泛的數據結構之一,真實場景中處處有圖。
7.2 圖的構成
圖表用於表示,查找,分析和優化元素(房屋,機場,位置,用戶,文章等)之間的連接。
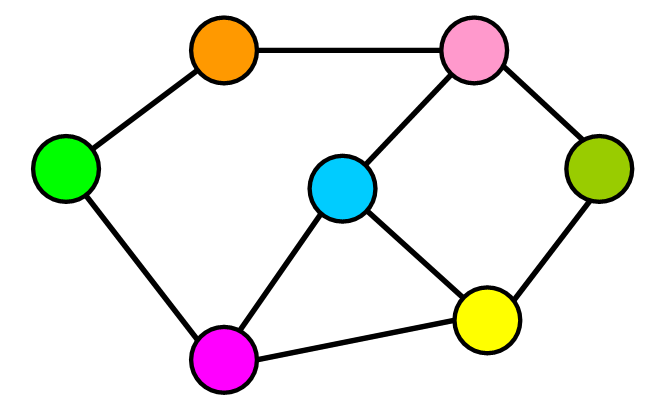
1. 圖的基本元素
- 節點:
Node,比如地鐵站中某個站/多個村莊中的某個村莊/互聯網中的某台主機/人際關係中的人. - 邊:
Edge,比如地鐵站中兩個站點之間的直接連線, 就是一個邊。

2. 符號和術語
-
|V|=圖中頂點(節點)的總數。 -
|E|=圖中的連接總數(邊)。
在下面的示例中
|V| = 6 |E| = 7

3. 有向圖與無向圖
圖根據其邊(連接)的特徵進行分類。
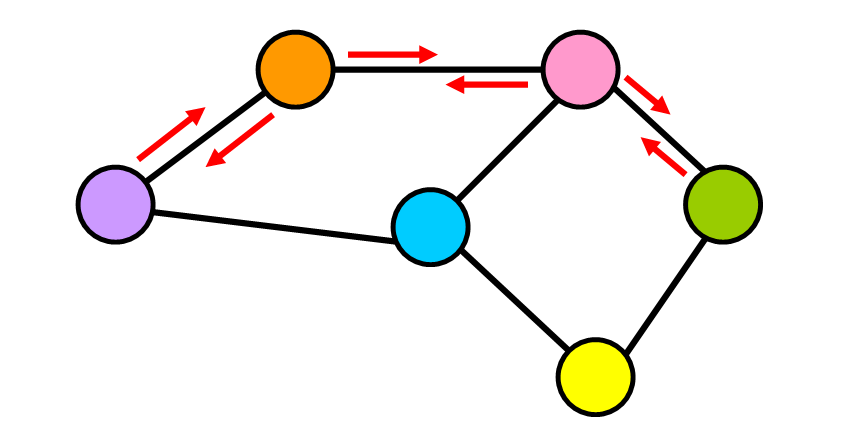
1. 有向圖
在有向圖中,邊具有方向。它們從一個節點轉到另一個節點,並且無法通過該邊返回到初始節點。
如下圖所示,邊(連接)現在具有指向特定方向的箭頭。 將這些邊視為單行道。您可以向一個方向前進併到達目的地,但是你無法通過同一條街道返回,因此您需要找到另一條路徑。

有向圖
2. 無向圖
在這種類型的圖中,邊是無向的(它們沒有特定的方向)。將無向邊視為雙向街道。您可以從一個節點轉到另一個節點並返回相同的「路徑」。
4. 加權圖
在加權圖中,每條邊都有一個與之相關的值(稱為權重)。該值用於表示它們連接的節點之間的某種可量化關係。例如:
- 權重可以表示距離,時間,社交網路中兩個用戶之間共享的連接數。
- 或者可以用於描述您正在使用的上下文中的節點之間的連接的任何內容。

著名的 Dijkstra演算法,就是使用這些權重通過查找網路中節點之間的最短或最優的路徑來優化路由。
5. 稀疏圖與密集圖
當圖中的邊數接近最大邊數時,圖是密集的。
密集圖
當圖中的邊數明顯少於最大邊數時,圖是稀疏的。

稀疏圖
6. 循環
如果你按照圖中的一系列連接,可能會找到一條路徑,將你帶回到同一節點。這就像「走在圈子裡」,就像你在城市周圍開車一樣,你走的路可以帶你回到你的初始位置。?
在圖中,這些「圓形」路徑稱為「循環」。它們是在同一節點上開始和結束的有效路徑。例如,在下圖中,您可以看到,如果從任何節點開始,您可以通過跟隨邊緣返回到同一節點。

循環並不總是「孤立的」,因為它們可以是較大圖的一部分。可以通過在特定節點上開始搜索並找到將你帶回同一節點的路徑來檢測它們。

循環圖
7.3 圖的實現
我們將實現具有鄰接列表的有向圖。
class Graph { constructor() { this.AdjList = new Map(); } // 基礎操作方法 // addVertex(vertex) {} // addEdge(vertex, node) {} // print() {} }
1. addVertex:添加頂點
addVertex(vertex) { if (!this.AdjList.has(vertex)) { this.AdjList.set(vertex, []); } else { throw 'Already Exist!!!'; } }
嘗試創建頂點:
let graph = new Graph(); graph.addVertex('A'); graph.addVertex('B'); graph.addVertex('C'); graph.addVertex('D');
列印後將會發現:
Map { 'A' => [], 'B' => [], 'C' => [], 'D' => [] }
之所以都為空數組 '[]',是因為數組中需要儲存邊( Edge)的關係。 例如下圖:

該圖的 Map將為:
Map { 'A' => ['B', 'C', 'D'], // B沒有任何指向 'B' => [], 'C' => ['B'], 'D' => ['C'] }
2. addEdge:添加邊( Edge)
addEdge(vertex, node) { // 向頂點添加邊之前,必須驗證該頂點是否存在。 if (this.AdjList.has(vertex)) { // 確保添加的邊尚不存在。 if (this.AdjList.has(node)){ let arr = this.AdjList.get(vertex); // 如果都通過,那麼可以將邊添加到頂點。 if(!arr.includes(node)){ arr.push(node); } }else { throw `Can't add non-existing vertex ->'${node}'`; } } else { throw `You should add '${vertex}' first`; } }
3. print:列印圖( Graph)
print() { for (let [key, value] of this.AdjList) { console.log(key, value); } }
測試一下
let g = new Graph(); let arr = ['A', 'B', 'C', 'D', 'E', 'F']; for (let i = 0; i < arr.length; i++) { g.addVertex(arr[i]); } g.addEdge('A', 'B'); g.addEdge('A', 'D'); g.addEdge('A', 'E'); g.addEdge('B', 'C'); g.addEdge('D', 'E'); g.addEdge('E', 'F'); g.addEdge('E', 'C'); g.addEdge('C', 'F'); g.print(); /* PRINTED */ // A [ 'B', 'D', 'E' ] // B [ 'C' ] // C [ 'F' ] // D [ 'E' ] // E [ 'F', 'C' ] // F []

到目前為止,這就是創建圖所需的。但是,99%的情況下,會要求你實現另外兩種方法:
- 廣度優先演算法,
BFS。 - 深度優先演算法,
DFS BFS的重點在於隊列,而DFS的重點在於遞歸。這是它們的本質區別。
5. 廣度優先演算法實現
廣度優先演算法(Breadth-First Search),同廣度優先搜索。
是一種利用隊列實現的搜索演算法。簡單來說,其搜索過程和 「湖面丟進一塊石頭激起層層漣漪」 類似。

如上圖所示,從起點出發,對於每次出隊列的點,都要遍歷其四周的點。所以說 BFS 的搜索過程和 「湖面丟進一塊石頭激起層層漣漪」 很相似,此即 「廣度優先搜索演算法」 中「廣度」的由來。
該演算法的具體步驟為:
- BFS將起始節點作為參數。(例如
'A') - 初始化一個空對象:
visited。 - 初始化一個空數組:
q,該數組將用作隊列。 - 將起始節點標記為已訪問。
(visited = {'A': true}) - 將起始節點放入隊列中。
(q = ['A']) - 循環直到隊列為空
循環內部:
- 從中獲取元素
q並將其存儲在變數中。(let current = q.pop()) - 列印 當前
current - 從圖中獲取
current的邊。(let arr = this.AdjList.get(current))。 - 如果未訪問元素,則將每個元素標記為已訪問並將其放入隊列中。
visited = { 'A': true, 'B': true, 'D': true, 'E': true } q = ['B', 'D', 'E']
具體實現:
createVisitedObject(){ let arr = {}; for(let key of this.AdjList.keys()){ arr[key] = false; } return arr; } bfs(startingNode){ let visited = this.createVisitedObject(); let q = []; visited[startingNode] = true; q.push(startingNode); while(q.length){ let current = q.pop() console.log(current); let arr = this.AdjList.get(current); for(let elem of arr){ if(!visited[elem]){ visited[elem] = true; q.unshift(elem) } } } }
6. 深度優先演算法實現
深度優先搜索演算法(Depth-First-Search,縮寫為 DFS),是一種利用遞歸實現的搜索演算法。簡單來說,其搜索過程和 「不撞南牆不回頭」 類似。

如上圖所示,從起點出發,先把一個方向的點都遍歷完才會改變方向…… 所以說,DFS 的搜索過程和 「不撞南牆不回頭」 很相似,此即 「深度優先搜索演算法」 中「深度」的由來。
該演算法的前期步驟和BFS相似,接受起始節點並跟蹤受訪節點,最後執行遞歸的輔助函數。
具體步驟:
- 接受起點作為參數
dfs(startingNode)。 - 創建訪問對象
let visited = this.createVisitedObject()。 - 調用輔助函數遞歸起始節點和訪問對象
this.dfsHelper(startingNode, visited)。 dfsHelper將其標記為已訪問並列印出來。
createVisitedObject(){ let arr = {}; for(let key of this.AdjList.keys()){ arr[key] = false; } return arr; } dfs(startingNode){ console.log('nDFS') let visited = this.createVisitedObject(); this.dfsHelper(startingNode, visited); } dfsHelper(startingNode, visited){ visited[startingNode] = true; console.log(startingNode); let arr = this.AdjList.get(startingNode); for(let elem of arr){ if(!visited[elem]){ this.dfsHelper(elem, visited); } } } doesPathExist(firstNode, secondNode){ let path = []; let visited = this.createVisitedObject(); let q = []; visited[firstNode] = true; q.push(firstNode); while(q.length){ let node = q.pop(); path.push(node); let elements = this.AdjList.get(node); if(elements.includes(secondNode)){ console.log(path.join('->')) return true; }else{ for(let elem of elements){ if(!visited[elem]){ visited[elem] = true; q.unshift(elem); } } } } return false; } }
Vans,下一個。
8. 字典樹: Trie

Trie(通常發音為「try」)是針對特定類型的搜索而優化的樹數據結構。當你想要獲取部分值並返回一組可能的完整值時,可以使用 Trie。典型的例子是自動完成。

Trie,是一種搜索樹,也稱字典樹或單詞查找樹,此外也稱前綴樹,因為某節點的後代存在共同的前綴。
它的特點:
- key都為字元串,能做到高效查詢和插入,時間複雜度為
O(k),k為字元串長度 - 缺點是如果大量字元串沒有共同前綴時很耗記憶體。
- 它的核心思想就是減少沒必要的字元比較,使查詢高效率。
- 即用空間換時間,再利用共同前綴來提高查詢效率。
例如: 搜索前綴「b」的匹配將返回6個值: be, bear, bell, bid, bull, buy。

搜索前綴「 be」的匹配將返回2個值: bear,bell

8.1 字典樹的應用
只要你想要將前綴與可能的完整值匹配,就可以使用 Trie。
現實中多運用在:
- 自動填充/預先輸入
- 搜索
- 輸入法選項
- 分類
也可以運用在:
- IP地址檢索
- 電話號碼
- 以及更多…
8.2 字典樹的實現
class PrefixTreeNode { constructor(value) { this.children = {}; this.endWord = null; this.value = value; } } class PrefixTree extends PrefixTreeNode { constructor() { super(null); } // 基礎操作方法 // addWord(string) {} // predictWord(string) {} // logAllWords() {} }
1. addWord: 創建一個節點
addWord(string) { const addWordHelper = (node, str) => { if (!node.children[str[0]]) { node.children[str[0]] = new PrefixTreeNode(str[0]); if (str.length === 1) { node.children[str[0]].endWord = 1; } else if (str.length > 1) { addWordHelper(node.children[str[0]], str.slice(1)); } }; addWordHelper(this, string); }
2. predictWord:預測單詞
即:給定一個字元串,返回樹中以該字元串開頭的所有單詞。
predictWord(string) { let getRemainingTree = function(string, tree) { let node = tree; while (string) { node = node.children[string[0]]; string = string.substr(1); } return node; }; let allWords = []; let allWordsHelper = function(stringSoFar, tree) { for (let k in tree.children) { const child = tree.children[k] let newString = stringSoFar + child.value; if (child.endWord) { allWords.push(newString); } allWordsHelper(newString, child); } }; let remainingTree = getRemainingTree(string, this); if (remainingTree) { allWordsHelper(string, remainingTree); } return allWords; }
3. logAllWords:列印所有的節點
logAllWords() { console.log('------ 所有在字典樹中的節點 -----------') console.log(this.predictWord('')); }
logAllWords,通過在空字元串上調用 predictWord來列印 Trie中的所有節點。
9. 散列表(哈希表): HashTables
使用哈希表可以進行非常快速的查找操作。但是,哈希表究竟是什麼玩意兒?
很多語言的內置數據結構像 python中的字典, java中的 HashMap,都是基於哈希表實現。但哈希表究竟是啥?
9.1 哈希表是什麼?
散列(hashing)是電腦科學中一種對資料的處理方法,通過某種特定的函數/演算法(稱為散列函數/演算法)將要檢索的項與用來檢索的索引(稱為散列,或者散列值)關聯起來,生成一種便於搜索的數據結構(稱為散列表)。也譯為散列。舊譯哈希(誤以為是人名而採用了音譯)。 它也常用作一種資訊安全的實作方法,由一串資料中經過散列演算法(
Hashingalgorithms)計算出來的資料指紋(data fingerprint),經常用來識別檔案與資料是否有被竄改,以保證檔案與資料確實是由原創者所提供。 —-Wikipedia
9.2 哈希表的構成
HashTables優化了鍵值對的存儲。在最佳情況下,哈希表的插入,檢索和刪除是恆定時間。哈希表用於存儲大量快速訪問的資訊,如密碼。
哈希表可以概念化為一個數組,其中包含一系列存儲在對象內部子數組中的元組:
{[[['a',9],['b',88]],[['e',7],['q',8]],[['j',7],['l ',8]]]};
- 外部數組有多個等於數組最大長度的桶(子數組)。
- 在桶內,元組或兩個元素數組保持鍵值對。
9.3 哈希表的基礎知識
這裡我就嘗試以大白話形式講清楚基礎的哈希表知識:
散列是一種用於從一組相似對象中唯一標識特定對象的技術。我們生活中如何使用散列的一些例子包括:
- 在大學中,每個學生都會被分配一個唯一的卷號,可用於檢索有關它們的資訊。
- 在圖書館中,每本書都被分配了一個唯一的編號,可用於確定有關圖書的資訊,例如圖書館中的確切位置或已發給圖書的用戶等。
在這兩個例子中,學生和書籍都被分成了一個唯一的數字。
1. 思考一個問題
假設有一個對象,你想為其分配一個鍵以便於搜索。要存儲鍵/值對,您可以使用一個簡單的數組,如數據結構,其中鍵(整數)可以直接用作存儲值的索引。
但是,如果密鑰很大並且無法直接用作索引,此時就應該使用散列。
2, 一個哈希表的誕生
具體步驟如下:
- 在散列中,通過使用散列函數將大鍵轉換為小鍵。
- 然後將這些值存儲在稱為哈希表的數據結構中。
- 散列的想法是在數組中統一分配條目(鍵/值對)。為每個元素分配一個鍵(轉換鍵)。
- 通過使用該鍵,您可以在
O(1)時間內訪問該元素。 - 使用密鑰,演算法(散列函數)計算一個索引,可以找到或插入條目的位置。
具體執行分兩步:
- 通過使用散列函數將元素轉換為整數。此元素可用作存儲原始元素的索引,該元素屬於哈希表。
- 該元素存儲在哈希表中,可以使用散列鍵快速檢索它。
hash = hashfunc(key) index = hash % array_size
在此方法中,散列與數組大小無關,然後通過使用運算符(%)將其縮減為索引(介於 0和 array_size之間的數字-1)。
3. 哈希函數
- 哈希函數是可用於將任意大小的數據集映射到固定大小的數據集的任何函數,該數據集屬於散列表
- 哈希函數返回的值稱為哈希值,哈希碼,哈希值或簡單哈希值。
要實現良好的散列機制,需要具有以下基本要求:
- 易於計算:它應該易於計算,並且不能成為演算法本身。
- 統一分布:它應該在哈希表中提供統一分布,不應導致群集。
- 較少的衝突:當元素對映射到相同的哈希值時發生衝突。應該避免這些。
注意:無論散列函數有多健壯,都必然會發生衝突。因此,為了保持哈希表的性能,通過各種衝突解決技術來管理衝突是很重要的。
4. 良好的哈希函數
假設您必須使用散列技術 {「abcdef」,「bcdefa」,「cdefab」,「defabc」}等字元串存儲在散列表中。
首先是建立索引:
a,b,c,d,e和f的ASCII值分別為97,98,99,100,101和102,總和為:597597不是素數,取其附近的素數599,來減少索引不同字元串(衝突)的可能性。
哈希函數將為所有字元串計算相同的索引,並且字元串將以下格式存儲在哈希表中。
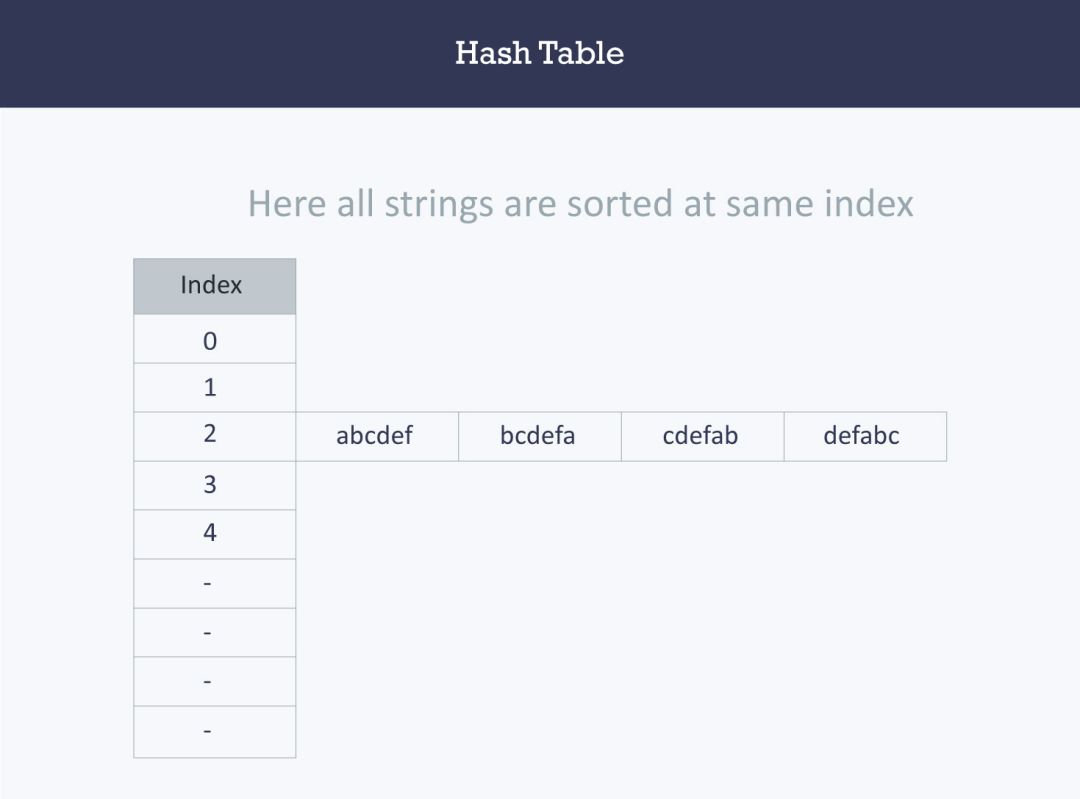
由於所有字元串的索引都相同,此時所有字元串都在同一個「桶」中。
- 這裡,訪問特定字元串需要
O(n)時間(其中n是字元串數)。 - 這表明該哈希函數不是一個好的哈希函數。
如何優化這個哈希函數?
注意觀察這些字元串的異同
{「abcdef」,「bcdefa」,「cdefab」,「defabc」}
- 都是由
a,b,c,d,e和f組成 - 不同點在於組成順序。
來嘗試不同的哈希函數。
- 特定字元串的索引將等於字元的ASCII值之和乘以字元串中它們各自的順序
- 之後將它與
2069(素數)取余。
字元串哈希函數索引
|
字元串 |
索引生成 |
計算值 |
|---|---|---|
|
abcdef |
(97 1 + 98 2 + 99 3 + 100 4 + 101 5 + 102 6)%2069 |
38 |
|
bcdefa |
(98 1 + 99 2 + 100 3 + 101 4 + 102 5 + 97 6)%2069 |
23 |
|
cdefab |
(99 1 + 100 2 + 101 3 + 102 4 + 97 5 + 98 6)%2069 |
14 |
|
defabc |
(100 1 + 101 2 + 102 3 + 97 4 + 98 5 + 99 6)%2069 |
11 |

在合理的假設下,在哈希表中搜索元素所需的平均時間應是O(1)。
9.4 哈希表的實現

class Node { constructor( data ){ this.data = data; this.next = null; } } class HashTableWithChaining { constructor( size = 10 ) { this.table = new Array( size ); } // 操作方法 // computeHash( string ) {...} // ... }

1. isPrime:素數判斷
isPrime( num ) { for(let i = 2, s = Math.sqrt(num); i <= s; i++) if(num % i === 0) return false; return num !== 1; }
2. computeHash|findPrime:哈希函數生成
computeHash( string ) { let H = this.findPrime( this.table.length ); let total = 0; for (let i = 0; i < string.length; ++i) { total += H * total + string.charCodeAt(i); } return total % this.table.length; } // 取模 findPrime( num ) { while(true) { if( this.isPrime(num) ){ break; } num += 1 } return num; }
3. Put:插入值
put( item ) { let key = this.computeHash( item ); let node = new Node(item) if ( this.table[key] ) { node.next = this.table[key] } this.table[key] = node }

4. Remove:刪除值
remove( item ) { let key = this.computeHash( item ); if( this.table[key] ) { if( this.table[key].data === item ) { this.table[key] = this.table[key].next } else { let current = this.table[key].next; let prev = this.table[key]; while( current ) { if( current.data === item ) { prev.next = current.next } prev = current current = current.next; } } } }


5. contains:判斷包含
contains(item) { for (let i = 0; i < this.table.length; i++) { if (this.table[i]) { let current = this.table[i]; while (current) { if (current.data === item) { return true; } current = current.next; } } } return false; }
6. Size&IsEmpty:判斷長度或空
size( item ) { let counter = 0 for(let i=0; i<this.table.length; i++){ if( this.table[i] ) { let current = this.table[i] while( current ) { counter++ current = current.next } } } return counter } isEmpty() { return this.size() < 1 }

7. Traverse:遍歷
traverse( fn ) { for(let i=0; i<this.table.length; i++){ if( this.table[i] ) { let current = this.table[i]; while( current ) { fn( current ); current = current.next; } } } }

最後放張哈希表的執行效率圖

10. 為啥寫這篇
還是和面試有關。雖然 leetcode上的題刷過一些,但因為缺乏對數據結構的整體認知。很多時候被問到或考到,會無所下手。
網上的帖子大多深淺不一,寫這篇的過程中翻閱了大量的資料和示例。在下的文章都是學習過程中的總結,如果發現錯誤,歡迎留言指出。
參考:
- DS with JS – Hash Tables— I
- Joseph Crick – Practical Data Structures for Frontend Applications: When to use Tries
- Thon Ly – Data Structures in JavaScript
- Graphs — A Visual Introduction for Beginners
- Graph Data Structure in JavaScript
- Trie (Keyword Tree)
求一份深圳的內推
好了,又水完一篇,入正題:
目前本人在(又)準備跳槽,希望各位大佬和HR小姐姐可以內推一份靠譜的深圳前端崗位!
- 微信:
huab119 - 郵箱:
[email protected]
