心有 netty 一點通!
一、標準的netty執行緒模型
雙池合璧:
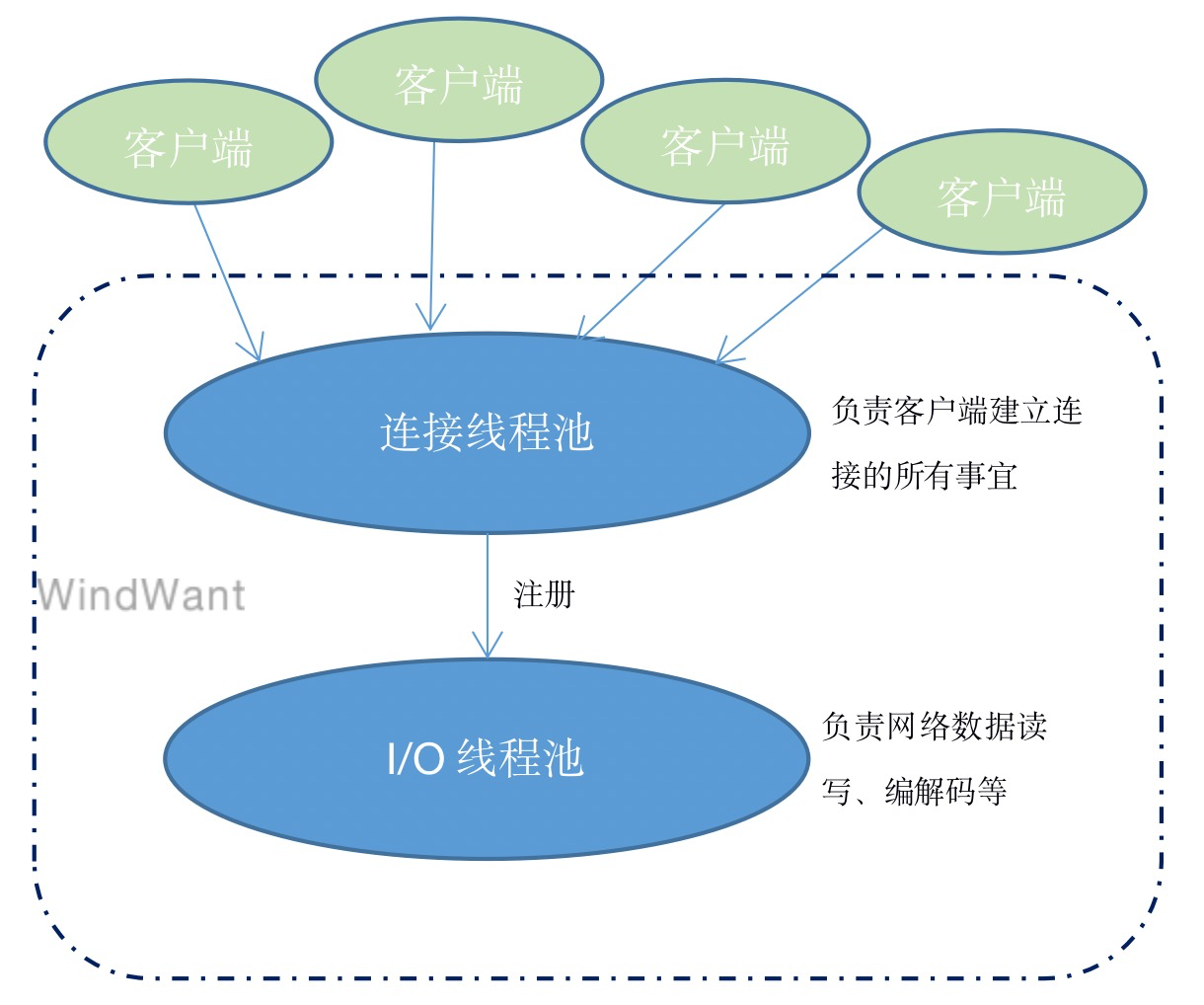
1、連接執行緒池:
連接執行緒池專門負責監聽客戶端連接請求,並完成連接的建立(包括諸如握手、安全認證等過程)。
連接的建立本身是一個極其複雜、損耗性能的過程,此處使用執行緒池,能夠極大的增加處理客戶端連接的能力。
2、I/O執行緒池:
連接執行緒池會將成功建立的連接註冊到後端I/O執行緒池,由I/O執行緒池負責對相應連接的網路數據進行讀寫、編解碼處理。
在實際應用中,我們通常會定義相應的業務消息協議,並選擇合適的序列化機制,netty I/O執行緒池部分根據預設的規則進行數據的編解碼。
二、延伸的業務執行緒池

其實我們這裡說的業務執行緒池不在網路層處理邏輯里。處理到I/O執行緒池部分,所需要的請求數據已經處理完畢,涉及具體的業務處理邏輯,比較複雜的,或者時間、性能消耗特別大的,通常我們會單獨設置相應的執行緒池來處理。
三、netty的極致性能設計
1、無鎖化設計
I/O執行緒的內部串列化:

局部無鎖化串列處理,避免多執行緒切換帶來的複雜性及性能損耗(鎖競爭、CPU資源分配)。至於對於處理能力的考慮,可以通過調整I/O執行緒池容量來平衡。
盡量避免I/O執行緒和業務執行緒混淆及切換。
2、直接記憶體使用
TCP接收和發送使用直接記憶體代替堆記憶體,避免了數據在堆記憶體和主記憶體之間的複製消耗,提升了I/O讀取和寫入的性能。

3、transferTo
依賴於作業系統零拷貝特性直接將緩衝區數據發送到相應的通道。

傳統的方式,先將源文件拷貝到記憶體,然後由記憶體寫到目的文件。
netty 利用 NIO FileChannel transferTo方法,通道對通道寫數據。
4、CompositeByteBuf
組合快取使用可以像操作單個快取一樣操作多個快取,避免了傳統的操作方式帶來的記憶體複製性能消耗。

5、記憶體池使用
netty支援通過記憶體池的方式循環利用ByteBuf,避免了頻繁的創建,銷毀ByteBuf帶來的資源及性能損耗。
ByteBuf byte數據緩衝區,是NIO編程的主要對象。高負載情景下,ByteBuf記憶體池使用,可以有效降低GC頻率。
PoolArena netty的記憶體池實現類。PoolArena 是由多個Chunk組成的大塊記憶體區域,每個Chunk由一個多個Page組成。
Chunk:組織管理Page的記憶體分配和釋放,Page被構建為二叉樹形式:

PoolSubpage:對於小於Page的記憶體使用,直接在Page中完成分配,每個Page切分為大小相同的多個存儲塊兒,存儲塊兒的大小由第一次申請的記憶體塊兒大小決定。
回收:netty使用狀態位標識Chunk及Page記憶體可用性,Chunk標識二叉樹Page節點使用狀態;Page標識內部記憶體塊兒的使用狀態。
6、執行緒安全優化
合理的使用執行緒安全容器、原子類等,提升系統的並發處理能力,
7、引用計數器
通過引用計數器及時的申請釋放不再引用的對象,細粒度的記憶體管理降低了GC的頻率,減少GC帶來的時延增大和CPU損耗。
Netty 4中 ByteBuf 和 ByteBufHolder 引入引用計數器功能(實現ReferenceCounted介面),在特定的對象上跟蹤引用的數目。
引用計數器初始為1。如果對象活動的引用計數器大於0,則不會被釋放。當引用計數減少到0,實例將會被釋放。這也是 PooledByteBufAllocator 記憶體池應用的核心特性。


