MongoDB知識點總結
一:MongoDB 概述
一、NoSQL 簡介
1. 概念:NoSQL(Not Only SQL的縮寫),指的是非關係型資料庫,是對不同於傳統的關係型資料庫的資料庫管理系統的統稱。用於超大規模數據的存儲,數據存儲不需要固定的模式,無需多餘操作就可以橫向擴展。
2. 特點
1. 優點:具有高可擴展性、分散式計算、低成本、架構靈活且是半結構化數據,沒有複雜的關係等。
2. 缺點:沒有標準化、有限的查詢功能、最終一致是不直觀的程式等。
3. 分類


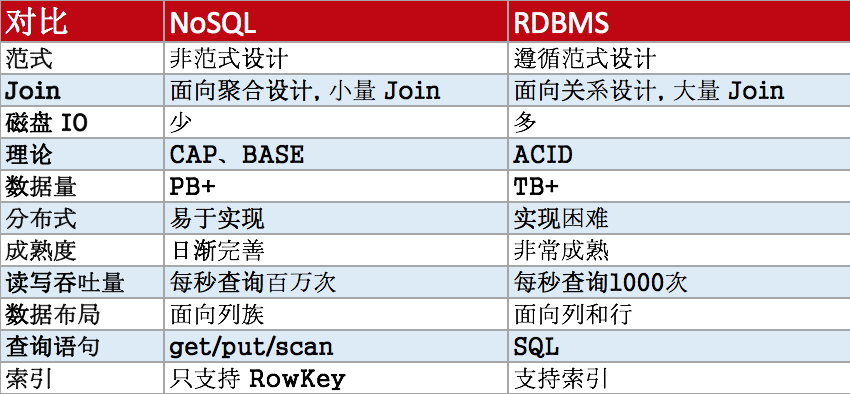
4. NoSQL 和 RDBMS 的對比
二、MongoDB 簡介
1. 概念:MongoDB 是由C++語言編寫的一個基於分散式文件存儲的開源文檔型資料庫系統。
2. 功能:JSON 文檔模型、動態的數據模式、二級索引強大、查詢功能、自動分片、水平擴展、自動複製、高可用、文本搜索、企業級安全、聚合框架MapReduce、大文件存儲GridFS。
1. 面向集合文檔的存儲:適合存儲Bson(json的擴展)形式的數據;
2. 格式自由,數據格式不固定,生產環境下修改結構都可以不影響程式運行;
3. 強大的查詢語句,面向對象的查詢語言,基本覆蓋sql語言所有能力;
4. 完整的索引支援,支援查詢計劃;
5. 使用分片集群提升系統擴展性;
3. 適用場景
1. 網站數據:Mongo非常適合實時的插入,更新與查詢,並具備網站實時數據存儲所需的複製及高度伸縮性。
2. 快取:由於性能很高,Mongo也適合作為資訊基礎設施的快取層。在系統重啟之後,由Mongo搭建的持久化快取層可以避免下層的數據源 過載。
3. 在高伸縮性的場景,用於對象及JSON數據的存儲。

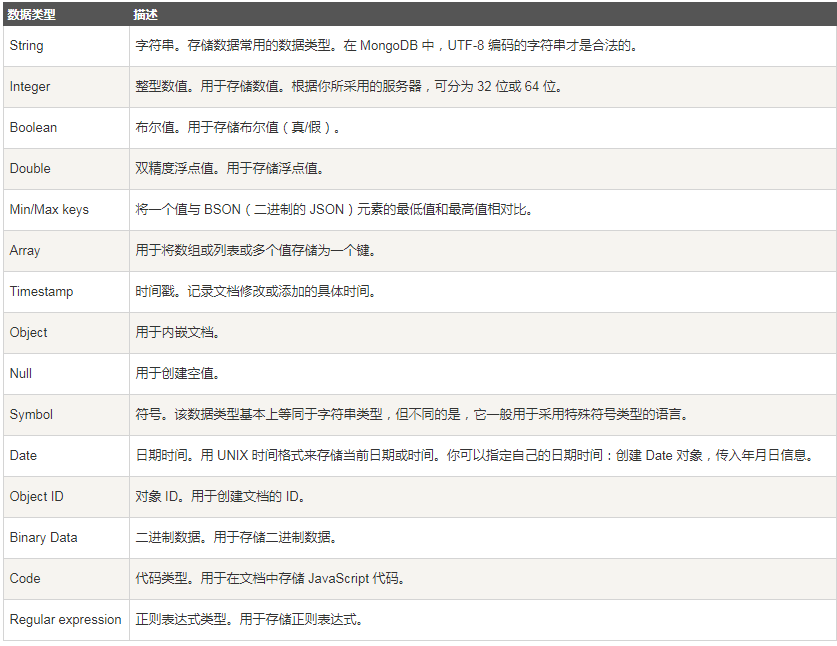
4. 數據類型
三、概念詳解
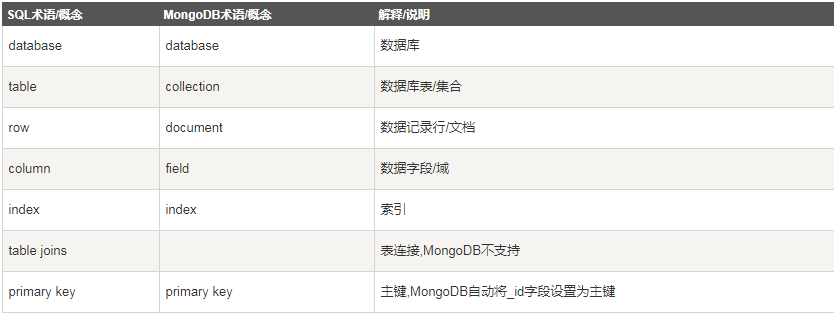
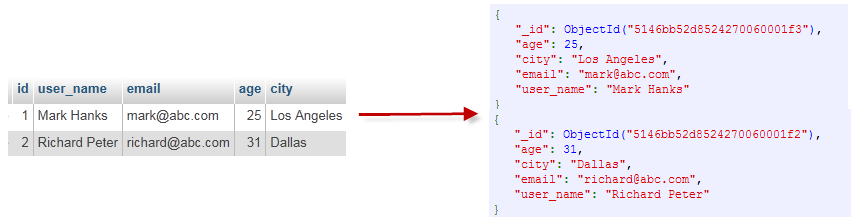
1. 資料庫:MongoDB 默認的資料庫為”db”,該資料庫存儲在data目錄中。單個實例可以容納多個獨立的資料庫,每一個都有自己的集合和許可權,不同的資料庫也放置在不同的文件中。
2. 集合:集合就是 MongoDB 文檔組,類似於 RDBMS 的表格。集合存在於資料庫中,集合沒有固定的結構,這意味著你在對集合可以插入不同格式和類型的數據,但通常情況下我們插入集合的數據都會有一定的關聯性。
3. 文檔:一個鍵值(key-value)對(即BSON)。MongoDB 的文檔不需要設置相同的欄位,並且相同的欄位不需要相同的數據類型,這與關係型資料庫有很大的區別,也是 MongoDB 非常突出的特點。
四、安裝配置
1. Windows
1. 下載(4.2.7版本以上)並直接安裝
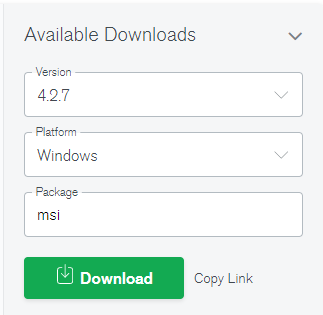
2. 配置環境變數

3. 測試
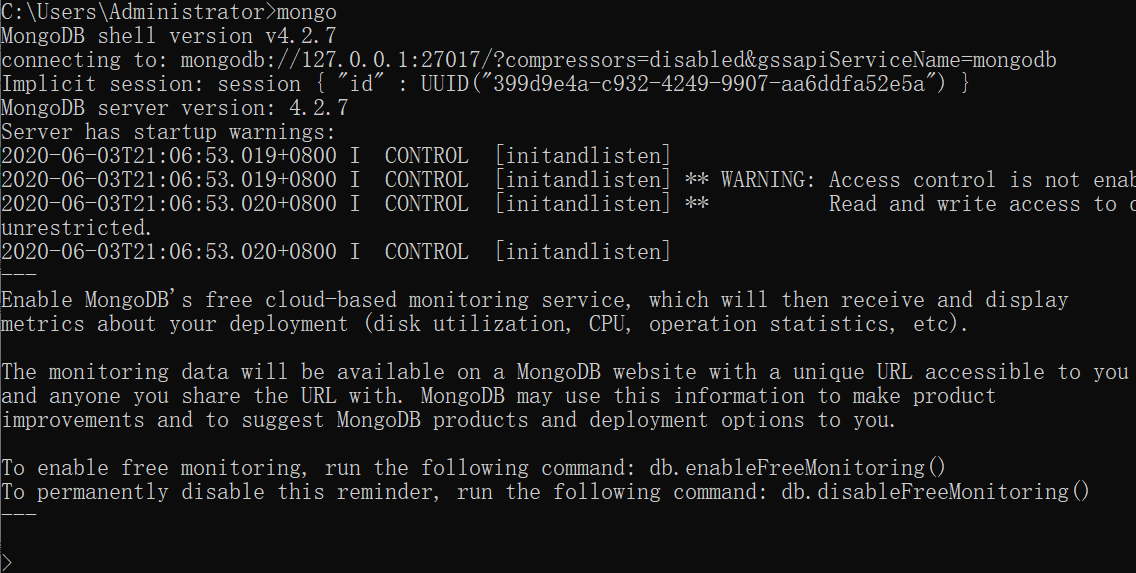
=
2. Linux

1 # 解壓到指定目錄 2 tar -zxvf mongodb-linux-x86_64-rhel70-4.2.7.tgz -C /opt/ 3 4 # 配置環境變數 5 # MONGODB_HOME 6 export MONGODB_HOME=/opt/mongodb-linux-x86_64-rhel70-4.2.7 7 export PATH=$PATH:$MONGODB_HOME/bin 8 9 # 測試 10 [root@controller ~]# mongo 11 MongoDB shell version: 4.2.7 12 connecting to: test
二:MongoDB CLI
一、增刪改

二、操作符

三、查詢
1. 基本操作

2. 聚合查詢

3. 管道操作:MongoDB的聚合管道將MongoDB文檔在一個管道處理完畢後將結果傳遞給下一個管道處理

五、管理
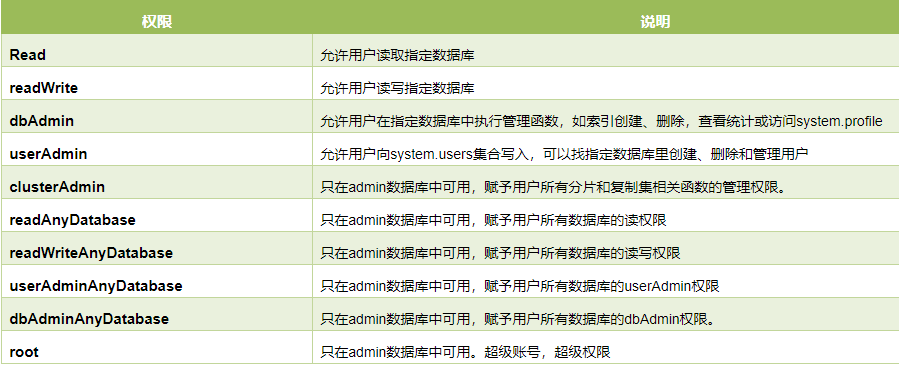

六、索引和高可用
1. 索引
簡介 作用:索引通常能夠極大的提高查詢的效率,如果沒有索引,MongoDB在讀取數據時必須掃描集合中的每個文件並選取那些符合查詢條件的記錄。索引主要用於排序和檢索。 MongoDB使用 ensureIndex() 方法來創建索引,ensureIndex()方法基本語法格式如下所示: db.collection.createIndex(keys, options) 語法中 Key 值為要創建的索引欄位,1為指定按升序創建索引,如果你想按降序來創建索引指定為-1,也可以指定為hashed(哈希索引)。 索引屬性: background:是否後台構建索引,在生產環境中,如果數據量太大,構建索引可能會消耗很長時間,為了不影響業務,可以加上此參數,後台運行同時還會為其他讀寫操作讓路,這個建議配置為true開啟,這樣來提高效率。 unique:是否為唯一索引 索引類型: 單鍵索引: 在某一個特定的屬性上建立索引,例如:db.users. createIndex({age:-1}); 1,mongoDB在ID上建立了唯一的單鍵索引,所以經常會使用id來進行查詢; 2,在索引欄位上進行精確匹配、排序以及範圍查找都會使用此索引; 複合索引: 在多個特定的屬性上建立索引,例如:db.users. createIndex({username:1,age:-1,country:1}); 1,複合索引鍵的排序順序,可以確定該索引是否可以支援排序操作; 2,在索引欄位上進行精確匹配、排序以及範圍查找都會使用此索引,但與索引的順序有關; 3,為了性能考慮,應刪除存在與第一個鍵相同的單鍵索引 多鍵索引: 在數組的屬性上建立索引,例如:db.users. createIndex({favorites.city:1}); 哈希索引: 不同於傳統的B-樹索引,哈希索引使用hash函數來創建索引。 1,在索引欄位上進行精確匹配,但不支援範圍查詢,不支援多鍵hash; 2,Hash索引上的入口是均勻分布的,在分片集合中非常有用; 優化 1,開啟內置的查詢分析器,記錄讀寫操作效率: db.setProfilingLevel(n,{m}),n的取值可選0,1,2; 0是默認值表示不記錄; 1表示記錄慢速操作,如果值為1,m必須賦值單位為ms,用於定義慢速查詢時間的閾值; 2表示記錄所有的讀寫操作; 2,分析慢速查詢 就是查看執行計劃,使用explain分析慢速查詢。 explain的入參可選值為: "queryPlanner":是默認值,表示僅僅展示執行計劃資訊; "executionStats":表示展示執行計劃資訊同時展示被選中的執行計劃的執行情況資訊; "allPlansExecution":表示展示執行計劃資訊,並展示被選中的執行計劃的執行情況資訊,還展示備選的執行計劃的執行情況資訊 3,合理建立索引 建立索引的規則: 1,索引很有用,但是它也是有成本的——它占記憶體,讓寫入變慢; 2,mongoDB通常在一次查詢里使用一個索引,所以多個欄位的查詢或者排序需要複合索引才能更加高效; 3,複合索引的順序非常重要,例如此腳本所示: 4,在生成環境構建索引往往開銷很大,時間也不可以接受,在數據量龐大之前盡量進行查詢優化和構建索引; 5,避免昂貴的查詢,使用查詢分析器記錄那些開銷很大的查詢便於問題排查; 6,通過減少掃描文檔數量來優化查詢,使用explain對開銷大的查詢進行分析並優化; 7,索引是用來查詢小範圍數據的,不適合使用索引的情況: 1,每次查詢都需要返回大部分數據的文檔,避免使用索引 2,寫比讀多 優化目標: 1,根據需求建立索引 2,每個查詢都要使用索引以提高查詢效率, winningPlan. stage 必須為IXSCAN ; 3,追求totalDocsExamined = nReturned
2. 高可用
1,可複製集 可複製集是跨多個MongDB伺服器(節點)分布和維護數據的方法。mongoDB可以把數據從一個節點複製到其他節點並在修改時進行同步,集群中的節點配置為自動同步數據;舊方法叫做主從複製,mongoDB 3.0以後推薦使用可複製集; 作用: 1,避免數據丟失,保障數據安全,提高系統安全性; (最少3節點,最大50節點) 2,自動化災備機制,主節點宕機後通過選舉產生新主機;提高系統健壯性; (7個選舉節點上限) 3,讀寫分離,負載均衡,提高系統性能; 4,生產環境推薦的部署模式; 原理: 數據同步:從節點與主節點保持長輪詢;1.從節點查詢本機oplog最新時間戳;2.查詢主節點oplog晚於此時間戳的所有文檔;3.載入這些文檔,並根據log執行寫操作; 阻塞複製:與writeconcern相關,不需要同步到從節點的策略(如: acknowledged Unacknowledged 、w1),數據同步都是非同步的,其他情況都是同步; 心跳機制:成員之間會每2s 進行一次心跳檢測(ping操作),發現故障後進行選舉和故障轉移; 選舉制度:主節點故障後,其餘節點根據優先順序和bully演算法選舉出新的主節點,在選出主節點之前,集群服務是只讀的; 注意: MongoDB複製集里Primary節點是不固定的,所以生產環境千萬不要直連Primary。 2,分片集群 分片是把大型數據集進行分區成更小的可管理的片,這些數據片分散到不同的mongoDB節點,這些節點組成了分片集群。 作用: 1,數據海量增長,需要更大的讀寫吞吐量:存儲分散式 2,單台伺服器記憶體、cpu等資源是有瓶頸的:負載分散式 注意:分片集群是個雙刃劍,在提高系統可擴展性和性能的同時,增大了系統的複雜性,所以在實施之前請確定是必須的。 容易發生的狀況: 請求分流:通過路由節點將請求分發到對應的分片和塊中; 數據分流:內部提供平衡器保證數據的均勻分布,數據平均分散式請求平均分布的前提; 塊的拆分:3.4版本塊的最大容量為64M或者10w的數據,當到達這個閾值,觸發塊的拆分,一分為二; 塊的遷移:為保證數據在分片節點伺服器分片節點伺服器均勻分布,塊會在節點之間遷移。一般相差8個分塊的時候觸發; 分片注意點: 熱點 :某些分片鍵會導致所有的讀或者寫請求都操作在單個數據塊或者分片上,導致單個分片伺服器嚴重不堪重負。自增長的分片鍵容易導致寫熱點問題; 不可分割數據塊:過於粗粒度的分片鍵可能導致許多文檔使用相同的分片鍵,這意味著這些文檔不能被分割為多個數據塊,限制了mongoDB均勻分布數據的能力; 查詢障礙:分片鍵與查詢沒有關聯,造成糟糕的查詢性能。 建議: 1,不要使用自增長的欄位作為分片鍵,避免熱點問題; 2,不能使用粗粒度的分片鍵,避免數據塊無法分割; 3,不能使用完全隨機的分片鍵值,造成查詢性能低下; 4,使用與常用查詢相關的欄位作為分片鍵,而且包含唯一欄位(如業務主鍵,id等); 5,索引對於分區同樣重要,每個分片集合上要有同樣的索引,分片鍵默認成為索引;分片集合只允許在id和分片鍵上創建唯一索引;
三:MongoDB API
一、
二、
三、

