HBase學習與實踐
- 2019 年 10 月 8 日
- 筆記

Photo by bealach verse on Unsplash
參考書籍:《HBase 權威指南》 —— Lars George著。
文章為個人從零開始學習記錄,如有錯誤,還請不吝賜教。
本文鏈接:https://www.cnblogs.com/novwind/p/11637404.html
· HBase 簡述

HBase是一個開源的非關係型分散式資料庫(NoSQL),它參考了Google的BigTable建模,實現的程式語言為 Java,運行於HDFS文件系統之上,為 Hadoop 提供類似於BigTable 規模的服務。HBase以極高的容錯和彈性方式處理稀疏數據,以及它可以處理多種類型的數據的方式,這也使其適用於各種業務場景。
HBase在列上實現了BigTable論文提到的壓縮演算法、記憶體操作和布隆過濾器。HBase的表能夠作為MapReduce任務的輸入和輸出,可以通過Java API來訪問數據,也可以通過REST、Avro或者Thrift的API來訪問。
PS:NoSQL最初指「非SQL」或「非關係」,有時也稱「Not Only SQL」,即「不僅SQL」,或對關係型SQL數據系統的補充。傳統關係型資料庫在處理數據密集型應用方面顯得力不從心,主要表現在靈活性差、擴展性差、性能差等方面。
· 表的特點
HBase是一個面向列的資料庫,在HBase中,最基本的單位是列(column).一列或多列形成一行(row),並由唯一的行鍵(row key)來確定存儲。反過來,一個表(table)中有若干行,其中每列可能有多個版本,在每一個單元格(cell)中存儲了不同的值。表架構僅定義列族,即鍵-值對。但是,一個表可能具有多個列族,並且此處每個列族可以具有任意數量的列。此外,在此之後的磁碟上,連續的列值被連續存儲。除了每個單元格可以保留若干個版本的數據這一點,整個結構看起來像典型的資料庫的描述,但很明顯有比這更重要的因素在所有的行按照RowKey字典序進行排序存儲。附一張自己畫的圖,畫的不是很好還請諒解,而右圖則是《HBase權威指南》一書中對HBase表與傳統資料庫表區別的描述。
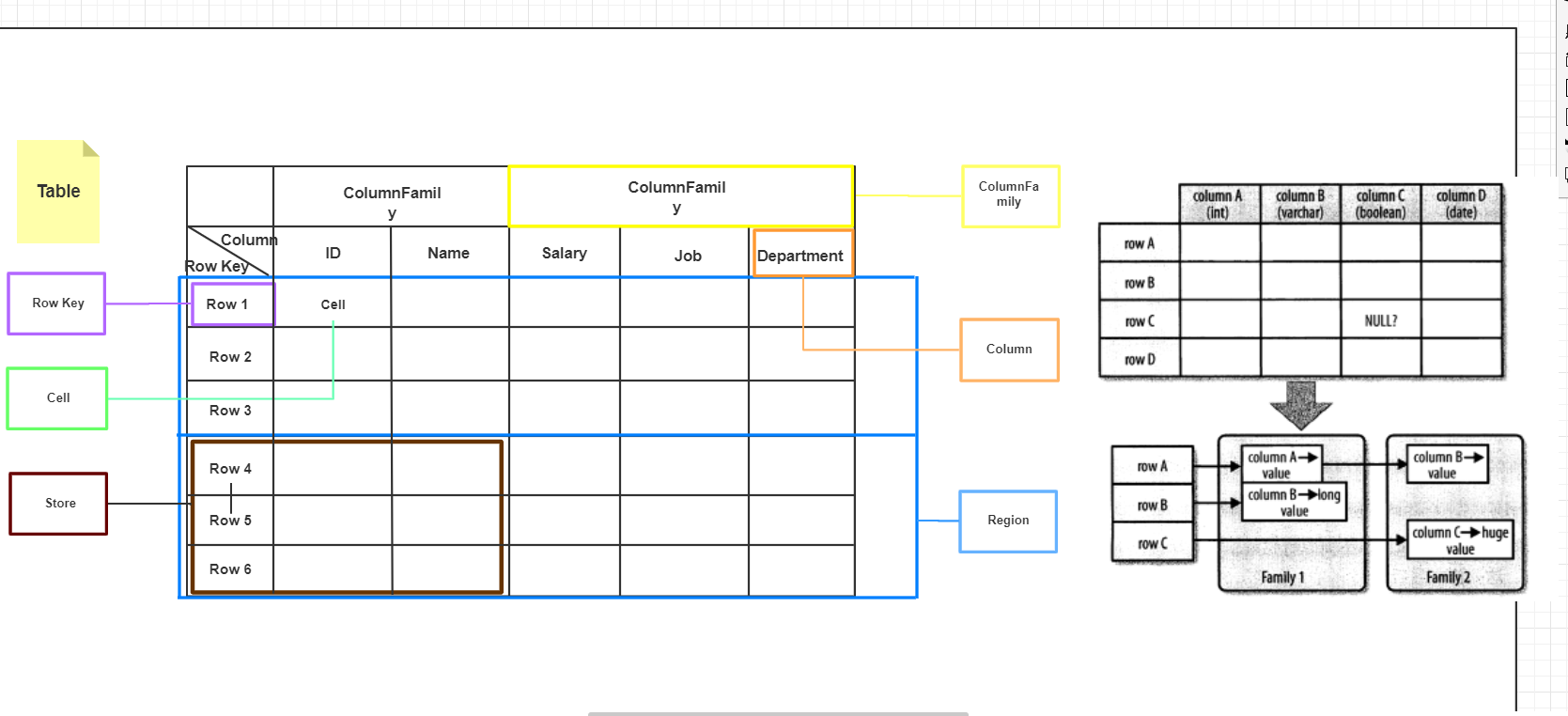
一行由若干列組成,若干列又構成一個列族(Column Family),這不僅有助於構建數據的語義邊界或者局部邊界,還有助於給它們設置某些特性(如壓縮),或者指示它們存儲在記憶體中。一個列族的所有列存儲在同一個底層的存儲文件里,這個存儲文件叫做HFile。
列族需要在表創建時就定義好,並且不能修改得太頻繁,數量也不能太多。在當前的實現中有少量己知的缺陷,這些缺陷使得列族數量只限於幾十,實際情況可能還小得多。列族名必須由可列印字元組成,這與其他名字或值的命名規範有顯著不同。
常見的引用列的格式為和family:qualifier,qualifier是任意的位元組數組。與列族的數量有限制相反,列的數量沒有限制:一個列族裡可以有數百萬個列。列值也沒有類型和長度的限定。
HBase中擴展和負載均衡的基本單元稱為region,region本質上是以行鍵排序的連續存儲的區間。如果region太大,系統就會把它們動態拆分,相反地,就把多個region合併,以減少存儲文件數量。每一個region只能由一台region伺服器(region server)載入,每一台region伺服器可以同時載入多個region。
數據的版本化:
HBase的一個特殊功能是,能為一個單元格(一個特定列的值)存儲多個版本的數據這是通過每個版本梗用一個時間戳.並且按照降序存儲來實現的.每個時間戳是一個長整型值,以毫秒為單位。它表示自世界標準時間(UTC)四70年1月1日0時以來所經過的時間,大多數繰作系統都有一個時鐘獲取函數來讀取這個時間。將數據存入HBase時,要麼顯式地提供一個時間戳,要麼忽略該時間戳.如果用戶忽略該時間戳的話,RegionServer會在執行put操作的時候填充該時間戳。
· 基礎架構
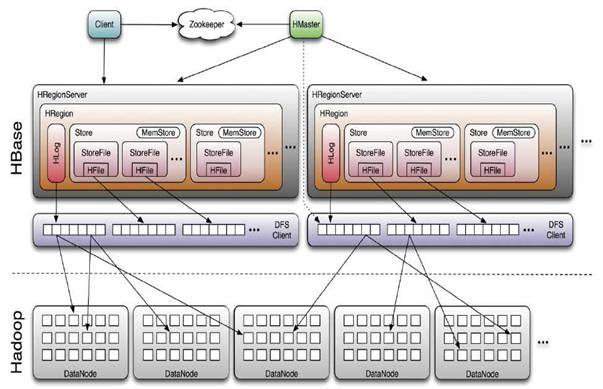
架構簡述:
- HMaster:HBASE體系結構遵循傳統的Master-Slave模型,其中有一個Master負責決策,一個或多個Slave執行真正的任務。在HBASE中,Master Server稱為HMaster,HMaster是Master Server的實現,它負責監視集群中的所有RegionServer實例並實現負載均衡,是所有元數據更改的介面。在分散式集群中,Master Server通常運行在NameNode.
- RegionServer:HBase中Slave稱為HRegionServers,是RegionServer的實現,負責管理Region,通常運行在DataNode。
- Regions:Region是表的可用性和分發的基本元素,由每個列族的存儲庫組成。
- Client:HBase Client通過查詢Hbase:meta表尋找RegionServer特定的行範圍。定位所需Region後,Client與服務於該區域的RegionServer聯繫,而不是通過Master,並發出讀寫請求。此資訊被快取在Client中,因此後續請求不必經過查找過程。如果某個Region由Master負載均衡重新分配,或者由於RegionServer已死,Client將再次請求meta表以確定User Region的新位置。
- ZooKeeper:Zookeeper集群用於存放整個 HBase集群的元數據以及集群的狀態資訊。並實現HMaster主從節點的故障轉移。
之所以是簡述是因為發現有這塊已經有很多優秀、詳盡的資料可供參考,那麼附上這些鏈接:
- Apache HBase ™ Reference Guide
- HBase and MapR Database: Designed for Distribution, Scale, and Speed
- An In-Depth Look at the HBase Architecture
- Overview of HBase Architecture and its Components
- 深入HBase架構解析(一)
· HBase Shell
這部分的學習過程參考了HBase 入門指南中推薦的鏈接(需要梯子):HBase shell commands
其實即使沒有其他資料,開啟HBase Shell,輸入命令 help,可以看到命令的提示(以下截取部分非完整),對於每條命令都可以使用 help "command"的方式查看其詳細參數和使用方式,只要理解了表的邏輯結構再搭配上提示即使是剛接觸HBase也應該能進行CRUD操作。
hbase(main):006:0* help HBase Shell, version 2.1.6, rba26a3e1fd5bda8a84f99111d9471f62bb29ed1d, Mon Aug 26 20:40:38 CST 2019 Type 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command. Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group. COMMAND GROUPS: Group name: general Commands: processlist, status, table_help, version, whoami Group name: ddl Commands: alter, alter_async, alter_status, clone_table_schema, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, list_regions, locate_region, show_filters Group name: namespace Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables Group name: dml Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve Group name: tools Commands: assign, balance_switch, balancer, balancer_enabled, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch, cleaner_chore_enabled, cleaner_chore_run, cleaner_chore_switch, clear_block_cache, clear_compaction_queues, clear_deadservers, close_region, compact, compact_rs, compaction_state, flush, hbck_chore_run, is_in_maintenance_mode, list_deadservers, major_compact, merge_region, move, normalize, normalizer_enabled, normalizer_switch, split, splitormerge_enabled, splitormerge_switch, stop_master, stop_regionserver, trace, unassign, wal_roll, zk_dump 。。。。。。 hbase(main):009:0> help "create" Creates a table. Pass a table name, and a set of column family specifications (at least one), and, optionally, table configuration. Column specification can be a simple string (name), or a dictionary (dictionaries are described below in main help output), necessarily including NAME attribute. Examples: Create a table with namespace=ns1 and table qualifier=t1 hbase> create 'ns1:t1', {NAME => 'f1', VERSIONS => 5} Create a table with namespace=default and table qualifier=t1 hbase> create 't1', {NAME => 'f1'}, {NAME => 'f2'}, {NAME => 'f3'} hbase> # The above in shorthand would be the following: hbase> create 't1', 'f1', 'f2', 'f3' hbase> create 't1', {NAME => 'f1', VERSIONS => 1, TTL => 2592000, BLOCKCACHE => true} hbase> create 't1', {NAME => 'f1', CONFIGURATION => {'hbase.hstore.blockingStoreFiles' => '10'}} hbase> create 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 1000000, MOB_COMPACT_PARTITION_POLICY => 'weekly'} Table configuration options can be put at the end. Examples: hbase> create 'ns1:t1', 'f1', SPLITS => ['10', '20', '30', '40'] hbase> create 't1', 'f1', SPLITS => ['10', '20', '30', '40'] hbase> create 't1', 'f1', SPLITS_FILE => 'splits.txt', OWNER => 'johndoe' 。。。。。。這裡的操作大部分都可以不言自明,所以只寫一段基本的流程用於和HBase API部分作對比。至於其重要的部分可能會補充在文章的後半部分。
//創建NameSpache hbase(main):019:0> create_namespace 'company' Took 0.2666 seconds //創建表,分配兩個列族 hbase(main):020:0> create 'company:employees',{NAME => 'p_info'},{NAME => 'job_info'} Created table company:employees Took 1.4237 seconds => Hbase::Table - company:employees //創建表並指定存儲版本 hbase(main):021:0> create 'company:department',{NAME => 'info',VERSIONS => 3},{NAME => 'manager',VERSIONS => 3} Created table company:department Took 1.3701 seconds => Hbase::Table - company:department //增,在p_info列族中添加eid列,下方同理 hbase(main):022:0> put 'company:employees','0001','p_info:eid','0001' Took 0.1115 seconds hbase(main):023:0> put 'company:employees','0001','p_info:ename','john' Took 1.1250 seconds hbase(main):024:0> put 'company:employees','0001','p_info:age',23 Took 0.0093 seconds hbase(main):025:0> put 'company:employees','0002','p_info:eid',0002 Took 0.0053 seconds hbase(main):026:0> put 'company:employees','0002','p_info:ename','Steven' Took 0.0060 seconds //查,掃描全表 hbase(main):027:0> scan 'company:employees' ROWCOLUMN+CELL 0001 column=p_info:age, timestamp=1570353400606, value=23 0001 column=p_info:eid, timestamp=1570353050029, value=0001 0001 column=p_info:ename, timestamp=1570353286962, value=john 0002 column=p_info:eid, timestamp=1570353430138, value=2 0002 column=p_info:ename, timestamp=1570353477462, value=Steven 2 row(s) Took 0.0356 seconds //查,row級查詢 hbase(main):028:0> get 'company:employees','0001' COLUMN CELL p_info:age timestamp=1570353400606, value=23 p_info:eid timestamp=1570353050029, value=0001 p_info:ename timestamp=1570353286962, value=john 1 row(s) Took 0.0278 seconds //column查詢 hbase(main):029:0> get 'company:employees','0001','p_info:ename' COLUMN CELL p_info:ename timestamp=1570353286962, value=john 1 row(s) Took 0.0094 seconds hbase(main):030:0> get 'company:employees','0001','p_info:ename','p_info:age' COLUMN CELL p_info:age timestamp=1570353400606, value=23 p_info:ename timestamp=1570353286962, value=john 1 row(s) Took 0.0227 seconds //改,依舊用put,只不過會存儲多個版本 hbase(main):004:0> put "company:employees","0001","p_info:age",25 Took 0.0555 seconds hbase(main):006:0> put "company:employees","0002","p_info:eid","0002" Took 0.0088 seconds hbase(main):013:0> put "company:department","00001","info:partName","finance" Took 0.0654 seconds hbase(main):014:0> put "company:department","00001","manager:minister","katrina" Took 0.0107 seconds hbase(main):015:0> put "company:department","00001","manager:minister","lucy" Took 0.0093 seconds //指定查詢的版本數 hbase(main):017:0> scan "company:department",{RAW => true,VERSIONS => 3} ROW COLUMN+CELL 00001 column=info:partName, timestamp=1570359496407, value=finance 00001 column=manager:minister, timestamp=1570359596742, value=lucy 00001 column=manager:minister, timestamp=1570359578748, value=katrina 1 row(s) Took 0.0223 seconds //刪,刪除列 hbase(main):020:0> delete "company:department","00001","info:partName" Took 0.0651 seconds //刪列族 hbase(main):021:0> delete "company:department","00001","manager" Took 0.0187 seconds //刪行 hbase(main):023:0> deleteall "company:department","00001" Took 0.0105 seconds //下線和刪除表 hbase(main):024:0> disable "company:department" Took 0.8700 seconds hbase(main):025:0> drop "company:department" Took 0.4792 seconds · HBase API
Admin API
表示HBASE中的Admin的類是HBaseAdmin。用戶可以使用這個類執行管理員的任務(如DDL),通過使用Connection.getAdmin()方法來獲得Admin的實例,示例API:
| 方法 | 描述 |
|---|---|
| void createTable(TableDescriptor desc) | 創建一個新表。 |
| void addColumnFamily(TableName tableName, ColumnFamilyDescriptor columnFamily) | 添加列族到表 |
| void createNamespace(NamespaceDescriptor descriptor) | 新建一個Namespace |
| void flush(TableName tableName) | 刷新緩衝區表的操作 |
| TableDescriptor getDescriptor(TableName tableName) | 獲取一個表的描述符 |
。。。。。。
Table API
當使用Admin實例獲取到一個Table實例時,就可以對錶進行一系列的操作,如(DML)。在HBase中表示HBASE表的類是org.apache.hadoop.hbase.client.HTable。
- put
表的put操作可粗略分為單行和多行,根據需求構建Put對象,通過調用addColumn來給數據添加列,如果不傳入時間戳則由RegionServer來補充時間戳,那麼保證Server端的時間準確就是非常重要的工作了,確保不會出現無序的版本歷史。另外如上面的程式碼所示,使用Put方法也可以傳入一個List集合來達到插入多行的目的。
每一個Put作實際上都是一個RPC操作,它將客戶端數據傳送到伺服器然後返回。這隻適合小數據量的操作,不太合適大規模數據的讀寫。關於這裡參考書籍中提到的寫緩衝區 SetAutoFlush 和其他部分API已經被HBase版本遺棄了,找遍了各種部落格發現很多今年的文章內容也是參考了舊的書籍,最後還是自己翻看源碼和查閱文檔找到了一些描述,如:HBASE-18500
默認情況下,HBase會保留3個版本的數據,在命令行使用 scan tableName,{RAW => TRUE,VERSIONS => 3} ,RAW選項表示掃描器返回所有的單元格(包括刪除標記和未收集的已刪除單元格)。還有需要注意當使用基於列表的put調用時,用戶無法控制伺服器端執行put的順序,這意味著伺服器被調用的順序也不受用戶控制。如果要保證寫入的順序,需要小心地使用這個操作,最壞的情況是,要減少每一批量處理的操作數,並顯示地刷寫客戶端寫緩衝區,強制把操作發送到遠程伺服器。 - get
與Put對應,get用於獲取指定的一行或多行數據,根據需求構建Get對象以獲得Result實例,當用戶使用get()方法獲取數據時,HBase返回的結果包含所有匹配的單元格數據,這些數據將被封裝在一個Result實例中返回給用戶。用它提供的方法,可以從伺服器端獲取匹配指定行的特定返回值,這些值包括列族、列限定符和時間戳等。HBase還封裝了不少工具類,如上方程式碼用到的Bytes和CellUtil來方便開發。另外Result類中封裝了一些面向列的存取方法,如
public List<Cell> getColumnCells(byte [] family, byte [] qualifier)當用戶創建Get實例時默認的版本數是1,可以通過如 readVersions(int versions) 方法來設置Get實例的版本數來達到獲取多個版本的目的。
與Put多行相對的是 Result[] get(List
- delete
delete方法依舊是需要Delete示例作參數傳入,在Delete示例中可以非常靈活的添加要刪除的Row、Column、Family、Cell,如果指定了刪除列且沒有指定時間戳將會刪除該列的所有版本。而如果指定了時間戳將匹配小於等於這個這個時間戳值的版本。如果嘗試刪除未設置時間戳的單元格,什麼都不會發生。例如,某一列有版本10和版本20,則刪除版本15將不會影響現存的任何版本。在刪除列表時如Put一樣,依舊無法確定執行的順序。 - batch
batch方法要求傳入的參數是一個實現了Row介面的實例集合,該方法對delete、get、put、increment、append、RowMutations進行批處理調用。未定義操作的執行順序。意思是說,如果你做了一個PUT和一個GET相同的batch調用時,不一定保證get返回PUT所放的內容。事實上,上面所述方法的基於列表操作都是基於batch方法來實現的。
這裡在Java程式碼中以HBase的API完成對資料庫的增刪改查操作
Configuration conf = HBaseConfiguration.create(); //指定Zookeeper集群地址 conf.set("hbase.zookeeper.quorum", "master,node1,node2"); //獲取連接 Connection conn = ConnectionFactory.createConnection(conf); //獲取Admin對象 Admin admin = conn.getAdmin(); //創建一個NameSpace NamespaceDescriptor mydata = NamespaceDescriptor.create("mydata").build(); admin.createNamespace(mydata); //如果存在則刪除表 TableName zooName = TableName.valueOf("zoo"); if (admin.tableExists(zooName)) { admin.disableTable(zooName); admin.deleteTable(zooName); } //表描述器構建者 TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(zooName); List<ColumnFamilyDescriptor> columnFamily = new ArrayList<>(); //列族描述器 columnFamily.add(ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("member")).build()); //從構建者獲取表描述器 TableDescriptor zoo = tableDescriptorBuilder.setColumnFamilies(columnFamily).build(); //創建表 admin.createTable(zoo); System.out.println("zoo表是否存在:"+admin.tableExists(zooName)); //獲取HTable對象 Table tableZoo = conn.getTable(zooName); //增 List<Put> data = new ArrayList<>(); data.add(new Put("0001".getBytes()) .addColumn(Bytes.toBytes("member"),Bytes.toBytes("id"),Bytes.toBytes("0001")) .addColumn(Bytes.toBytes("member"),Bytes.toBytes("name"),Bytes.toBytes("hadoop"))); data.add(new Put(Bytes.toBytes("0002")) .addColumn(Bytes.toBytes("member"),Bytes.toBytes("id"),Bytes.toBytes("0002")) .addColumn(Bytes.toBytes("member"),Bytes.toBytes("name"),Bytes.toBytes("zookeeper"))); tableZoo.put(data); //查 Scanner或者get ResultScanner results = tableZoo.getScanner(new Scan() .addColumn("member".getBytes(), "id".getBytes()) .addColumn("member".getBytes(), "name".getBytes())); System.out.println("ROW"+"tttCOLUMN+CELL"); for (Result result : results) { for (Cell cell : result.rawCells()) { System.out.println( Bytes.toString(CellUtil.cloneRow(cell)) +"tttcolumn="+Bytes.toString(CellUtil.cloneFamily(cell)) +":"+Bytes.toString(CellUtil.cloneQualifier(cell)) +","+Bytes.toString(CellUtil.cloneValue(cell))); } } //刪 tableZoo.delete(new Delete("0002".getBytes())); tableZoo.close(); admin.disableTable(zooName); admin.deleteTable(zooName); System.out.println("zoo表是否存在:"+admin.tableExists(zooName)); admin.close(); conn.close();· HBase & MapReduce
HBase的特點之一就是可以緊密地與MapReduce集成。下面一步一步的學習與MapReduce交互的知識。
首先是文檔中給出的RowCounter示例。要讓MapReduce作業獲得所需的訪問許可權可以添加HBase所需的依賴項並使用HADOOP_CLASSPATH或-libjars選項。另外文檔還給出了其他兩種方法但明確表示不推薦:
- 添加HBASE-site.xml到Hadoop_home/conf並將HBASE的Jar包添加到$Hadoop_home/lib目錄並分發到集群的各個節點。
- 可以編輯$Hadoop_home/conf/Hadoop-env.sh並將HBASE依賴項添加到HADOOP_CLASSPATH變數。
這兩種方法都不值得推薦,因為這將使用HBASE引用來污染Hadoop安裝。它還要求您重新啟動Hadoop集群,然後Hadoop才能使用HBASE數據。
那麼開始動手,因為我安裝的每個大數據組件都在環境變數里有聲明,再將HBase的lib路徑引入到HADOOP_CLASSPATH中就可以直接啟動,記得在這之前把該啟動的組件都啟動起來,然後根據文檔的提示使用hadoop 運行jar包
{HBASE_HOME}../hadoop-2.6.0/bin/hadoop jar lib/hbase-mapreduce-2.1.6.jar An example program must be given as the first argument. Valid program names are: CellCounter: Count cells in HBase table. WALPlayer: Replay WAL files. completebulkload: Complete a bulk data load. copytable: Export a table from local cluster to peer cluster. export: Write table data to HDFS. exportsnapshot: Export the specific snapshot to a given FileSystem. import: Import data written by Export. importtsv: Import data in TSV format. rowcounter: Count rows in HBase table. verifyrep: Compare data from tables in two different clusters. It doesn't work for incrementColumnValues'd cells since timestamp is changed after appending to WAL.可以看到給出了幾個選項的提示,那麼選擇rowcounter和一個HBase中存在的表。
{HBASE_HOME}../hadoop-2.6.0/bin/hadoop jar lib/hbase-mapreduce-2.1.6.jar rowcounter student 19/09/25 20:29:37 INFO client.RMProxy: Connecting to ResourceManager at node1/192.168.0.212:8032 19/09/25 20:29:40 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT 19/09/25 20:29:40 INFO zookeeper.ZooKeeper: Client environment:host.name=Master 19/09/25 20:29:40 INFO zookeeper.ZooKeeper: Client environment:java.version=1.8.0_212 19/09/25 20:29:40 INFO zookeeper.ZooKeeper: Client environment:java.vendor=Oracle Corporation ....................省略去一大串,熟悉的MapReduce結果 HBase Counters BYTES_IN_REMOTE_RESULTS=113 BYTES_IN_RESULTS=113 MILLIS_BETWEEN_NEXTS=1043 NOT_SERVING_REGION_EXCEPTION=0 NUM_SCANNER_RESTARTS=0 NUM_SCAN_RESULTS_STALE=0 REGIONS_SCANNED=1 REMOTE_RPC_CALLS=1 REMOTE_RPC_RETRIES=0 ROWS_FILTERED=0 ROWS_SCANNED=3 RPC_CALLS=1 RPC_RETRIES=0 org.apache.hadoop.hbase.mapreduce.RowCounter$RowCounterMapper$Counters ROWS=3 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=0這些驅動類可以在org.apache.hadoop.hbase.mapreduce.Driver類中看到其實現程式碼,下面貼出一小段源碼以模仿實現
public static void main(String[] args) throws Throwable { ProgramDriver pgd = new ProgramDriver(); pgd.addClass(RowCounter.NAME, RowCounter.class, "Count rows in HBase table."); pgd.addClass(CellCounter.NAME, CellCounter.class, "Count cells in HBase table."); .......... ProgramDriver.class.getMethod("driver", new Class [] {String[].class}). invoke(pgd, new Object[]{args}); } *invoke調用的程式碼段* public int run(String[] args) throws Throwable { if (args.length == 0) { //如果沒有傳入參數就列印提示資訊 System.out.println("An example program must be given as the first argument."); printUsage(this.programs); return -1;首先第一個問題是Hadoop如何讀取HBase中的數據,想想之前學習Hadoop時提取和輸出數據用的InputFormat和OutputFormat,而HBase提供了一組專用的實現為TableInputFormatBase,用戶可使用其子類TableInputFormat來實現數據的輸入。至於數據的導入過程可參考文章附錄部分的 ImportTSV小節,下面貼出程式碼實現,由於是第一次編寫,程式碼的讀寫方式參考了 CellCounter 和 ImportTsv且練習程式碼並未考慮擴展性,僅作新手學習階段的記錄。
public class PhoneDriver { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "Phone Sales Volume"); job.setJarByClass(PhoneDriver.class); Scan scan = getConfiguredScanForJob(conf, args); //這裡參考了兩個工具類的設置方式,表名是寫死的,需要通過參數傳遞的話則可以改成變數 TableMapReduceUtil.initTableMapperJob("phone",scan,PhongMapper.class,ImmutableBytesWritable.class, Result.class,job); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); TableMapReduceUtil.initTableReducerJob("saleVolume",PhoneReducer.class,job); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Mutation.class); System.exit(job.waitForCompletion(true) ? 0 : 1); } private static Scan getConfiguredScanForJob(Configuration conf, String[] args) throws IOException { // create scan with any properties set from TableInputFormat Scan s = TableInputFormat.createScanFromConfiguration(conf); s.setCacheBlocks(false); return s; } static class PhongMapper extends TableMapper<Text, IntWritable> { private Text deviceModel; private static final IntWritable one = new IntWritable(1); @Override protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException { if(value==null){ throw new IllegalStateException("values passed to the map is null"); } deviceModel = new Text( value.getValue(Bytes.toBytes("orderInfo"), Bytes.toBytes("device_model"))); context.write(deviceModel,one); } } static class PhoneReducer extends TableReducer<Text,IntWritable, NullWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum +=value.get(); } context.write(NullWritable.get(), new Put(key.getBytes()) .addColumn(Bytes.toBytes("info"),Bytes.toBytes("sale_count"),Bytes.toBytes(sum))); } } }打包上傳到Linux,在HBase中建表並運行
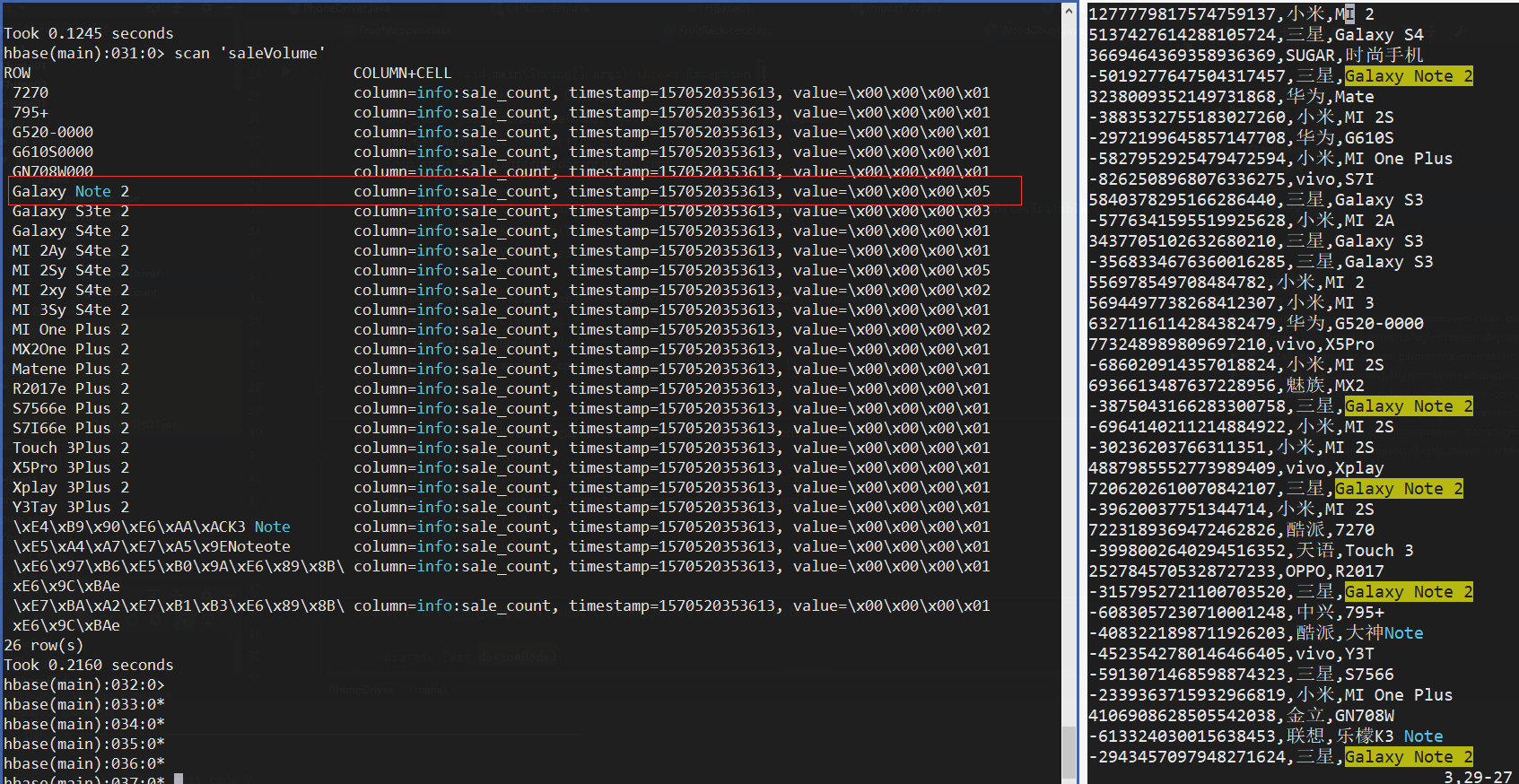
hbase(main):015:0> create 'saleVolume','info' ${HBASE_HOME}../hadoop-2.6.0/bin/hadoop jar learn/part2/HBase01-1.0-SNAPSHOT.jar YouQualifiedClassName確認數據無誤
· 附錄
ImportTSV
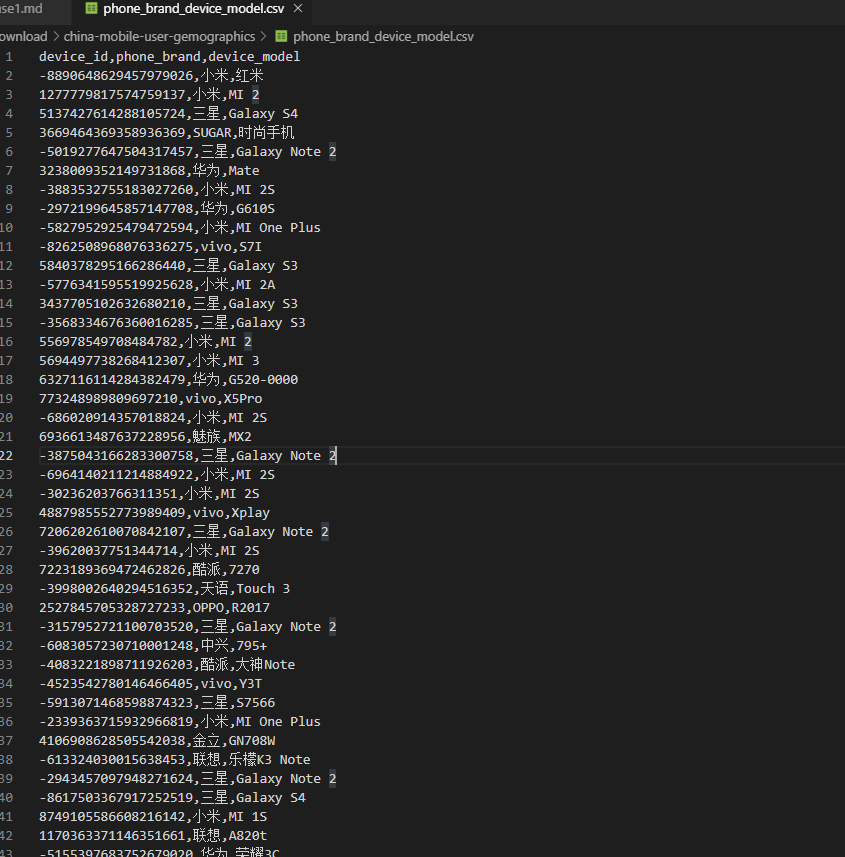
測試導入這麼一張CSV數據文件:
使用HBase-Mapreduce包下的的ImportTsv程式,這個程式的使用方法可以通過看文檔:ImportTsv或者查閱源碼的方式來學習使用,這裡簡單翻譯概述一下其用法:
importTsv是將TSV格式的數據載入到HBASE中的實用工具。它有兩種不同的用法:通過PUT將TSV格式的HDFS數據載入到HBASE,或生成StoreFiles通過completebulkload載入到HBase。
將給定的TSV數據輸入目錄導入指定的表中。必須使用-Dimporttsv.columns指定TSV數據的列名。此選項採用逗號分隔的列名形式,其中每個列名可以是一個簡單的列族,也可以是一個columnfamily:qualifier。特殊的列名HBASE_ROW_KEY用於指定應該使用該列作為每個導入記錄的行鍵。你必須精確地指定一列要成為RowKey,且必須為每個存在的列指定列名。
By default importtsv will load data directly into HBase. To instead generate
HFiles of data to prepare for a bulk data load, pass the option:
-Dimporttsv.bulk.output=/path/for/output
Note: the target table will be created with default column family descriptors if it does not already exist.
Other options that may be specified with -D include:
-Dimporttsv.skip.bad.lines=false – fail if encountering an invalid line
‘-Dimporttsv.separator=|’ – eg separate on pipes instead of tabs
-Dimporttsv.timestamp=currentTimeAsLong – use the specified timestamp for the import
-Dimporttsv.mapper.class=my.Mapper – A user-defined Mapper to use instead of org.apache.hadoop.hbase.mapreduce.TsvImporterMapper
hadoop fs -put phone.csv /mydata #上傳文件到HDFS cd ${HADOOP_HOME} ##以下三行為一條命令 bin/hadoop jar ../hbase-2.1.6/lib/hbase-mapreduce-2.1.6.jar importtsv '-Dimporttsv.separator=,' -Dimporttsv.columns=HBASE_ROW_KEY,orderInfo:phone_brand,orderInfo:device_model phone hdfs://Master:9000/mydata/phone.csv通過源碼可以得知默認的列分隔符是"t",根據情況寫參數,部分默認值:
...... final static String DEFAULT_SEPARATOR = "t"; final static String DEFAULT_ATTRIBUTES_SEPERATOR = "=>"; final static String DEFAULT_MULTIPLE_ATTRIBUTES_SEPERATOR = ","; final static Class DEFAULT_MAPPER = TsvImporterMapper.class; ......執行完成後:
...... Map-Reduce Framework Map input records=39 Map output records=39 Input split bytes=100 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=232 CPU time spent (ms)=2380 Physical memory (bytes) snapshot=132243456 Virtual memory (bytes) snapshot=2129027072 Total committed heap usage (bytes)=22409216 ImportTsv Bad Lines=0 File Input Format Counters Bytes Read=1376 ...... ...... hbase(main):016:0> scan 'phone' ROW COLUMN+CELL -2339363715932966819 column=orderInfo:device_model, timestamp=1570458713990, value=MI One Plus -2339363715932966819 column=orderInfo:phone_brand, timestamp=1570458713990, value=xE5xB0x8FxE7xB1xB3 -2943457097948271624 column=orderInfo:device_model, timestamp=1570458713990, value=Galaxy Note 2 -2943457097948271624 column=orderInfo:phone_brand, timestamp=1570458713990, value=xE4xB8x89xE6x98x9F -2972199645857147708 column=orderInfo:device_model, timestamp=1570458713990, value=G610S -2972199645857147708 column=orderInfo:phone_brand, timestamp=1570458713990, value=xE5x8Dx8ExE4xB8xBA -30236203766311351 column=orderInfo:device_model, timestamp=1570458713990, value=MI 2S -30236203766311351 column=orderInfo:phone_brand, timestamp=1570458713990, value=xE5xB0x8FxE7xB1xB3 -3157952721100703520 column=orderInfo:device_model, timestamp=1570458713990, value=Galaxy Note 2 -3157952721100703520 column=orderInfo:phone_brand, timestamp=1570458713990, value=xE4xB8x89xE6x98x9F -3568334676360016285 column=orderInfo:device_model, timestamp=1570458713990, value=Galaxy S3 ......補充:KeyValue
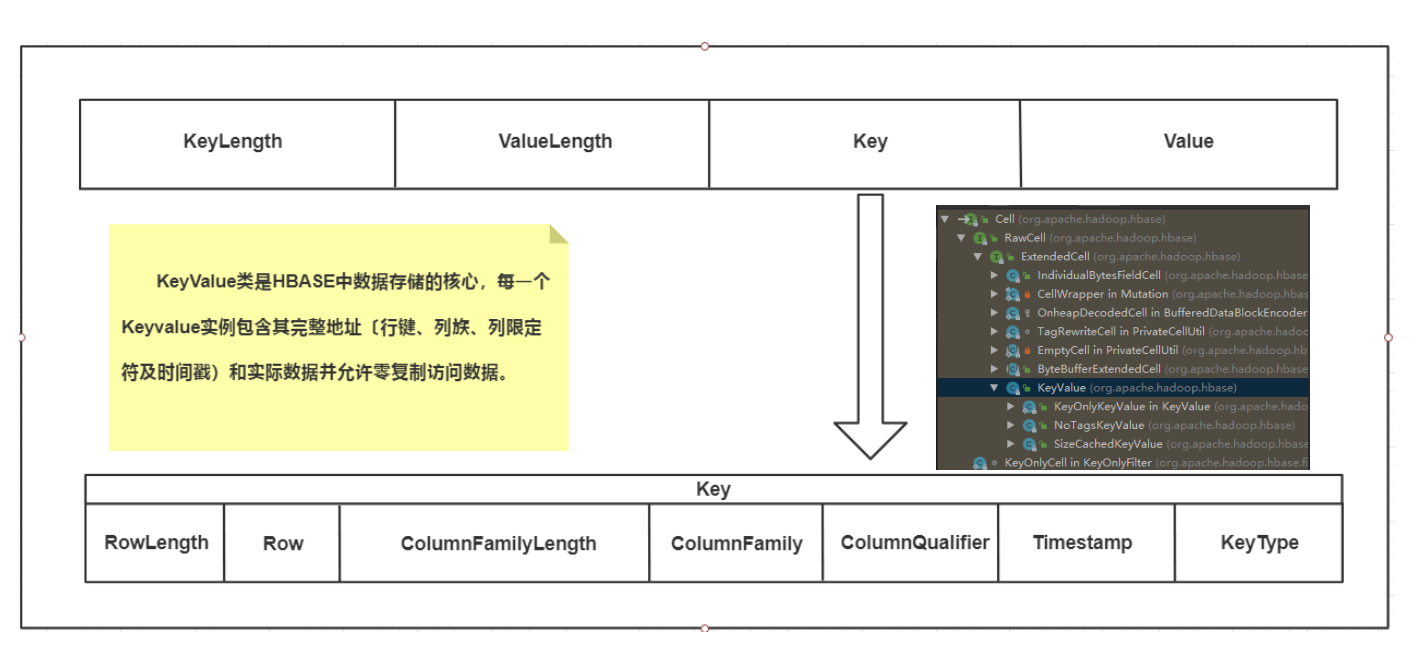
KeyValue類是HBASE中數據存儲的核心,每一個KeyValue實例包含其完整地址〔行鍵、列族、列限定符及時間戳)和實際數據並允許零複製訪問數據。KeyValue封裝一個位元組數組,並在傳遞的數組中提取偏移量和長度,該數組指定從何處開始將內容解釋為KeyValue。位元組數組中的KeyValue格式組成是KeyLength、ValueLength、Key、Value。
該結構以兩個分別表示鍵長度(KeyLengh)和值長度(ValueLengh)的定長數字開始。有了這個資訊,用戶就可以在數據中跳躍,例如,可以忽略鍵直接訪問值。其他情況下,用戶也可以從鍵中獲取必要的資訊。一旦其被轉換成一個KeyValue的Java實例,用戶就能通過對應的getter方法得到更多的細節資訊,
Key進一步分解為:RowLength、Row、ColumnFamilyLength、ColumnFamily、ColumnQualifier、Timestamp、KeyType
· 未完部分
- HBase架構和存儲
- HBase表設計和事務、高級模式
- HBase集群監控和管理
- HBase性能優化
Mark一下,隨緣更新,看書…
