REDIS主從頻繁切換事件排查
目錄
前言
目前生產配置了2台redis一主一從1.193和12.6,和3個哨兵。1.193,3.10,12.6,搭建的redis高可用環境。突然發生了redis頻繁無響應。
現象
2台生產redis突然發生頻繁的主從切換。由於目前redis配置主從切換全量同步先生成rdb數據文件保存到硬碟,然後將rdb文件傳輸到從庫。因此redis目錄下產生了大量的rdb文件
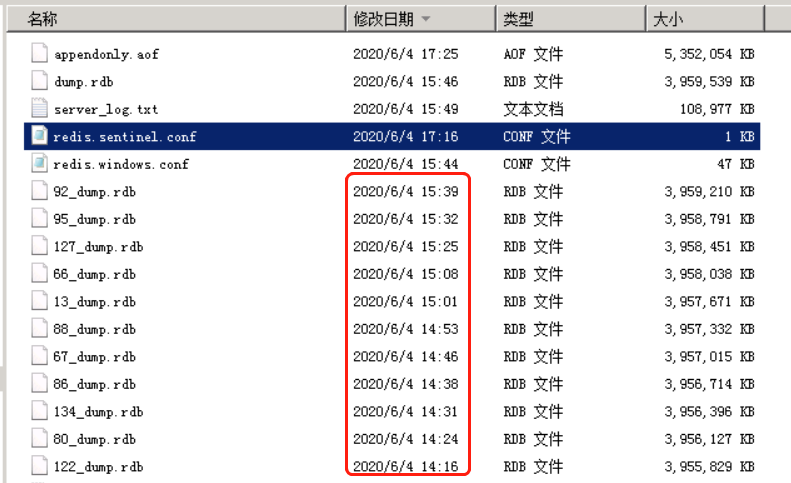
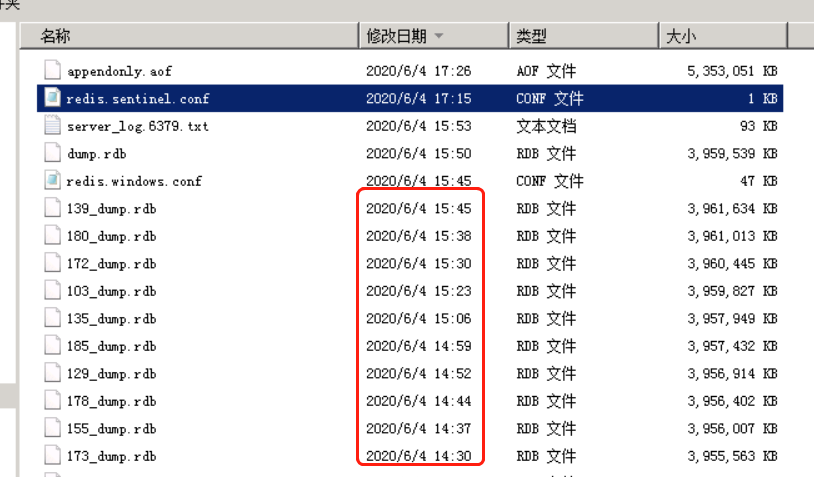
可以看出大約7分鐘左右會產生一個rdb文件。
排查
查看2個redis服務日誌,可以看到兩個redis每隔一段時間就會變為主,且有許多連接丟失的情況,同時存在頻繁主從全量同步。
1.193 redis
...
[3932] 04 Jun 14:18:32.846 * MASTER MODE enabled (user request from 'id=107487221 addr=172.19.12.1:49610 fd=188 name=sentinel-872f1eee-cmd age=71 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=0 qbuf-free=32768 obl=36 oll=0 omem=0 events=r cmd=exec')
[3932] 04 Jun 14:18:32.862 # CONFIG REWRITE executed with success.
[3932] 04 Jun 14:18:44.983 * Slave 172.18.12.6:6380 asks for synchronization
[3932] 04 Jun 14:18:44.983 * Full resync requested by slave 172.18.12.6:6380
[3932] 04 Jun 14:18:44.983 * Starting BGSAVE for SYNC with target: disk
[3932] 04 Jun 14:18:45.061 * Background saving started by pid 140176
[3932] 04 Jun 14:22:42.416 # fork operation complete
[3932] 04 Jun 14:22:44.381 * Background saving terminated with success
[3932] 04 Jun 14:22:49.186 # Connection with slave 172.18.12.6:6380 lost.
[3932] 04 Jun 14:22:59.373 * SLAVE OF 172.18.12.6:6380 enabled (user request from 'id=107487264 addr=172.18.12.6:56951 fd=188 name=sentinel-7a359562-cmd age=10 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=0 qbuf-free=32768 obl=36 oll=0 omem=0 events=r cmd=exec')
[3932] 04 Jun 14:22:59.388 # CONFIG REWRITE executed with success.
[3932] 04 Jun 14:22:59.700 * Connecting to MASTER 172.18.12.6:6380
[3932] 04 Jun 14:22:59.700 * MASTER <-> SLAVE sync started
[3932] 04 Jun 14:22:59.700 * Non blocking connect for SYNC fired the event.
[3932] 04 Jun 14:22:59.700 * Master replied to PING, replication can continue...
[3932] 04 Jun 14:22:59.700 * Partial resynchronization not possible (no cached master)
[3932] 04 Jun 14:22:59.763 * Full resync from master: f391e124ded4a1bbe62f0e1d0214b823943f3461:1
[3932] 04 Jun 14:25:52.642 * MASTER MODE enabled (user request from 'id=107487264 addr=172.18.12.6:56951 fd=188 name=sentinel-7a359562-cmd age=183 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=0 qbuf-free=32768 obl=36 oll=0 omem=0 events=r cmd=exec')
[3932] 04 Jun 14:25:52.658 # CONFIG REWRITE executed with success.
[3932] 04 Jun 14:26:04.077 * Slave 172.18.12.6:6380 asks for synchronization
[3932] 04 Jun 14:26:04.077 * Full resync requested by slave 172.18.12.6:6380
[3932] 04 Jun 14:26:04.077 * Starting BGSAVE for SYNC with target: disk
[3932] 04 Jun 14:26:04.171 * Background saving started by pid 1428
[3932] 04 Jun 14:30:08.342 # fork operation complete
[3932] 04 Jun 14:30:10.277 * Background saving terminated with success
[3932] 04 Jun 14:30:15.659 # Connection with slave 172.18.12.6:6380 lost.
[3932] 04 Jun 14:30:25.705 * SLAVE OF 172.18.12.6:6380 enabled (user request from 'id=107487335 addr=172.18.12.6:57160 fd=161 name=sentinel-7a359562-cmd age=17 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=0 qbuf-free=32768 obl=36 oll=0 omem=0 events=r cmd=exec')
[3932] 04 Jun 14:30:25.721 # CONFIG REWRITE executed with success.
[3932] 04 Jun 14:30:26.064 * Connecting to MASTER 172.18.12.6:6380
[3932] 04 Jun 14:30:26.064 * MASTER <-> SLAVE sync started
...
MASTER MODE enabled被哨兵設置為主CONFIG REWRITE executed with success配置重寫成功Slave 172.18.12.6:6380 asks for synchronization從redis請求主從同步Full resync requested by slave 172.18.12.6:6380全量同步Starting BGSAVE for SYNC with target: disk後台保存到硬碟Background saving started by pid 140176子進程開始保存fork operation complete子執行緒操作完成Background saving terminated with success保存成功Connection with slave 172.18.12.6:6380 lost.連接到從連接丟失SLAVE OF 172.18.12.6:6380 enabled被哨兵設置為從Connecting to MASTER 172.18.12.6:6380連接到主MASTER <-> SLAVE sync started主從同步開始Partial resynchronization not possible (no cached master)無法部分同步Full resync from master: f391e124ded4a1bbe62f0e1d0214b823943f3461:1全量同步
查看哨兵日誌(下面是其中一個哨兵日誌),每個哨兵日誌都顯示頻繁發生重新選舉。
172.17.1.193的哨兵
[132436] 04 Jun 14:07:19.705 # +sdown master master 172.17.1.193 6379
[132436] 04 Jun 14:07:19.939 # +new-epoch 3
[132436] 04 Jun 14:07:19.955 # +vote-for-leader 7a359562268faaf4b588343b75fea8afbd6a2816 3
[132436] 04 Jun 14:07:20.345 # -sdown master master 172.17.1.193 6379
[132436] 04 Jun 14:07:21.234 # +config-update-from sentinel 7a359562268faaf4b588343b75fea8afbd6a2816 172.18.12.6 16380 @ master 172.17.1.193 6379
[132436] 04 Jun 14:07:21.234 # +switch-master master 172.17.1.193 6379 172.18.12.6 6380
[132436] 04 Jun 14:07:21.234 * +slave slave 172.17.1.193:6379 172.17.1.193 6379 @ master 172.18.12.6 6380
[132436] 04 Jun 14:07:31.280 * +convert-to-slave slave 172.17.1.193:6379 172.17.1.193 6379 @ master 172.18.12.6 6380
[132436] 04 Jun 14:10:23.333 # +sdown master master 172.18.12.6 6380
[132436] 04 Jun 14:10:23.442 # +odown master master 172.18.12.6 6380 #quorum 2/2
[132436] 04 Jun 14:10:23.442 # +new-epoch 4
[132436] 04 Jun 14:10:23.442 # +try-failover master master 172.18.12.6 6380
[132436] 04 Jun 14:10:23.442 # +vote-for-leader 1e28fa3c46c51d90d497412d75326034b9e439a0 4
[132436] 04 Jun 14:10:23.458 # 7a359562268faaf4b588343b75fea8afbd6a2816 voted for 7a359562268faaf4b588343b75fea8afbd6a2816 4
[132436] 04 Jun 14:10:23.489 # 872f1eee7d73890b2b4d75a2a0bead3f0a33603e voted for 7a359562268faaf4b588343b75fea8afbd6a2816 4
[132436] 04 Jun 14:10:24.643 # -sdown master master 172.18.12.6 6380
[132436] 04 Jun 14:10:24.643 # -odown master master 172.18.12.6 6380
[132436] 04 Jun 14:10:34.456 # -failover-abort-not-elected master master 172.18.12.6 6380
[132436] 04 Jun 14:12:33.734 # +sdown slave 172.17.1.193:6379 172.17.1.193 6379 @ master 172.18.12.6 6380
[132436] 04 Jun 14:13:46.929 # -sdown slave 172.17.1.193:6379 172.17.1.193 6379 @ master 172.18.12.6 6380
...
+sdown master master主觀下線主redisnew-epoch 3新一輪投票vote-for-leader 7a359562268faaf4b588343b75fea8afbd6a2816 3選舉哨兵領導者+sdown master master客觀下線主redisconfig-update-from sentinel從哨兵更新配置,更新到本地,最終選舉出的主redisswitch-master master切換到主redisslave slave設置從redisconvert-to-slave主節點轉換為從節點failover-abort-not-elected選舉中止
+sdown表示認定主觀下線,-sdown是撤銷主觀下線
另一台哨兵日誌
172.17.3.10的哨兵
[7152] 04 Jun 14:05:34.856 # +new-epoch 3
[7152] 04 Jun 14:05:34.872 # +vote-for-leader 7a359562268faaf4b588343b75fea8afbd6a2816 3
[7152] 04 Jun 14:05:35.106 # +sdown master master 172.17.1.193 6379
[7152] 04 Jun 14:05:35.185 # +odown master master 172.17.1.193 6379 #quorum 3/2
[7152] 04 Jun 14:05:35.185 # Next failover delay: I will not start a failover before Thu Jun 04 14:06:35 2020
[7152] 04 Jun 14:05:35.247 # -sdown master master 172.17.1.193 6379
[7152] 04 Jun 14:05:35.247 # -odown master master 172.17.1.193 6379
[7152] 04 Jun 14:05:36.153 # +config-update-from sentinel 7a359562268faaf4b588343b75fea8afbd6a2816 172.18.12.6 16380 @ master 172.17.1.193 6379
[7152] 04 Jun 14:05:36.153 # +switch-master master 172.17.1.193 6379 172.18.12.6 6380
[7152] 04 Jun 14:05:36.153 * +slave slave 172.17.1.193:6379 172.17.1.193 6379 @ master 172.18.12.6 6380
[7152] 04 Jun 14:08:37.880 # +sdown master master 172.18.12.6 6380
[7152] 04 Jun 14:08:38.380 # +new-epoch 4
[7152] 04 Jun 14:08:38.380 # +vote-for-leader 7a359562268faaf4b588343b75fea8afbd6a2816 4
[7152] 04 Jun 14:08:39.021 # +odown master master 172.18.12.6 6380 #quorum 3/2
[7152] 04 Jun 14:08:39.021 # Next failover delay: I will not start a failover before Thu Jun 04 14:09:39 2020
[7152] 04 Jun 14:08:39.568 # -sdown master master 172.18.12.6 6380
[7152] 04 Jun 14:08:39.568 # -odown master master 172.18.12.6 6380
[7152] 04 Jun 14:10:48.584 # +sdown slave 172.17.1.193:6379 172.17.1.193 6379 @ master 172.18.12.6 6380
[7152] 04 Jun 14:12:01.781 # -sdown slave 172.17.1.193:6379 172.17.1.193 6379 @ master 172.18.12.6 6380
...
Next failover delay 選舉時間間太短,等下一次選舉,避免網路短時間內波動造成頻繁主從切換。該時間間隔是down-after-milliseconds值的10倍
結論
仔細看哨兵redis發現,伺服器1.193的哨兵也會認為1.193的redis主觀下線sdown master master 172.17.1.193 6379,懷疑有可能是redis服務的問題,而不是網路問題。
查看日誌發現有頻繁的fork operation complete 日誌,由於有全量同步和aof同步出現,fork執行緒和子執行緒處理完通知父執行緒後的邏輯處理都會有短暫阻塞。因此在RDB和AOF持久化時造成阻塞(當時的redis數據量達到9G),可能會導致哨兵誤認為節點主觀下線。
主從同步阻塞時,當增量數據超過配置的閾值或配置的時間,則會觸發全量數據同步。
redis主從配置注意點
- 控制Redis實例最大可用記憶體,fork耗時跟記憶體成正比。10GB的redis記憶體大約需要20MB的記憶體頁表,因此記憶體越大fork越耗時,正常情況大約每GB需要消耗20ms左右。可以通過
latest_fork_usec查看最後一次fork時間,單位是微秒。 - 儘可能關閉rdb持久化方式,rdb每次會全量保存文件,保存需要雙倍數據記憶體,主從同步方式可以使用無硬碟模式,儘可能使用aof每秒保存,若是4.X版本的redis,則使用rdb-aof模式,增量數據以aof追加,aof重寫時以rbd數據保存。
- 哨兵主觀下線時間配置
down-after-milliseconds不要配置太短,配置太短很可能造成頻繁發生主從切換。 - 增大主從同步的快取大小
repl-backlog-size,當主從連接斷開重連後,若增量同步數據小於快取大小, 則僅需增量同步即可,無需全量同步。默認1MB - 適當增大主從斷開全量同步時間超過配置的
repl-backlog-ttl值會觸發全量同步,單位時秒。 - 當搭建了集群,若超過半數節點無響應,則整個集群會掛掉。當發生主從同步,持久化時節點可能阻塞,適當調整集群通訊超時時間。
cluster-node-timeout單位是毫秒。

