關於Pulsar與Kafka的一些比較和思考
- 2019 年 10 月 8 日
- 筆記
作者:Sijie Guo 來源:https://streaml.io/blog/pulsar-streaming-queuing
場景描述:Pulsar和Kafka比較中,我將引導您完成我認為重要的幾個領域,並且對於人們選擇強大,高可用性,高性能的流式消息傳遞平台至關重要。消息傳遞模型(Messaging model)是用戶在選擇流式消息傳遞系統時應首先考慮的事情。
關鍵詞:Kafka Pulsar
在本系列的Pulsar和Kafka比較文章中,我將引導您完成我認為重要的幾個領域,並且對於人們選擇強大,高可用性,高性能的流式消息傳遞平台至關重要。消息傳遞模型(Messaging model)是用戶在選擇流式消息傳遞系統時應首先考慮的事情。消息傳遞模型應涵蓋以下3個方面:
- Message consumption(消息消費):如何發送和消費消息
- Message Acknowledgement(消息確認):如何確認消息
- Message Retention(消息保留):消息要保留多久、出發消息刪除的原因以及刪除方式
消息消費
在一個現代的實時流式架構中,消息用例可被分為兩類:隊列和流。
隊列
隊列是無序或共享的消息傳遞,通過隊列進行消息傳遞,多個消費者可以被創建以從單個點對點消息傳遞通道接收消息。當通道傳遞消息時,任何消費者都可能接收消息。消息傳遞系統的實現決定哪個消費者實際接收的消息。隊列用例通常與無狀態的應用程式一起使用,無狀態應用程式不關心排序,但它們需要能夠進行消息確認(acknowledge)或消息刪除(remove)、以及儘可能擴展消息消費並行性的能力。典型的基於排隊的消息傳遞系統包括RabbitMQ和RocketMQ。
流
相比之下、流是嚴格排序或獨佔的消息傳遞。使用流式消息傳遞,始終只有一個消費者使用消息傳遞通道。消費者按照編寫它們的確切順序接收從通道發送的消息。流式用例通常與有狀態應用程式相關聯。有狀態的應用程式關心順序及其狀態。消息的排序決定了有狀態應用程式的狀態。順序將影響應用程式在發生無序消耗時需要應用的任何處理邏輯的正確性。
在面向微服務或事件驅動的體系結構中,流和隊列都是必需的。
Pulsar Model
Apache Pulsar將隊列和流統一為消息傳遞模型:producer-topic-subscription-consumer。主題(分區)是用於發送消息的命名通道。每個主題分區都由存儲在Apache BookKeeper中的分散式日誌支援。發布者發布的每條消息僅存儲在主題分區上一次,複製以存儲在多個bookies(BookKeeper伺服器)上,並且可以根據消費者的需要多次消費使用。主題是消費真相的來源,儘管消息僅在主題分區上存儲一次,但是可以有不同的方式來消費這些消息。消費者被組合在一起以消費消息。每組消費者都是對主題的訂閱,每個消費者群體都可以擁有自己的消費方式 – 獨佔,共享或故障轉移 – 這些消費群體可能會有所不同。這在一個模型和API中結合了隊列和流,它的設計和實現目標是不影響性能和引入成本開銷,同時還為用戶提供了很多靈活性,以最適合當前用例的方式使用消息。
獨佔訂閱(流):顧名思義,在任何給定時間內,訂閱(消費者組)中只有一個消費者消費主題分區。下面的圖1說明了獨佔訂閱的示例。有一個有訂閱A的活動消費者A-0消息m0到m4按順序傳送並由A-0消費。如果另一個消費者A-1想要附加到訂閱A,則不允許這樣做。
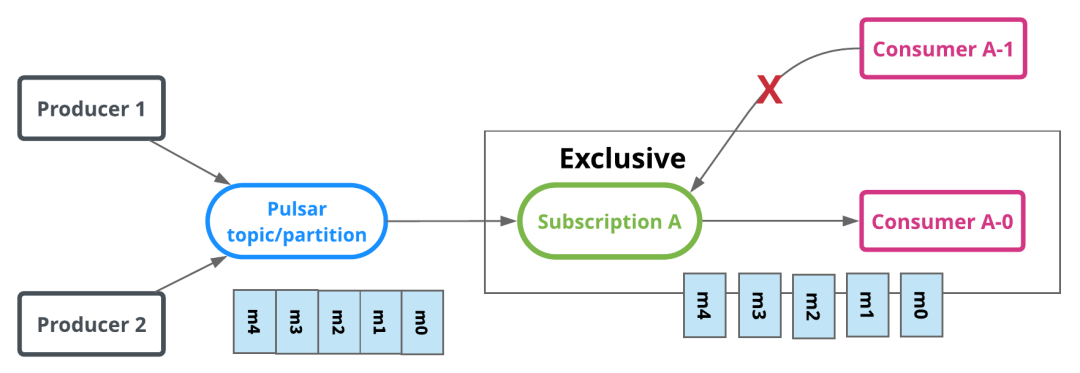
獨佔訂閱
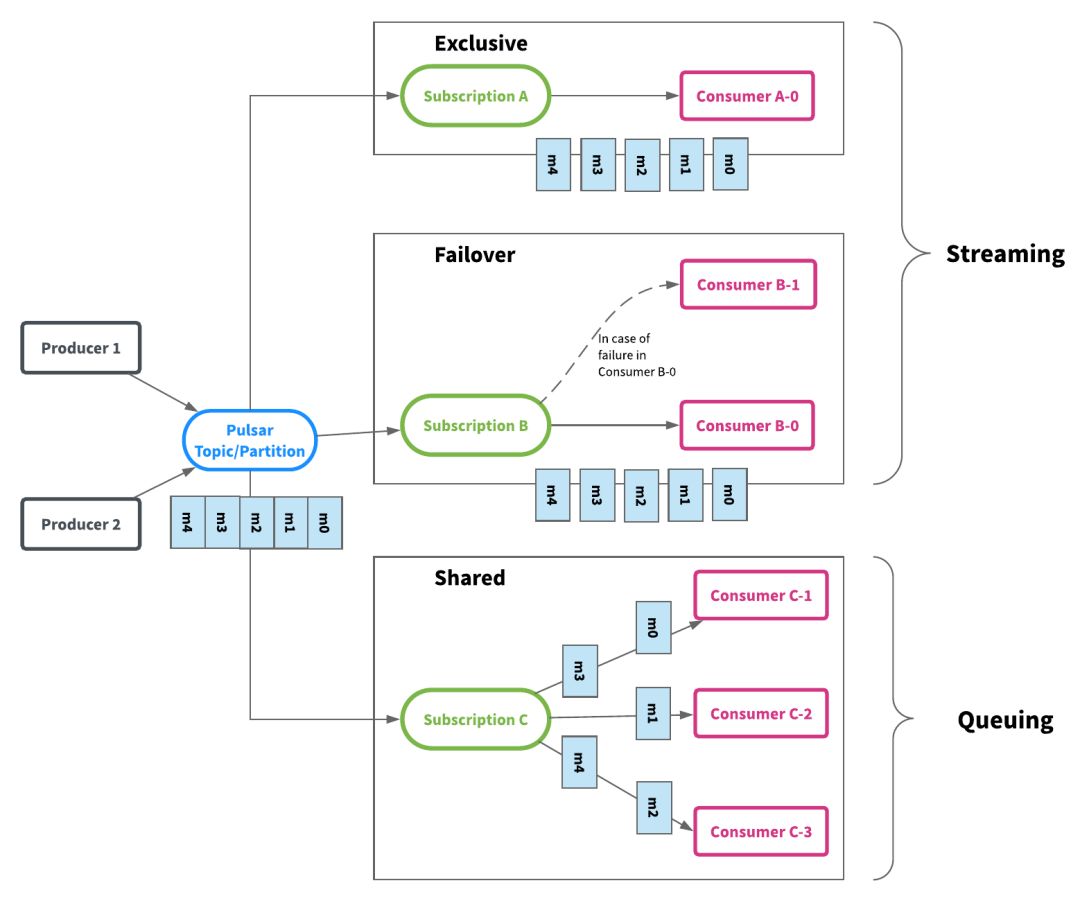
故障轉移訂閱(Failover sub streaming):使用故障轉移訂閱,多個使用者可以附加到同一訂閱。但是,對於給定的主題分區,將選擇一個使用者作為該主題分區的主使用者,其他消費者將被指定為故障轉移消費者,當主消費者斷開連接時,分區將被重新分配給其中一個故障轉移消費者,而新分配的消費者將成為新的主消費者。發生這種情況時,所有未確認的消息都將傳遞給新的主消費者,這類似於Apache Kafka中的使用者分區重新平衡。圖2顯示了故障轉移訂閱,消費者B-0和B-1通過訂閱B訂閱消費消息.B-0是主消費者並接收所有消息,B-1是故障轉移消費者,如果消費者B-0出現故障,將接管消費。

故障轉移訂閱
共享訂閱(隊列):使用共享訂閱,可以將所需數量的消費者附加到同一訂閱。消息以多個消費者的循環嘗試分發形式傳遞,並且任何給定的消息僅傳遞給一個消費者。當消費者斷開連接時,所有傳遞給它並且未被確認的消息將被重新安排,以便發送給該訂閱上剩餘的剩餘消費者。圖3說明了共享訂閱。消費者C-1,C-2和C-3都在同一主題分區上消費消息。每個消費者接收大約1/3的消息。如果您想提高消費率,您可以在不增加分區數量的情況下為更多的消費者提供相同的訂閱(儘可能多的消費者)。

共享訂閱
獨佔和故障轉移訂閱僅允許每個訂閱每個主題分區僅有一個消費者。它們按分區順序使用消息。它們最適用於需要嚴格排序的流用例。另一方面,共享訂閱允許每個主題分區有多個消費者,同一訂閱中的每個消費者僅接收發布到主題分區的一部分消息。共享訂閱最適用於不需要排序的並且可以擴展超出分區數量的使用者數量的隊列用例。
Pulsar中的subscription(訂閱)實際上與Apache Kafka中的消費者群體相同。創建訂閱具有高度可擴展性且非常低廉的。可以根據需要創建任意數量的訂閱,對同一主題的不同訂閱不必具有相同的訂閱類型。這意味著可以在同一主題上有10個消費者的故障轉移訂閱或有20個消費者的共享訂閱。如果共享訂閱處理事件的速度很慢,則可以在不更改分區數的情況下向共享訂閱添加更多消費者。圖4描繪了一個包含3個訂閱A,B和C的主題,並說明了消息如何從生產者流向消費者。
除了統一消息傳遞API之外,由於Pulsar主題分區實際上是存儲在Apache BookKeeper中的分散式日誌,它還提供了一個讀取器(reader) API(類似於消費者(consumer) API但沒有游標管理),以便用戶完全控制如何使用消息本身。
消息確認(Message Ackmowledgment)
當使用跨機器分布的消息傳遞系統時,可能會發生故障。在消費者從消息傳遞系統中的主題消費消息的情況下,消費消息的消費者和服務於主題分區的消息代理都可能失敗。當發生這樣的故障時,能夠從消費者停止的地方恢復消費,這樣既不會錯過消息,也不必處理已經確認的消息。在Apache Kafka中,恢復點通常稱為偏移,更新恢復點的過程稱為消息確認或提交偏移。在Apache Pulsar中,游標(cursors)用於跟蹤每個訂閱(subscription)的消息確認(message acknowledgment)。每當消費者在主題分區上確認消息時,游標都會更新,更新游標可確保消費者不會再次收到消息,但是游標並不像Apache Kafka那樣簡單。Apache Pulsar有兩種方法可以確認消息,個體確認ack或累積確認消息。通過累積確認,消費者只需要確認它收到的最後一條消息,主題分區中的所有消息(包括)提供消息ID將被標記為已確認,並且不會再次傳遞給消費者,累積確認與Apache Kafka中的偏移更新實際上相同。Apache Pulsar的區別特徵是能夠個體單獨進行ack,也就是選擇性acking。消費者可以單體確認消息。Acked消息將不會被重新傳遞。圖5說明了ack個體和ack累積之間的差異(灰色框中的消息被確認並且不會被重新傳遞)。在圖的頂部,它顯示了ack累積的一個例子,M12之前的消息被標記為acked。在圖的底部,它顯示了單獨進行acking的示例。僅確認消息M7和M12 – 在消費者失敗的情況下,除了M7和M12之外,將重新傳送所有消息。

獨佔(exclusive)或故障轉移(failover)訂閱的消費者能夠單個或累積地發送消息(ack message);而共享訂閱中的消費者只允許單獨發送消息(ack messages)。單獨確認消息的能力為處理消費者故障提供了更好的體驗。對於某些應用來說,處理那些已經確認過的消息可能是非常耗時的,防止重新傳送已經確認的消息是非常重要。
Message Retention
與傳統的消息傳遞系統相比,消息在被確認後不會立即被刪除。Pulsar代理在接收消息確認時僅更新cursor,只有在所有訂閱已經使用它之後才能刪除消息(消息在其sorcor中標記為已確認)。Pulsar還允許將消息保留更長時間,即使所有訂閱已經消費了它們,這是通過配置消息保留期來完成的。圖6說明了如何在具有2個訂閱的主題分區中保留消息,訂閱A已經消費了M6之前的所有消息,訂閱B已經消費M10之前的所有消息。這意味著M6之前的所有消息(灰色框中)都可以安全刪除,訂閱A仍未使用M6和M9之間的消息,無法刪除它們。如果主題分區配置了消息保留期,則即使A和B已經消耗它們,消息M0到M5也將在配置的時間段內保持不變。

Time-to-Live(TTL)
除了消息保留(message retention),Pulsar還支援消息生存時間(TTL)。如果消息在配置的TTL時間段內沒有被消費者使用,則消息將自動標記為已確認。消息保留和消息TTL之間的區別在於消息保留適用於標記為已確認並將其設置為已刪除的消息,保留是對主題應用的時間限制,而TTL適用於未使用的消息。因此,TTL是訂閱消費的時間限制。上面的圖6說明了Pulsar中的TTL。例如,如果訂閱B沒有活動消費者,則在配置的TTL時間段過後,消息M10將自動標記為已確認,即使沒有消費者實際讀取該消息。
Kafka與Pulsar異同
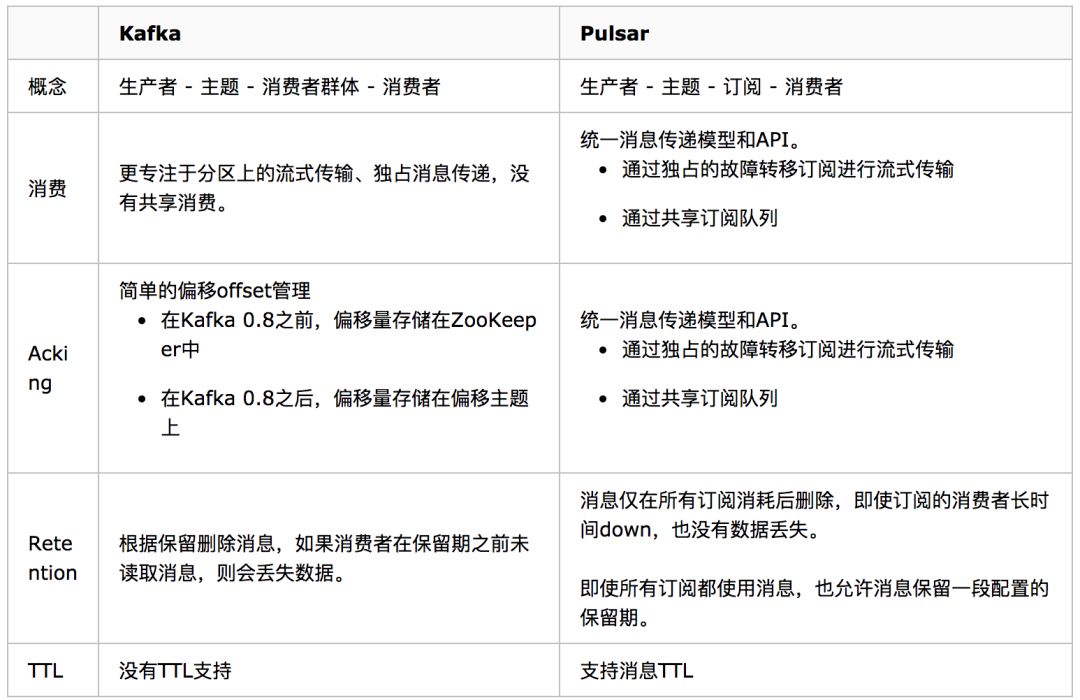
Apache Pulsar將高性能流式處理(Apache Kafka所追求的)和靈活的傳統隊列(RabbitMQ所追求的)結合到一個統一的消息傳遞模型和API中,Pulsar使用統一的API提供一個流式處理和隊列系統,具有相同的高性能。
