我眼中的華為公有雲AI平台–ModelArts
前言
AWS Sagemaker has been a great deal for most data scientists who would want to accomplish a truly end-to-end ML solution——by John Moolayil
這是數據科學在線網站「towards data science」一篇文章中的一段話。時常有人問我,「為什麼會有ModelArts存在」,這是一個很有價值的問題,結合國外專家對AWS Sagemaker的評價,我決定寫一篇文章,講講我對華為雲ModelArts全流程AI平台的理解。
ModelArts平台的初心
為什麼不能僅僅使用開源軟體構建AI訓練和推理過程?答案是,可以的,但是不能用於大規模生產環境下,至於為什麼我這麼說,讓我們先談談人工智慧產品。我認為,如果要將人工智慧技術集成到各個行業,需要有一套完整的軟硬體平台支撐。
人工智慧平台大致的分層架構如下圖所示:
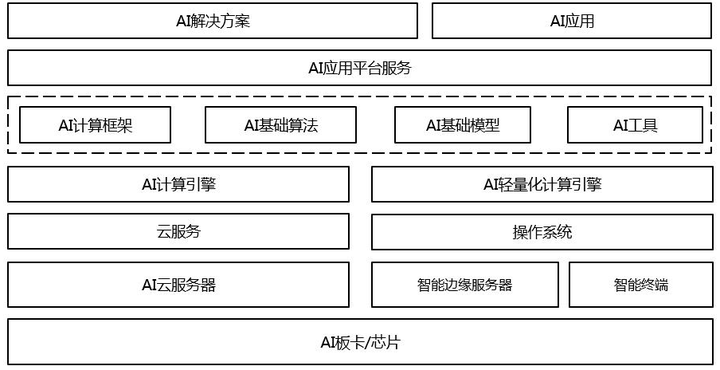
完整的人工智慧平台,水平方向上支援端、邊、雲三種場景,每個場景均涵蓋了從底層硬體至上層應用。
最底層是晶片層(例如華為的昇騰晶片、Google的TPU晶片、NVIDIA的GPU卡),再往上是適用於端邊雲的硬體系統(包括伺服器和終端設備等)及其基礎軟體環境(如雲服務、作業系統)。
位於這三層之上的是AI計算引擎層,AI計算引擎可以藉助計算資源,完成AI模型的訓練和推理。當模型訓練後之後,需要部署進行推理,推理模組由於計算資源消耗較少,更容易覆蓋端、邊、雲三個場景。
在AI計算引擎之上,人工智慧平台提供了常用的AI框架、演算法、模型及其其他工具方便用戶進行AI業務的開展。常用的AI工具包括但不限於:數據的格式轉換、預處理、模型保存、模型評估、模型壓縮等等。AI框架、演算法、模型和工具是解決常用AI問題時必備的組件。這些可以大大降低AI應用開發的門檻,簡化開發AI應用所需的程式碼量。在此之上,AI應用平台服務提供AI應用的開發和部署服務,支援一次開發、任意部署(含雲、邊、端)。
再往上是AI應用平台服務,它提供端到端的AI應用開發和部署服務。
最頂層是基於AI應用平台服務開發出的AI解決方案和AI應用,可用於解決業務問題。
自下向上的每一層,我們可以看出,AI平台需要提供從硬體到軟體、演算法工具再到雲服務的全棧優化,才能夠真正提升AI應用開發的效率,進而使能行業AI。
ModelArts平台的初心,除了降低以上所說的各層的複雜性之外,更是為了便於用戶創造AI應用。為什麼AI應用有別於傳統軟體應用?因為目前常用的人工智慧演算法,大多基於概率統計,所以具有一定的不確定性和概率性。例如在影像分類場景下,任何AI模型都不可能實現100%的分類準確率。當AI模型預測一張影像類別時必須伴隨著一定的概率值,這個概率值不可能達到100%,只能無限接近。而傳統AI軟體基本都在執行確定性的操作,不會出現概率性。這就是AI應用和傳統軟體應用最大的區別。
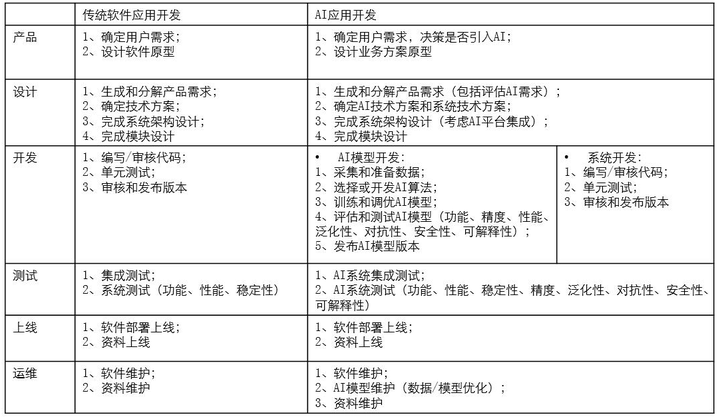
如下表所示,從產品設計、方案設計、開發、測試、上線再到運維的全生命周期的每個階段中,傳統軟體應用開發和AI應用開發都有很大的區別。
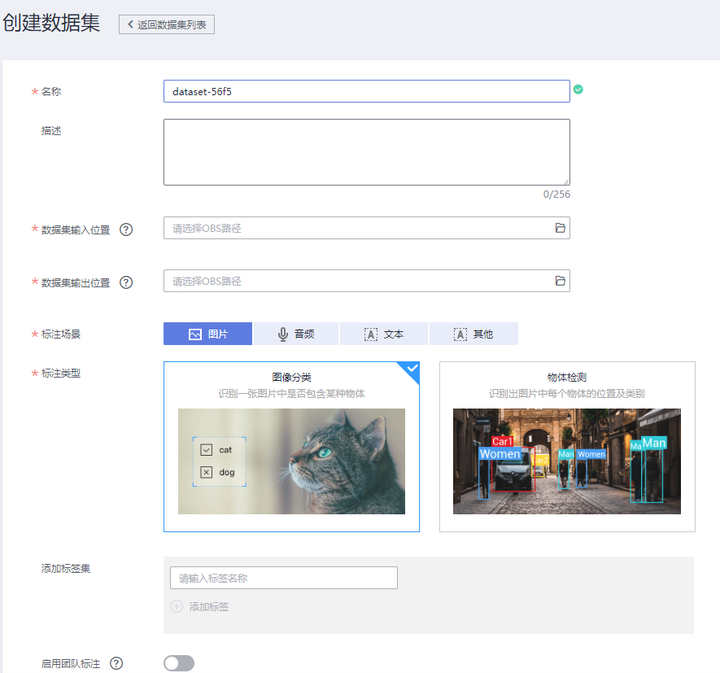
初識ModelArts
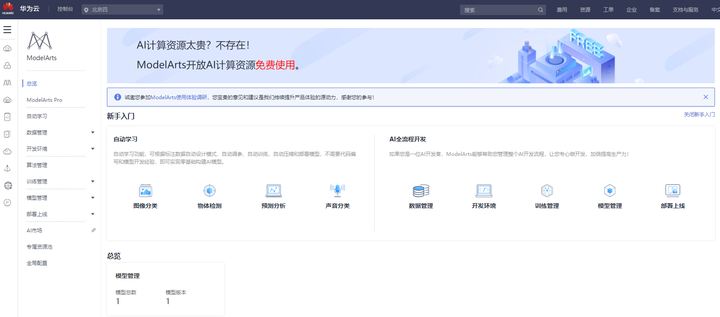
這是ModelArts的首頁,有人會說為什麼這麼雜亂,很多功能都被平鋪在了首頁上?如果你換位思考,ModelArts是面向2C用戶的AI平台,從完全不懂編程的小白,到精通AI開發全流程的工程師,我們要讓更多人享受到AI帶來的紅利,我們自然需要覆蓋更廣的用戶技能範圍,所以,你看到了自動學習、AI全流程開發,這兩個不同方向並排在了首頁。普惠,瞭然於心。
進一步剖析ModelArts
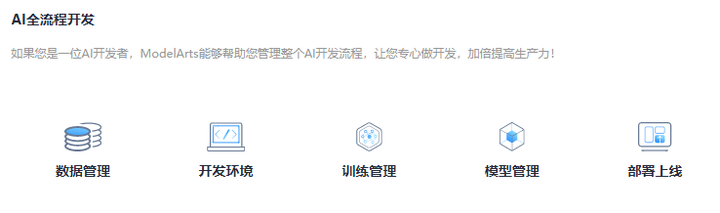
了解一下AI全流程開發,如下圖所示:
對於數據管理的理解
AI應用開發的全流程是對數據源不斷地進行處理,並得到最終期望結果的過程。這個過程的每個步驟,都會基於一定的處理邏輯對輸入數據進行處理,並得到輸出數據,同時也可能會產生一個或多個模型,以及一些可能的元資訊文件(如配置項文件等)。
在處理的過程中,可能會接受外部輸入(例如用戶的輸入、配置、其他外部環境的輸入等)。每個處理步驟的處理邏輯可以是平台內置的處理邏輯,也可以是開發者自定義的處理邏輯(例如開發者利用平台的開發調試環境開發的一套程式碼)。當數據源經過一系列處理之後,我們會得到最終的結果數據(例如影像識別精度等報表數據)。在這一系列的處理步驟中,可能會出現反覆,例如當我們對某個處理步驟輸出的數據不滿意時,可以重新修正輸入數據或者處理邏輯,重新進行處理,也可以跳到其他處理步驟進行進一步處理。
當前,大部分人工智慧是圍繞數據為中心進行開發,其中涉及到的演算法往往以概率統計為基礎,這些演算法往往對其輸入數據有非常強的先驗假設(例如獨立同分布等),我們需要將原始數據轉換為滿足這些假設的數據才能用來訓練模型。
學術界對於一些常見的我們通常專註於演算法的創新設計和開發,而較少地去做數據的採集、清洗、處理等工作。工業界情況恰好相反,我們需要在數據方面做非常多的工作,例如當我們需要採用機器學習分類演算法解決一個具體業務問題時,數據來源可能是多方面的,可能是在本地存儲的某些文件,也可能是業務系統的資料庫,也可能是一些紙質文檔。
因此,我們需要統一的數據源接入層完成數據採集。在這些數據採集過程中,可能還會涉及到模型的訓練和推理。例如,可以調用一個現有的OCR模型用來識別紙質文檔上的關鍵數據,用於電子化歸檔並做進一步處理。除了數據採集之外,我們還需要進行一系列的數據預處理(例如脫敏、去燥、校驗、條件篩選等等)。由於目前人工智慧演算法大部分都是基於監督學習的方法,所以數據標註十分必要。另外,實際的數據經常會面臨很多問題,比如數據品質較差、數據冗餘性較多、數據規律發現難等。因此數據需要額外的調優工作。數據經過一系列採集、處理、標註、調優之後還需要進行半自動、自動化審核驗證。例如在經過標註之後,我們需要能夠及時評估標註品質。最後,為了方便管理數據,我們需要數據管理來實現數據的存儲對接、數據許可權控制、數據版本控制、數據元資訊管理、數據集切分等。
數據獲取:數據源接入模組能夠保證ModelArts方便地讀取各類數據,例如存儲在資料庫、本地文件系統、對象存儲系統等上的離線數據,也可以是來自於實時流系統的數據流、消息等。另外,為了應對數據獲取難的問題,ModelArts服務提供了數據檢索和數據擴增的能力。
數據預處理:提供一系列的預處理演算法和工具包,例如針對於非結構化數據的格式合法性校驗、數據脫敏,以及針對於結構化(表格類)數據的特徵清洗(異常樣本去除、取樣等,還有一些針對單個特徵的缺失值補充、歸一化、統計變換、離散化等)。
數據標註:針對於非結構化數據(例如影像、影片、文本、音頻等)通常,提供一系列的智慧化標註能力和團隊標註能力。
數據調優:提供數據生成、數據遷移、數據選擇、特徵選擇的能力,以及數據特徵分析、標籤分析、數據可視化的能力。
數據驗證和平台:提供數據審核、標註審核的能力,使處理後的數據滿足可信要求。
數據集管理:提供數據集存儲管理(對接多類存儲系統,如對象存儲系統、本地文件系統等)、數據集版本管理、數據元資訊管理、數據集切分和生成。
對於開發環境的理解
在AI研究探索場景中,Jupyter 作為一個特殊的存在迅速成長為AI探索類場景開發的首選,能夠在其各個階段滿足開發者訴求並覆蓋這些關鍵點,以及支援在瀏覽器中使用的特點。
Jupyter 起始於 IPython 項目,IPython 最初是專註於 Python 的項目,但隨著項目發展壯大,已經不僅僅局限於 Python 這一種程式語言了。按照Jupyter創始人的想法,最初的目標是做一個能直接支援Julia(Ju),Python(Py)以及R三種科學運算語言的互動式計算工具平台,所以將他命名為Ju-Py-te-R,發展到現在Jupyter已經成為一個幾乎支援所有語言,能夠把程式碼、計算輸出、解釋文檔,多媒體資源整合在一起的多功能科學運算平台。
這裡需要提到的另外一個概念就是「文學編程」,文學編程是一種由Donald Knuth提出的編程範式。這種範式提供了用自然語言來解釋程式邏輯的機會。簡單來說,文學編程的讀者不是機器,而是人。 從寫出讓機器讀懂的程式碼,過渡到向人們解說如何讓機器實現我們的想法,其中除了程式碼,更多的是敘述性的文字、圖表等內容。 文學編程中間穿插著宏片段和傳統的源程式碼,從中可以生成可編譯的源程式碼。
作為第一個貫穿整個科學計算研究的生命周期工具平台,可以將可以分解為,如果我們將科學計算研究全生命周期分解為,個人探索,協作與分享,生產化運行環境,發表與教學,Notebook都可以在這些階段中滿足科研工作的需求。

Jupyter有沒有缺點?有的。如果你追求的是產品化程式碼開發,例如程式碼格式、依賴管理、產品打包、單元測試等等功能在IDE中是沒有很好的支援,當前有一些插件可以做,但是相比重型IDE,功能還是比較弱。此外,Jupyter定義為研究類調試環境,一方面對於分散式的任務當前推薦都是通過單機多進程的方式進行模擬,真實到有多節點拓撲資訊的部分在Jupyter中不容易實現,另外一方面,Jupyter的架構並不適合跑非常重量級的作業。對於真實軟體產品開發的訴求,還是需要在IDE中進行工程化程式碼開發,並配搭測試邏輯,將任務部署在集群中進行運行。
所以,我們還是需要繼續使用pyCharm開發程式,但是如何讓本地的pyCharm與ModelArts結合在一起呢?放心,我們有pyCharm的ModelArts插件。
我們實際上使用一個PyCharm ToolKit工具來幫助建立從本地pyCharm IDE到ModelArts的連接通道,本案例我使用MXNet實現手寫數字影像識別應用的示例,在本地快速完成程式碼編寫,發布到ModelArts公有雲完成模型的訓練和模型生成。
安裝toolkit前需要先安裝2019.2版本(目前toolkit僅適配該版本)的pycharm,下載地址是://developer.huaweicloud.com/tools。
需要注意,如果已經安裝了高版本的pyCharm,需要首先卸載(自動)已安裝的pyCharm:
下載一個工具Pycharm-ToolKit-PC-2019.2-HEC-1.3.0.zip,連接本地IDE與雲之間的鏈路:
//www.jetbrains.com/pycharm/download/other.html
解壓後看到一堆jar文件,
接著回到pyCharm IDE,打開Settings:
找到Plugins,選擇一個插件:
點擊RestartIDE:
重啟後看到如下介面:
然後我們需要去ModelArts網站申明秘鑰:
申請秘鑰:
簡訊驗證碼註冊成功後,請務必把csv文件保存到本機。
回到pyCharm IDE:
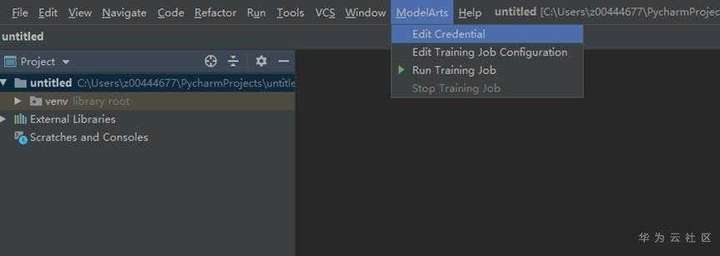
注意,如果填寫秘鑰鍵值對成功後,Edit Credential應該是要打鉤的,如果沒有,請查看網路連接是否存在問題,例如不允許連接外網,或是對訪問外網有限制。
注意,需要你重新點擊edit credential按鈕,退出後就能看到打鉤了。
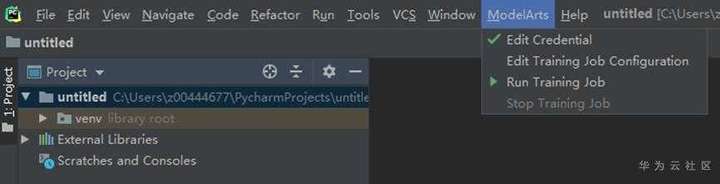
這樣我們就完成了pyCharm IDE與ModelArts的對接工作,進入下一步,實際訓練一個模型。
登錄華為雲上傳OBS:
創建兩個文件夾,一個用於存放數據集,一個用於存放訓練生成的日誌(需要傳回到pyCharm IDE並顯示):
接著在pyCharm打開工程,點擊「Run Training Job」:
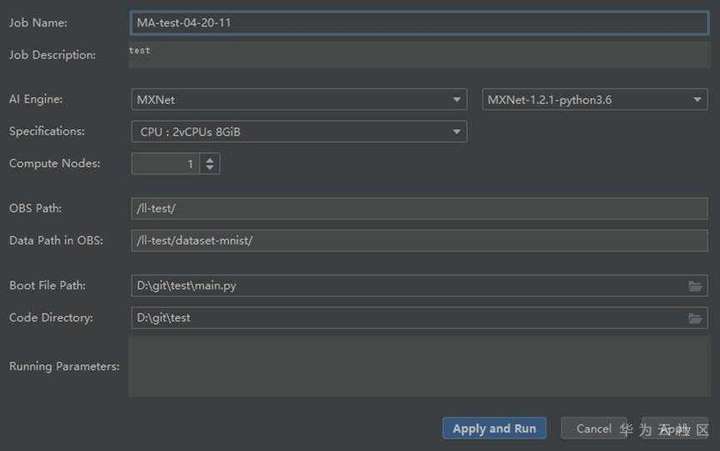
填寫參數,可以參考ModelArts訓練模型時填寫的參數:
訓練完成後,訓練模型保存在OBS中 /工程名/output/V0006/。
自動學習
在典型的機器學習應用場景中,開發者還必須選擇合適的數據預處理工具,特徵提取和特徵選擇方法,從而使原始數據適合機器學習的輸入。 在經過這些預處理步驟之後,開發者通常需要根據經驗選擇恰當的模型演算法,以滿足當前的場景需求。同時在做模型訓練的時候,通常需要做大量的超參數優化,以獲得比較優異的的機器學習模型的預測性能。
比如說深度學習在語音識別,影像識別等領域已經取得了令人矚目的成就。AlexNet在2012年在ImageNet挑戰中打敗了所有其他傳統模型之後,越來越多更加複雜的網路結構被提出來了,網路的層數越來越深,目前的網路已經從最初AlexNet的5個卷積層,增長到目前的上百層,其中涉及到的參數也超過了1億個。而這些參數都是基於研究人員不斷的試錯以及調參經驗所確定的。而這些通過人工調參得到的模型通常只能針對某一類問題(比如說影像分類)有突出的性能,在遇到新的需要AI建模的問題的時候,通常需要重新構建AI模型,所以在構建AI模型的時候,研究人員需要花費大量的時間和計算資源。
為了降低模型構建的成本,提升AI建模的效率,研究人員提出了自動機器學習(AutoML)的概念,針對特定的機器學習任務,AutoML能夠端到端的完成數據處理,特徵提取,模型選擇以及模型評估。
談一個ModelArts的自動學習案例-心臟病預測。
我們已經了解了機器學習預測模型的實現原理,本文我們並不會自己動手從頭實現,因為當前預測演算法已經非常成熟,我們完全可以利用一些公有雲大廠提供的自動學習技術,實現模型的快速訓練及預測。本案例我們採用的是華為雲的公有雲AI平台ModelArts,數據來源Kaggle網站。
Kaggle是一家在線AI競賽網站,開源提供了針對各個行業的脫敏數據,用於支援學生訓練對應的AI模型。
首先需要下載開源數據集,原始數據(已開源的脫敏數據)下載地址如下:
//www.kaggle.com/johnsmith88/heart-disease-dataset
打開csv文件,你可以看到如下圖所示:
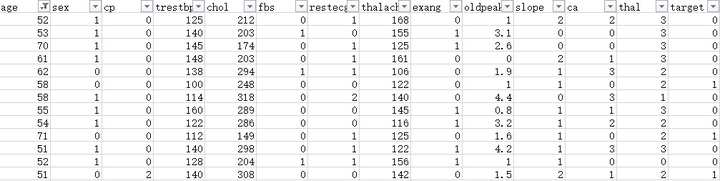
上圖中的數據集截圖中包括了14個欄位,對這14個欄位的含義做逐一解釋:
- Age:年齡;
- Sex:性別;
- chest pain type (4 values):胸部疼痛類型;
- resting blood pressure:靜息血壓;
- serum cholestoral in mg/dl:血漿膽固醇水平;
- fasting blood sugar > 120 mg/dl:空腹血糖>120 mg/dl;
- resting electrocardiographic results (values 0,1,2):靜息心電圖結果;
- maximum heart rate achieved:最大心率;
- exercise induced angina:與運動相關的心絞痛;
- oldpeak = ST depression induced by exercise relative to rest:與靜息時比較,運動導致的ST段下移;
- the slope of the peak exercise ST segment:心電圖ST segment的傾斜度;
- number of major vessels (0-3) colored by flourosopy:透視檢查看到的血管數;
- thal: 1 = normal; 2 = fixed defect; 3 = reversable defect:檢測方式;
- target:0和1。
根據醫學雜誌上查到的資訊,一般認為,膽固醇介於200-300之間發病率高;心率異常易導致發病,最大心率在150到175間發病率高;最大心跳在150到175間發病率高;血壓在120到140時發病率高。
下載數據之後,我們接下來做的是上傳數據到華為雲。華為雲提供了OBS桶用於存放文件,本文所涉及的csv文件可以作為對象上傳。上傳文件截圖如下圖所示:
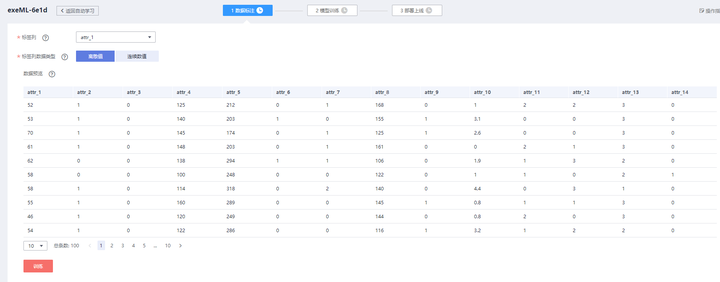
注意,上傳文件前請刪除表頭欄位名,否則訓練過程中會報錯。此外,數據集不用自己劃分為訓練集和測試集,AI平台會自動按照7:3的比例進行切分。數據預覽如下圖所示:
接下來就可以進行模型訓練了。首先登陸網站//console.huaweicloud.com/modelarts/,首頁如下圖所示:
有沒有看到螢幕中間的「自動學習」按鈕?後續我會寫一篇文章系統性介紹什麼是自動學習,這裡先略過。我們本案例要做的是預測,也就是「預測分析」按鈕,點擊該按鈕。
點擊「創建項目」按鈕:
接著選定數據集後,你會看到如下圖所示的步驟,分為數據標註、魔性訓練,以及部署上線。
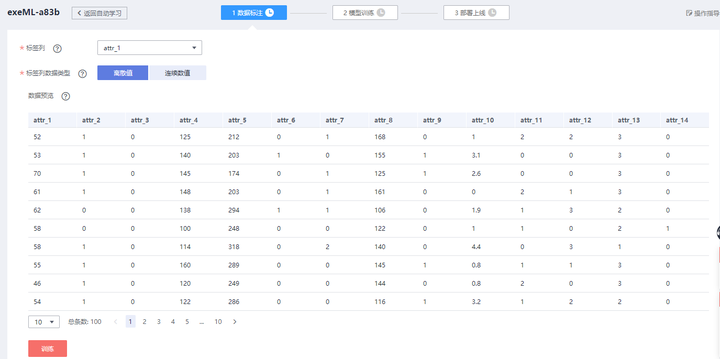
點擊訓練按鈕,開始模型訓練,由於是機器學習演算法,只需要採用CPU資源即可。
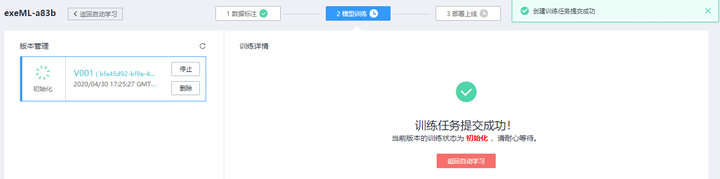
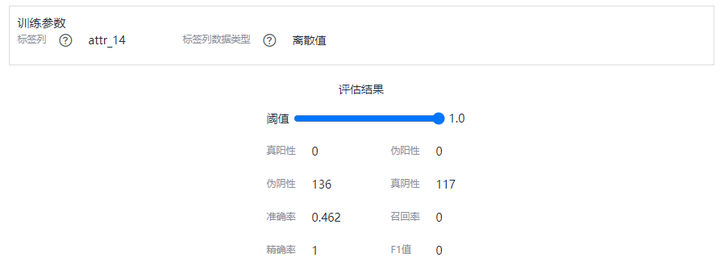
訓練任務完成後,你可以點擊進去查看模型的準確度預測(默認7:3比例已經預留了測試集,可以用來生成測試報告),如下圖所示:
AI市場
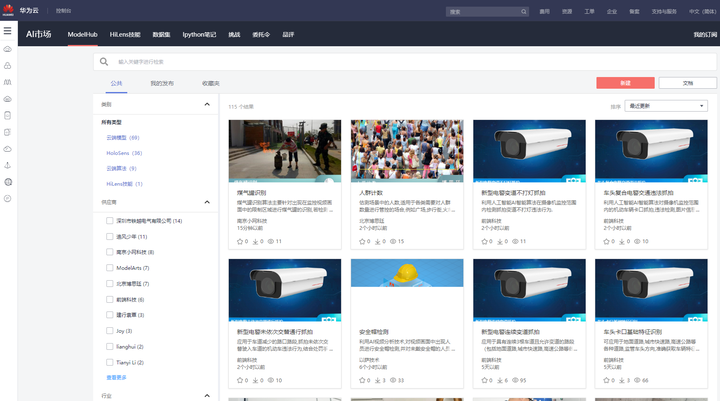
AI市場是一個面向一站式AI開發平台,它提供AI數字資產(包括AI開發工作流和開箱即用的數據集、演算法、模型等)的託管式存儲倉庫。AI市場提供細粒度許可權控制的共享,使得個人或企業開發者,能夠以公開、私密的方式託管AI數字資產,從而促進開發人員、數據科學家和機器學習工程師使用相應數字資產進行協同工作。隨著AI市場測試版的不斷改進,後續將支援更多的用法和內容類型,從而進一步簡化 AI 的學習、實驗、開發和在生產環境中的部署與迭代。
AI市場售賣的由第三方發布的人工智慧領域相關AI數字資產本質上屬於軟體服務,可分為演算法類和模型類兩種形態。演算法類軟體目前僅包含雲端演算法(Cloud Algorithm)。模型類的軟體進一步根據不同的支援平台,又細分為雲端模型(Cloud Model)、慧眼技能(HiLens skill),以及HoloSens三種。
後記
ModelArts 是可以讓開發者上手更快、訓練更快、部署更快的全流程平台。它可以為企業帶來更多價值:
1、數據標準與準備效率百倍提升
在數據標註與準備階段,調查發現:數據標註與準備非常耗時費力,約佔整體開發時間50%,所以有大家常說的「沒有人工就沒有智慧」。 ModelArts內置AI數據框架,以AI的機制來治理數據,用迭代訓練來解決標註的數據量問題。尤其適合數據量很大的場景,數據標註與準備效率百倍提升。
2、模型訓練耗時降一半
在模型訓練階段,針對模型訓練耗時長的挑戰,ModelArts通過各類優化技術,尤其,我們的級聯式混合併行技術,在同樣的模型、數據集和同等硬體資源情況下,模型訓練耗時降低一半。
3、模型一鍵部署到雲、邊、端
在模型部署階段,AI規模化落地,模型部署會非常複雜。例如智慧交通,就有一個常見場景:即更新後的模型,需要一次性同時部署到各種不同規格、不同廠商的攝影機上,是一項非常耗時、費力的巨大工程。而ModelArts已實現一鍵推送模型到所有邊緣、端的設備上,雲上的部署還支援 在線和批量推理,滿足大並發和分散式等多種場景需求。
4、用AI的機制加速AI開發過程,降低開發門檻
解決了標註、訓練、部署之後,ModelArts還能幫助開發者提升開發的效率。AI要規模化走進各行各業,必須要變成一種易掌握的基本技能。ModelArts的自動學習功能,包括模型的自動設計與自動調參等,目的是讓每個開發者,都可以快速上手。
ModelArts實現在AI開發全生命周期中,從原始數據、標註數據、訓練作業、演算法、模型、推理服務等,提供全流程可視化管理。實現千萬級模型、數據集以及服務等對象的管理,無需人工干預,自動生成溯源圖,選擇任一模型,就可以找到對應的數據集、參數、模型部署在哪裡。尤其是訓練斷點接續和訓練結果比對,這些很實用的功能很受華為內部開發者歡迎。
5、ModelArts幫助開發者構建自己的生態
ModelArts為開發者提供了支援數據、模型和API的共享管理平台。
對內,可以內部實現數據、模型的共享,幫助企業提升AI開發效率,構建企業自己的AI能力,同時全方位的保障企業AI資訊資產的安全。
對外,通過模型倉庫,實現開放、健康的生態,幫助AI開發者實現知識到價值的變現,幫開發者構建自己的影響力和生態。
正如本文開篇的引用,Sagemaker是我們強有力的友商AWS的產品,做得很不錯,我們始終要滿懷著尊敬之心,從友商身上學習精髓,我們始終要以客戶為中心,為他們提供各種各樣的服務,讓中國的用戶可以享受安全、可信的公有雲服務,可以基於公有雲服務享受AI帶來的紅利。



