Hadoop 系列(三)—— 分散式計算框架 MapReduce
- 2019 年 10 月 3 日
- 筆記
一、MapReduce概述
Hadoop MapReduce 是一個分散式計算框架,用於編寫批處理應用程式。編寫好的程式可以提交到 Hadoop 集群上用於並行處理大規模的數據集。
MapReduce 作業通過將輸入的數據集拆分為獨立的塊,這些塊由 map 以並行的方式處理,框架對 map 的輸出進行排序,然後輸入到 reduce 中。MapReduce 框架專門用於 <key,value> 鍵值對處理,它將作業的輸入視為一組 <key,value> 對,並生成一組 <key,value> 對作為輸出。輸出和輸出的 key 和 value 都必須實現Writable 介面。
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)二、MapReduce編程模型簡述
這裡以詞頻統計為例進行說明,MapReduce 處理的流程如下:
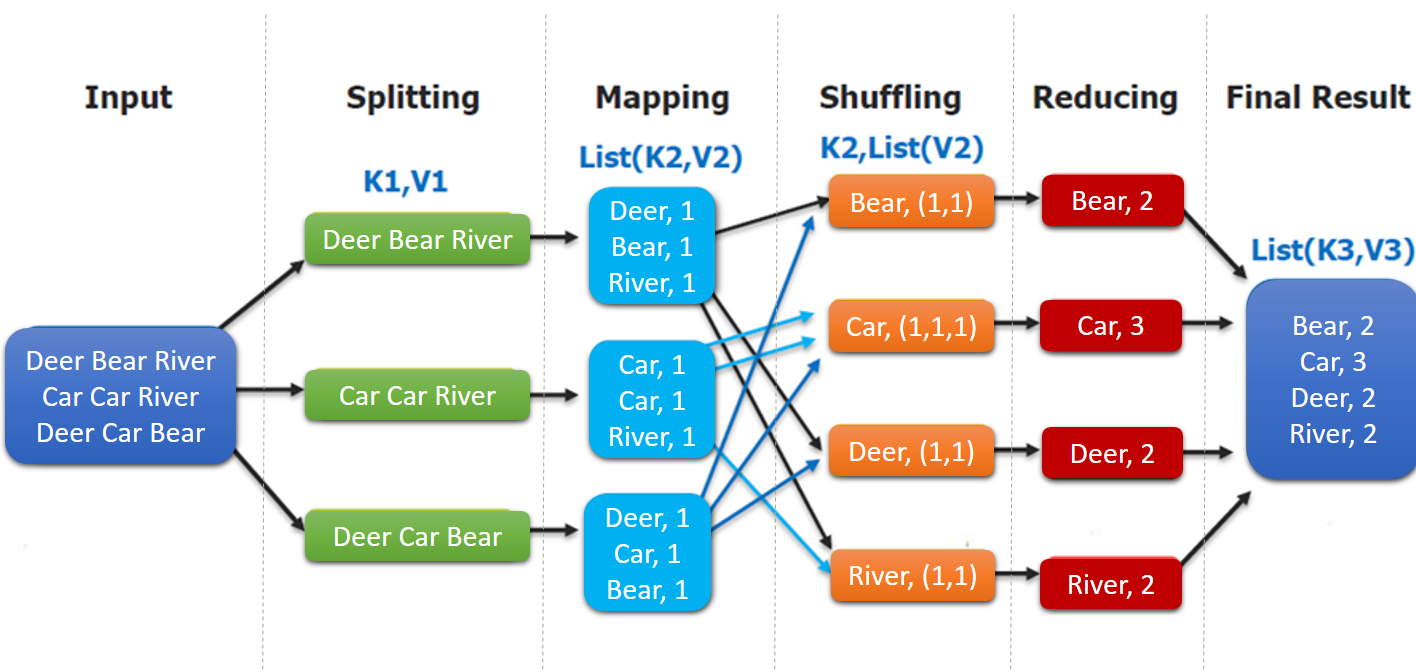
-
input : 讀取文本文件;
-
splitting : 將文件按照行進行拆分,此時得到的
K1行數,V1表示對應行的文本內容; - mapping : 並行將每一行按照空格進行拆分,拆分得到的
List(K2,V2),其中K2代表每一個單詞,由於是做詞頻統計,所以V2的值為 1,代表出現 1 次; - shuffling:由於
Mapping操作可能是在不同的機器上並行處理的,所以需要通過shuffling將相同key值的數據分發到同一個節點上去合併,這樣才能統計出最終的結果,此時得到K2為每一個單詞,List(V2)為可迭代集合,V2就是 Mapping 中的 V2; -
Reducing : 這裡的案例是統計單詞出現的總次數,所以
Reducing對List(V2)進行歸約求和操作,最終輸出。
MapReduce 編程模型中 splitting 和 shuffing 操作都是由框架實現的,需要我們自己編程實現的只有 mapping 和 reducing,這也就是 MapReduce 這個稱呼的來源。
三、combiner & partitioner
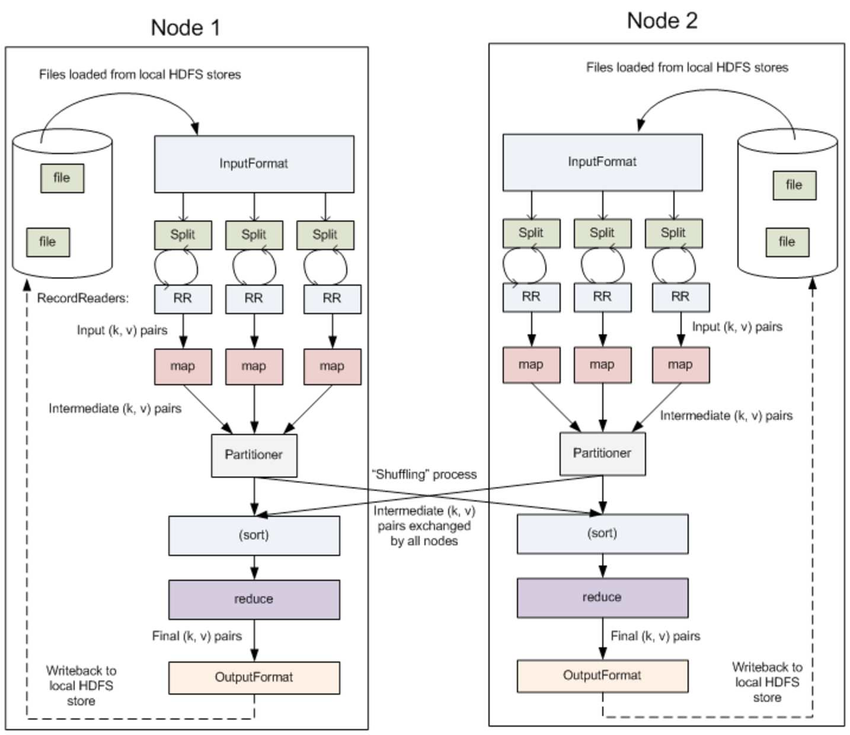
3.1 InputFormat & RecordReaders
InputFormat 將輸出文件拆分為多個 InputSplit,並由 RecordReaders 將 InputSplit 轉換為標準的<key,value>鍵值對,作為 map 的輸出。這一步的意義在於只有先進行邏輯拆分並轉為標準的鍵值對格式後,才能為多個 map 提供輸入,以便進行並行處理。
3.2 Combiner
combiner 是 map 運算後的可選操作,它實際上是一個本地化的 reduce 操作,它主要是在 map 計算出中間文件後做一個簡單的合併重複 key 值的操作。這裡以詞頻統計為例:
map 在遇到一個 hadoop 的單詞時就會記錄為 1,但是這篇文章里 hadoop 可能會出現 n 多次,那麼 map 輸出文件冗餘就會很多,因此在 reduce 計算前對相同的 key 做一個合併操作,那麼需要傳輸的數據量就會減少,傳輸效率就可以得到提升。
但並非所有場景都適合使用 combiner,使用它的原則是 combiner 的輸出不會影響到 reduce 計算的最終輸入,例如:求總數,最大值,最小值時都可以使用 combiner,但是做平均值計算則不能使用 combiner。
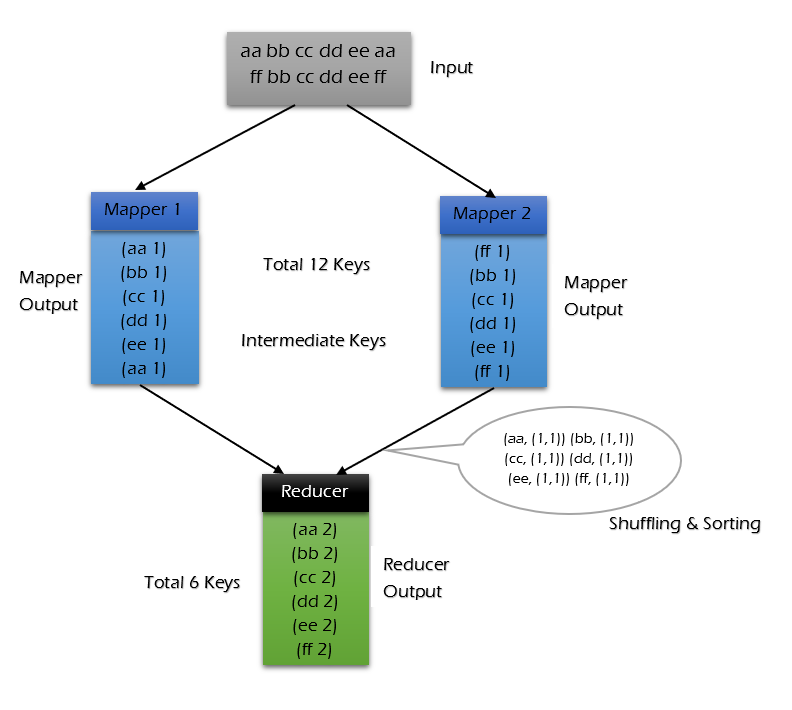
不使用 combiner 的情況:
使用 combiner 的情況:
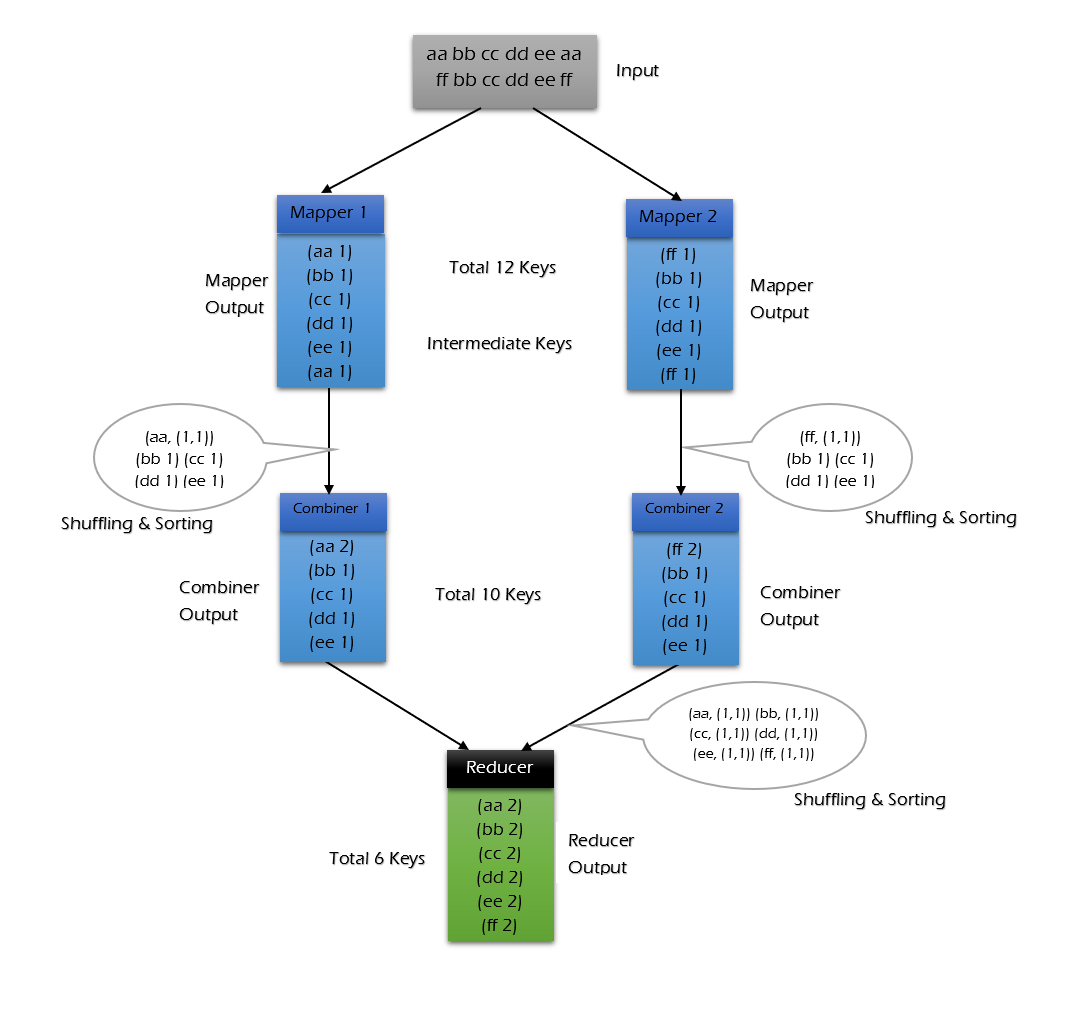
可以看到使用 combiner 的時候,需要傳輸到 reducer 中的數據由 12keys,降低到 10keys。降低的幅度取決於你 keys 的重複率,下文詞頻統計案例會演示用 combiner 降低數百倍的傳輸量。
3.3 Partitioner
partitioner 可以理解成分類器,將 map 的輸出按照 key 值的不同分別分給對應的 reducer,支援自定義實現,下文案例會給出演示。
四、MapReduce詞頻統計案例
4.1 項目簡介
這裡給出一個經典的詞頻統計的案例:統計如下樣本數據中每個單詞出現的次數。
Spark HBase Hive Flink Storm Hadoop HBase Spark Flink HBase Storm HBase Hadoop Hive Flink HBase Flink Hive Storm Hive Flink Hadoop HBase Hive Hadoop Spark HBase Storm HBase Hadoop Hive Flink HBase Flink Hive Storm Hive Flink Hadoop HBase Hive為方便大家開發,我在項目源碼中放置了一個工具類 WordCountDataUtils,用於模擬產生詞頻統計的樣本,生成的文件支援輸出到本地或者直接寫到 HDFS 上。
項目完整源碼下載地址:hadoop-word-count
4.2 項目依賴
想要進行 MapReduce 編程,需要導入 hadoop-client 依賴:
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency>4.3 WordCountMapper
將每行數據按照指定分隔符進行拆分。這裡需要注意在 MapReduce 中必須使用 Hadoop 定義的類型,因為 Hadoop 預定義的類型都是可序列化,可比較的,所有類型均實現了 WritableComparable 介面。
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] words = value.toString().split("t"); for (String word : words) { context.write(new Text(word), new IntWritable(1)); } } }WordCountMapper 對應下圖的 Mapping 操作:
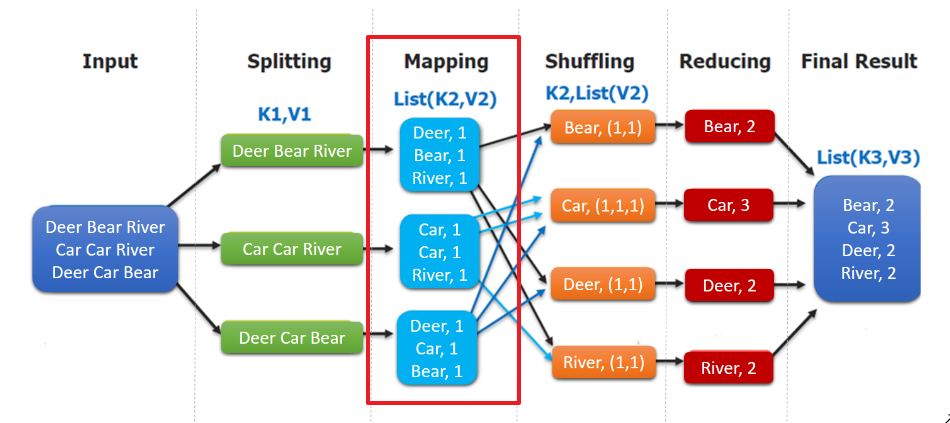
WordCountMapper 繼承自 Mappe 類,這是一個泛型類,定義如下:
WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { ...... }- KEYIN :
mapping輸入 key 的類型,即每行的偏移量 (每行第一個字元在整個文本中的位置),Long類型,對應 Hadoop 中的LongWritable類型; - VALUEIN :
mapping輸入 value 的類型,即每行數據;String類型,對應 Hadoop 中Text類型; - KEYOUT :
mapping輸出的 key 的類型,即每個單詞;String類型,對應 Hadoop 中Text類型; - VALUEOUT:
mapping輸出 value 的類型,即每個單詞出現的次數;這裡用int類型,對應IntWritable類型。
4.4 WordCountReducer
在 Reduce 中進行單詞出現次數的統計:
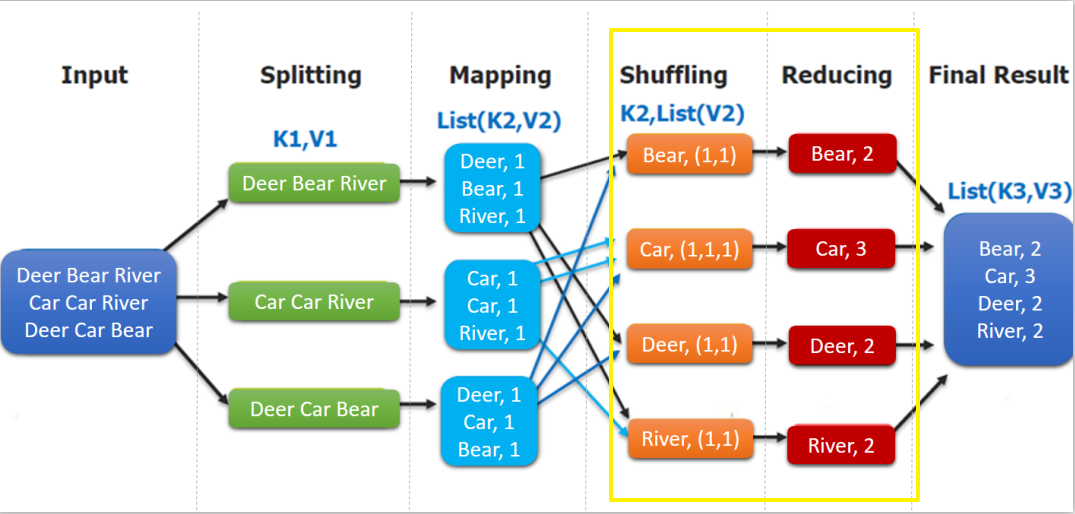
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count = 0; for (IntWritable value : values) { count += value.get(); } context.write(key, new IntWritable(count)); } }如下圖,shuffling 的輸出是 reduce 的輸入。這裡的 key 是每個單詞,values 是一個可迭代的數據類型,類似 (1,1,1,...)。
4.4 WordCountApp
組裝 MapReduce 作業,並提交到伺服器運行,程式碼如下:
/** * 組裝作業 並提交到集群運行 */ public class WordCountApp { // 這裡為了直觀顯示參數 使用了硬編碼,實際開發中可以通過外部傳參 private static final String HDFS_URL = "hdfs://192.168.0.107:8020"; private static final String HADOOP_USER_NAME = "root"; public static void main(String[] args) throws Exception { // 文件輸入路徑和輸出路徑由外部傳參指定 if (args.length < 2) { System.out.println("Input and output paths are necessary!"); return; } // 需要指明 hadoop 用戶名,否則在 HDFS 上創建目錄時可能會拋出許可權不足的異常 System.setProperty("HADOOP_USER_NAME", HADOOP_USER_NAME); Configuration configuration = new Configuration(); // 指明 HDFS 的地址 configuration.set("fs.defaultFS", HDFS_URL); // 創建一個 Job Job job = Job.getInstance(configuration); // 設置運行的主類 job.setJarByClass(WordCountApp.class); // 設置 Mapper 和 Reducer job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); // 設置 Mapper 輸出 key 和 value 的類型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 設置 Reducer 輸出 key 和 value 的類型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 如果輸出目錄已經存在,則必須先刪除,否則重複運行程式時會拋出異常 FileSystem fileSystem = FileSystem.get(new URI(HDFS_URL), configuration, HADOOP_USER_NAME); Path outputPath = new Path(args[1]); if (fileSystem.exists(outputPath)) { fileSystem.delete(outputPath, true); } // 設置作業輸入文件和輸出文件的路徑 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, outputPath); // 將作業提交到群集並等待它完成,參數設置為 true 代表列印顯示對應的進度 boolean result = job.waitForCompletion(true); // 關閉之前創建的 fileSystem fileSystem.close(); // 根據作業結果,終止當前運行的 Java 虛擬機,退出程式 System.exit(result ? 0 : -1); } }需要注意的是:如果不設置 Mapper 操作的輸出類型,則程式默認它和 Reducer 操作輸出的類型相同。
4.5 提交到伺服器運行
在實際開發中,可以在本機配置 hadoop 開發環境,直接在 IDE 中啟動進行測試。這裡主要介紹一下打包提交到伺服器運行。由於本項目沒有使用除 Hadoop 外的第三方依賴,直接打包即可:
# mvn clean package使用以下命令提交作業:
hadoop jar /usr/appjar/hadoop-word-count-1.0.jar com.heibaiying.WordCountApp /wordcount/input.txt /wordcount/output/WordCountApp作業完成後查看 HDFS 上生成目錄:
# 查看目錄 hadoop fs -ls /wordcount/output/WordCountApp # 查看統計結果 hadoop fs -cat /wordcount/output/WordCountApp/part-r-00000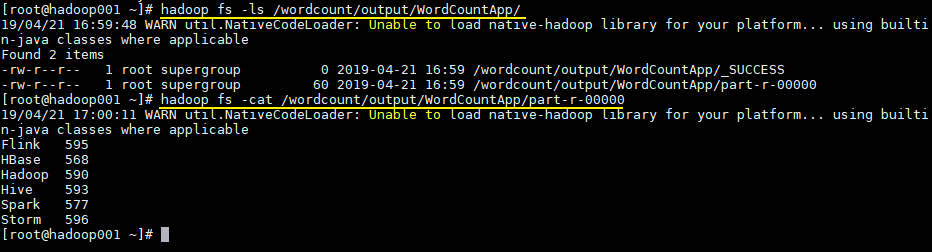
五、詞頻統計案例進階之Combiner
5.1 程式碼實現
想要使用 combiner 功能只要在組裝作業時,添加下面一行程式碼即可:
// 設置 Combiner job.setCombinerClass(WordCountReducer.class);5.2 執行結果
加入 combiner 後統計結果是不會有變化的,但是可以從列印的日誌看出 combiner 的效果:
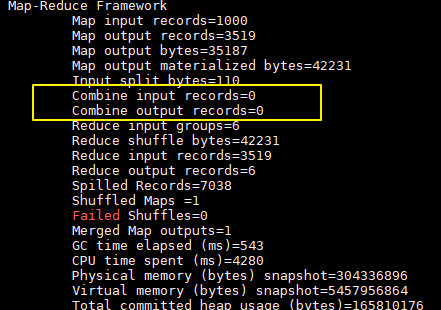
沒有加入 combiner 的列印日誌:
加入 combiner 後的列印日誌如下:
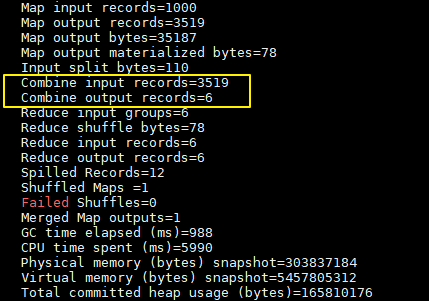
這裡我們只有一個輸入文件並且小於 128M,所以只有一個 Map 進行處理。可以看到經過 combiner 後,records 由 3519 降低為 6(樣本中單詞種類就只有 6 種),在這個用例中 combiner 就能極大地降低需要傳輸的數據量。
六、詞頻統計案例進階之Partitioner
6.1 默認的Partitioner
這裡假設有個需求:將不同單詞的統計結果輸出到不同文件。這種需求實際上比較常見,比如統計產品的銷量時,需要將結果按照產品種類進行拆分。要實現這個功能,就需要用到自定義 Partitioner。
這裡先介紹下 MapReduce 默認的分類規則:在構建 job 時候,如果不指定,默認的使用的是 HashPartitioner:對 key 值進行哈希散列並對 numReduceTasks 取余。其實現如下:
public class HashPartitioner<K, V> extends Partitioner<K, V> { public int getPartition(K key, V value, int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; } }6.2 自定義Partitioner
這裡我們繼承 Partitioner 自定義分類規則,這裡按照單詞進行分類:
public class CustomPartitioner extends Partitioner<Text, IntWritable> { public int getPartition(Text text, IntWritable intWritable, int numPartitions) { return WordCountDataUtils.WORD_LIST.indexOf(text.toString()); } }在構建 job 時候指定使用我們自己的分類規則,並設置 reduce 的個數:
// 設置自定義分區規則 job.setPartitionerClass(CustomPartitioner.class); // 設置 reduce 個數 job.setNumReduceTasks(WordCountDataUtils.WORD_LIST.size());6.3 執行結果
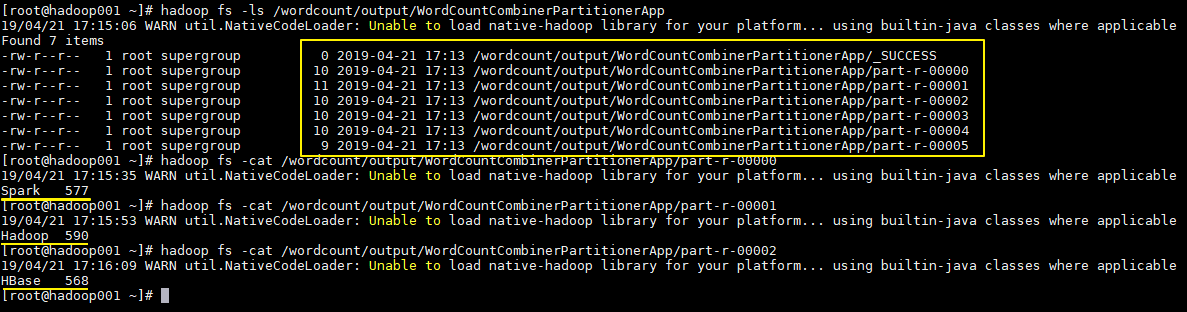
執行結果如下,分別生成 6 個文件,每個文件中為對應單詞的統計結果:
參考資料
更多大數據系列文章可以參見 GitHub 開源項目: 大數據入門指南
