華為五大專家親述:如何轉型搞 AI?
導語:非AI專業技術人員轉型AI技術,或是作為一名學生學習AI技術開發,對每個有這樣訴求和經歷的人來說,都希望能夠看到AI技術人才的成長經歷,給出自己的真實經歷分享。
前言
參考塞繆爾.約翰遜(18世紀英國文學評論家、詩人,著有《英語大辭典》、《莎士比亞集》)的思路,「當一個人厭倦了學習技術,那他肯定也厭倦了IT行業;因為只有持續學習,才會有IT行業帶給你的一切,包括金錢」。這是IT行業的實際情況,沒有哪個人可以靠吃老本長期生存,AI技術更是如此。最近我在讀《倫敦人》,書中講述了200多位新老倫敦人對於倫敦這座城市的切身感受和故事,感覺應該就AI技術人才的成長寫一篇,因此,有了本文。
非AI專業技術人員轉型AI技術,或是作為一名學生學習AI技術,對每個有這樣訴求和經歷的人來說,可能都希望能夠看到類似經歷的人,給出自己的真實經歷分享。
今天,我找了幾位我的同事,包括我在內一共五位,我們都很有代表性,逐一介紹一下:
- 麥克周:2004年畢業於浙江大學,電腦專業碩士,15歲開始學習編程,使用的是Basic語言,讀書期間主要寫C語言,2004年畢業時寫的是JSP程式碼(一種將Java語言嵌入在HTML程式碼中的編寫方式),工作幾年後轉入分散式軟體技術,再後來進入大數據技術領域,最近的4年時間從事AI平台產品研發工作。
- Mr Qiu:演算法相關專業碩士,工作五年時間。2013年進入杭州電子科技大學學習人工智慧和電子資訊技術,碩士方式主要以嵌入式和影像演算法為主,畢業後進入安防行業的大華公司,再到華為,一直從事電腦視覺、演算法移植優化、訓練框架優化、機器學習等工作。
- Hannah:曼徹斯特大學電子電氣工程本科,倫敦大學學院數據科學碩士,畢業後加入華為公司,已經工作兩年。華為公司作為中國私有雲的先驅廠商之一,在數據科學這一領域有很多沉澱。因此,工作期間有機會參與多維度的工作,從演算法研究落地,到平台開發,再到POC項目開發、現場建模PK等,在短時間內加深了對數據科學這一學科的認知。
- Doctor Zeng:中國某重點大學博士,2018年華為Special Offer。本科畢業工作五年之後回到學校,繼續自己的碩博攻讀。碩士期間開始協助導師做項目,接觸IT行業的十餘年時間,具備豐富的資訊系統項目開發與管理經驗、人工智慧領域的項目實戰經驗,並作為實驗室技術骨幹參與若干國家級、省部級項目。博士期間的主要研究領域是NLP、知識圖譜,現擔任華為某演算法建模團隊首席專家。
- 帆哥:20年ICT工作經驗,4年訊號處理機開發,5年企業數通產品研發,3年作業系統架構設計,3年大數據分析研究,5年AI產品規劃,目前是華為雲ModelArts首席產品管理專家。
正文
麥克周
知識不能單從經驗中得出,而只能從理智的發明和觀察到的事實兩者比較中得出——愛因斯坦
作為一位喜歡徹底搞清楚原理的軟體工程師,我的每一次轉型都在大量閱讀和實際操作中完成。我給的建議是根據自己的實際情況,從全局性的到具體技術的書,一本本讀,不要急。
我看的第一本書是尼克的《人工智慧簡史》,這本書幾乎全面講述人工智慧的發展史,幾乎覆蓋人工智慧學科的所有領域,包括人工智慧的起源、自動定理證明、專家系統、神經網路、自然語言處理、遺傳演算法、深度學習、強化學習、超級智慧、哲學問題和未來趨勢等,當然,他不是一本動手教你編程的書,而是給你一個宏觀印象,適合AI產品經理、CTO閱讀。
如果你覺得還需要進一步拓展自己對技術的全局性理解,我建議你可以讀Stephen Lucci和Danny Kopec一起編寫的《人工智慧(第二版)》,這本書有點像高校的人工智慧相關專業教材,堪稱「人工智慧的百科全書」,全書涵蓋了人工智慧簡史、搜索方法、知情搜索、博弈中的搜索、人工智慧中的邏輯、知識表示、產生式系統、專家系統、機器學習和神經網路、遺傳演算法、自然語言處理、自動規劃、機器人技術、高級電腦博弈、人工智慧的歷史和未來等主題。
看了全局化的知識後,建議你可以根據自己的實際情況選擇書籍,周志華的《機器學習》、Ian等人合著的《深度學習》、Aston Zhang等人合著的《動手學深度學習》、鄭澤宇等人合著的《TensorFlow:實戰Google深度學習框架(第2版)》、Vishnu Subramanian的《PyTorch深度學習》,這些書都是不錯的,當然還有其他很多優秀的著作,這裡不展開介紹,更多取決於你當前的狀態,你是想快速動手訓練模型,還是想了解清楚原理,因人情況不同而異。
除了系統化看書學習以外,我最希望的是儘快上手編碼、訓練模型,動手必須有IDE工具的支撐,我不太適應公有雲的IDE,但是又希望使用公有雲的強大的計算資源,所以我希望能有工具,幫助完成本地IDE能夠與公有雲平台聯動,我講一個已經實現的案例–如何使用PyCharm與ModelArts公有雲服務聯動開發,快速且充分地利用雲端GPU計算資源。
這裡我連接的是某花廠公有雲AI平台。我們實際上使用一個PyCharm ToolKit工具來幫助建立從本地PyCharm IDE到ModelArts的連接通道,本案例我使用MXNet實現手寫數字影像識別應用的示例,在本地快速完成程式碼編寫,發布到ModelArts公有雲完成模型的訓練和模型生成,生成的模型可以進一步快速進行部署(本文沒有覆蓋該步驟)。安裝ToolKit前需要先安裝2019.2版本(目前ToolKit僅適配該版本)的PyCharm,下載地址是://download.jetbrains.com/python/PyCharm-professional-2019.2.exe?_ga=2.11170941.815358500.1587189937-686177363.1586569505
需要注意,如果已經安裝了高版本的PyCharm,需要首先卸載(自動)已安裝的PyCharm:
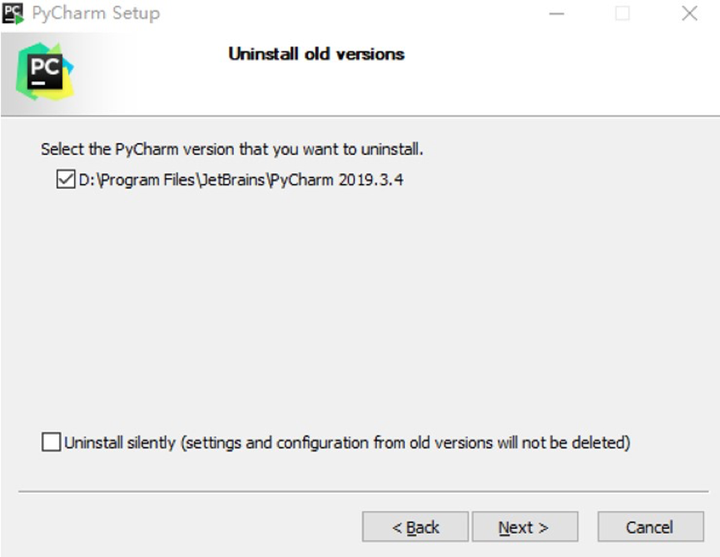
下載一個工具PyCharm-ToolKit-PC-2019.2-HEC-1.3.0.zip,連接本地IDE與雲之間的鏈路://www.jetbrains.com/PyCharm/download/other.html
接著回到PyCharm IDE,打開Settings:
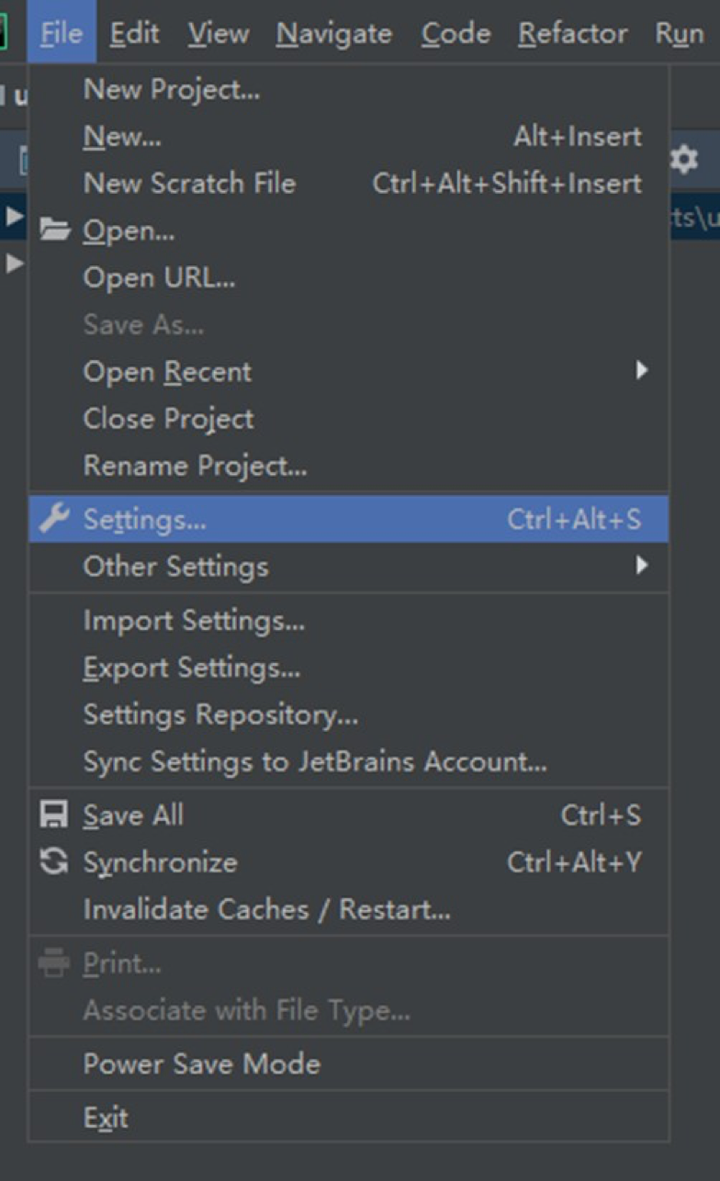
找到Plugins,選擇一個插件:
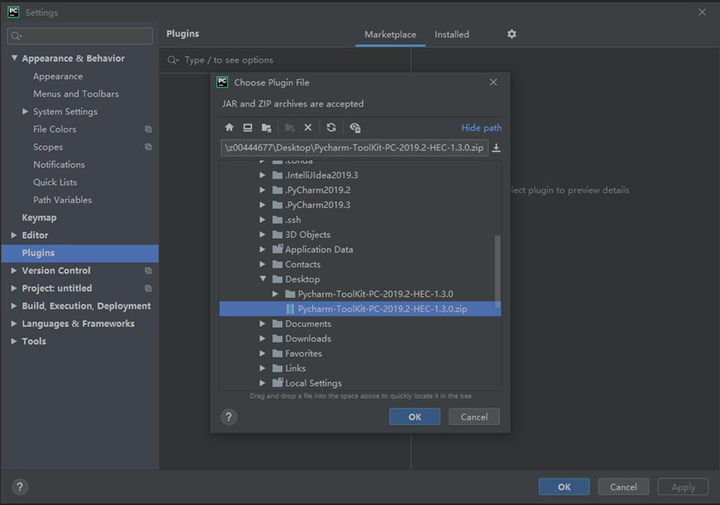
重啟後看到如下介面:

然後我們需要去華為雲申明OBS的秘鑰:

簡訊驗證碼註冊成功後,請務必把csv文件保存到本機。回到PyCharm IDE:
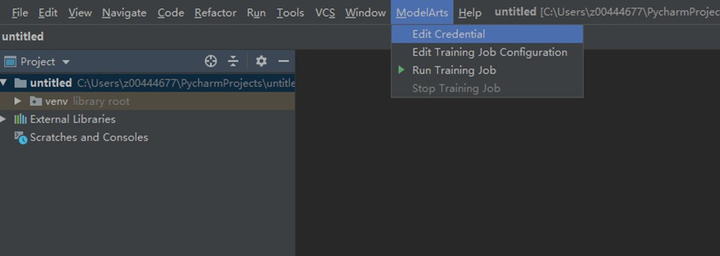
注意,需要你重新點擊edit credential按鈕,退出後就能看到打鉤了。
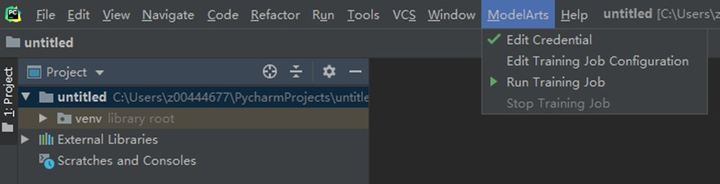
這樣我們就完成了PyCharm IDE與ModelArts的對接工作,進入下一步,實際訓練一個模型。首先,下載手寫字的數據集,下載鏈接如下://modelarts-cnnorth1-market-dataset.obs.cn-north-1.myhuaweicloud.com/dataset-market/Mnist-Data-Set/archiver/Mnist-Data-Set.zip,登錄華為雲上傳OBS:
創建完畢文件夾後,接著在PyCharm打開工程,填寫參數,可以參考ModelArts訓練模型時填寫的參數:

點擊「Run Training Job」,右下角是從公有雲傳回到PyCharm的訓練日誌資訊:

訓練完成後,訓練模型保存在公有雲的OBS里,你可以自己選擇下載或是在雲上做推理。
如果有這樣的一堆工具,是我們這些實際寫程式碼的人的福音。
Mr Qiu
「某利郡後;頗與郡人相安;日知來四處無虞;早收中熟;覺風雨如期;晚稻亦可望;惟是力綿求牧;來日方長。」——宋·文天祥《與洪度瑞明雲岩書》
在介紹如何轉型進入AI領域之前,先介紹下個人的經歷。從接觸AI到工作至今大概7年,我把它分為3段:(1)在校學習期;(2)實習轉型期;(3)工作成長期。在校期間學的比較廣,主要方向在人工智慧、高頻電子電路、傳統影像演算法、嵌入式系統等,這個階段通過以賽促學方式,取得了一些不錯的比賽成績;實習期間有幸參與到某重點項目的「以圖搜圖」模組,積累了大量的影像、人工智慧方面的實戰經驗;畢業參加工作後,主要圍繞電腦視覺、演算法移植優化,深度學習框架優化,機器學習等進入研究和實踐,有了一定的全棧AI經驗。偶有感慨,雖然資質平平,但好在目標明確,持續奮鬥,也遇到很多值得感謝的人,才有機會在這裡介紹下經驗。
2012年,一年一度的ImageNet影像識別比賽,CNN網路AlexNet以碾壓的分類性能超過第二名(SVM方法),從此深度學習開始吸引研究者的注意。但真正吸引工業界去大規模投入深度學習,大概到了2015年到2016年,這個時候,賈揚清在博士期間開源了深度學習框架Caffe,Google開源第一版的人工智慧引擎TensorFlow,Caffe曾一度以其優秀的程式碼架構,便捷的開發介面等優點受到廣大研究者和工程師的推崇。早期做AI開發,很多工具都不完善,需要造輪子,這裡的輪子主要包括離線訓練時需要開發影像標註工具、需要修改深度學習框架實現相關運算元的前向和後向計算、實現卷積中間特徵可視化來調優模型等,在線部署時需要自己實現運算元的FP16和int8計算,需要自己寫CUDA程式碼等。
現在,進入AI領域的開發者不再需要做這些輪子,真的很幸福。
影像標註工具LabelImg等已開源,可以直接拿過來使用;TensorFlow迭代到更加利於開發者使用,提供了很多優秀的示例,可視化工具和推理部署工具等;隨著PyTorch的逐漸崛起,已經可以與TensorFlow評分秋色,開發者有了更多的選擇;NVIDIA 推出了基於GPU的推理加速工具TensorRT可以免費使用,華為也推出了基於自研晶片達芬奇的推理加速和框架MindSpore,以更高密度的算力豐富開發者的選擇。
隨著巨頭公司全力投入AI,AI的工具也越來越完善,開發者可以將精力集中在模型開發以及業務的實現上,這是一個AI的好時代,也是AI開發者的好時代,我想現在開始轉型AI正逢其時。
再回頭看看這些年的AI發展歷程和踩過的坑,以個人的角度提煉出傳統軟體開發轉型到AI開發工程的方法,希望對大家有幫助。暫且把這些總結為3個部分,分別為(1)動手跑起來、(2)原理掌握起來、(3)推理部署起來。
1. 動手跑起來:
這個階段就是通過現有開源的優秀項目進行學習,這裡我推薦darknet YOLOv3,項目地址//github.com/pjreddie/darknet。該項目框架基於C語言實現,框架清晰易於調試。初學者在下載到項目程式碼後首先要將該項目跑起來,通過跟蹤數據在整個框架的流動大致掌握AI是怎麼工作的,可以解決什麼樣的問題。同時在跑通搭建環境的過程中,可以快速掌握GPU跟深度學習框架是怎麼結合起來工作的、深度學習框架在運行過程中需要有什麼依賴。
2. 原理掌握起來:
作為優秀和經典的端到端檢測演算法,首先推薦以YOLO進行學習,從推出至今已迭代到第四版本。可以從第一版本YOLOv1開始進入,再到第四版本YOLOv4,掌握YOLO是如何演化的,分別作了哪些改進,改進為什麼會起到性能提升的效果。網上已有大量優秀的部落格,開發者可以自行去搜索閱讀。結合動手跑起來階段的程式碼調試,相信會進步的更快。研究完成YOLO演化過程後,有興趣可以再去研究下R-CNN系列的檢測演算法,R-CNN系列演算法區別於YOLO是召回率高、準確率高,但是耗時,所以綜合考慮工業界一般用的更多還是YOLO。
3. 推理部署起來:
推理部署就是將深度學習框架訓練好的模型部署到PC或者端測設備進行推理,解決實際的業務問題。這個過程主要包括模型性能調優,GPU或者D晶片的適配,業務邏輯的實現。對於模型性能調優,主要是將模型推理原有的FP32量化成FP16或者int8,從而實現推理加速,實現實時推理。這裡推薦NVIDIA 的TensorRT和華為的D晶片加速模組,它們會對模型做更高階的優化,除了量化,還會有模型網路層之間的運算元融合、kennel優化等,具體資料可以到相應的官網去搜索。模型優化完成後,通過相應的推理引擎和業務邏輯實現去完成模型的在線推理,完成真正的工業化,解決實際問題,這也是AI真正為社會產生價值的部分。
通過這三個部分的學習,日積月累,相信你也會慢慢成為AI領域的資深演算法工程師。
Hannah
既然我已經踏上這條道路,那麼,任何東西都不應妨礙我沿著這條路走下去。——康德

大家好,在本文的五人組裡,我是一個職場小白。作為一個沒啥社會經歷的小白,我的大部分人生是在學校度過的,我這邊就主要介紹我上學的經歷吧。
本科的時候,我選擇了電子電氣工程這個專業。當時對於專業和工作沒有什麼大的概念,只是覺得理科生就該選一個「帶電」的專業,我就從長長的專業列表裡選了這個最多「電」的專業,然後背著我的小書包,開開心心到了曼徹斯特開始我的大學生涯。
開學後,果然和我想像的不一樣,這種工科類的專業對學生的動手實驗能力要求很高,我在第一次上實驗課,看到一堆的實驗器材的時候就懵了。當時場景對我來說是挺可怕的,同組印度小哥聽了實驗老師給的要求後就咔咔一頓操作,我在旁邊愣住了,連把他的操作錄下來後面自己回去學習這麼重要的事情都忘了。在他得出實驗結果後,我才小心翼翼地求教這些操作是怎麼一回事。小哥哥是熱心腸,用快速的印度口音英語給我解釋了一遍。但是我學的英語聽力,只聽過英音和美音,對於印式英語實在是陌生,我只能厚臉皮讓小哥再說一次。他在第三次的時候,終於失去了耐心,指著教材的一段讓我讀。我這才意識到,他一直都在說這段話,只是我沒聽懂,包括他指著讀的那一次。於是,第一節實驗課我是在查各種儀器名稱、和同組印度小哥的高速咖喱英語解釋的過程中,度過的。感恩團隊沒有放棄我,讓我順利度過我的大一。
到本科選擇畢設方向的時候,我靈機一動,選了DSP(數字訊號處理)相關的一個降噪耳機的項目。用下面的圖來解釋下原理:
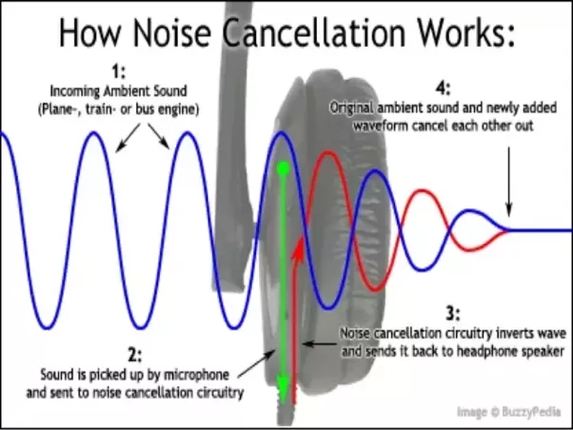
一般主動降噪耳機內部會有一個小的麥克風用來採集外界的聲音,通過計算,可以生成一個完全相反的音波,然後和外界的噪音疊加,使得噪音消減。
整個項目只是按照老師的教材和給的參考書上面的操作,實現了一個FIR-LMS演算法的濾波器。演算法雖然簡單,但是實現效果還蠻好的。我額外做了一套麥克風的小硬體用來演示成果,在麥克風旁邊用手機播放白噪,同時說話,最後從音響出來的聲音是有部分降低噪音的效果的。
在做這個項目的時候最大的感觸就是,這種演算法不僅是可以在科研界獲得一些成果,更多的是,在應用到生活中的時候,可以給我們這些普通人很多的便利。
當時很中二的我就會想,如何能接觸到更多的這種科技,甚至於參與這種科技的落地。這個時候,一個動畫片告訴了我答案。《超能陸戰隊》里的高級人工智慧機器人大白,他是一個近乎全能的家庭醫生。這個是AI的力量,在當時幾個研究生的offer里,最終選擇了數據科學作為我的研究生方向。
研究生階段起步並不輕鬆,從電子電氣的方向轉到數據科學這個學科並不是非常的順利。數據科學這個專業是統計系和電腦科學系合作辦的,也就是說,這個專業對於統計學和電腦科學的要求是比較高的。當時老師也列出了長長的一串參考書目,印象深刻的是PRML(《模式識別與機器學習》)和BRML(《貝葉斯推理和機器學習》)。大家有興趣也可以去看看,中國也有很好的書籍,推薦李航《統計學習方法》和周志華的《機器學習》。

這個專業依舊也是非常重視我們的實際建模的技能,幾乎所有的課程都有30%以上的分數是需要我們去建模。其中有一門是應用機器學習,這門課要求我們在Kaggle上參加比賽,並用我們的名次來給我們打實驗分。一個月時間內,我們組參加了三個項目,其中有一個我們拿到了前4%的成績。Kaggle上面的項目很適合初學者練手,在學習了一堆理論知識後,初學者很多時候會對這一堆數學公式很陌生,不知道他們的實際效果。在Kaggle上的比賽給了初學者一個接觸真實數據並用來建模的機會,參加這些比賽,還能根據自己的結果了解當前學習的模型在解決真實問題的時候,能否在排名中靠前,是否是真的比較好的解決方案。這讓我在短時間內,對我在課堂上學習到的理論有了更深一層的認識。即使我們對於數據的實際含義並不明晰,即使數據的含義是經過加密處理的,但是還是可以使用一些機器學習技巧建模,對結果進行預測。Kaggle里的Titanic這個項目,也是很多老師選擇給學生進行數據分析入門和機器學習入門首選項目,有興趣的人可以去實際體驗一下。
學術界和工業界對模型對要求和應用是不一樣的,為了更加了解實際的建模過程,我在畢設的時候,選擇了學校和公司合作的項目。畢設項目是我第一個數據科學方面的實習,為華納音樂公司做一個簡單的相似歌手推薦和一份歌手在英國巡演的最佳城市路線圖。在這個項目中,我接觸了真實的客戶數據,並和公司合作,嘗試在數據中挖掘更多的關聯。同時我也在挖掘更多的可能,在Kaggle上參加了另一個NLP類的比賽,判斷兩個短文本的相似度。這些項目結束的時候,我的研究生生涯也結束了。
回國後,我休息了一段時間就加入了華為公司。在華為公司,我這邊第一個大數據相關的項目是PyTorch大規模加速訓練,類似於華為雲上面的MoXing,但這個是基於PyTorch的一個優化。在這個項目中,我有機會接觸到深度學習計算中較為底層的一些概念,並對GPU之間對通訊有了了解。隨後,為了給平台上增添更多的模型,我有機會更深一層去了解模型的架構,復原了當時很流行的MobileNet的效果。接著學習並在我們的產品上成功嵌入了R-CNN系列的目標檢測演算法。
在這一段深度學習的經歷後,我又投入了我們產品的機器學習的平台和基礎演算法實現部分。我在華為雲嵌入了LightGBM演算法,並對我們機器學習平台進行了一些優化的工作。
接著,我主導了某國家級單位的演算法模型POC項目和中國某大行的信用卡中心演算法聯創項目。再次接觸到真實到數據,並針對數據進行建模的工作。這兩個項目都是風險控制類的項目,在真實的數據中建模真的十分有趣。每一次使用不同行業的數據進行建模,都像是對另一個行業有了全新的認知。在這期間,我還有機會站在國外的論壇上,用英文給VIP客戶介紹一些機器學習的科普知識。
在我短短兩年的工作中,我嘗試了專業範圍內所有的工作。我現在還是覺得我的專業很棒,他幫我打開了新的世界。
Doctor Zeng
一寸光陰一寸金,寸金難買寸光陰 ——《增廣賢文》
作為一位有很多年實際工作經驗的電腦科學專業博士,我就直截了當講講自己對建模流程的理解,以及對應的實際案例。
對於IT界的從業人員而言,從事傳統資訊系統項目開發的項目經理、工程師,可能大多數都被這個時髦的名字所吸引,但卻不知如何下手打造一個高大上的AI項目,就像古代的楊子,遇見了歧路便只知道蹲下來哭泣。好在這是一個最美的時代,我們不用再望著千百條路不知如何下腳,大量頭戴智慧光環的科學家與工程師們,早已為我們打下了牢固的基礎,出現了許多連業餘人員都可以快速上手的AI建模平台。

說到機器學習,可能很多人會望而卻步,認為需要掌握非常高深的數學知識和各種晦澀難懂的理論。幸而不幸,專業的AI人員確實需要掌握牢固的數學知識,也需要精通機器學習的各種理論,但對於構建一個AI項目卻不一定要精通這些知識。這裡我會從一個簡單場景逐步鋪開,幫助大家了解一個典型的機器學習項目構建過程。
所謂眾生熙熙皆為利來,那我們就拿金融業中的場景開刀。金融業可能是大家非常關注的一個領域,就連窮得走漏了風聲的我,也略微知道幾個金融業術語,比如信用卡欺詐。既然第一個冒出的念頭是信用卡申請欺詐,那就聽從內心的聲音,讓我們以信用卡申請欺詐檢測為例聊聊AI項目的構建過程。
萬事開頭難,然後中間難,最後結尾難。對於很多人而言,AI項目似乎就是這種感覺,總是讓人難以捉摸。有人說,AI三要素是「數據」、「算力」和「演算法」,但我認為還有一個要素也不可或缺—「業務」。與學術研究不同,工程項目通常是面向特定的業務場景及特定的業務目標的,平時我們在構建AI項目的過程中,總是習慣性地把整個過程劃分為數據處理、特徵工程、模型訓練、模型推理及模型部署等過程,但其實對業務的分析與理解貫穿項目始終。一位前輩說,以他從事AI項目開發的經驗,理解了業務、有了充足的數據、找到了合適的演算法,這個項目便十拿九穩,其中吃透業務是至關緊要的一步,我深以為然。
既然業務理解會貫穿始終,那麼我們首先來談談業務理解。簡單地講,業務理解就是要去弄清楚我們要做的事(業務常識)、這件事的現狀(現有資源)以及要達成的目標(業務目標)等。對於信用卡欺詐檢測項目而言,除了項目準備、資源準備等前期工作外,首先需要做的就是深入理解信用卡業務,知道什麼是信用卡申請欺詐、為什麼容易出現信用卡申請欺詐、我們擁有哪些可用的數據資源,以及信用卡欺詐檢測系統要達成的目標,等等,然後才去思考如何做信用卡申請欺詐檢測。業務理解的過程,往往需要業務專家的深度介入,需要演算法建模人員與業務專家的密切配合。
在理解了業務需求後,對數據的獲取、分析及處理就成為了無法繞過的重要步驟。數據的獲取相對容易理解,簡單點說就是在合法合規的前提下,儘可能多地收集到與業務問題密切關聯的數據,比如信用卡申請人在申請信用卡過程中填寫的個人資訊、人行徵信報告、第三方機構的信用分析報告等等,均可作為信用卡申請欺詐檢測系統的輸入數據。數據分析的主要目的是認識數據並從數據中提取有用資訊,這又是一個一言難盡的大範疇,工具五花八門,手段也多種多樣,甚至貫穿著整個AI項目構建過程。
一般而言,從不同渠道獲取到的數據,其品質良莠不齊,充斥著大量的冗餘、重複、缺失、異常以及不一致的數據,很難直接用於AI模型的構建過程。冗餘數據的判定需要結合業務分析、相關性分析等手段,通常包括在業務上無效的數據,或與別的數據高度相關的數據等,這類數據與重複數據的處理方法很簡單,簡單粗暴地刪除即可;缺失數據的處理方式有很多種,通常有簡單刪除、特殊值填補、相關數據衍生等常規方法,以及熱卡填充、聚類填充、基於簡單機器學習模型預測的高階方法等;而異常值的處理,需要採用箱型圖、三西格瑪準則、DBSCAN聚類及孤立森林等方法進行分析,識別出數據中的異常值後,按照缺失值的處理方式進行處理;不一致數據主要指那些意義相同但表示方式不一致的數據,比如大小寫混用、日期格式不規則、地址不規範以及單位不統一等,這類數據只需要結合數據規則進行統一規整即可。
數據規整後,通常需要對數據集進行切分。當數據量比較大的時候,可以切分出訓練集、驗證集與測試集,直接使用訓練集訓練模型,用驗證集確定最佳的模型參數,用測試集評估模型性能;當數據量較小的時候,通常不切割出專門的驗證集,而採用交叉驗證的方式確定模型參數,以確保模型得到充分的訓練。信用卡申請欺詐檢測數據,往往總量特別大,但其中真正發生了欺詐行為的數據卻很少,即存在非常嚴重的數據不均衡問題。因此,在數據集切分過程中,要確保欺詐類的數據能夠以一定比例進入到各個數據集中。下面這張截圖包含數據分割運算元的平台。
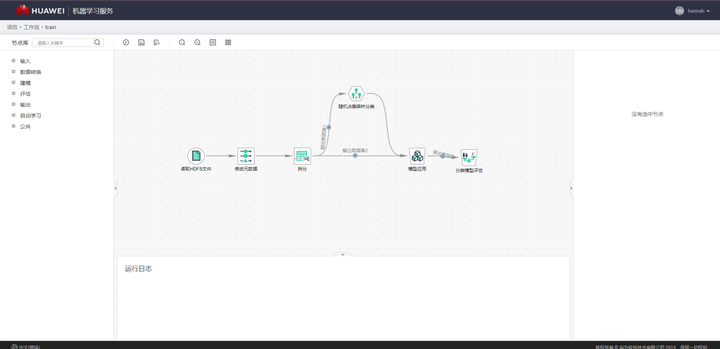
數據處理完成後,便進入了複雜精巧的特徵工程階段。在傳統的機器學習類項目中,數據處理和特徵工程具有極高的地位,甚至有人提出數據和特徵決定了機器學習的上限,而演算法和模型不過是逼近這一上限而已。在我們的實踐中,數據處理和特徵工程的整個過程至少佔據了整個項目的百分之七十以上的開發人力,通常還需要在建模過程中回過頭對特徵進行反覆打磨。下面這張圖是特徵工程工作流截圖。
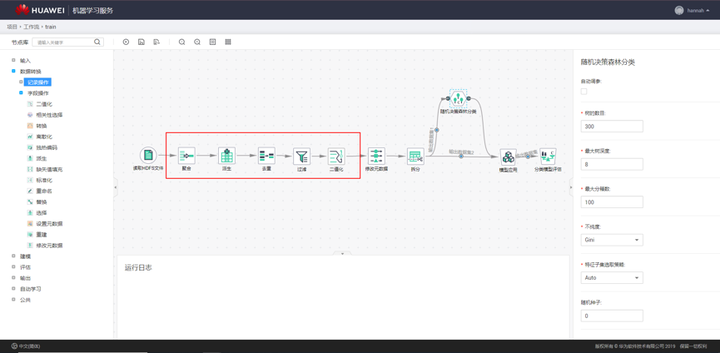
終於,用於建模的數據準備好了,我們可以開始進行高大上的建模工作了。我更樂意把這個過程叫成模型工程,涵蓋了模型選擇、模型訓練、模型評估和模型推理等子過程。模型選擇的過程,通常既要用到很多機器學習的基本功,又需要對數據、業務等有深刻理解,還可能需要一定的建模經驗(別人的經驗也是經驗)。
我們知道,機器學習任務通常可以根據數據集是否有標籤而劃分為有監督、無監督或半監督等類別,根據預測的數據是離散值還是連續值又可以劃分為分類問題和回歸問題兩類。對於信用卡申請欺詐檢測這個問題而言,最簡單的處理方式就是把它當成有監督的二分類問題,即我們只需要判斷用戶發起的一個申請是或不是欺詐申請。現在我們用得比較多的是LGBM、XGBoost、RF等,如下圖所示。

模型選定後,就進入模型訓練、推理和評估的過程了。模型的訓練過程就是要把準備好的訓練數據餵給模型,讓模型以參數等形式學習到數據中蘊含的規律和規則等。通常,在這個過程中,你要設置好模型需要的各類超參數。現在各類開源的機器學習庫、便捷易用的機器學習平台俯拾皆是,大部分情況下,我們並不需要從零開始構建一個機器學習模型,只簡單地做個「調包俠」調一下各種開源機器學習包或者在機器學習平台上拖拽幾個運算元即可。模型推理的過程很好理解,就是把測試集中的數據喂進訓練好的模型中,讓模型預測出結果即可。比如對於信用卡申請欺詐檢測問題而言,就是將待預測的數據丟進模型中,由模型給出每一條數據對應的預測結論。模型評估過程則是通過各類指標對預測結果進行評估,度量預測結果與真實結果之間的差距。對於分類問題而言,常見的有精確率、準確率、召回率、F1值等度量指標,對於回歸問題而言,常見的有MAE、MSE等度量指標。

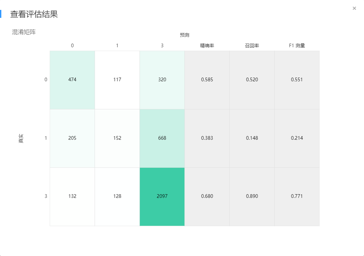
 ModelArts Miner平台評估運算元結果顯示介面截圖
ModelArts Miner平台評估運算元結果顯示介面截圖
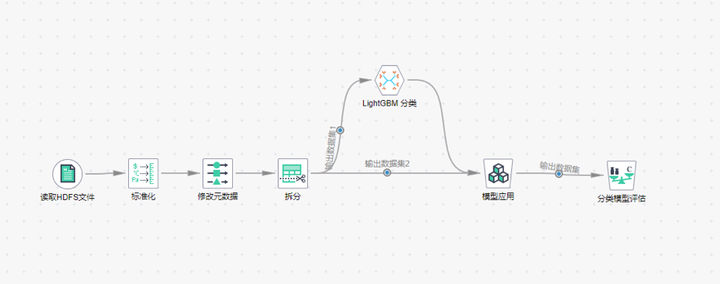
模型訓練、推理和評估過程,甚至包含數據處理和特徵工程過程,可能需要反覆調整與錘鍊,但只要功夫深,金箍棒也能磨成針,你終究會得到你想要的。好了,我們假設你已經得到想要的了,你的模型也能一定程度地預測信用卡申請單是否存在欺詐了。至此,黎明的曙光終於照亮東方的長空,天邊也出現了一絲魚肚白。現在你要做的,就是讓黎明來的更猛烈一些,把你的模型部署到你的業務系統中,讓你的數據歡快的暢遊在AI的管道里,噴出耀眼的煙火。部署到業務系統後,你要不斷地審視你的結果,並且根據最新的數據不斷地調整與優化你的整個模型。但這時候,已經不是我這篇文章能幫助你的了,你展開雄壯的翅膀,去擊穿蒼穹,盡情翱翔吧。下面這站圖是基於華為雲AI平台工作流模式,針對信用卡欺詐檢測全流程介面截圖。
帆哥
天行健,君子以自強不息。——《周易·乾》
作為一名資深產品經理,轉型搞AI後從事了多年的AI平台產品設計,我講講我對AI產品的理解。對於公眾認知的AI開發而言,大家往往想到的都是演算法開發,其實對一個商業落地的AI開發過程,會涉及到很多不同方面,它不僅僅是演算法開發,還會涉及到算力、數據、迭代優化等環節。 對於AI的商業化落地中, CTO們會均衡考慮到三類方面的資源投入,不僅僅是IT基礎實施還包括工程師投入:
1. 算力 –> 普惠;
2. 數據 –> 模型;
3. 演算法 –> 落地; 每一個環節涉及到的人力投入不同,大致會涉及到IT工程師、數據科學家、應用工程師。
具體展開講:
1. 算力—> 普惠(面向IT工程師)
對於AI開發而言,如何利用好算力資源,提升資源利用率是目前特別重要的工作。往往演算法工程師並不擅長這些事情,需要有專業的系統級工程師來幫助是實現,從集群的搭建、運維、韌體運維、底層運算元優化、分散式調優,以及大量的框架維護等方面,另外面向不同部門之間的資源管理也是IT工程師需要關注的內容。對於簡單開發而言,自己用開源搭建搞搞是可行的,但是一旦需要大規模的商業化,需要一個有個比較好的平台尤為重要。

2. 數據 –> 模型(面向數據科學家)
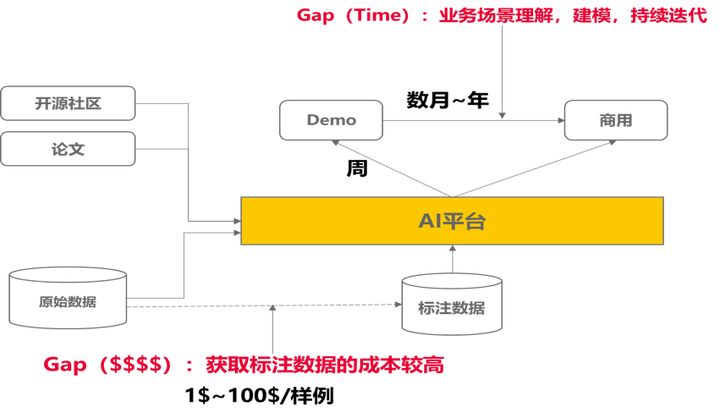
對於AI建模,本質上面是基於數據去生成模型的過程,那麼一般來說,初始demo快的幾天就可以出來,但是到真正落地的時候,少則花費算月,多則上年。這個過程中涉及兩類的大量投入,一類投入獲取訓練數據,從數據收集和標註端到端,另一類投入不斷模型迭代優化上,涉及到大量的領域技能。
訓練數據:面向通用類的場景,會涉及大量的數據標註的工作,這會花費大量的標註人力,對於一般場景下,普通的人員就可以標註,但是面向複雜場景下,都需要專業人士去標註,如醫療影像類場景,一般人都標註不了。所以對於專業領域的標註,以及大量的數據標註下,有一個非常友好的自動化標註及數據難例的演算法能力,尤為重要。
迭代優化:模型建模過程中,商業場景下,數據科學家建模過程中,更多的使用成熟的論文和演算法,圍繞具體的業務場景,結合數據的情況,來選擇性建模,並且隨著不同環境變化情況下,不斷的調整演算法的設計和組合優化,從而達到最佳的演算法效果。這個過程中涉及到大量的場景理解。對於開發模型而言,有一個很好的案例庫,能快速找到場景化的沉澱領域知識,是非常有幫助的。
3. 演算法 –> 落地(面嚮應用工程師)
以往大家覺得演算法落地就是一個類似軟體開發的集成過程,其實對於AI類的應用並非那麼簡單。一般非常通用類的場景下,集成已有的模型去做一些識別比較成熟,如語音識別。但是往往商用類場景下,往往場景的適配度都不夠好,雖然業界都在討論萬物識別的可能,但是都並不如意。所以從對於演算法實際落地而言,都需要基於實際情況去不斷優化。由於需要迭代優化的過程,那麼應用工程師就必須要圍繞思考場景下部署與訓練的業務通路和方便性。一般數據科學家和演算法工程師都是比較稀缺的,讓數據科學家和演算法工程師到每一個現場去做調優實施是不可行的,大量的現場實施工作必須有大量的應用工程師來完成。面嚮應用工程師去自優化模型並且不斷迭代和調整模型的精度將是以往軟體工程不太發生的問題。
所以這往往也需要一個系統體系化的平台,去支撐業務場景的快速迭代,從而提升應用工程師的效率。
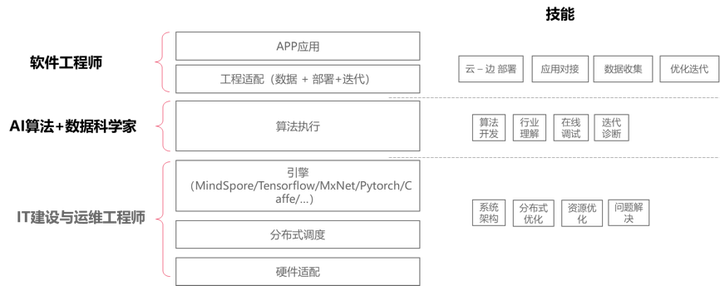
從近20年的自身工作經歷來說,商用落地一個AI業務其實是一項最複雜的系統工程的事情。它不僅僅是一個單獨的演算法開發這麼簡單,圍繞商用AI落地的所需的相關技能特別多。
1、從IT工程師角度上,他需要聚焦資源效率和成本做不同的考慮,圍繞底層資源管理、系統架構設計、分散式優化、資源調度管理、IT建設設計、端-邊-雲的部署與簡便維護等做相應的設計,從而能很好的支撐演算法應用落地;
2、從數據科學家角度上,他不僅僅要懂得去開發一個演算法和參數優化能力,還要對行業場景做深入理解,具備行業Know-how,根據環境和數據的問題,不斷迭代和建模,不斷調整演算法應對環境變化,達成相應的效果,期間會需要關注大量的倫理和道德,包括安全合規,模型的防攻擊和可解釋性類的問題等;
3、從應用工程師角度上,他不僅僅是一個應用集成,需要理解AI應用的不確定性,去選擇合適的場景限制,並且根據實際的情況,去適應已有模型的能力。並且還能夠有獨立進行模型的訓練迭代的能力,通過數據科學家預置好的流水線去迭代,自行現場去優化和迭代。從而達到真實場景下的落地。
綜述,對於很多商業公司而言,他們更聚焦在AI的商用場景上面,往往會忽略AI平台的重要性。但往往對於有前瞻性的商業公司CTO/CIO們,他們都會考慮AI商業落地的時的AI平台選擇。華為雲ModelArts平台的初衷也是聚焦在AI商業落地的困難孕育而生,結合華為自有的昇騰晶片系統,集合ModelArts不斷致力於AI的普惠。
後記
經過幾十年的發展,電腦科學已經成為一門成熟的學科,當前大學電腦系的組織架構圖,每個電腦系大多有三撥人:理論、系統和AI(人工智慧)。20年前的美國電腦圈子曾有一種說法:理論和系統的人互相看不起,但又同時看不起AI的人。AI這幾年火了,但曾經也是被壓迫者。哲學曾經孕育了科學,但一旦問題確定,就分離成為單獨的科學。
正如Allen Newell所言,AI的歷史是一串兒對立議題的鬥爭,如模擬與數字、串列與並行、取代與增強、語法與語義、機械論與目的論、生物學與活力論、工程與科學、符號與連續、邏輯與心理等,在每一個議題下有進一步可分的子議題,如在邏輯與心理下又有定理證明與問題求解等,有爭議才有發展的空間。
我相信這個鬥爭的趨勢依然會存在相當長的一段時間,我們只有適應這樣的鬥爭、進步,不斷增強自己的技術、迎接新技術的挑戰,我們才能保持自己職業生涯的持續前進。因此,你可以利用業界大公司提供的一攬子培訓計劃,不斷加強自己的技術深度,例如華為雲面向所有嚮往AI的開發者,設計了一門優質課程《2020華為雲AI實戰營》,內容包括影像分類、物體檢測、影像分割、人臉識別、OCR、影片分析、自然語言處理和語音識別這8大熱門AI領域的基礎知識、經典數據集和經典演算法的介紹和實踐。每章課程都是由華為雲AI專家精心打造的實戰案例,全流程覆蓋模型訓練、測試、評估,配合程式碼講解和課後作業,幫助您掌握八大熱門AI領域的模型開發能力,轉型成為一名AI開發者。
作者:周明耀,九三學社社員,2004年畢業於浙江大學,工學碩士。現任華為雲AI產品研發總監,著有《大話Java性能優化》、《深入理解JVM&G1 GC》、《技術領導力-如何帶領一支軟體研發團隊》、《程式設計師煉成記》等。職業生涯從軟體工程師起步,後轉為分散式技術工程師、大數據技術工程師,2016年開始接觸AI技術。微訊號michael_tec。



