腦膠質瘤論文筆記
基於深度學習的腦膠質瘤分割方法的研究
針對傳統Unet模型較淺問題解與與二維全卷積神經網路存在的三維空間資訊獲取不足以及三維全卷積神經網路顯示記憶體消耗問題,提出了DM-DA-Unet(Dual Multidimensional Dense Attention Unet,並與ResUnet進行對比。其中DM-DA-Unet加入了Attention,DenseUnet Block 以及多尺度融合等機制,充分提取腦膠質瘤影像的多序列資訊,提高分割精度。
(1)2DResUnet
整體流程為:
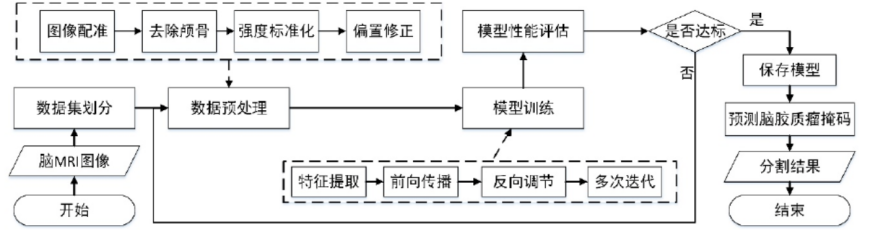
① 該演算法的第一步是對數據進行預處理操作,對於腦膠質瘤的原始 MRI 進行預處理操作,從而消除原始影像採集中影響神經網路訓練的因素,並使影像轉化為模型需要的輸入形式,其主要操作包括影像偏置修正(在核磁共振儀生成 MRI 的過程中,由於機器本身的性能限制以及周圍環境的影響,生成的 MRI 常常出現具有強度不均勻和運動偽影的偏置場效應。這種偏置場效應會導致影像模糊和產生雜訊從而加大影像分割的難度),影像裁剪(去除部分無關背景),影像標準化(使強度變得均勻),隨機取樣(首先,以病人 Flair 序列中標準化後的腦實質區域作為取樣範圍,同時以腦實質區域像素點作為取樣中心,然後根據 2DResUnet 的模型輸入要求,隨機以這些點為中心取 128*128 的小框作為Patch,在 Flair 序列的每層中獲取 3 個 Patch、如果這 3 個 Patch 中存在超出邊界的Patch,則將其丟棄,並在其它層中多取一個符合條件的 Patch,從而使得 Flair 序列中每一層平均獲得 3 個 Patch。接著在病人的其他序列中取相同位置的 Patch,從而獲得大小為 2DResUnet 的輸入數據)等操作
② 為了更好地解決腦膠質瘤分割中類別不均衡且需要對多區域分割的問題,本文在使用 Generalised Dice Loss(Dice Loss一般用作二分類樣本不均勻,不適合用作多分類,因為在訓練過程中,一旦多區域中某個區域的預測結果錯誤,就會出現 Dice Loss 大幅度變化的現象,從而導致梯度變化劇烈,訓練不穩定)作為損失函數的基礎上,再加入了Weighted Cross Entropy(WCE)損失函數。WCE 損失函數是在交叉熵(Cross Entropy)損失函數的基礎上對需要分割的目標區域進行加權,從而加強模型對目標區域的學習。
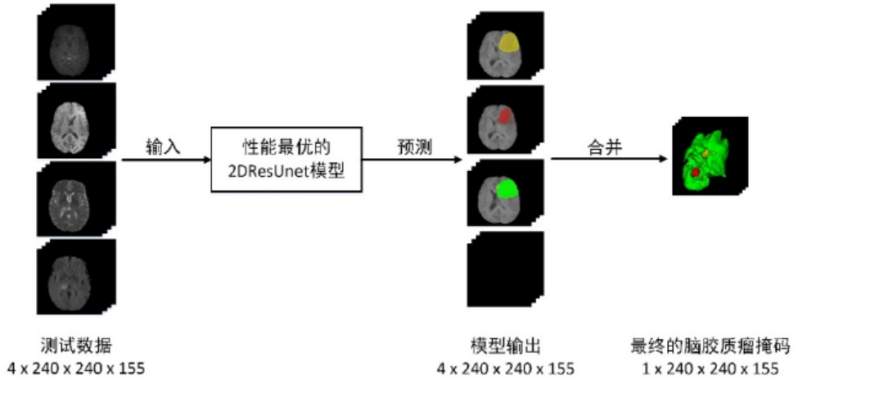
③ 模型的預測:對於 BraTS 數據集而言,原始序列影像大小為 4*240*240*155,因此可以對輸入的多序列影像通過分割效果最好的 2DResUnet 模型進行逐層預測。在對輸入數據的155 層二維影像進行預測的過程中,每一層都會把一個大小為 4*240*240 的數據在數據預處理之後輸入到 2DResUnet 中,並得到輸出大小為 4*240*240 的預測結果。在所有層都經過模型預測之後,再將所有層的預測結果進行疊加,並將多個區域進行合併,從而得到 1*240*240*155 的腦膠質瘤分割掩碼結果。
疑問:為什麼要採用隨機取樣的模式,如果採用隨機取樣,會不會出現取樣的區域沒有包含腫瘤區域,其次,如果採用隨機取樣,對應額掩碼如何處理,如何讓label與input一一對應。
(2)DM-DA-Unet
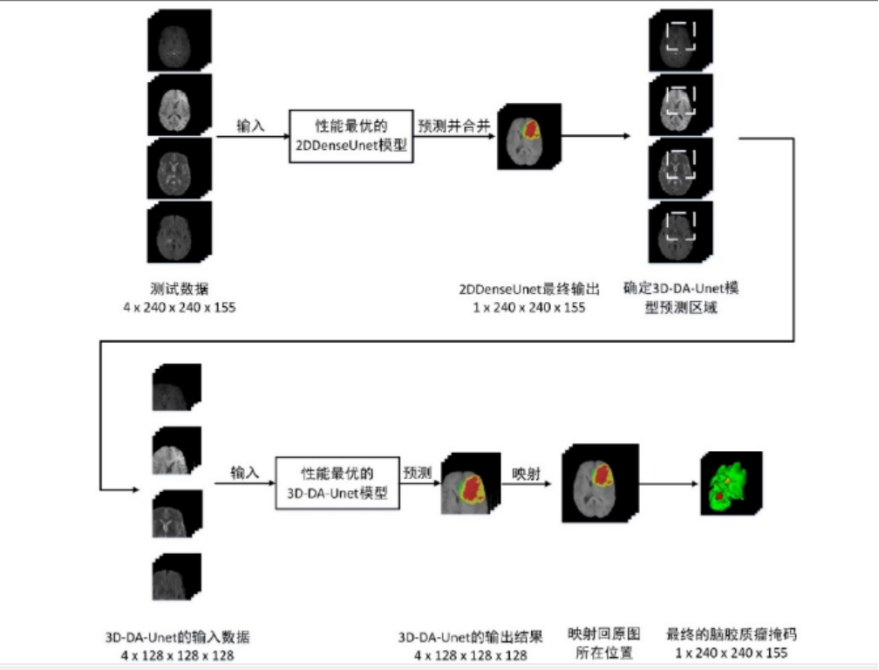
二維的卷積神經網路容易損失腦膠質瘤的空間資訊,但是其消耗顯示記憶體低,預測速度快,靈敏度高,但是如果全程用於三維卷積則對於硬體條件非常高。因此,預測的時候(在訓練的時候是單獨訓練)在第一階段使用2DDenseUnet對腦膠質瘤進行全局定位,將此輸出作為三維卷積的輸入,從而實現腦膠質瘤的精準分割。


Attention 機制由一個主幹分支(Trunk Branch)和一個軟掩碼分支(Soft Mask Brank)
組成,用於融合模型下取樣部分和上取樣部分的特徵。多尺度融合部分是在上取樣的過程中收集各個階段不同尺度的特徵圖,並通過UpScale 將它們的大小縮放為同一尺度並加入到最終輸出的特徵圖中,用於融合多尺度特徵。 在 3D-DA-Unet 中當影像經過三維卷積層之後常常會使用 Instance Nomalization(IN)((由於傳統 BN 層是通過 Batch Size 個數據來計算均值和方差,所以對影像輸入的Batch Size 大小比較敏感。在腦膠質瘤分割中,因為腦膠質瘤影像是多序列影像,如果 Batch Size 太大會造成記憶體泄漏和顯示記憶體不足的情況,所以一般使用較小的 Batch Size 進行訓練和預測,而 Batch Size 太小又會導致 BN 層計算的均值和方差不符合原始影像的分布。因此,在 3D-DA-Unet 中需要使用 IN 層來對輸入影像實例進行標準化,不僅可以加速模型收斂,並且可以保持每個影像實例之間的獨立))層進行特徵歸一化,並使用 Leaky ReLU(由於常用的激活函數 ReLU 是將特徵圖中所有的負值都設為零,而對於經過標準化的腦膠質瘤輸入而言,存在小於 0 的強度值,因此需要使用 Leaky ReLU來給所有負值變數賦予一個非零的斜率,從而消除使用 ReLU 函數帶來的梯度消失現象) 激活函數添加非線性特徵。
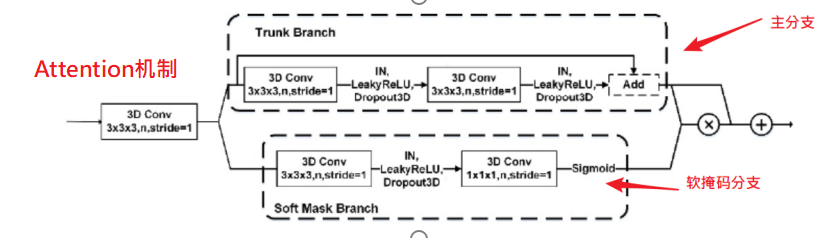
其中,主幹分支用於學習原始特徵,而軟掩模分支則用於減少雜訊和增強特徵。
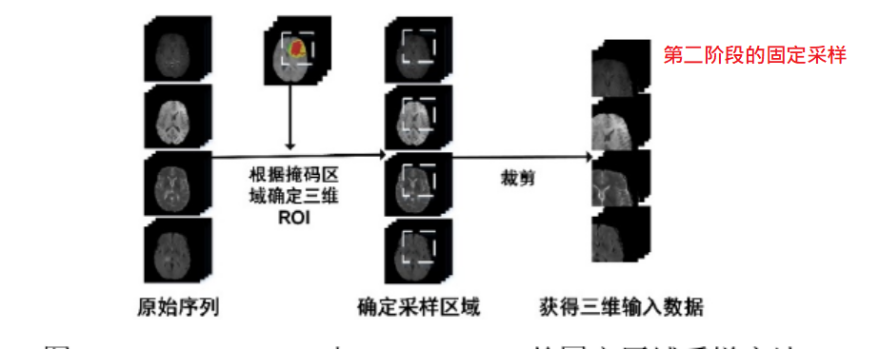
① 數據預處理:在第一階段,對每個序列的每一層進行隨機取樣得到4*128*128大小,在第二階段,通過掩碼獲得感興趣區域(ROI)並適當增大,將增大的ROI區域進行固定區域取樣,即以腦膠質瘤的中心作為ROI的中心,取128*128大小,得到128*128*128的立方體,因此,第二階段的輸入為128*128*128*4
② 標準化:第二階段標準化

對背景添加隨機雜訊,如下圖所示:

③ 數據增強:首先,在 3D-DA-Unet 訓練過程中對輸入的三維立方體數據進行在線數據增強,即對輸入的 4*128*128*128 的數據進行 x,y,z 軸上的三維旋轉,以及 x,y,z 軸上的隨機翻轉等六種增強方式的數據增強,從而得到6*4*128*128*128 的增強數據,並將這些增強數據用於 3D-DA-Unet 模型的訓練。 然後,3D-DA-Unet 對數據的預測過程中,使用與模型訓練過程相同的 6 種隨機增強方式,從而得到 6 個 TTA 增強之後的測試數據,並將 6 個增強之後的數據通過使用 TTA 數據增強訓練得到的模型進行預測,因此得到 6 個預測結果。然後,將這些預測結果還原為同樣的視圖和方向,並對它們進行求和然後取均值,就能得到多個預測結果的融合結果,即 TTA 數據增強的模型預測結果
④ 訓練:二者單獨訓練
⑤ 預測:在第一階段,使用 2DDenseUnet 的網路結構,對需要預測的多序列三維影像進行逐層分割,從而得到 2DDenseUnet 分割的腦膠質瘤掩碼。由於此時獲得的2DDenseUnet 分割掩碼具有很高的敏感性,因此可以通過獲取 2DDenseUnet 掩碼的三維邊界框進而得到腦膠質瘤區域的中心位置,並以該中心位置取一個 128*128*128的三維邊界框,並從 4 個輸入序列中獲得用於下一階段分割的三維數據。 在第二階段,通過第一階段得到的三維邊界框,可以在不同序列上得到相同的三維區域,並通過裁剪得到不同序列的三維立方體。然後,將多個序列的三維立方體作為 3D-DA-Unet 的輸入影像,並將該輸入影像通過 3D-DA-Unet 預測進而得到最終的掩碼,由於在 3D-DA-Unett 網路中採用了三維卷積進行特徵取樣,並使用多視圖融合為基礎的 TTA(Test Time Augment)作為數據增強方式,因此可以很好腦膠質瘤區域的空間資訊,在第一階段獲得的三維區域中對腦膠質瘤區域進行更加精確的分割,獲 4*128*128*128 的腦膠質瘤多區域分割結果,並將三個腦膠質瘤分割區域和背景區域進行融合,從而得到 1*128*128*128 的預測結果。最後,在對腦膠質瘤預測結果進行後處理之後,可以將該結果映射尺寸大小為 240*240*155 的原始影像中,從而獲得最終的腦膠質瘤分割掩碼
參考文獻:基於深度學習的腦膠質瘤分割方法研究_庄宇舟_華中科技大學


