10分鐘了解一致性hash演算法
- 2019 年 10 月 3 日
- 筆記
應用場景
當我們的數據表超過500萬條或更多時,我們就會考慮到採用分庫分表;當我們的系統使用了一台快取伺服器還是不能滿足的時候,我們會使用多台快取伺服器,那我們如何去訪問背後的庫表或快取伺服器呢,我們肯定不會使用循環或者隨機了,我們會在存取的時候使用相同的哈希演算法定位到具體的位置。
簡單的哈希演算法
我們可以根據某個欄位(比如id)取模,然後將數據分散到不同的資料庫或表中。
例如前期規劃,我們某個業務數據5個庫就能滿足了,根據id取模 如下圖
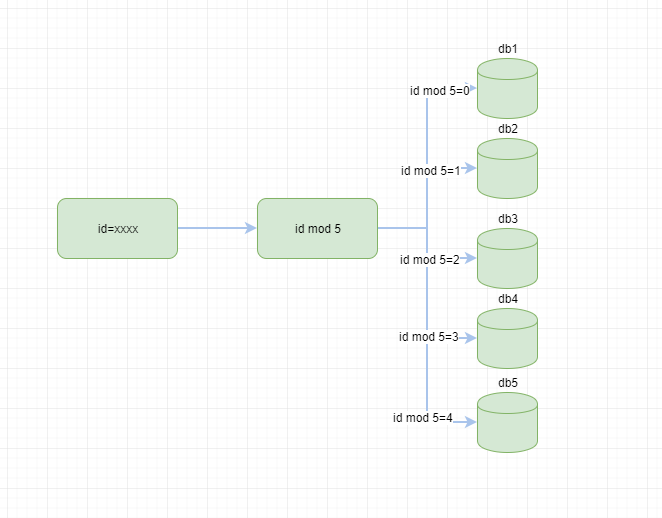
我們通過hash取模很方便的路由到對應的庫上,但是上述的簡單的hash演算法還是有一些缺陷的,假如,5個庫也無法滿足業務的時候,我們需要9個庫,那麼原來的取模公式mod 5要變成 mod 9了,並且大部分數據都要重新分布,涉及到數據轉移工作量也是巨大的。有沒有一勞永逸的方法,答案是有的一致性hash演算法
一致性哈希演算法
演算法概述
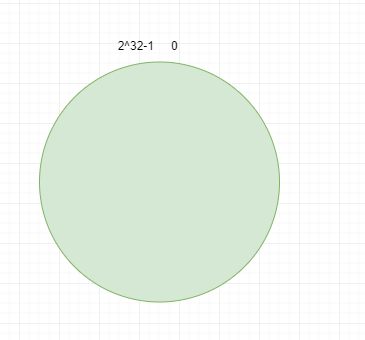
一致性哈希演算法(Consistent Hashing),是MIT的karge及其合作者在1997年發表的學術論文提出的,最早在論文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出。簡單來說,一致性哈希將整個哈希值空間組織成一個虛擬的圓環,如假設某哈希函數H的值空間為0 – 2^32-1(即哈希值是一個32位無符號整形),整個哈希空間環如下:
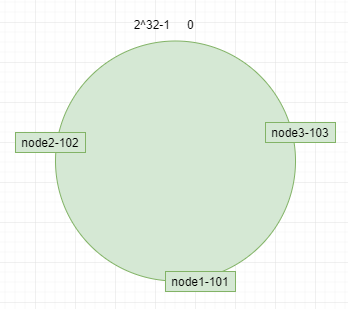
伺服器(ip或者主機名)本身進行哈希,確認每台機器在哈希環上的位置,例如ip:192.168.4.101,192.168.4.102,192.168.4.103 分別對應節點node1-101,node2-102,node3-103 如圖
數據key使用相同的函數計算出哈希值h,根據h確定此數據在環上的位置,從此位置沿環順時針“行走”,最近的伺服器就是其應該定位到的伺服器。 例如 我們使用”10″,”11″,”12″,”13″,”14″ 四個數據對象對應key10,key11,key12,key13,key14,經過哈希計算後,在環空間的位置如下:
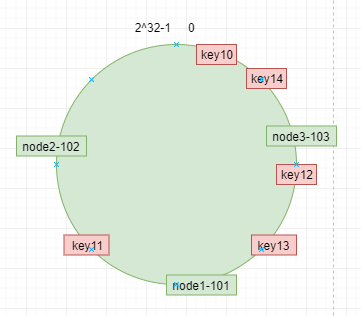
根據一致性哈希演算法,數據key10,key14會被定位到節點node3-103上,key12,key13被定位到節點node1-101上,而key11會被定位到節點node2-102上。
擴展性
節點添加
如果我們新增一個節點node4-104 對應的ip:192.168.4.104通過對應的哈希演算法得到哈希值,並映射到環中,如下圖

通過按順時針遷移的規則,那麼key10被遷移到了node4-104中,其它數據還保持這原有的存儲位置
節點刪除
如果刪除一個節點node3-103,那麼按照順時針遷移的方法,key10,key14將會被遷移到node1-101上,其它的對象沒有任何的改動。如下圖:

如果服務節點太少的時候,會出現數據分配不均,比如極端情況下所有數據都落到node1-101節點上,如何解決數據傾斜問題,需要引入虛擬節點
虛擬節點
如果節點比較少的情況下,在0到2^32-1形成的環中,會出每個節點存放的數據不均勻;一致性哈希演算法提出虛擬節點的解決方案。即虛擬節點時實際節點(物理機器)在hash環中的複製品,一個實際節點對應N多個虛擬節點,這個對應個數也成為了複製個數,虛擬節點在hash環中以hash值排列。
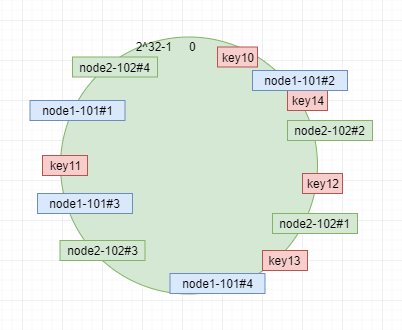
例如 我們以刪除了一個點,只剩下 node1 和node2 兩個節點的圖;我們添加4個虛擬節點,兩個節點 則對應8個節點,最後映射關係 如圖

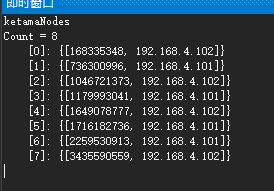
核心程式碼
public class KetamaNodeLocator { private SortedList<long, string> ketamaNodes = new SortedList<long, string>(); private HashAlgorithm hashAlg; private int numReps = 160; public KetamaNodeLocator(List<string> nodes, int nodeCopies) { ketamaNodes = new SortedList<long, string>(); numReps = nodeCopies; //對所有節點,生成nCopies個虛擬結點 foreach (string node in nodes) { //每四個虛擬結點為一組 for (int i = 0; i < numReps / 4; i++) { //getKeyForNode方法為這組虛擬結點得到惟一名稱 byte[] digest = HashAlgorithm.computeMd5(node + i); /** Md5是一個16位元組長度的數組,將16位元組的數組每四個位元組一組,分別對應一個虛擬結點,這就是為什麼上面把虛擬結點四個劃分一組的原因*/ for (int h = 0; h < 4; h++) { long m = HashAlgorithm.hash(digest, h); ketamaNodes[m] = node; } } } } public string GetPrimary(string k) { byte[] digest = HashAlgorithm.computeMd5(k); string rv = GetNodeForKey(HashAlgorithm.hash(digest, 0)); return rv; } string GetNodeForKey(long hash) { string rv; long key = hash; //如果找到這個節點,直接取節點,返回 if (!ketamaNodes.ContainsKey(key)) { //得到大於當前key的那個子Map,然後從中取出第一個key,就是大於且離它最近的那個key 說明詳見: http://www.javaeye.com/topic/684087 var tailMap = from coll in ketamaNodes where coll.Key > hash select new { coll.Key }; if (tailMap == null || tailMap.Count() == 0) key = ketamaNodes.FirstOrDefault().Key; else key = tailMap.FirstOrDefault().Key; } rv = ketamaNodes[key]; return rv; } } public class HashAlgorithm { public static long hash(byte[] digest, int nTime) { long rv = ((long)(digest[3 + nTime * 4] & 0xFF) << 24) | ((long)(digest[2 + nTime * 4] & 0xFF) << 16) | ((long)(digest[1 + nTime * 4] & 0xFF) << 8) | ((long)digest[0 + nTime * 4] & 0xFF); return rv & 0xffffffffL; /* Truncate to 32-bits */ } /** * Get the md5 of the given key. */ public static byte[] computeMd5(string k) { MD5 md5 = new MD5CryptoServiceProvider(); byte[] keyBytes = md5.ComputeHash(Encoding.UTF8.GetBytes(k)); md5.Clear(); //md5.update(keyBytes); //return md5.digest(); return keyBytes; } 最後貼上了實現程式碼,可以運行跑跑,加深理解,希望對您有所幫助,碼字不易請多多支援。
參考
代震軍—-https://www.cnblogs.com/daizhj/archive/2010/08/24/1807324.html
