【真相揭秘】requests獲取網頁編碼亂碼本質
- 2020 年 5 月 28 日
- 筆記
有沒有被網頁編碼抓狂,怎麼轉都是亂碼。
通過查看requests源程式碼,才發現是庫本身歷史原因造成的。
作者是嚴格http協議標準寫這個庫的,《HTTP權威指南》里第16章國際化里提到,如果HTTP響應中Content-Type欄位沒有指定charset,則默認頁面是’ISO-8859-1’編碼。
這處理英文頁面當然沒有問題,但是中文頁面,特別是那些不規範的頁面,就會有亂碼了!
比如分析jd.com 頁面為gbk編碼,問題就出在這裡。
chardet庫監測編碼卻是GB2312,兩種編碼雖然兼容的,但用GB2312解碼gbk編碼的網頁位元組串會運行錯誤!
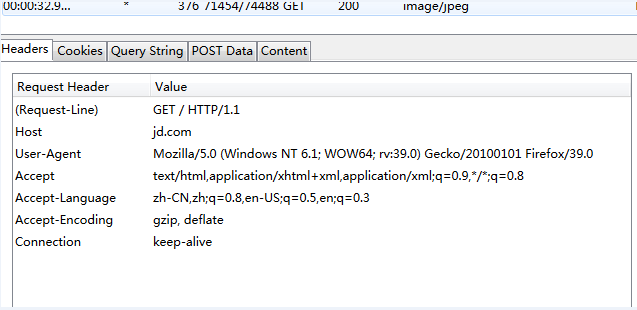

reqponse header只指定了type,但是沒有指定編碼(一般現在頁面編碼都直接在html頁面中)。所有該函數就直接返回’ISO-8859-1’。
# test1
In [1]: r = requests.get('//www.baidu.com/') In [2]: r.encoding Out[2]: 'ISO-8859-1' In [3]: type(r.text) Out[3]: unicode In [4]: type(r.content) Out[4]: str In [5]: r.apparent_encoding Out[5]: 'utf-8' In [6]: chardet.detect(r.content) Out[6]: {'confidence': 0.99, 'encoding': 'utf-8'}
在requests獲取網頁的編碼格式時,有兩種方式encoding和apparent_encoding,結果也不同,
推薦apparent_encoding,常規寫法
url='xxx' req =requests.get(url) req.encoding=req.apparent_encoding print(req.text)
總之一句話,遇到亂碼加上apparent_encoding就完事了。
參考
//www.cnblogs.com/emmm/p/9792832.html
//www.cnblogs.com/bitpeng/p/4748872.html

