學術資訊 | 優Tech分享-To B業務中的影像多標籤識別
- 2020 年 5 月 27 日
- AI



現實生活中,人們通常會使用手機記錄生活,拍攝並保存自己的所見所聞。因此,對相冊中的照片場景及相關進行識別分類,幫助人們更快速整理照片成了一種不可或缺的需求。
判斷拍攝的畫面包含了什麼以及屬於怎樣的場景,就是影像多標籤項目想要做的事。



我們根據相冊中經常出現的畫面選定了上百個標籤,概括一下主要分為以下幾大類標籤 ,例如:
- 人物:成人,合影等
- 動物:貓,狗等,包含長尾標籤,例如具體的貴賓犬、蘇格蘭折耳貓等
- 場景:超市、辦公室、建築等
……

這批標籤存在以下四「非」,是最大的難點所在。
– 標籤非體系化:即層級關係,存在大類和細分類並存情況。例如:貓和蘇格蘭折耳貓。
– 標籤非原子性:類別可能涵蓋的形式種類繁多。例如唱歌的形式多種多樣,單人站立唱歌,多人站立唱歌,多人帶動作唱歌等。
– 標籤非獨立性:即相關關係,存在兩個類別既不互斥也不完全相同的情況。例如繪畫和卡通,如果繪畫恰巧是卡通人物,則也屬於卡通,但是並不是所有的卡通都屬於繪畫。
– 標籤非單一性:即因果關係,存在有一必有二的情況。例如照片中存在森林和叢林,必然存在樹。
一個CV項目的完成,依靠的是數據、演算法、推理三塊能力,接下來也會按照這個順序來依次做詳細的介紹。
本節我們首先展示總結梳理的思維導圖,便於讀者對項目有整體的把握。



為了保證數據集的完整性及多樣性,主要從以下三個方面構建項目數據集。

– Open Images V5:
Open images 數據集是Google提出的數據集,在[OID-dataset]
(//storage.googleapis.com/openimages/web/index.html) 中詳細的介紹了數據集的基本資訊,不僅如此,[OID-paper]
(//arxiv.org/pdf/1811.00982.pdf) 中還詳細地從數據集構造、數據如何標註、模型訓練及測評等多個角度進行了介紹。由於數據全部來自Flickr,因此更符合真實場景。涵蓋8000+類別及900w數據的多標籤數據集,作為項目數據集初始化很適合,而且論文中的方法和經驗也有很多值得借鑒的地方。
– 標籤映射:將OID數據集標籤翻譯並選擇合適標籤映射到項目標籤
– 數據集構建:按照映射,選擇人工標註過的相應數據

– 公開數據集缺陷
由於項目背景是中國場景,OID數據集存在以下三種情況的缺陷:
- 國外不存在一些場景,例如文檔類;
- 場景雖滿足但是全部為國外,存在覆蓋度不足的情況,例如餐廳、博物館等
- 長尾標籤數量較少,例如貓狗細分類
以上三種情況,都需要爬取一定的數據做補充。
– 客戶定義覆蓋度
在和客戶合作中,迭代模型輸出測試結果發現,有些標籤其定義範圍比我們自有情況更大,客戶會提供少量示例圖集,因此也需要爬取數據增大標籤覆蓋度。

部門和公司其他內部合作積累的數據,更符合中國的場景,這部分數據也做相應的標籤映射,用於構造數據集。
主要有以下兩種方式(通過內部工具):
– 關鍵字爬取:輸入標籤名直接進行爬取,並且由標註人員核驗數據是否符合;
– 以圖搜圖式爬取:搜圖,直接上傳示例圖片,標註人員將搜索結果中符合示例圖片的數據爬取保存。
至此,數據集初始化完成,數據量大概在90w的量級,每個數據的標籤量在4個左右。
但是數據集仍然存在很多問題,具體在之後的數據集模組及演算法模組詳細闡述。

一個大數量級的數據集通常存在兩個問題,一個是漏標籤,一個是錯標註。
項目中的數據也存在這樣的情況,而如何做數據清洗去解決這些問題,是改善模型的一個基本關鍵之一。
而面對龐大的數據量,Kaiming He也曾在論文中提到過,當一個標籤的數據量達到某個邊界時,其錯標或漏標對整個模型表現的影響幾乎為0,因此,數據集清洗的流程是要建立在模型已有結果的基礎上的。
這裡先假設已有baseline及相應的測評結果,便可剔除超出臨界點的標籤,將清洗工作專註在部分標籤上。
針對這兩種情況,清洗的方法一致:
– 提取數據
以標籤為單位,提取該標籤下的所有數據。
– 構建偽標籤
對於每一個數據,它的標籤主要可分成如下幾種形式:
- 數據本身的標籤
- baseline模型預測結果top5中高於0.5閾值的標籤
- 競品(主要是百度影像識別API)預測結果映射到項目標籤
– 清洗
- 標註標準:細化並撰寫標註文檔,指定文檔格式,重點對每個標籤特有屬性進行定義及區分,指導標註人員提高關注點。
- 標註可視化:每天隨機可視化標註結果,抽檢並對理解不當標註做強調,將標註準確率控制在90%左右。
- 更新數據集標註

以標籤為基本單位,按照9:1劃分為訓練和驗證集,驗證集即為自有測試集,用於迭代交付中指標的核驗。



這個項目的原有方案為:
將標籤具體分為12個類目,訓練相應的小模型,之後再合併到一起推理出結果。
這種分治的思想不夠適用,是因為標籤本身的特性導致的,因此同時也提到迭代優化難的問題。

我們調研了一些影像多標籤的論文及實際應用場景,發現類似的落地項目很少,大多是在學術的層面進行探討,或者是nlp項目通過BERT等方式做多標籤。
因此,對於這個項目而言,我們可以借鑒的成熟經驗比較少。如何入手,如何做好冷啟動是一個關鍵。
本著less is more的原則,以及對OID論文的研讀,決定baseline先採用如下策略:
– 模型backbone選擇resnet ,該結構在ImageNet2015中大放異彩,其優越的收斂速度以及優化性能(模型速度和精度的平衡)是可以保障模型基本需求。
– 多標籤訓練策略通常是將每一個輸出神經元都看成一個單獨的二分類問題,因此損失函數首先想到二分交叉熵
– 端到端訓練,多機多卡提升速度
具體使用什麼模型,可以先嘗試幾種常見的競賽及論文中提到的模型,再對比所需推理速度和精度,權衡選擇backbone。
模型選定後,訓練出baseline,根據測評結果和交付回饋決定優化方向。


本節提到的都是一些常見的訓練優化策略,可以把這些策略看成是一個個小的部件,但是如何組合及使用這些部件才能達到最好的效果,還是需要一些ablation study驗證。

▶ 3.2.1.1 Learning rate warmup
訓練初期,網路所有的參數都是隨機初始化,和最終參數值相差甚遠。如果初期使用太大的學習率可能會導致數值不穩定。因此,使用warmup策略,使學習率在若干epoch內由0線性增長到設置的數值,這種方式訓練會更加魯棒。
▶ 3.2.1.2 Pretrain model
利用已有的預訓練模型,將大型數據集上訓練好的已有模型知識遷移,幫助模型訓練。
▶ 3.2.1.3 Cosine learning rate decay
訓練過程中的學習率調整是非常重要的。和warmup相配合,能夠達到更好的收斂效果,具體做法是將學習率從指定數值按照coseine的方式降到0。假設總批次數為T,那麼當訓練到第t個批次時,學習率應該是

▶ 3.2.1.4 Multistep learning rate decay
這是一種常見的學習率線性衰減策略,根據其衰減策略也能看出,它很適用於後期模型微調時修改學習率,而且在整個模型已經處於收斂較好的情況下,即最優解附近,優化個別標籤時學習率變化驟降,小步伐抵達最優解很有效。

數據不均衡是一種很常見的現象,現實生活中這些標籤的分布也是呈現某些標籤較多,而其他標籤只是偶爾出現或者長尾的現象。
但是對於神經網路來說,訓練時如果數據不平衡,無論從演算法本身對數據分布要求的角度,還是從損失函數的構建角度,都會對深度模型學習造成嚴重的影響。
上述原因提供了解決的依據,我們從橫向和縱向兩個角度出發,對數據級及特徵級都加入了優化,以達到盡量減小數據不均衡對模型訓練的影響,達到收斂。
▶ 3.2.2.1 橫向——特徵級
Kaiming He在論文中提出Focal loss,一方面,數據分布中存在極度不平衡;另一方面,easy example雖然在後期訓練過程中損失很低,但是由於數量大,對損失的貢獻還是很大導致模型始終向著易學標籤方向收斂。
因此,解決方法如圖所示,簡單直接地在訓練中增加難樣本權重。
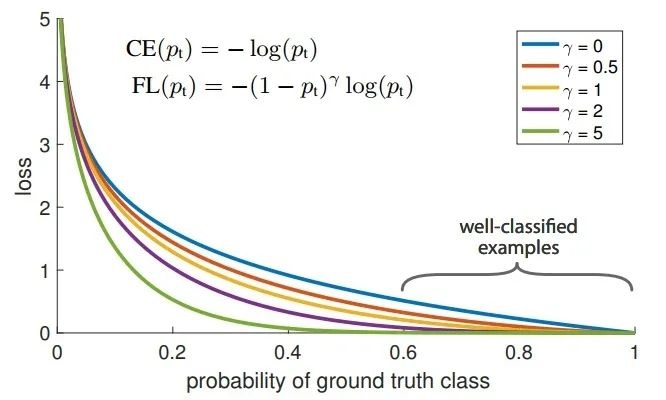
其中,關於超參的選擇需要做ablation study。
▶ 3.2.2.2 縱向——數據級
對於數據本身,我們也可以用一種有效的數據擴增方法,有效的提高不平衡數據中弱勢標籤的頻次,通俗來講,提升標籤的存在感,即resampling。
由於是多標籤識別,因此resampling也需要一定的策略:
– 重複因子設定
- 標籤級:

對於每個標籤來說,至少重複一次,至多重複右側函數返回值次。
- 影像級:多個標籤重複因子的最大值
– resampling函數F選擇
- uniform
函數結果即n本身
- square root
函數結果即為n開根號
上述兩點確認之後,還需要一個閾值,即計算標籤級重複因子公式中包含的t,表徵標籤的目標頻次。
自測及客戶回饋結果可見,上述方法對模型性能的提升,無論是橫向還是縱向都有極大的幫助,以下表格展示了在召回相差不多的情況下,性能提升的對比。


這部分標籤例如眼鏡,通常在一個整體畫面都比較小,雖然神經網路會學到各個標籤之間的一些高級語義關係,但是能力有限,因此這裡需要藉助目標檢測對這類小物體識別做輔助。
由於場景多標籤識別是整個項目的重點,目標檢測部分作為輔助,簡單使用了SSD模型 ,這裡不做太多闡述。

除了深度學習演算法層面可以做的優化,從標籤的特性來看,在後處理中也可以藉助標籤之間的多種關係來補足模型沒有學盡的語義知識,因此,要使用先驗知識構建關係圖譜。
這裡給出關係圖譜的部分示例。

自測及回饋顯示效果顯著,特別對於一些大類標籤(例如運動,因種類繁多而造成特徵不統一,網路難以學習得很好)有極強的提高。
整個迭代過程中都能看出,ToB業務的影像識別項目,需要更加註意和實際場景的結合,其中有很多細節沒有展現,也有很多演算法嘗試沒有提及,這裡僅展示對演算法有效且成功的優化點。一個演算法的優化都是以問題分析作為依託的,了解好背景及現狀,抓住痛點對症下藥,一定是良方。

推理是項目的重點,如何給客戶輸出更佳的預測結果,也是一個需要加入考慮且必不可少的環節。
本文開篇就提到,項目的測評方式很直接,每一類作為單獨的類別,計算準召。
由此可見,在項目的迭代過程中,自測集的構建及乾淨程度對結果尤為重要。
本章假設自測集的乾淨程度在95%左右,即錯誤標籤+漏標籤少於5%,如果沒有達到這個標準,先按照二做相應的清洗。
影像多標籤的輸出有別於單標籤,不是簡單地輸出top1就可以,需要訂製化閾值,每個標籤進行比對再決策輸出結果,這就引出了一個重要的工具:PR曲線。
PR曲線的構造其實是根據測試集中標籤所對應的數據推理結果,不斷選擇梯度閾值而計算所得的結果,如下圖所示。(標籤名做了脫敏處理)

由於是訂製化服務,因此選擇客戶需要的准召對應的閾值即可達到模型的相應性能。例如圖中服裝店,想要達到准召90/50的標準,選擇閾值0.6左右即可。
多種策略相輔相成,最終大大超出客戶預期完成交付。

一個項目的廣度遠不止完成交付,還有極大的空間做擴展:

標籤體系可以由上百類逐步擴充,特別是場景及事件等難識別標籤類。
結合自有標籤(上千類),擴大標籤涵蓋維度,為日常生活場景識別提供更好服務。

根據客戶的具體需求,加強模型對所需類別的敏感度,提供更好的訂製化服務。

- [The Open Images Dataset V4]
- [Deep Residual Learning for Image Recognition]
- [Exploring the Limits of Weakly Supervised Pretraining ]
- [torch.nn.BCEWithLogitsLoss]
- [Bag of Tricks for Image Classification with Convolutional Neural Networks]
- [pytorch model zoo]
- [Must Know Tips/Tricks in Deep Neural Networks]
- [The Impact of Imbalanced Training Data for Convolutional Neural Networks]
- [Focal Loss for Dense Object Detection]
- [sklearn.metrics.precision_recall_curve]
- [SSD: Single Shot MultiBox Detector]




