人工智慧中小樣本問題相關的系列模型演變及學習筆記(三):遷移學習、深度遷移學習
【說在前面】本人部落格新手一枚,象牙塔的老白,職業場的小白。以下內容僅為個人見解,歡迎批評指正,不喜勿噴![握手][握手]
【再啰嗦一下】本文銜接上兩個隨筆:人工智慧中小樣本問題相關的系列模型演變及學習筆記(一):元學習、小樣本學習
【再啰嗦一下】本文銜接上兩個隨筆:人工智慧中小樣本問題相關的系列模型演變及學習筆記(二):生成對抗網路 GAN
一、遷移學習綜述
說到小樣本學習,我也想再說說遷移學習。但是別誤會,遷移學習也並不是只針對小樣本學習,還有很多別的豐富應用。
本文主要參考了一篇綜述:A Survey on Transfer Learning
1. 基本概念
在許多機器學習和數據挖掘演算法中,一個重要的假設就是目前的訓練數據和將來的訓練數據,一定要在相同的特徵空間並且具有相同的分布。然而,在許多現實的應用案例中,這個假設可能不會成立。這種情況下,如果知識的遷移做得成功,我們將會通過避免花費大量昂貴的標記樣本數據的代價,使得學習性能取得顯著的提升。近年來,為了解決這類問題,遷移學習作為一個新的學習框架出現在人們面前。
遷移學習主要有以下三個研究問題:1)遷移什麼,2)如何遷移,3)何時遷移。
- 「遷移什麼」提出了遷移哪部分知識的問題。 一些知識對單獨的域或任務有用,一些知識對不同的領域是通用的,可以用來提高目標域或目標任務的性能。
- 「何時遷移」提出了哪種情況下運用遷移學習。當源域和目標域無關時,強行遷移可能並不會提高目標域上演算法的性能,甚至會損害性能。這種情況稱為負遷移。
- 當前大部分關於遷移學習的工作關注於「遷移什麼」和「如何遷移」,隱含著一個假設:源域和目標域彼此相關。然而,如何避免負遷移是一個很重要的問題。
基於遷移學習的定義,我們歸納了傳統機器學習方法和遷移學習的異同見下表:

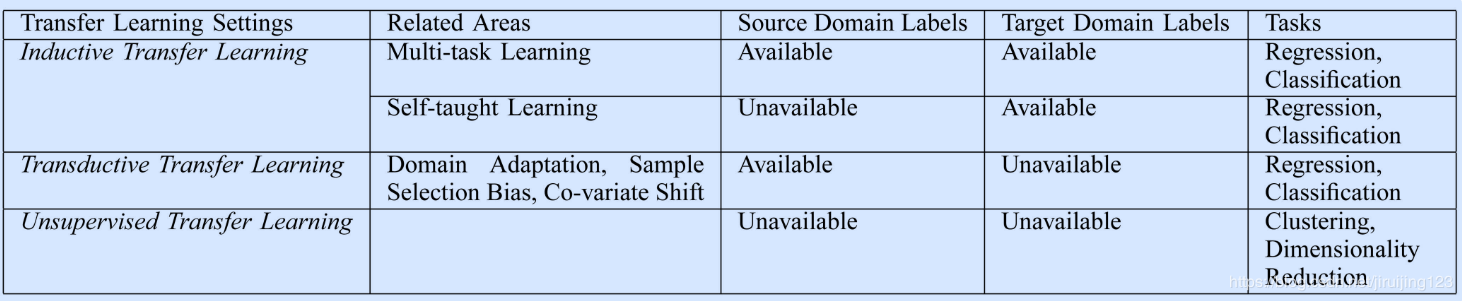
(1)inductive transfer learning:推導遷移學習,也叫歸納遷移學習。其目標任務和源任務不同,無論目標域與源域是否相同。這種情況下,要用目標域中的一些已標註數據生成一個客觀預測模型以應用到目標域中。根據源域中已標註和未標註數據的不同情況,可以進一步將inductive transfer learning分為兩種情況:
- 源域中大量已標註數據可用。這種情況下推導遷移學習和多任務學習類似。然而,推導遷移學習只關注於通過從源任務中遷移知識以便在目標任務中獲得更高性能,然而多任務學習嘗試同時學習源任務和目標任務。
- 源域中無已標註數據可用。這種情況下推導遷移學習和自我學習相似。自我學習中,源域和目標域間的標籤空間可能不同,這意味著源域中的邊緣資訊不能直接使用。因此當源域中無已標註數據可用時這兩種學習方法相似。
(2)transductive transfer learning:轉導遷移學習,也叫直推式遷移學習。其源任務和目標任務相同,源域和目標域不同。這種情況下,目標域中無已標註數據可用,源域中有大量已標註數據可用。根據源域和目標域中的不同狀況,可以進一步將轉導遷移學習分為兩類:
- 源域和目標域中的特徵空間不同
- 源域和目標域間的特徵空間相同,但輸入數據的邊緣概率分布不同。這種情況與自適應學習相關,因為文本分類、樣本選擇偏差和協方差移位中的知識遷移都有相似的假設。
(3)unsupervised transfer learning:無監督遷移學習。與推導遷移學習相似,目標任務與源任務不同但相關。然而,無監督遷移學習專註於解決目標域中的無監督學習問題,例如聚類、降維、密度估計等。這種情況下,訓練中源域和目標域都無已標註數據可用。
2. 遷移學習的分類
上述三種遷移學習可以基於「遷移什麼」被分為四種情況:

(1)Instance-based TL(樣本遷移):可以被稱為基於實例的遷移學習。儘管source domain數據不可以整個直接被用到target domain里,但是在source domain中還是找到一些可以重新被用到target domain中的數據。對它們調整權重,使它能與target domain中的數據匹配之後可以進行遷移。
instance reweighting(樣本重新調整權重)和importance sampling(重要性取樣)是instance-based TL里主要用到的兩項技術。
例如在這個例子中就是找到例子3,然後加重它的權值,這樣在預測的時候它所佔權重較大,預測也可以更準確。

(2)Feature-representation-transfer(特徵遷移):可以被稱為基於特徵表示的遷移學習。找到一些好的有代表性的特徵,通過特徵變換把source domain和target domain的特徵變換到同樣的空間,使得這個空間中source domain和target domain的數據具有相同的分布,然後進行傳統的機器學習就可以了。
特徵變換這一塊可以舉個栗子:比如評論男生的時候,你會說「好帥!好有男人味!好有擔當!」,評論女生的時候,你會說「好漂亮!好有女人味!好溫柔!」可以看出共同的特徵就是「好看」。把「好帥」映射到「好看」,把「好漂亮」映射到「好看」,「好看」便是它們的共同特徵。
(3)Parameter-transfer(參數/模型遷移):可以被稱為基於參數的遷移學習。假設source tasks和target tasks之間共享一些參數,或者共享模型hyperparameters(超參數)的先驗分布。這樣把原來的模型遷移到新的domain時,也可以達到不錯的精度。
(4)Relational-knowledge-transfer(關係遷移):可以被稱為基於關係知識的遷移學習。把相似的關係進行遷移,比如生物病毒傳播到電腦病毒傳播的遷移,比如師生關係到上司下屬關係的遷移。最近,統計關係學習技術主導了這一領域。
3. 小結
綜合第1小節和第2小節的內容,下圖展示了不同遷移學習分類中不同方法的使用情況:

與生成對抗網路GAN一樣,遷移學習同樣可以在很多領域使用,同時,可以與很其他機器學習演算法相結合,道理是相通的。
說到這裡,前面各種方法中的統計學習實現實在是太恐怖了,我只想接下來重點介紹一下深度遷移學習的內容,即深度學習+遷移學習!
4. 「小王愛遷移」系列學習內容:含深度遷移學習!
本小節主要分享一下大佬的知乎專欄的學習內容,主要包括遷移學習領域經典的各大方法,用於輔助對上文的理解:
(1)遷移成分分析(TCA):Domain adaptation via transfer component analysis,2009-2011
主要思想是:屬於基於特徵的遷移學習方法。PCA是一個大矩陣進去,一個小矩陣出來,TCA是兩個大矩陣進去,兩個小矩陣出來。從學術角度講,TCA針對domain adaptation問題中,源域和目標域處於不同數據分布時,將兩個領域的數據一起映射到一個高維的再生核希爾伯特空間。在此空間中,最小化源和目標的數據距離,同時最大程度地保留它們各自的內部屬性。直觀地理解就是,在現在這個維度上不好最小化它們的距離,那麼就找個映射,在映射後的空間上讓它們最接近,那麼不就可以進行分類了嗎?
主要步驟為:輸入是兩個特徵矩陣,首先計算L和H矩陣,然後選擇一些常用的核函數進行映射(比如線性核、高斯核)計算K,接著求的前m個特徵值。然後,得到的就是源域和目標域的降維後的數據,就可以在上面用傳統機器學習方法了。
(2)測地線流式核方法(GFK):Geodesic flow kernel for unsupervised domain adaptation,2011-2012
SGF方法的主要思想:把source和target分別看成高維空間(Grassmann流形)中的兩個點,在這兩個點的測地線距離上取d個中間點,然後依次連接起來。這樣,由source和target就構成了一條測地線的路徑。只需要找到合適的每一步的變換,就能從source變換到target了。
SGF方法的主要貢獻在於:提出了這種變換的計算及實現了相應的演算法。但是它有很明顯的缺點:到底需要找幾個中間點?就是說這個參數d是沒法估計的。
GFK方法解決了SGF的問題:
- 如何確定source和target路徑上中間點的個數。它通過提出一種kernel方法,利用路徑上的所有點的積分,把這個問題解決了。
- 當有多個source的時候,我們如何決定使用哪個source跟target進行遷移?GFK提出Rank of Domain度量,度量出跟target最近的source來解決這個問題。
GFK方法有以下幾個步驟:選擇最優的子空間維度進行變換、構建測地線、計算測地線流式核、以及構建分類器。
(3)聯合分布適配(JDA):Transfer feature learning with joint distribution adaptation,2013
主要思想是:屬於基於特徵的遷移學習方法。是一個概率分布適配的方法,而且適配的是聯合概率。JDA方法同時適配兩個分布,然後非常精巧地規到了一個優化目標里。用弱分類器迭代,最後達到了很好的效果。
和TCA的主要區別有兩點:
- 1)TCA是無監督的(邊緣分布適配不需要label),JDA需要源域有label。
- 2)TCA不需要迭代,JDA需要迭代。
——————————————————————————————-
(4)在線遷移學習:A framework of online transfer learning,2010-2014
這是在線遷移學習研究的第一篇文章,作者分別對同構OTL和異構OTL提出了相應的方法,就是基於SVM以及集成學習進行組合。
基本思想是:先針對可用的源域數據建立一個分類器,然後,每來一個目標域數據,就對這個新數據建立一個分類器,然後與在源域上建立的這個分類器進行組合。
核心問題是:確定源域和新數據分類器各自應該以怎麼樣的權重進行組合。
(5)負遷移:提出「傳遞遷移學習」的解決思路,2015-2017
如果兩個領域之間基本不相似,那麼就會大大損害遷移學習的效果。還是拿騎自行車來說,拿騎自行車的經驗來學習開汽車,這顯然是不太可能的。因為自行車和汽車之間基本不存在什麼相似性。所以,這個任務基本上完不成。這時候,可以說出現了負遷移(negative transfer)。
產生負遷移的原因主要有:
- 源域和目標域壓根不相似,談何遷移?——數據問題
- 源域和目標域是相似的,但是,遷移學習方法不夠好,沒找到可遷移的成分。 ——方法問題
因此,在實際應用中,找到合理的相似性,並且選擇或開發合理的遷移學習方法,能夠避免負遷移現象。
隨著研究的深入,已經有新的研究成果在逐漸克服負遷移的影響:
- 楊強教授團隊2015在數據挖掘領悟頂級會議KDD上發表了傳遞遷移學習文章《Transitive transfer learning》,提出了傳遞遷移學習的思想。
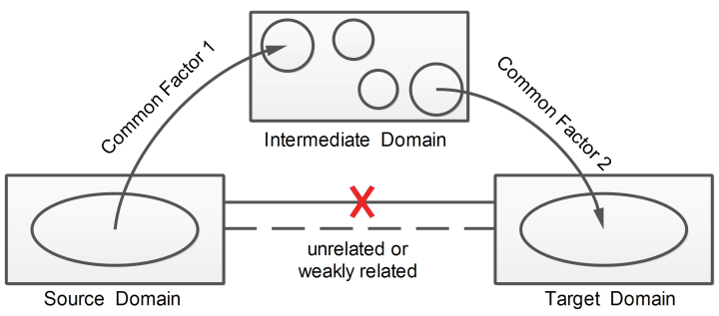
- 楊強教授團隊在2017年人工智慧領域頂級會議AAAI上發表了遠領域遷移學習文章《Distant domain transfer learning》,可以用人臉來識別飛機。
這些研究的意義在於,傳統遷移學習只有兩個領域足夠相似才可以完成,而當兩個領域不相似時,傳遞遷移學習卻可以利用處於這兩個領域之間的若干領域,將知識傳遞式的完成遷移。這個是很有意義的工作,可以視為解決負遷移的有效思想和方法。
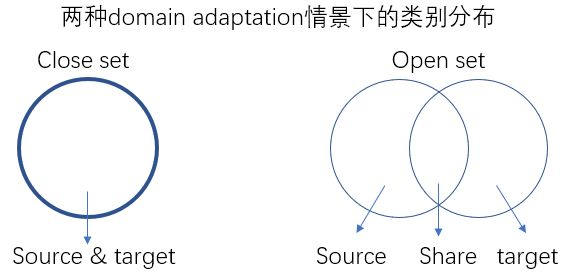
(6)開放集遷移學習:Open Set Domain Adaptation,2017
現有的domain adaptation都針對的是一個「封閉」的任務,就是說,source和target中的類別是完全一樣的,source有幾類,target就有幾類。這些方法都只是理想狀態下的domain adaptation。而真正的環境中,source和target往往只會共享一些類的資訊,而不是全部。
整個文章的解決思路大致是這樣的:
- 利用source和target的關係,給target的樣本打上標籤
- 並將source轉換到和target同一個空間中
兩者依次迭代,直到收斂。作者根據target domain是否有label,把問題分成了unsupervised和semi-supervised domain adaptation,然後分開解決。
(7)張量遷移學習:When Unsupervised Domain Adaptation Meets Tensor Representations,2017
現有的那些domain adaptation方法都只是針對向量(vector)的。而這種表示所帶來的問題就是,當把這些數據應用於高維度表示(如卷積)時,數據首先要經過向量化(vectorization)。此時,無法精準完備地保留一些統計屬性。所以作者提出,不經過向量化來進行domain adaptation的方法,很自然地用到了tensor(張量)。
(8)從經驗中學習遷移:Learning To Transfer,2018
提出了一個新穎的研究問題:類似於增量學習,如何最大限度地利用已有的遷移學習經驗,使得其對新問題的泛化能力很好?同時也可以避免一出現新問題就從頭進行學習。
在解決問題的方法上,雖然用的都是老方法,但是能夠想到新已有方法很好地應用於這個問題。引來的拓展思考:在深度網路中如何持續學習?
(9)探秘任務遷移:Taskonomy: Disentangling Task Transfer Learning,2018
諸如物體識別、深度估計、邊緣檢測等一些常見的電腦視覺任務,彼此之間都或多或少地有一些聯繫。比如,我們很清楚地知道曲面的法線和深度是相關的:它們是彼此的梯度。但與此同時,另一些任務我們卻不清楚,例如,一個房間中的關鍵點檢測和陰影是如何協同工作完成姿態估計的?
已有的相關工作均忽略了這些任務的關聯性,而是單獨地對各個任務進行建模。不利用任務之間的相關性,無疑是十分耗時和複雜的。即使是要在不同的任務之間進行遷移,由於不同任務的不同任務空間之間的聯繫尚不清楚,也無法實現簡單有效的任務遷移。
(10)選擇性對抗遷移學習:Partial Transfer Learning with Selective Adversarial Networks,2018
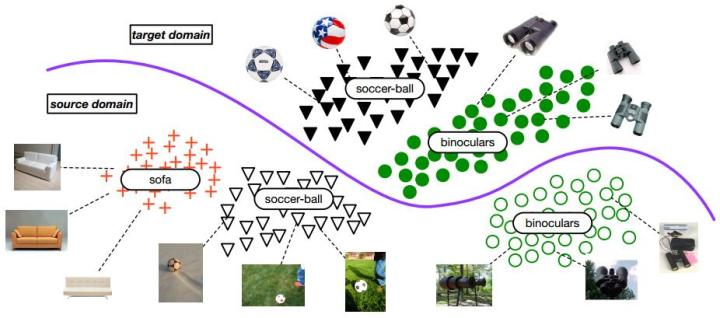
傳統的遷移學習問題情境都是,源域和目標域的類別空間一樣。在大數據時代,通常我們會有大量的源域數據。這些源域數據比目標域數據,在類別上通常都是豐富的。比如基於ImageNet訓練的影像分類器,必然是針對幾千個類別進行的分類。我們實際用的時候,目標域往往只是其中的一部分類別。
因此,就要求相應的遷移學習方法能夠對目標域,選擇相似的源域樣本(類別),同時也要避免負遷移。但是目標域通常是沒有標籤的,不知道和源域中哪個類別更相似。作者指出這個問題叫做partial transfer learning(部分遷移學習)。
(11)聯邦遷移學習:2018
事實上,Google在2017年的一篇論文里進行了去中心化的推薦系統建模研究。其核心是,手機在本地進行模型訓練,然後僅將模型更新的部分加密上傳到雲端,並與其他用戶的進行整合。一些研究者也提出了CryptoDL深度學習框架、可擴展的加密深度方法、針對於邏輯回歸方法的隱私保護等。但是,它們或只能針對於特定模型,或無法處理不同分布數據。
正是為了解決上述這些挑戰,香港科技大學楊強教授和微眾銀行AI團隊,最近提出了聯邦遷移學習 (Federated Transfer Learning, FTL)。FTL將聯邦學習的概念加以推廣,強調在任何數據分布、任何實體上,均可以進行協同建模學習。
這項工作在中國,是楊教授與微眾銀行AI團隊主導,目的是建立數據聯邦,以解決大數據無法聚合的問題。在國外,目前是Google在進行相關的研究。二者的區別:微眾銀行AI團隊的做法是,用戶維度部分重疊,特徵維度不重疊;而Google則是反過來:特徵重疊,用戶不重疊。
聯邦遷移學習 vs 遷移學習 vs 多任務學習
- 多任務學習和FTL都注重多個任務的協同學習,最終目標都是要把所有的模型變得更強。但是,多任務學習強調不同任務之間可以共享訓練數據,破壞了隱私規則。而FTL則可以在不共享隱私數據的情況下,進行協同的訓練。
- 遷移學習注重知識從一個源領域到另一個目標領域的單向遷移。而這種單向的知識遷移,往往伴有一定的資訊損失,因為通常只會關注遷移學習在目標領域上的效果,而忽略了在源領域上的效果。FTL則從目標上就很好地考慮了這一點,多個任務之間協同。
- 遷移學習和多任務學習都可以解決模型和數據漂移的問題,這一點在FTL中也得到了繼承。
——————————————————————————————-
(12)深度神經網路的可遷移性:How transferable are features in deep neural networks,2014
深度網路的一個事實:前面幾層都學習到的是通用的特徵(general feature),後面的網路更偏重於學習特定的特徵(specific feature)。
雖然該論文並沒有提出一個創新方法,但是通過實驗得到了以下幾個結論,對以後的深度學習和深度遷移學習都有著非常高的指導意義:
- 神經網路的前3層基本都是general feature,進行遷移的效果會比較好。
- 深度遷移網路中加入fine-tune,效果會提升比較大,可能會比原網路效果還好。
- Fine-tune可以比較好地克服數據之間的差異性。
- 深度遷移網路要比隨機初始化權重效果好。
- 網路層數的遷移可以加速網路的學習和優化。
(13)深度遷移學習:例如DaNN、DDC、DAN等,2014-2015
DaNN(Domain Adaptive Neural Network)的結構異常簡單,它僅由兩層神經元組成:特徵層和分類器層。作者的創新工作在於,在特徵層後加入了一項MMD適配層,用來計算源域和目標域的距離,並將其加入網路的損失中進行訓練。所以,整個網路的優化目標也相應地由兩部分構成:在有label的源域數據上的分類誤差,以及對兩個領域數據的判別誤差。
但是,由於網路太淺,表徵能力有限,故無法很有效地解決domain adaptation問題(通俗點說就是精度不高)。因此,後續的研究者大多數都基於其思想進行擴充,例如將淺層網路改為更深層的AlexNet、ResNet、VGG等,例如將MMD換為多核的MMD等。
DDC(Deep Domain Confusion)針對預訓練的AlexNet(8層)網路,在第7層(也就是feature層,softmax的上一層)加入了MMD距離來減小source和target之間的差異。這個方法簡稱為DDC。下圖是DDC的演算法插圖。
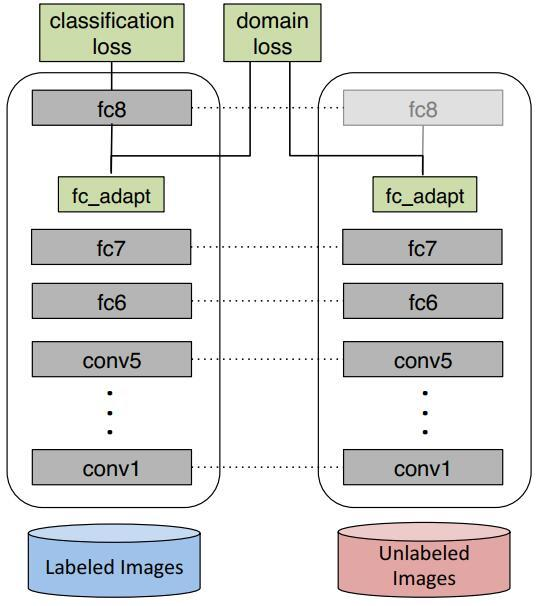
從上圖可以很明顯地看出,DDC的思想非常簡單:在原有的AlexNet網路的基礎上,對網路的fc7層(分類器前一層)後加一層適配層(adaptation layer)。適配層的作用是,單獨考察網路對源域和目標域的判別能力。如果這個判別能力很差,那麼我們就認為,網路學到的特徵不足以將兩個領域數據區分開,因而有助於學習到對領域不敏感的特徵表示。
DAN(Deep Adaptation Network)是在DDC的基礎上發展起來的,它很好地解決了DDC的兩個問題:
- 一是DDC只適配了一層網路,可能還是不夠,因為Jason的工作中已經明確指出不同層都是可以遷移的,所以DAN就多適配幾層。
- 二是DDC是用了單一核的MMD,單一固定的核可能不是最優的核。DAN用了多核的MMD(MK-MMD),效果比DDC更好。
DAN的創新點是多層適配和多核MMD。下圖是DAN的網路結構示意圖。
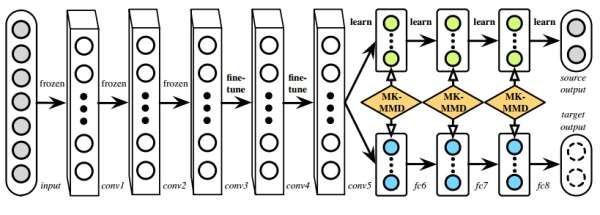
DDC和DAN作為深度遷移學習的代表性方法,充分利用了深度網路的可遷移特性,然後又把統計學習中的MK-MMD距離引入,取得了很好的效果。DAN的作者在2017年又進一步對其進行了延伸,做出了Joint Adaptation Network (JAN),進一步把feature和label的聯合概率分布考慮了進來,可以視作之前JDA(joint distribution adaptation)的深度版。
(14)深度遷移學習文章解讀:Simultaneous Deep Transfer Across Domains and Tasks,2015
針對情況:target的部分class有少量label,剩下的class無label。文章最大的創新點是:現有的方法都是domain classifier加上一個domain confusion,就是適配。作者提出這些是不夠的,所以提出了還要再加一個soft label loss。意思就是在source和target進行適配的時候,也要根據source的類別分布情況來進行調整target的。其實本意和JDA差不多。
網路結構如下圖所示。網路由AlexNet修改而來,前面的幾層都一樣,區別只是在第fc7層後面加入了一個domain classifier,也就是進行domain adaptation的一層,在fc8後計算網路的loss和soft label的loss。就現在的研究成果看來,絕大多數也都是在深度網路後加一些相關的loss層,以之來提高網路的適配性。本質並沒有很大的創新性。
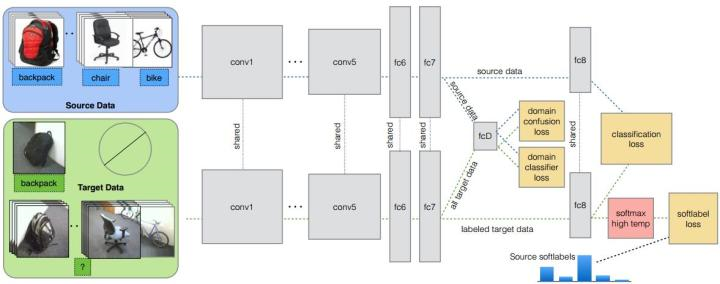
(15)深度遷移度量學習:Deep Transfer Metric Learning,2015
已有的metric learning研究大多數集中在傳統方法和深度方法中,它們已經取得了長足的進步。但是這些單純的度量研究,往往只是在數據分布一致的情況下有效。如果數據分布發生了變化,已有的研究則不能很好地進行處理。因此,遷移學習就可以作為一種工具,綜合學習不同數據分布下的度量,使得度量更穩定。
另一方面,已有的遷移學習工作大多都是基於固定的距離,例如MMD,因此無法學習到更好的距離表達。雖然近年來有一些遷移度量學習的工作,但它們都只考慮在數據層面將特徵分布差異減小,而忽略了在源領域中的監督資訊。因而,作者提出要在深度遷移網路中對度量進行學習,有效利用源領域中的監督資訊,學習到更泛化的距離表達。
(16)用於部分遷移學習的深度加權對抗網路:Importance Weighted Adversarial Nets for Partial Domain Adaptation,2018
作者提出了一個深度加權對抗網路,如下圖所示。網路的主要部分是:分別作用於源域和目標域的兩個特徵提取器(分別叫做 和
),以及兩個領域分類器(分別叫做
和
)。第一個領域分類器用來篩選出源域中與目標域相似的那部分樣本(或者源域中與目標領域共享的那部分類別),第二個領域分類器進行正常的domain adaptation。

本文核心創新點是,從任務出發,直觀地構造出兩階段式對抗網路,對源域中與目標域共享的類別樣本進行有效篩選。另一個與已有工作不同的地方是,作者分別對源域和目標域採用了不同的特徵提取器。
(17)基於條件對抗網路的領域自適應:Conditional Adversarial Domain Adaptation,2018
Domain adaptation問題一直以來是遷移學習和電腦視覺領域等的研究熱點。從傳統方法,到深度方法,再到最近的對抗方法,都在嘗試解決此問題。作者在本文中提出,現在的對抗方法面臨兩個挑戰:
- 一是當數據特徵具有非常複雜的模態結構時,對抗方法無法捕獲多模態的數據結構,容易造成負遷移。
- 二是當上面的問題存在時,domain classifier就很容易出錯,所以造成遷移效果不好。
本文提出了基於條件對抗網路的領域自適應方法,主要由Condition + Adversarial + Adaptation這三部分構成。進行condition的時候,用到了一個叫做multilinear map的數學工具,主要是來刻畫多個特徵和類別之間的關係。
(18)深度遷移學慣用於時間序列分類:Transfer learning for time series classification,2018
基本方法與在影像上進行深度遷移一致,先在一個源領域上進行pre-train,然後在目標領域上進行fine-tune。
網路的結構如下圖所示。網路由3個卷積層、1個全局池化層、和1個全連接層構成。使用全連接層的好處是,在進行不同輸入長度序列的fine-tune時,不需要再額外設計池內化層。
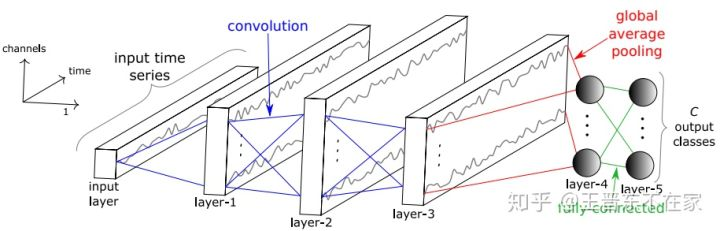
與影像的區別就是,輸入由圖片換成了時間序列。注意到,圖片往往具有一定的通道數(如常見的R、G、B三通道)。時間序列也有通道,即不同維的時間序列數據。最簡單的即是1維序列,可以認為是1個通道。多維時間序列則可以認為是多個通道。
(19)最大分類器差異的領域自適應:Maximum Classifier Discrepancy for Unsupervised Domain Adaptation,2018
方法的主要思想非常簡單:用源域訓練的網路如果用到目標域上,肯定因為目標域與源域的不同,效果也會有所不同。效果好的我們就不管了,重點關注效果不好的,因為這才能體現出領域的差異性。為了找到這些效果差的樣本,作者引入了兩個獨立的分類器 和
,用二者的分歧表示樣本的置信度不高,需要重新訓練。

(20)異構網路的遷移:Learn What-Where to Transfer,2019
本文另闢蹊徑,從根源上研究不同架構的深度網路如何進行遷移,並提供了行之有效的解決方案。
深度網路都是對遷移學習最為友好的學習架構。從最簡單的finetune(微調),到固定網路的特徵提取層不變在倒數第二層加入可學習的距離,再到通過領域對抗的思想學習隱式分布距離,深度遷移學習方法大行其道。在諸多影像分類、分割檢測等任務上取得了不錯的效果。
縱觀這些方法的思路,大多均逃脫不開一個固有的模式:源域和目標域的網路架構完全相同,固定前若干層,微調高層或在高層中加入分布適配距離。然而,在遷移模型變得越來越臃腫、特定數據集精度不斷攀升的同時,極少有人想過這樣一個問題:
- 這種固定+微調的模式是否是唯一的遷移方法?
- 如果2個網路結構不同(比如),則上述模式直接失效,此時如何做遷移?
本文將這一思路具體表述為2點:What to transfer和Where to transfer
- What部分解決網路的可遷移性:源域中哪些層可以遷移到目標域哪些層?
- Where部分解決網路遷移多少:源域中哪些層的知識遷移多少給目標域的哪些層?
簡單來說就是:學習源域網路中哪些層的知識可以遷移多少給目標域的哪些層。
二、深度遷移學習綜述
說到遷移學習,我想最時髦的就是深度遷移學習了。有了深度學習的加持,遷移學習在人工智慧領域有著豐富的應用。
上一節的內容其實已經包含了深度遷移學習的很多方法,包括非常多的idea,本節就作為輔助理解用吧!
本文參考了一篇綜述:A Survey on Deep Transfer Learning
這裡強推大佬的知乎專欄和guthub://github.com/jindongwang/transferlearning
1. 基本概念
深度遷移學習是通過深度神經網路研究如何利用其他領域的知識。隨著深度神經網路在各個領域的廣泛應用,大量的深度遷移學習方法被提出。包括離線/在線、增量學習、生成對抗、同構/異構等,可以說是非常豐富。
2. 深度遷移學習的分類
本文將深度遷移學習分為四類:基於實例的深度遷移學習、基於映射的深度遷移學習、基於網路的深度遷移學習和基於對抗的深度遷移學習。

(1)基於實例的深度遷移學習。與遷移學習分類中的第一類是一致的,這裡不再贅述。

(2)基於映射的深度遷移學習。與遷移學習分類中的第二類是一致的,這裡不再贅述。
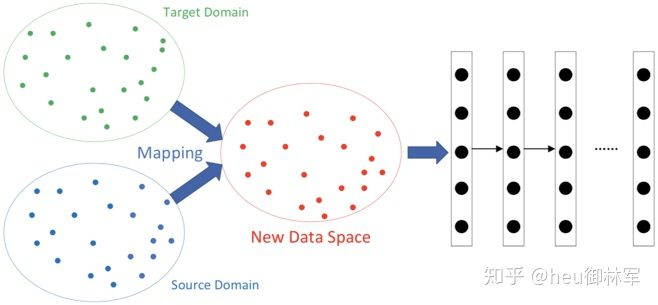
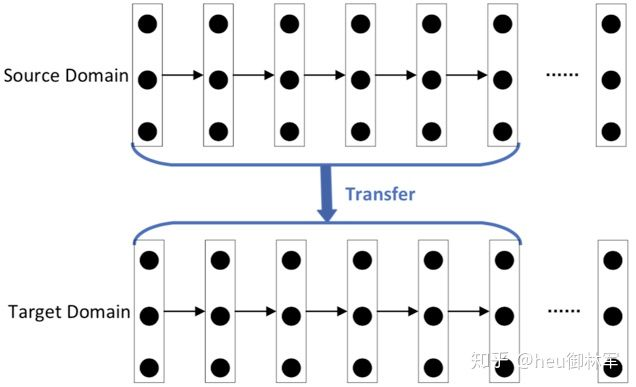
(3)基於網路的深度遷移學習。將原領域中預先訓練好的部分網路,包括其網路結構和連接參數,重新利用,將其轉化為用於目標領域的深度神經網路的一部分。
(4)基於對抗的深度遷移學習。在生成對抗網路 GAN 的啟發下,引入對抗性技術,尋找既適用於源域又適用於目標域的可遷移表達。

負遷移和可遷移性測度是傳統遷移學習中的重要問題。如何利用深度神經網路在無監督或半監督學習中進行知識的遷移會受到越來越多的關注。
補充一點,元學習與遷移學習的區別聯繫是什麼?
- 元學習關注的是一組任務T~p(T),元學習的目標是從T1,T2…中不斷學習,從中學到更通用的知識,從而具有適應新任務Ti的能力,它關注的是任務T到Ti這個過程。
- 遷移學習通常只有一個源域A(當然可以有多個),一個目標域B,目標是學習A到B的遷移,更關注的是A到B的這個過程。
當然,兩者有很多重疊之處,要結合著看,互相補充,互相學習。
歡迎持續關注我的下一篇隨筆:人工智慧中小樣本問題相關的系列模型演變及學習筆記(四):知識蒸餾、增量學習
如果您對異常檢測感興趣,歡迎瀏覽我的另一篇部落格:異常檢測演算法演變及學習筆記
如果您對智慧推薦感興趣,歡迎瀏覽我的另一篇部落格:智慧推薦演算法演變及學習筆記 、CTR預估模型演變及學習筆記
如果您對知識圖譜感興趣,歡迎瀏覽我的另一篇部落格:行業知識圖譜的構建及應用、基於圖模型的智慧推薦演算法學習筆記
如果您對時間序列分析感興趣,歡迎瀏覽我的另一篇部落格:時間序列分析中預測類問題下的建模方案 、深度學習中的序列模型演變及學習筆記
如果您對數據挖掘感興趣,歡迎瀏覽我的另一篇部落格:數據挖掘比賽/項目全流程介紹 、機器學習中的聚類演算法演變及學習筆記
如果您對人工智慧演算法感興趣,歡迎瀏覽我的另一篇部落格:人工智慧新手入門學習路線和學習資源合集(含AI綜述/python/機器學習/深度學習/tensorflow)、人工智慧領域常用的開源框架和庫(含機器學習/深度學習/強化學習/知識圖譜/圖神經網路)
如果你是電腦專業的應屆畢業生,歡迎瀏覽我的另外一篇部落格:如果你是一個電腦領域的應屆生,你如何準備求職面試?
如果你是電腦專業的本科生,歡迎瀏覽我的另外一篇部落格:如果你是一個電腦領域的本科生,你可以選擇學習什麼?
如果你是電腦專業的研究生,歡迎瀏覽我的另外一篇部落格:如果你是一個電腦領域的研究生,你可以選擇學習什麼?
如果你對金融科技感興趣,歡迎瀏覽我的另一篇部落格:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之後部落客將持續分享各大演算法的學習思路和學習筆記:hello world: 我的部落格寫作思路


