Python一鍵獲取日漫Top100榜單電影資訊
最近看到一個 UP 主做的影片,使用可視化動態圖,把目前播放量最多的 UP 主一一列出來,結果第一名是嗶哩嗶哩番劇,第一名的播放量是第二名近 10 倍。
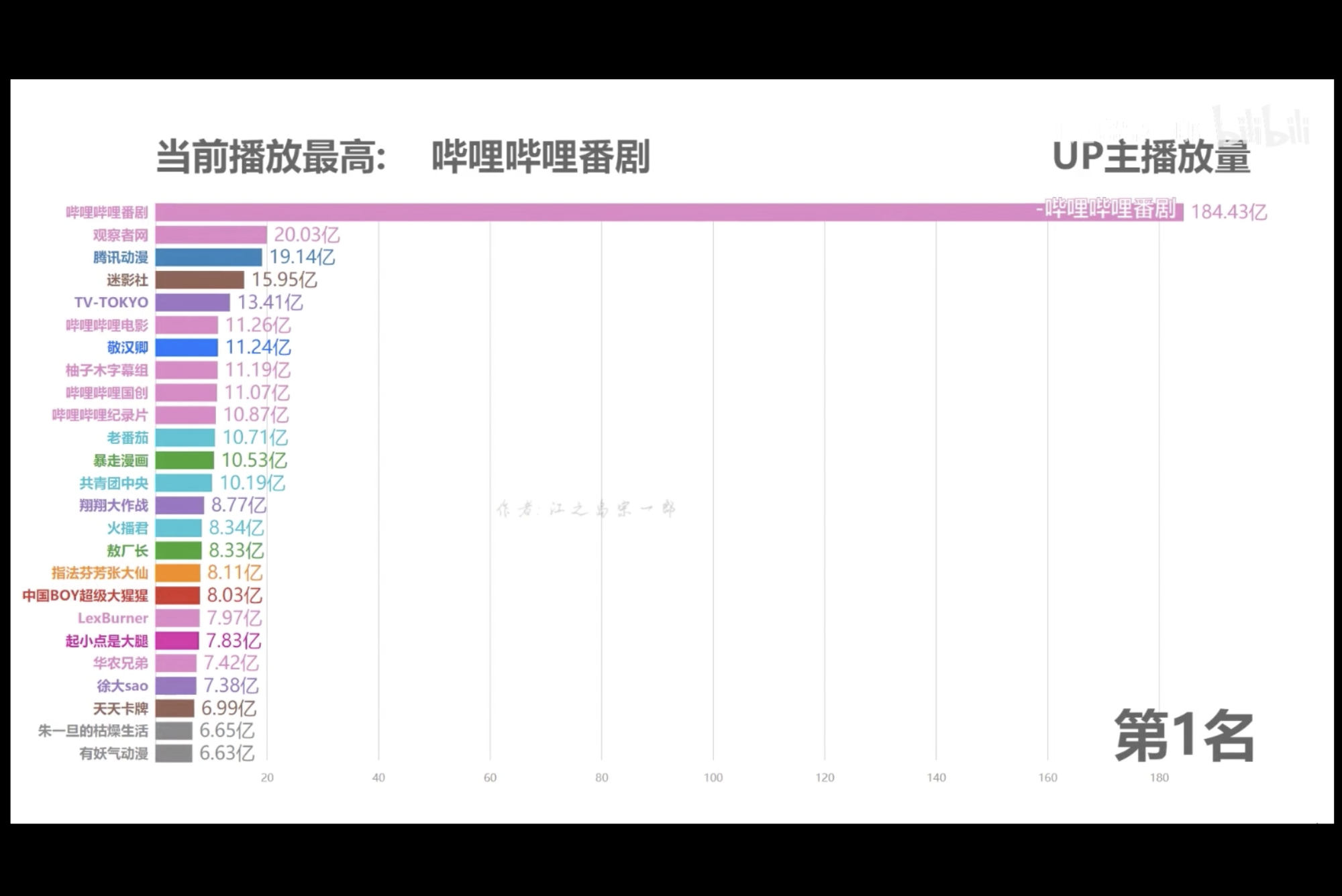
B站的番劇數量,也是相對其他平台比較多的,而且品質都還不錯。說實話,剛開始用嗶哩嗶哩的時候,就是為了看番劇。作為一個喜歡看番劇的 pk 哥,我決定用爬蟲爬取一下日本動漫電影 TOP100 都有哪些?網上看了一下,時光網正好有這個排行榜,而且資訊相對來說比較全。
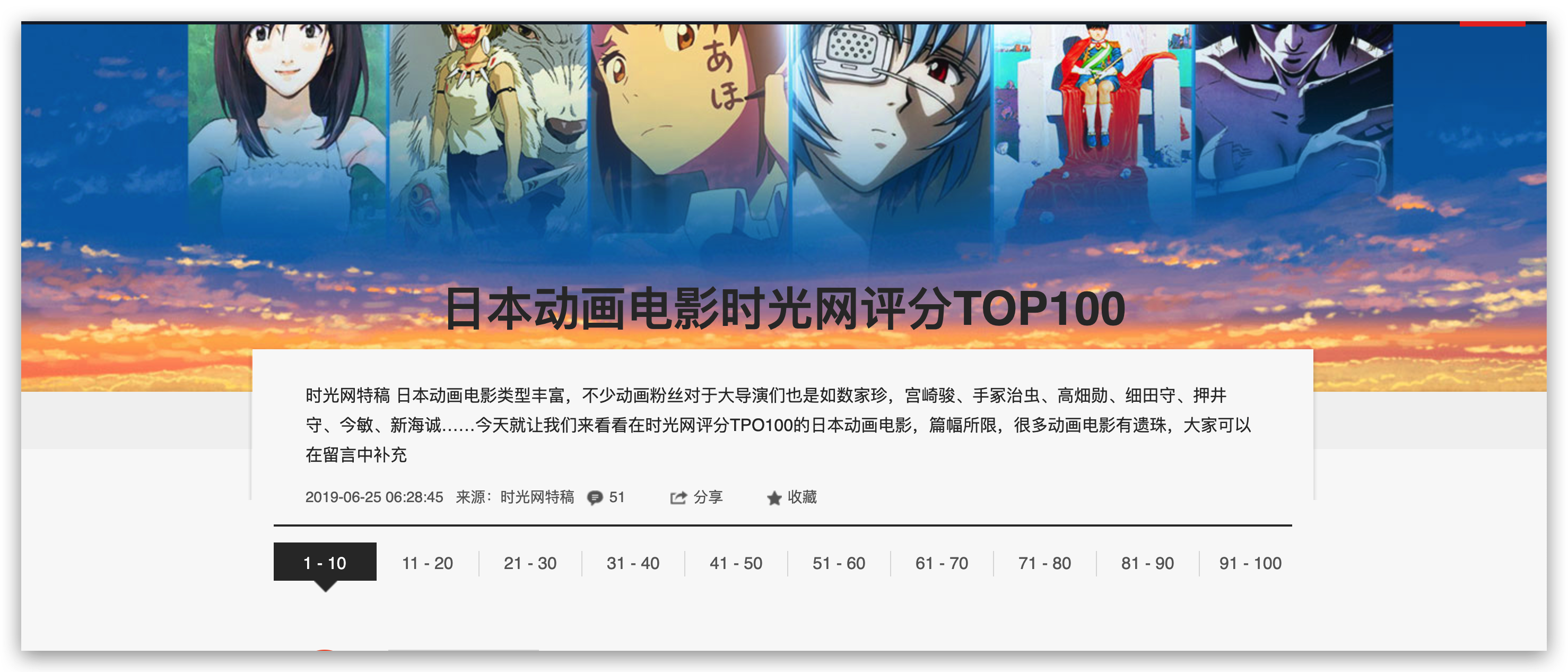
所以我決定用爬蟲把這個榜單上 Top100 的所有電影資訊全部保存為 csv 文件放在本地,看有沒有之前我遺漏的經典動漫電影。
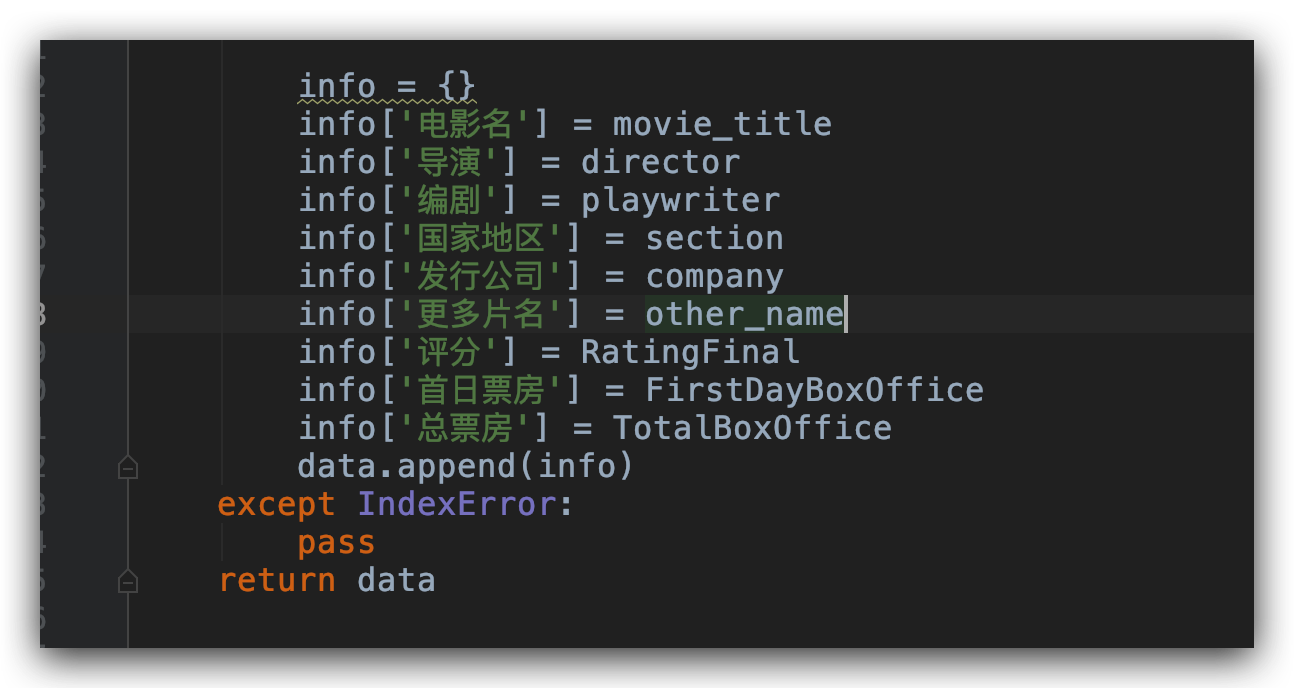
以下是保存的效果。保存的列包括電影名稱、導演編劇、發行公司、更多片名、評分、首日票房、總票房。有些電影沒有評分和票房資訊的就直接顯示為空。

獲取電影ID資訊
本次爬蟲項目主要分為三個部分。第一部分我們要獲取電影的 Id資訊,因為我們需要保存的所有資訊,都和這個有關。Id從哪裡獲取呢?我們打開這個榜單頁面的源程式碼。源程式碼中我們可以看到,id都在鏈接後面。

為了縮小範圍,我們發現這些鏈接都在 class=top_nlist 裡面,我們用 beautifulsoup 庫提取屬性 class= top_nlist 所有的元素。然後用正則表達式,提取出每頁的 id資訊。
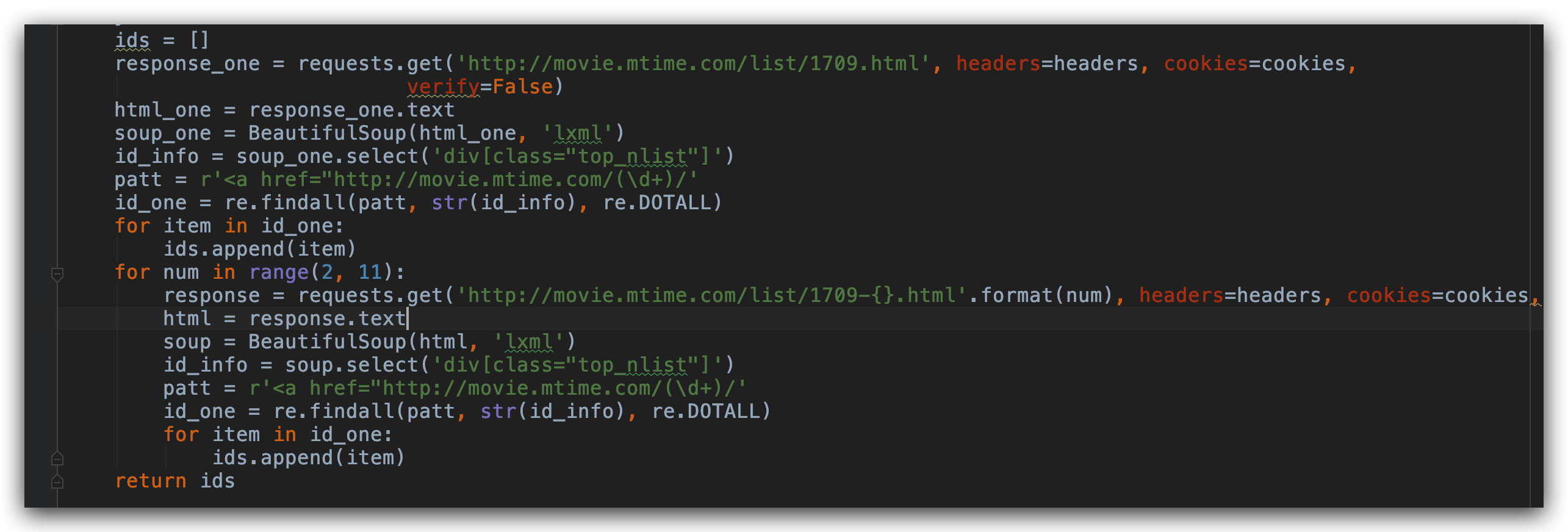
這裡第 1 個頁面需要特殊處理一下,因為第 2 個頁面到第 10 個頁面後面都是直接帶的數字,第 1 個頁面直接我在後面加 -1 的話會報 404,所以這個頁面單獨拿出來提取頁面資訊。然後再把 ID 資訊全部加到空列表裡面。
提取評分和票房資訊
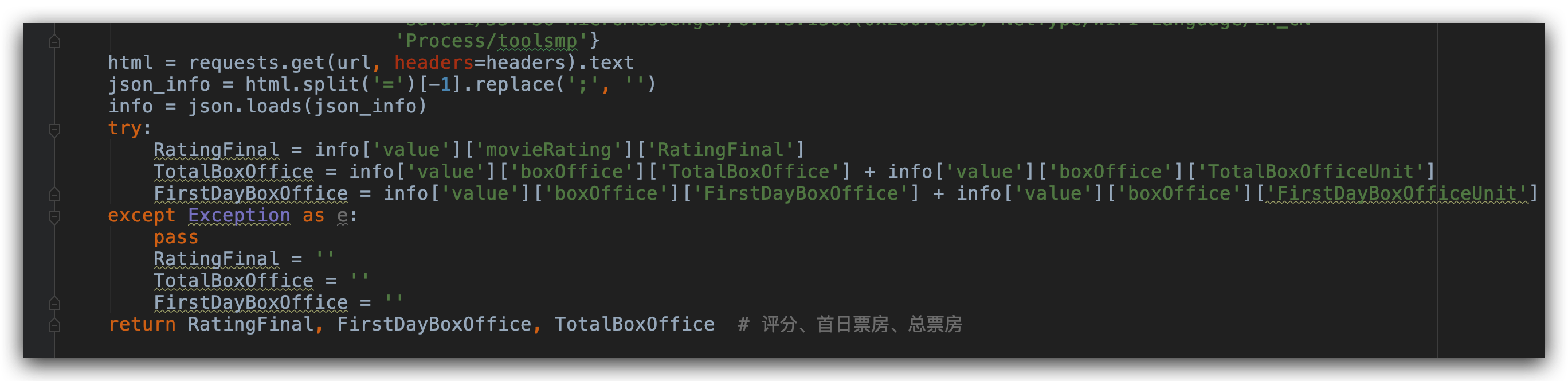
ID 資訊獲取了,接下來我們通過 ID 資訊來獲取電影的評分和票房資訊。通過 F12 調試我們可以看到。評分和票房資訊在 js 裡面。

請求鏈接里變化的就是電影的 ID ,其他的保持不變就好。
我們對返回資訊通過簡單的處理轉換為 Json 格式。之後我們就可以直接通過 key 值提取 value 值了。這裡主要提取的資訊有:評分、首日票房和總票房。
提取其他電影詳細資訊
接下來我們需要通過 ID 資訊獲取對應電影的名稱和導演編劇等詳細資訊。這些資訊在源程式碼中,可以直接通過正則表達式來提取。
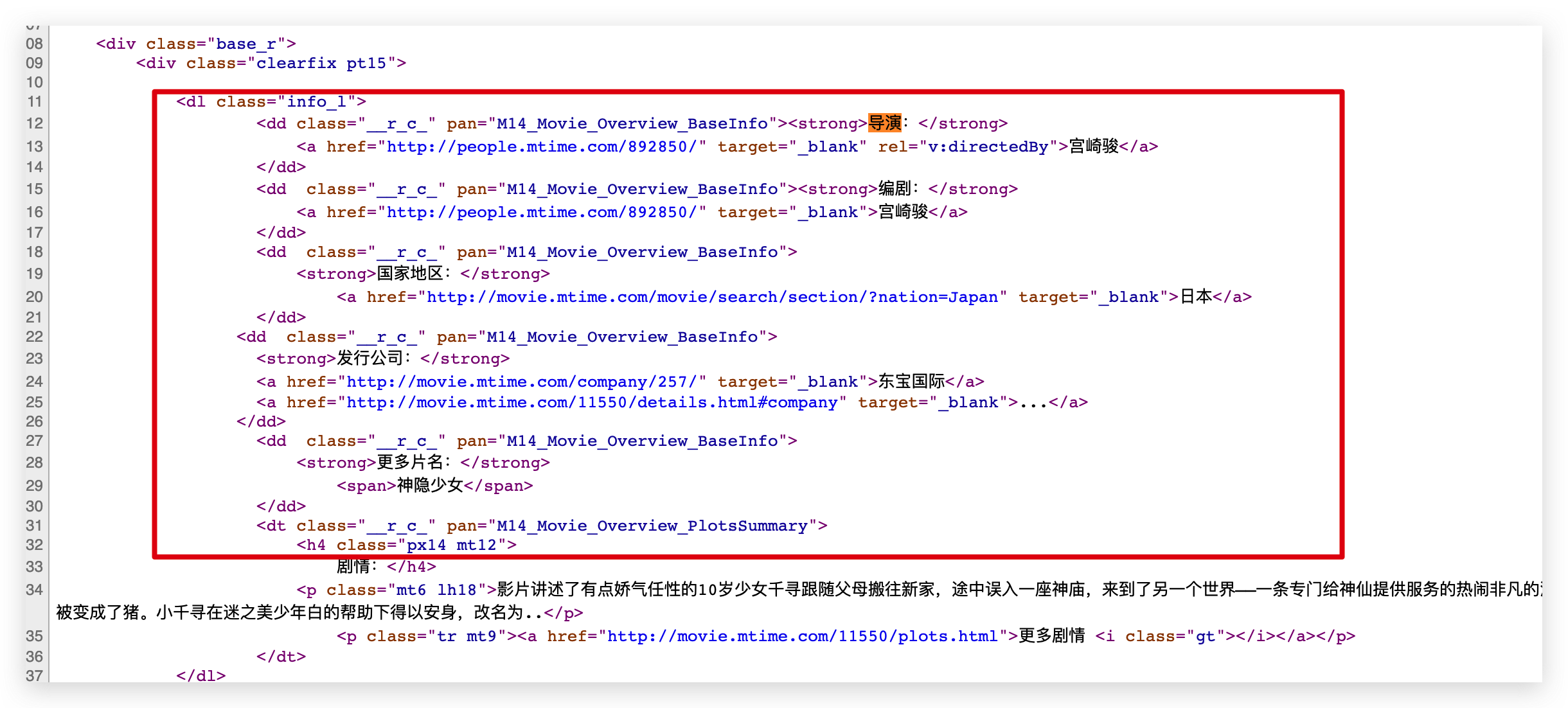
用正則表達式提取資訊的前提是我們要找到資訊的規律。這樣通過正則表達式提取就又快又准。

提取了這些資訊之後,我們把它保存在 list 列表中,這樣做的目的是為了後面我們保存為 csv 文件做準備。
保存為csv文件
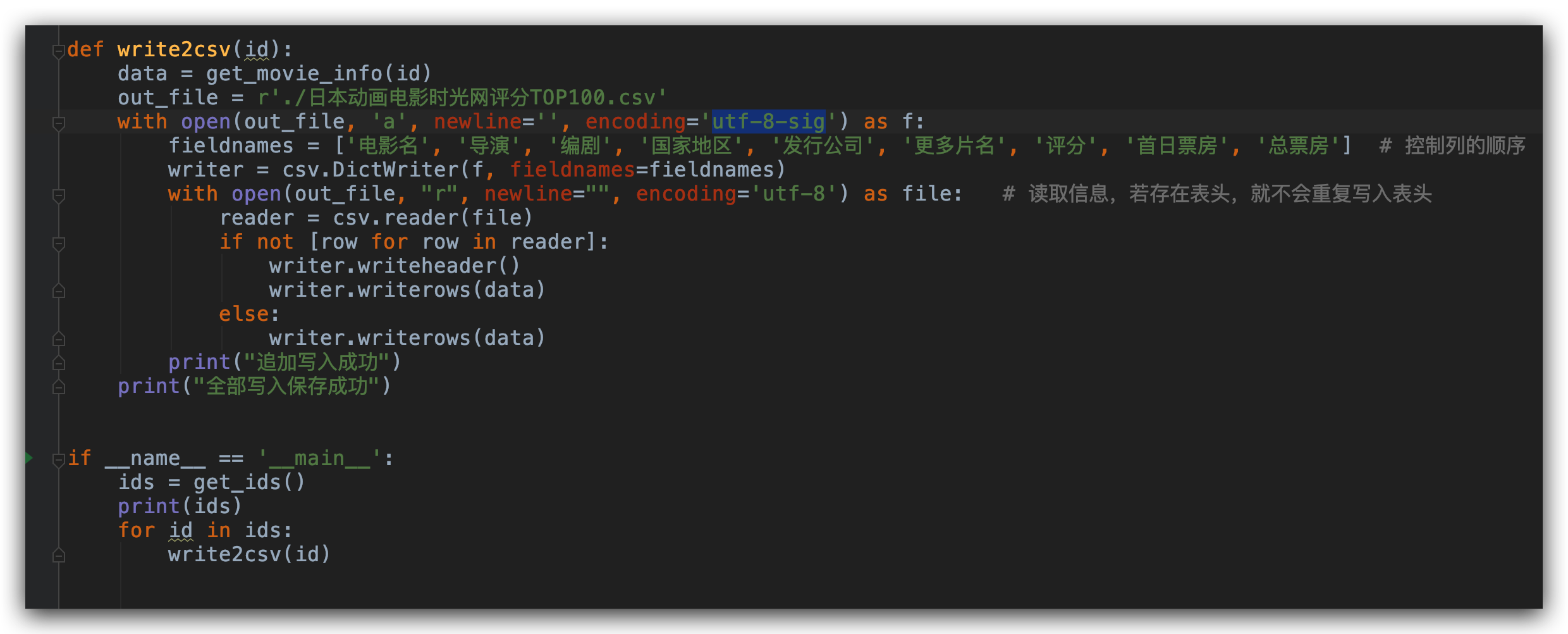
每頁的資訊獲取了之後,我們就可以把這些資訊追加保存到 csv 文件中。每保存一部電影資訊,保存下一部電影資訊就進行追加保存。為了避免保存後的 csv 文件打開出現亂碼,我們需要將編碼形式設置為 encoding=’utf-8′ 格式。
通過這三步,這個 Top100 排行榜中的所有動漫電影資訊都全部保存在本地的 csv 文件中啊。那我們就可以更方便的瀏覽這些電影資訊。這樣我們就可以更好的追番了。本文所有的程式碼資訊可在公眾號「Python知識圈」後台回復「動漫電影」獲取。


