行業知識圖譜的構建及應用
【說在前面】本人部落格新手一枚,象牙塔的老白,職業場的小白。以下內容僅為個人見解,歡迎批評指正,不喜勿噴![認真看圖][認真看圖]
【補充說明】如果你對知識圖譜感興趣,歡迎先瀏覽我的另一篇隨筆:基於圖模型的智慧推薦演算法學習筆記
一、知識圖譜的機遇與挑戰
分享一下肖仰華教授的報告。報告深度剖析知識圖譜的發展進程,系統整理知識圖譜上半場的主要成果,分析知識圖譜下半場的挑戰與機遇,以期為各行業的認知智慧實踐帶來有益的參考。
▌知識圖譜上半場
1. 傳統知識工程

2. 大數據知識工程
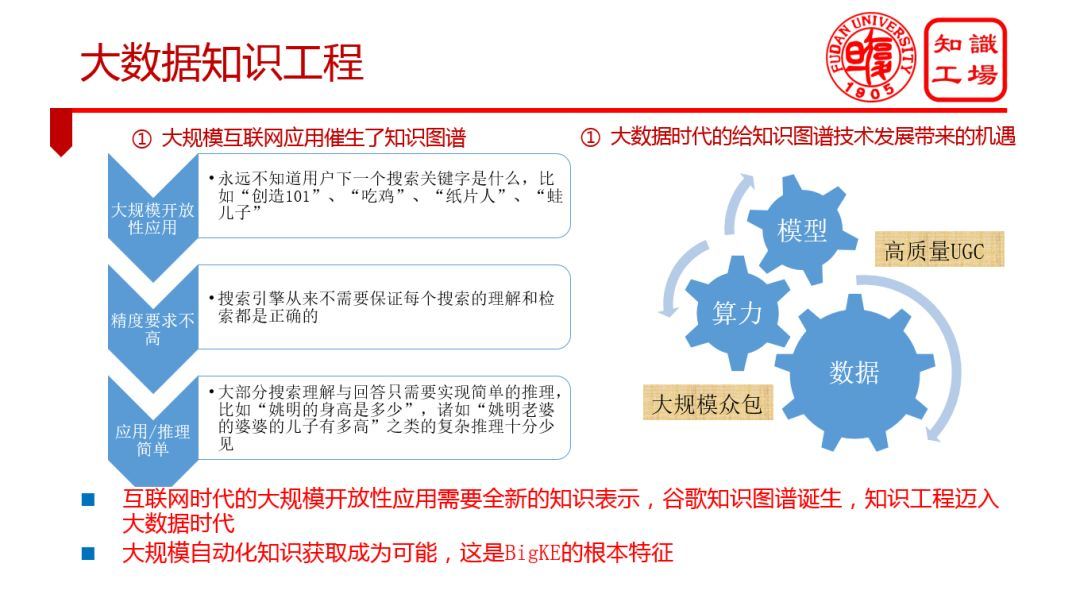
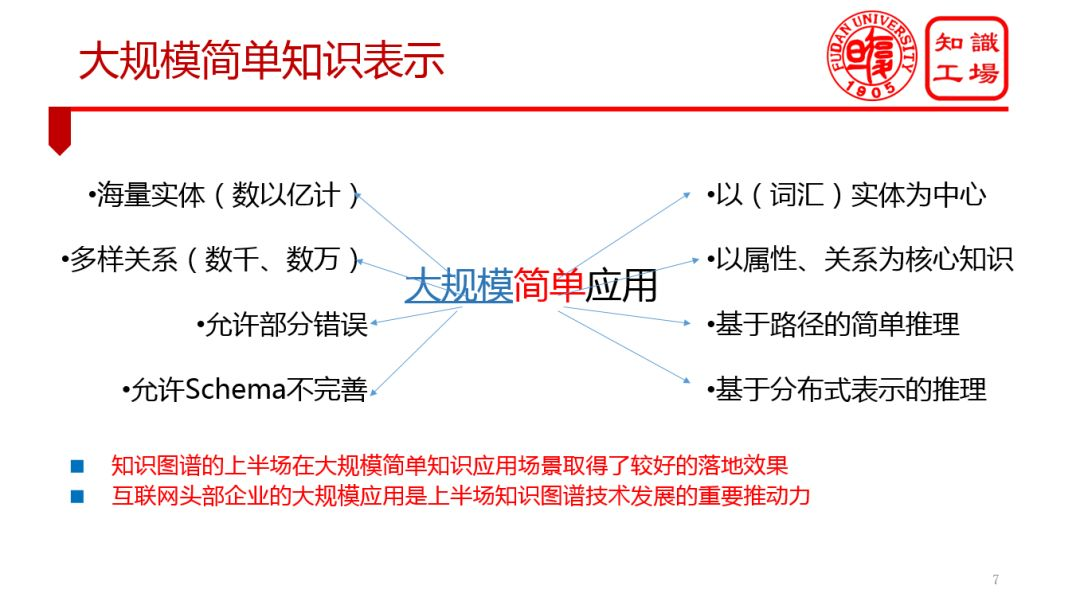
① 大規模簡單知識表示
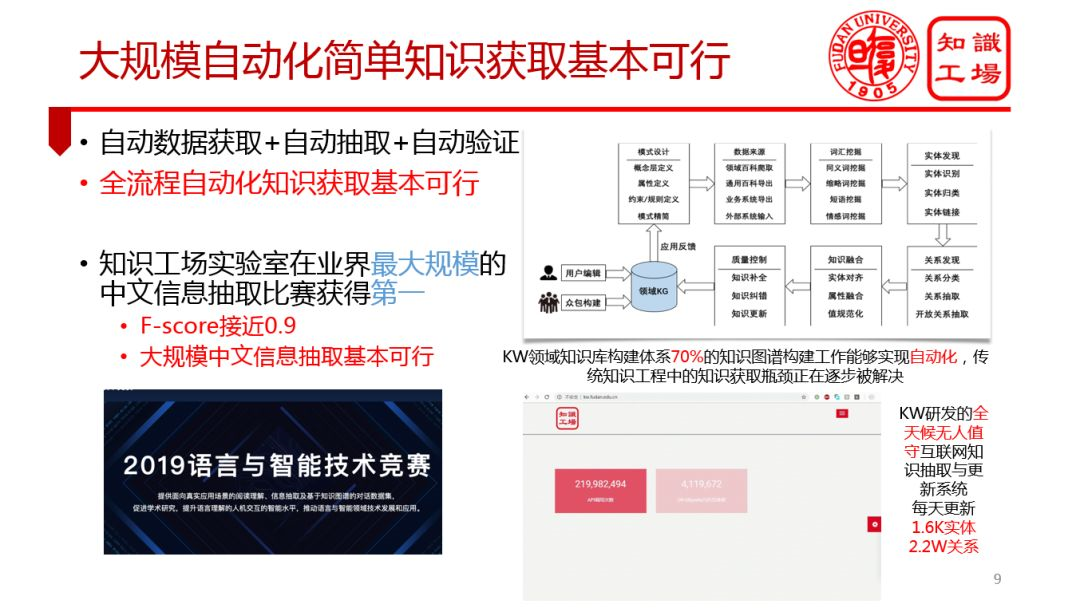
② 知識獲取

③ 基於知識圖譜的簡單推理

3. 大數據知識工程到底解決了哪些問題?
① 語言表達鴻溝

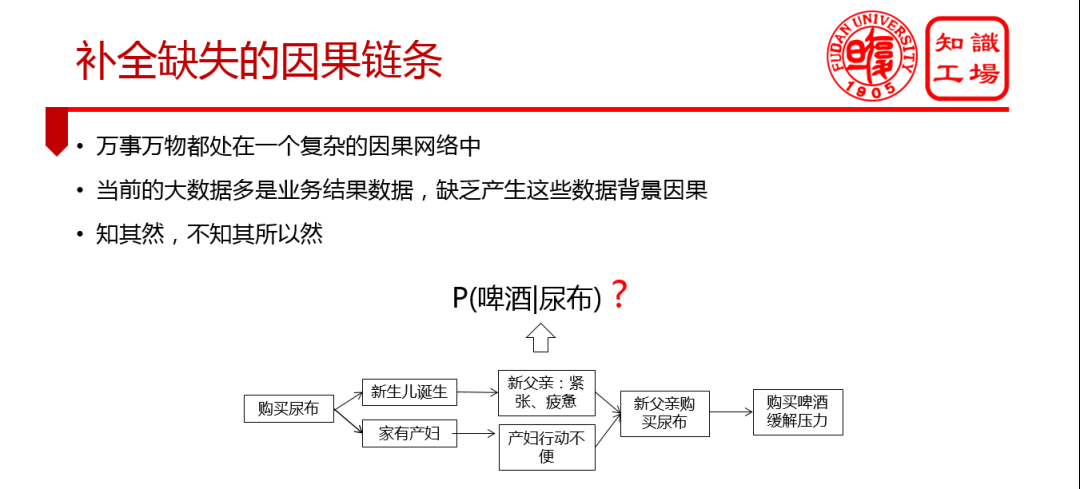
② 缺失的因果鏈條
③ 碎片化數據的關聯與融合
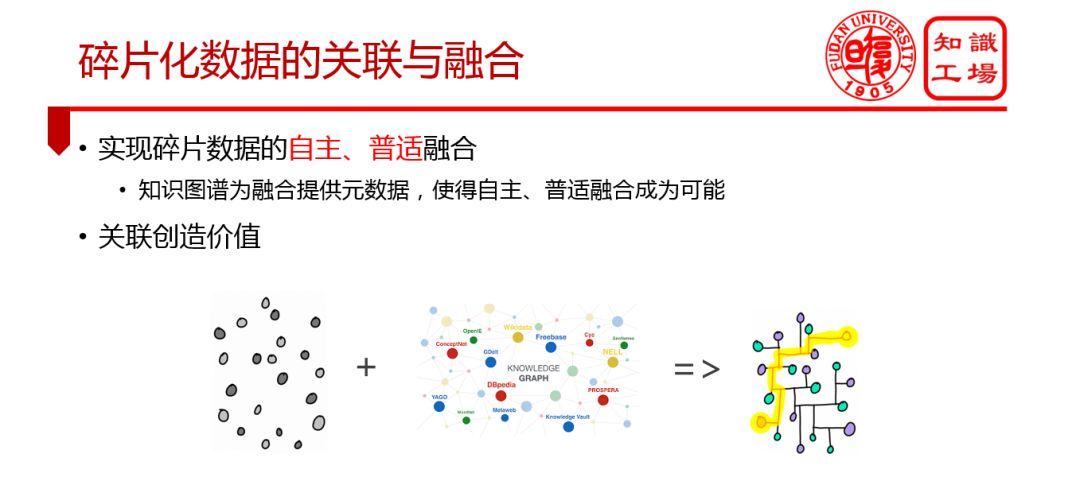
④ 深化行業數據的理解與洞察
⑤ 顯著提升了機器的自然語言理解水平

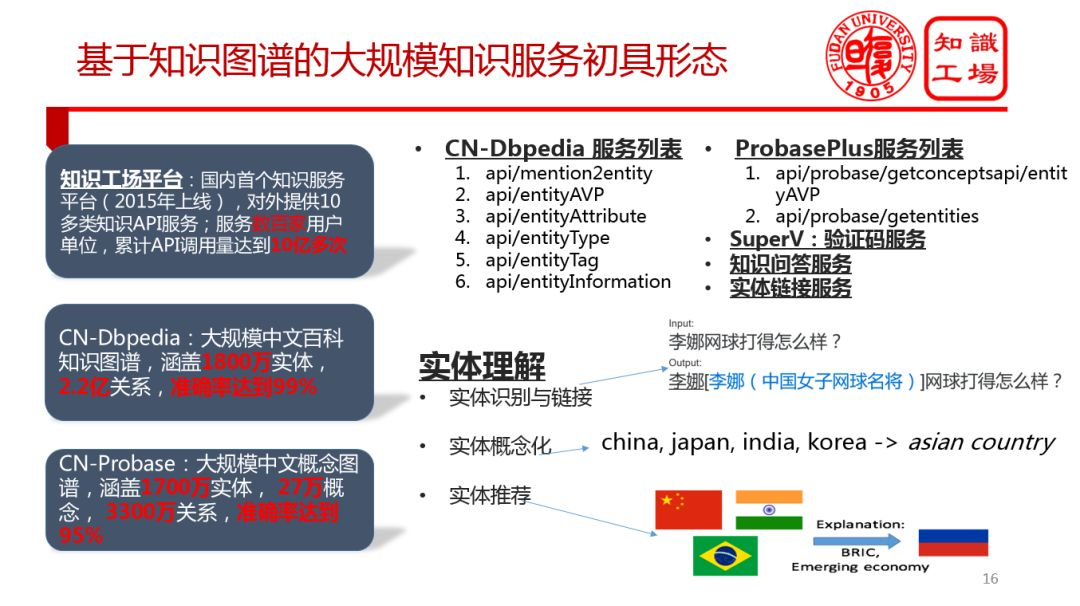
⑥ 基於知識圖譜的大規模知識服務
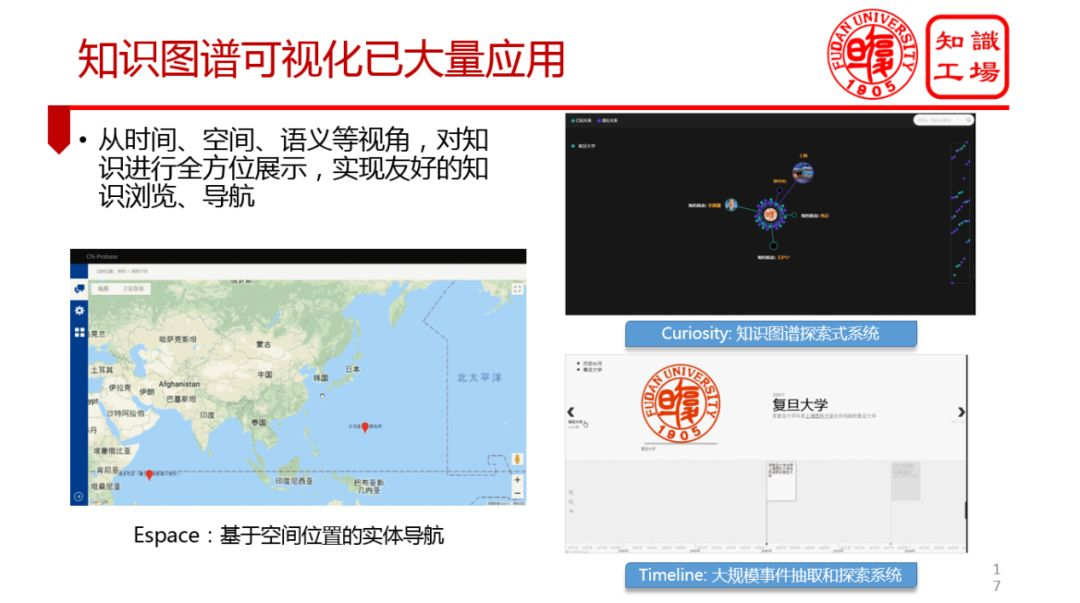
⑦ 知識圖譜可視化已大量應用
⑧ 大數據知識工程理論體系日趨完善

▌知識圖譜下半場
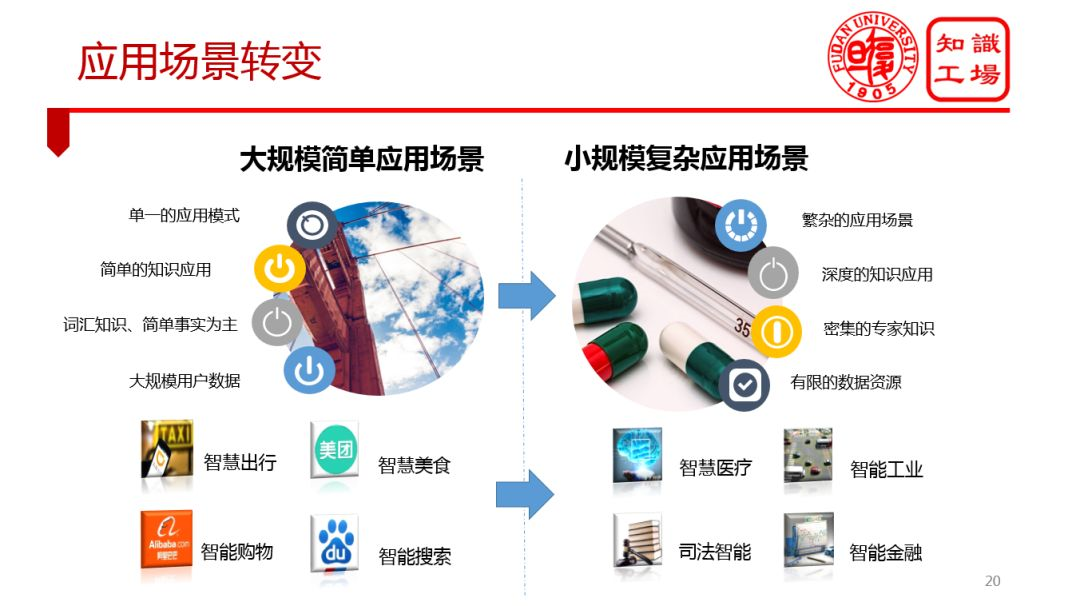
1. 應用場景轉變
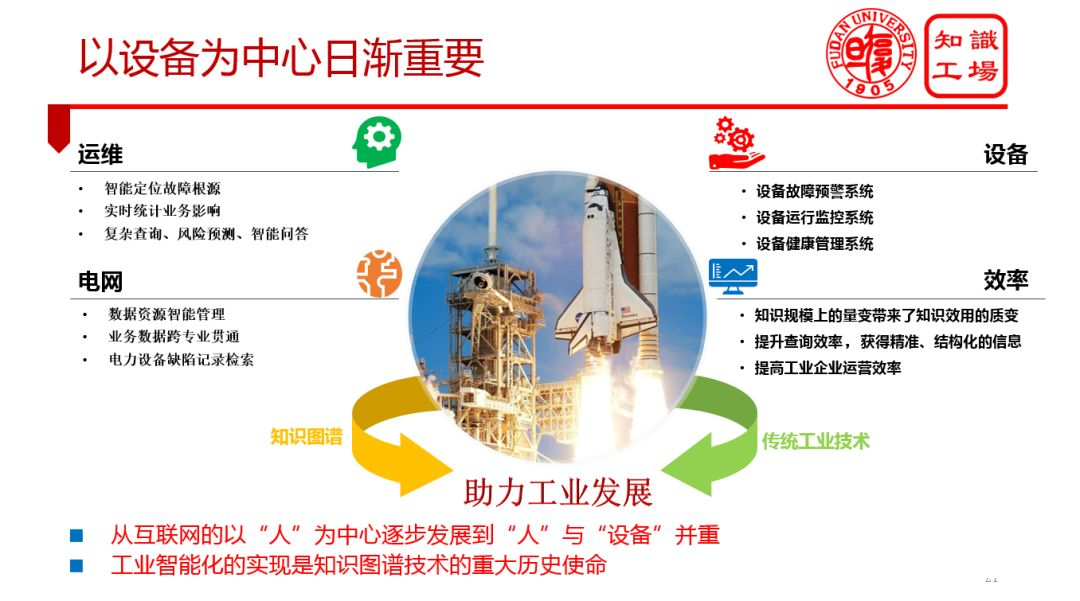
2. 新的趨勢
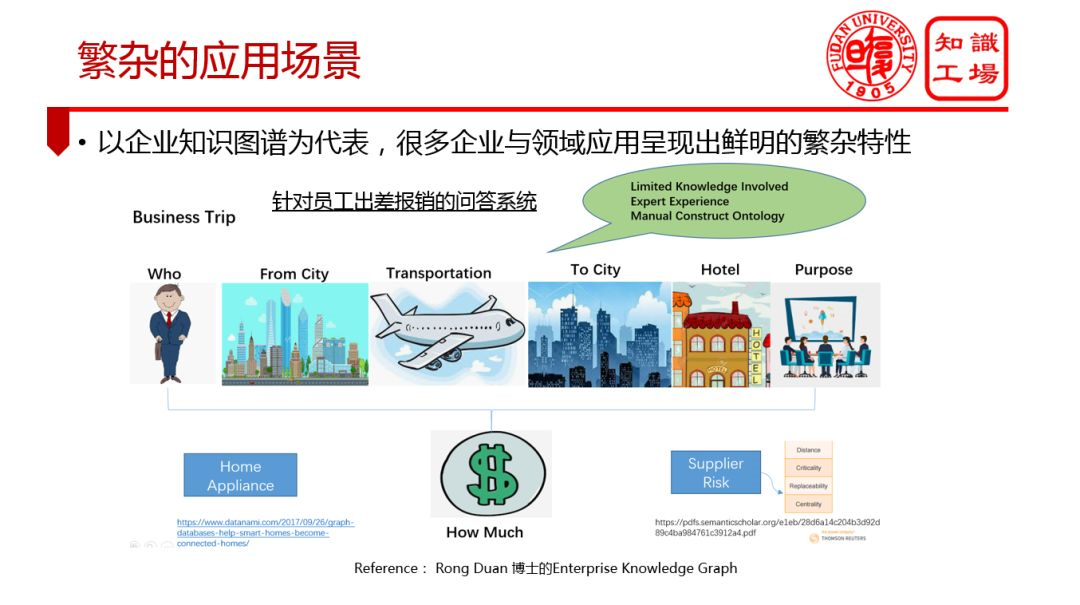
① 繁雜的應用場景
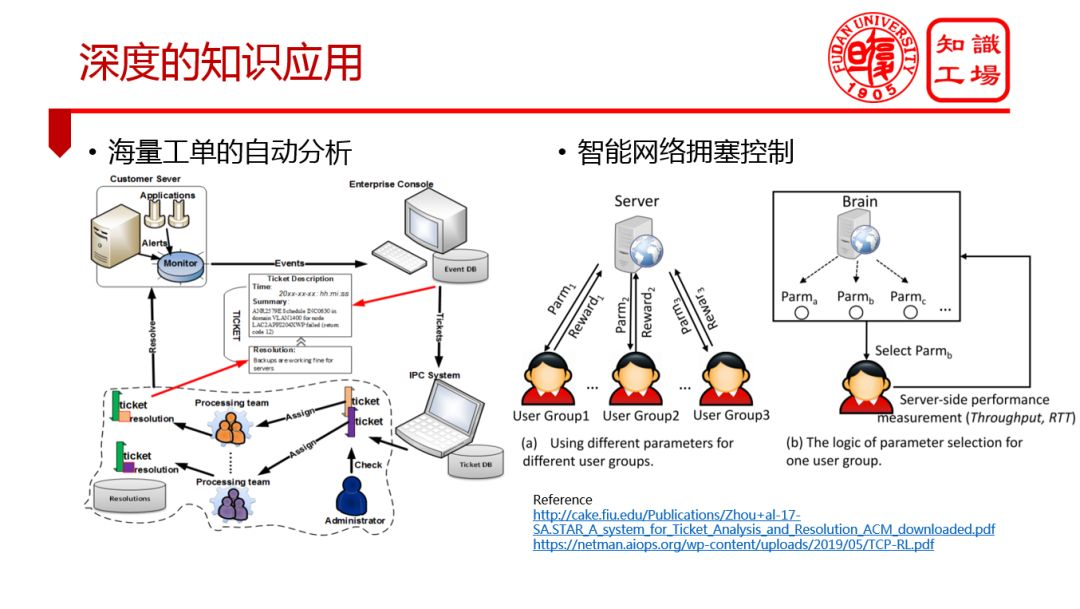
② 深度的知識應用
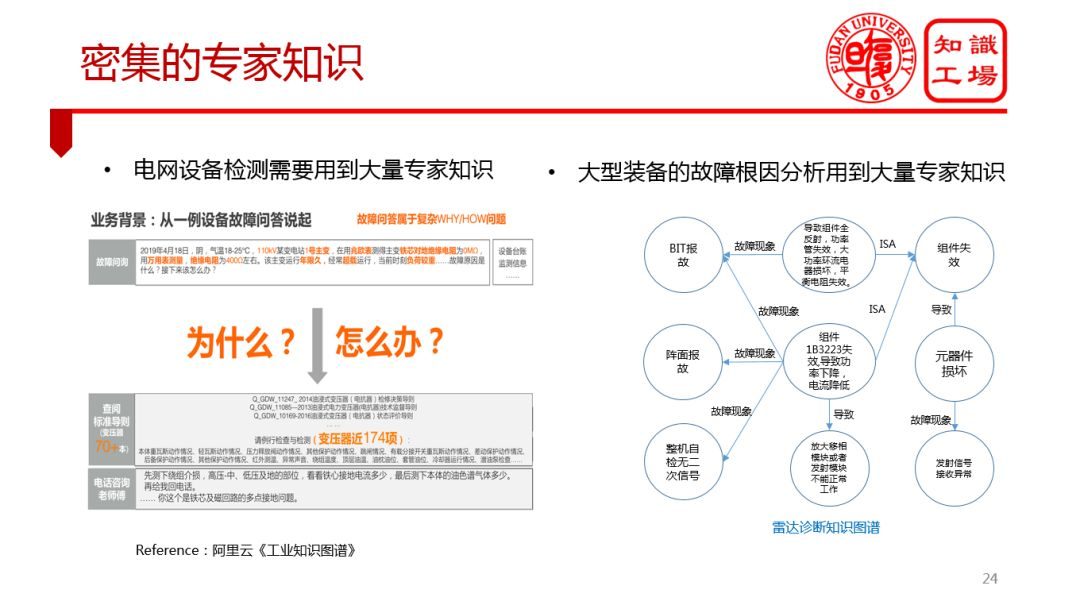
③ 密集的專家知識
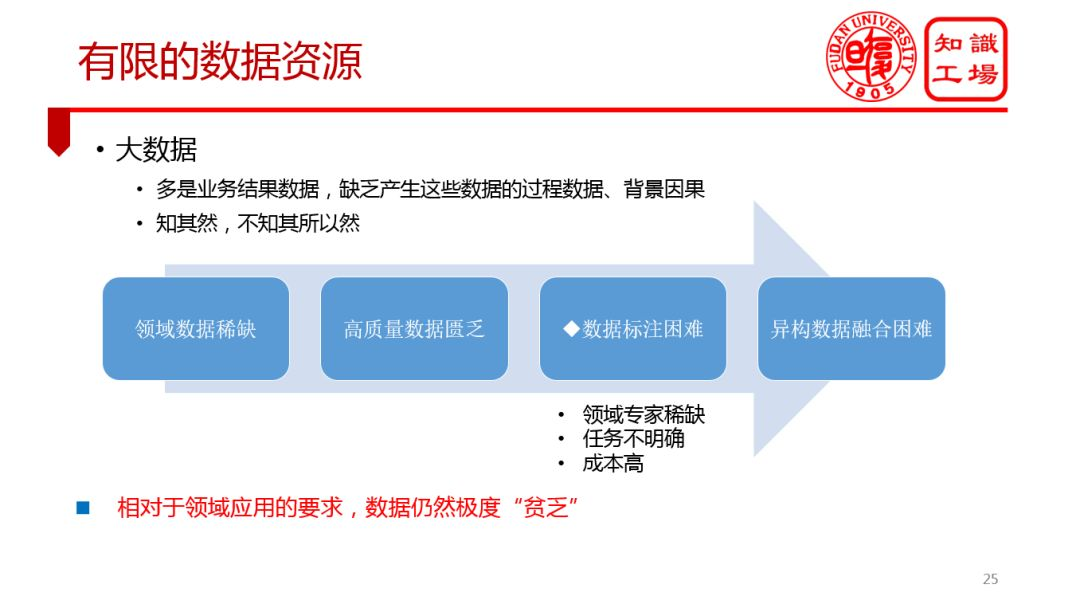
④ 有限的數據資源
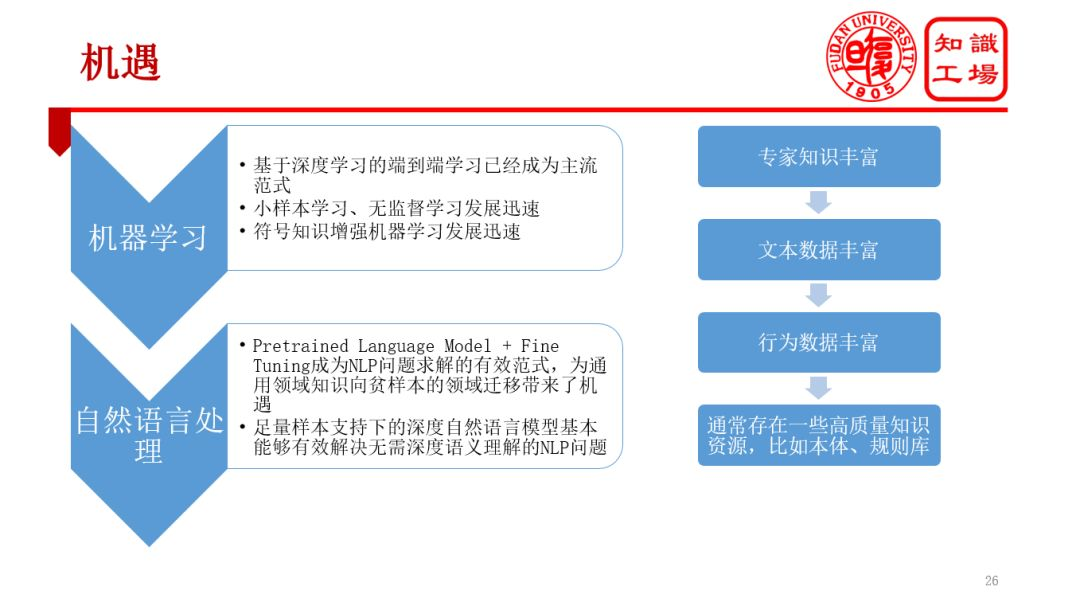
3. 機遇
4. 應對策略
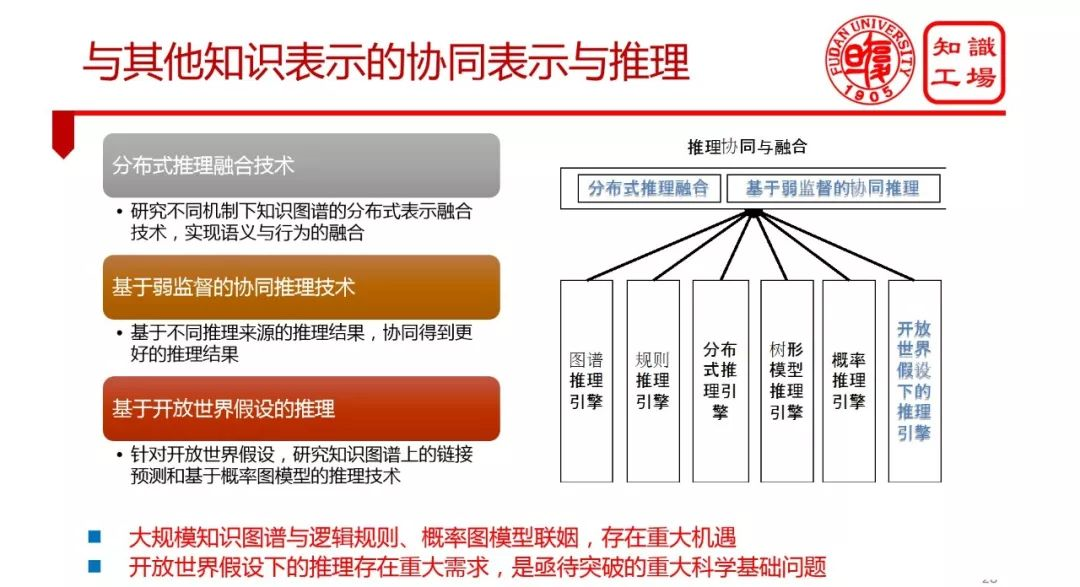
知識表示方面:
① 與其他知識表示的協同表示與推理
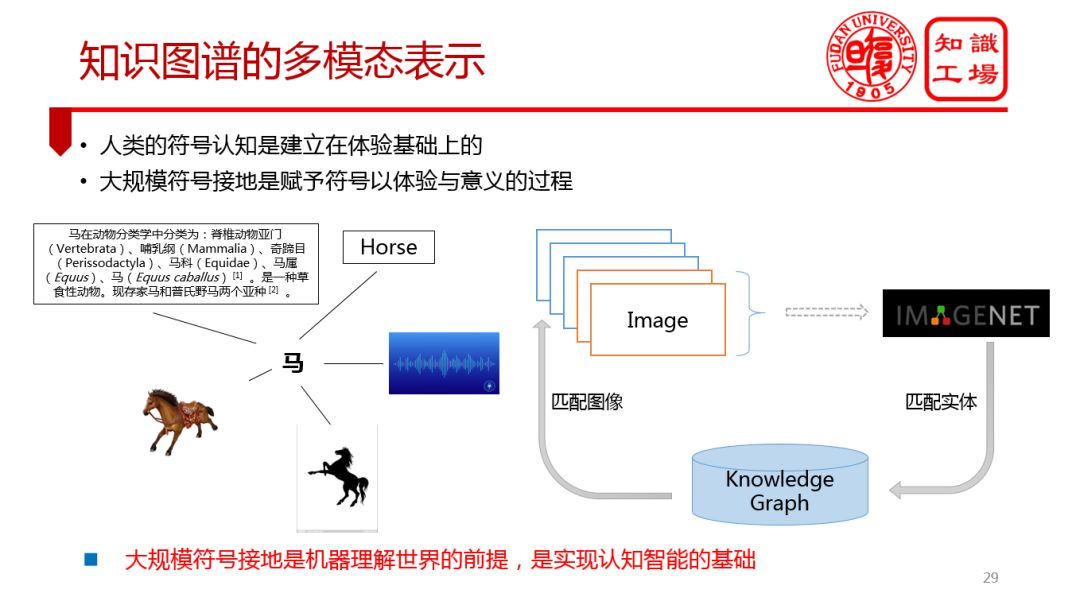
② 知識圖譜的多模態表示
③ 知識圖譜的個性化表示
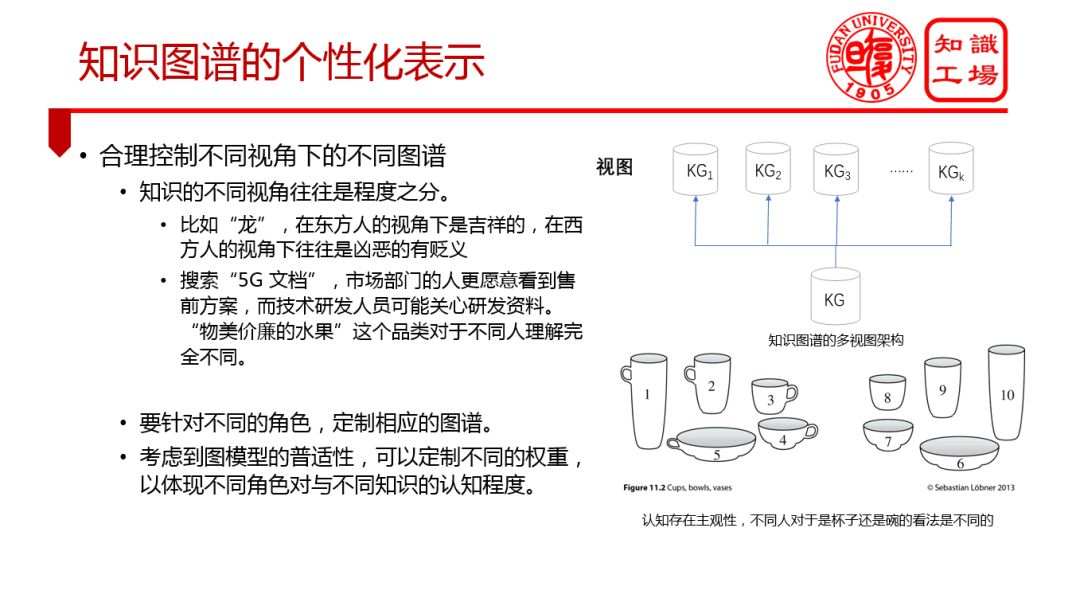
知識獲取方面:
① 發展低成本知識獲取方法

② 注重多粒度知識獲取
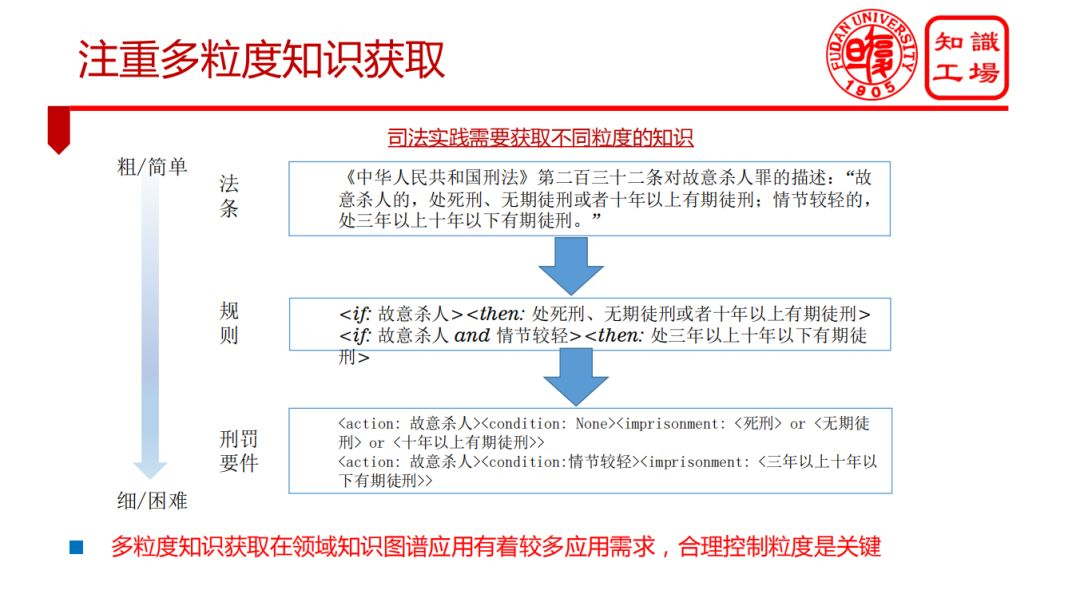
③ 發展大規模常識知識獲取
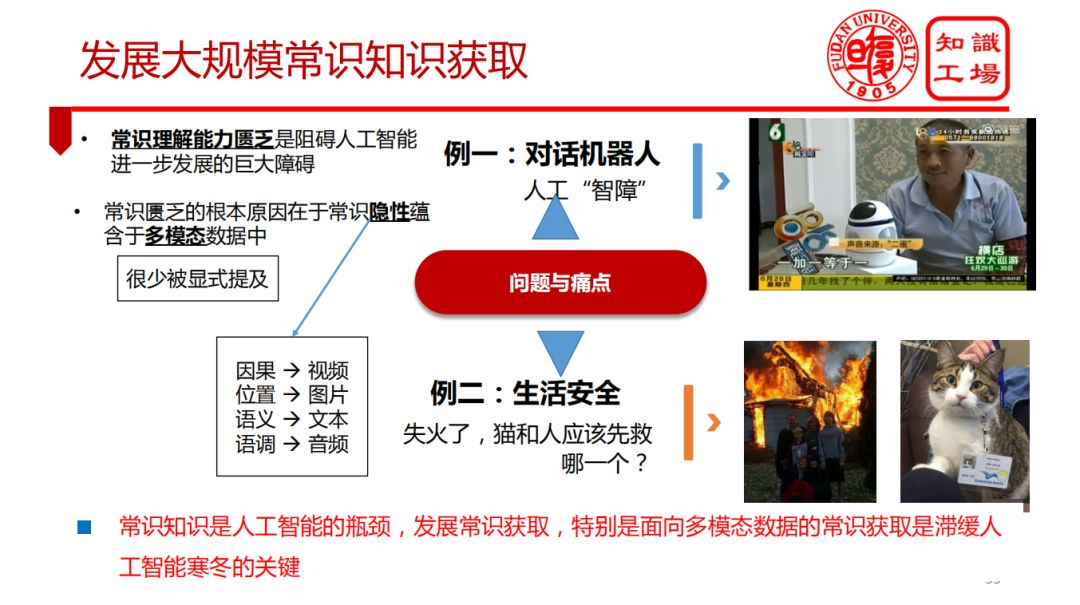
④ 複雜知識獲取機制與方法


知識應用方面:
① 知識圖譜應用透明化
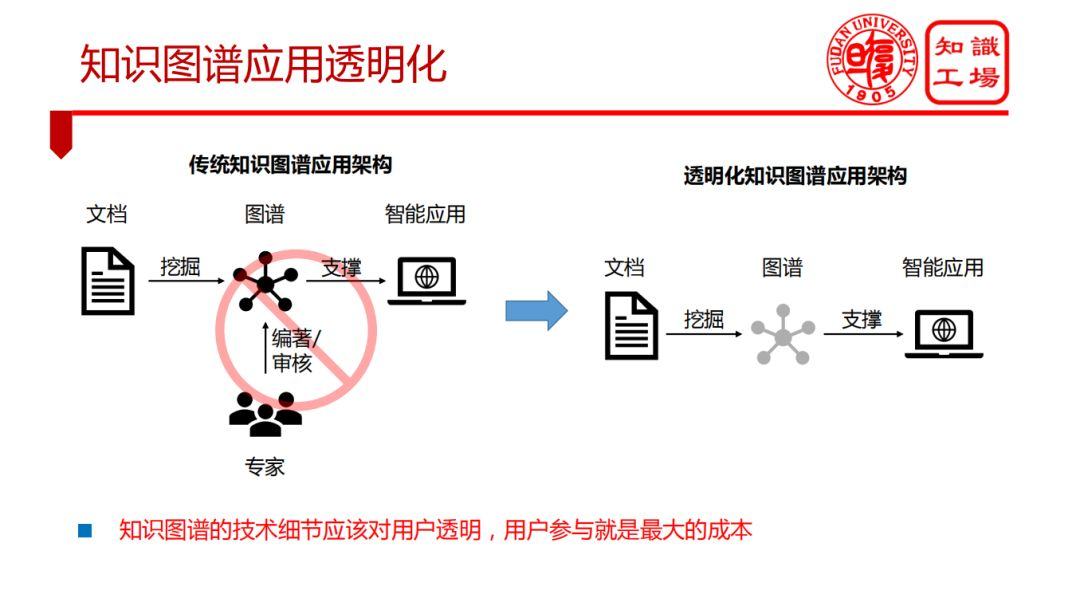
② 基於知識圖譜的可解釋人工智慧

③ 發展符號知識指導下的機器學習模型
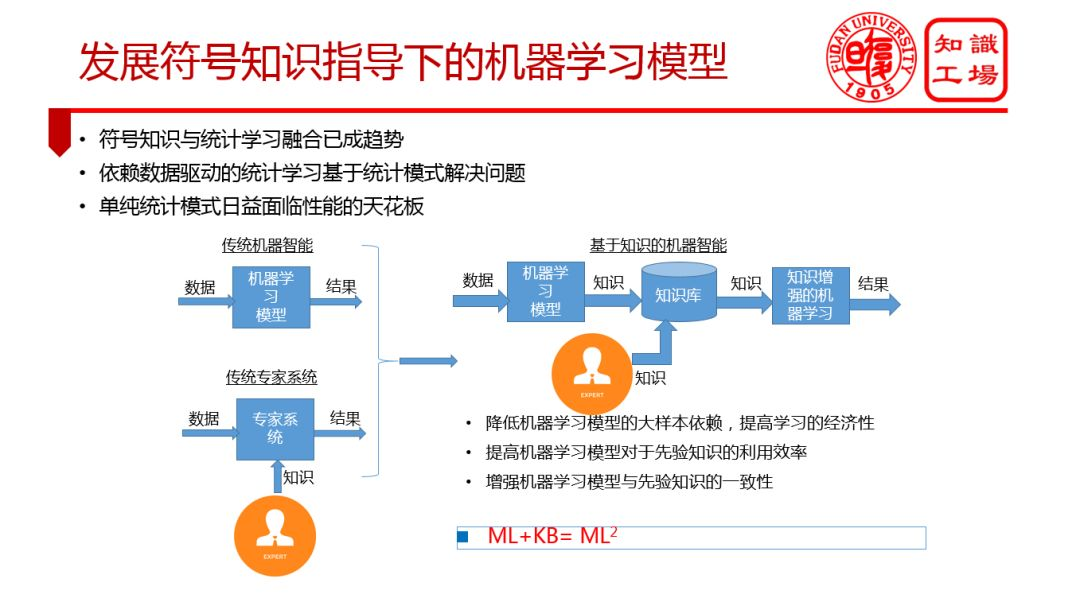
▌總結
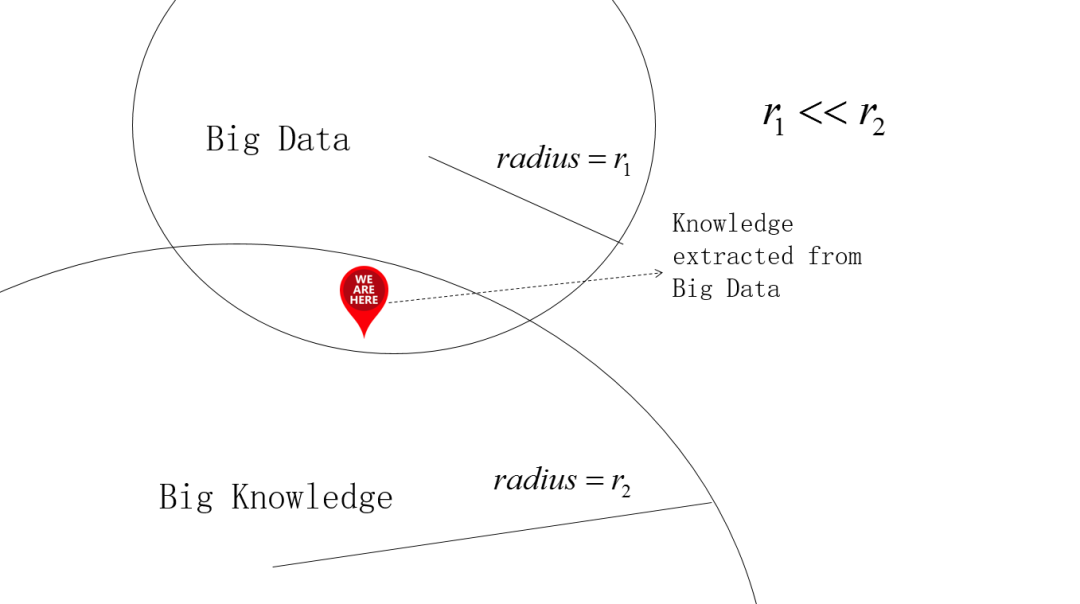
二、行業知識圖譜的構建與應用
分享一下PlantData的文章:行業知識圖譜構建與應用。
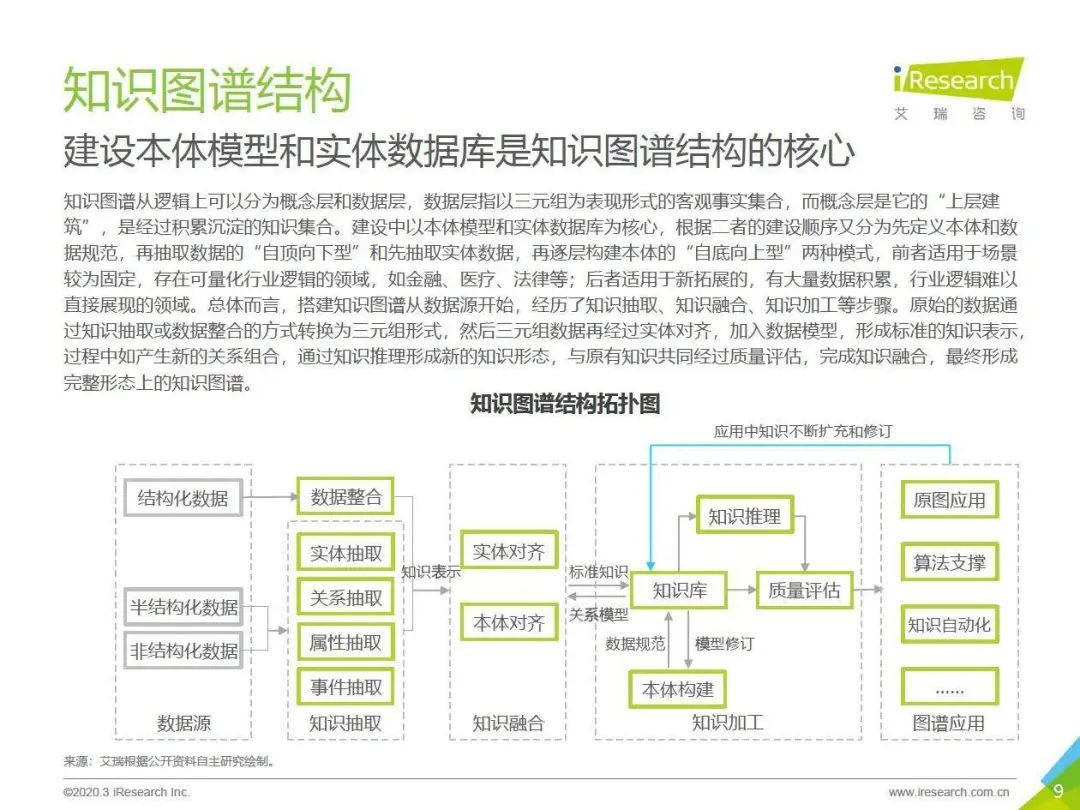
1. 知識圖譜整體結構描述
知識圖譜結構拓撲圖如圖所示:
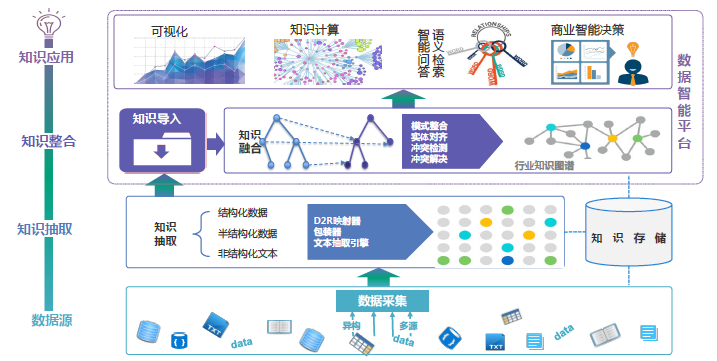
企業全量數據應用挑戰及應對策略:
(1)多源異構數據難以融合
使用知識圖譜(本體)對各類數據建模,基於可動態變化的數據模型(概念-實體-屬性-關係),實現統一建模。
(2)數據模式動態變遷困難
使用可支援數據模式動態變化的知識圖譜的數據存儲。
(3)非結構化數據電腦難以理解
利用資訊抽取技術。
(4)數據使用專業程度過高
(5)分散的數據難以統一消費利用
在知識融合的基礎上,基於語義檢索、知識問答、圖計算、推理、可視化等技術,提供數據檢索/分析/利用,統一平台。
2. 知識建模
(1)以實體為主體目標,實現對不同來源的數據進行映射與合併。(實體抽取與合併)
(2)利用屬性來表示不同數據源中針對實體的描述,形成對實體的全方位描述。(屬性映射與歸併)
(3)利用關係來描述各類抽象建模成實體的數據之間的關聯關係,從而支援關聯分析。(關係抽取)
(4)通過實體鏈接技術,實現圍繞實體的多種類型數據的關聯存儲。(實體鏈接)
(5)使用事件機制描述客觀世界中動態發展,體現事件與實體間的關聯;並利用時序描述事件的發展狀況。(動態事件描述)
知識建模工具:Protégé(本體編輯器,較局限)
3. 知識抽取
知識抽取的主要策略如圖所示(針對結構化、半結構化、非結構化數據的處理方式不同):
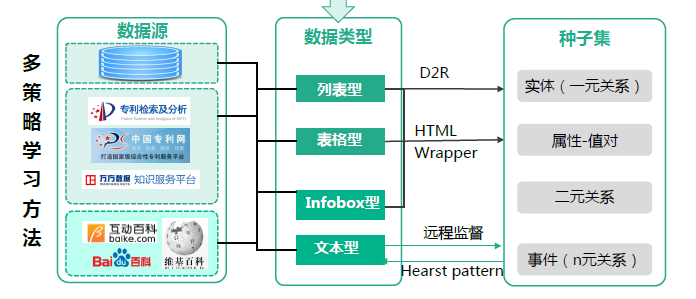

知識抽取中的文本資訊抽取,主要包括:實體識別、關係抽取、事件抽取、概念抽取。資訊抽取主要有兩大類工具:
- OpenIE:面向開放領域抽取資訊、關係類型事先未知、基於語言學模式進行抽取、規模大、精度相對較低。典型工具:ReVerb、TextRunner(準確率低,實用性不強,一般不用)
- CloseIE:面向特定領域抽取資訊、預先定義好抽取的關係類型、基於領域專業知識抽取、規模小、精度比較高。典型工具:DeepDive(主要是針對實體識別,缺乏對關係/事件/概念的抽取)
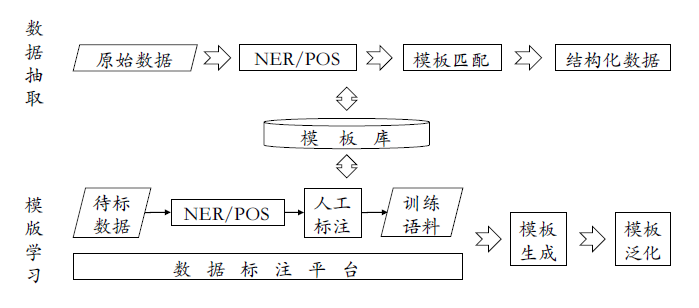
非結構化文本數據的處理包括以下步驟:
- 分詞、詞性標註、語法解析、依存分析
- NER命名實體識別、實體鏈接
- 關係抽取、事件抽取
其中,事件抽取可以分為預定義事件抽取和開放域事件抽取,行業知識圖譜中主要為預定義事件抽取。採用模式匹配方法,包括三個步驟:
- 準備事件觸發詞表
- 候選事件抽取:尋找含有觸發詞的句子
- 事件元素識別:根據事件模版抽取相應的元素
還有基於機器學習模型的抽取:SVM、邏輯回歸、CRF、LSTM等:
補充說明,關於知識表示,歡迎先瀏覽我的另一篇隨筆:基於圖模型的智慧推薦演算法學習筆記,這裡不再贅述。
- 基於數理邏輯的知識表示:RDF(資源描述框架)、OWL(RDF Schema 的擴展)、SPARQL(RDF查詢語言)
- 基於向量空間學習的分散式知識表示:Rescal、NTN、TransE(Embedding)
4. 知識融合
(1)數據層融合:實體鏈接技術
即等同性判斷:給定不同數據源中的實體,判斷其是否指向同一個真實世界實體(實體屬性與關係的合併)。
- 基於實體知識的鏈接
- 基於篇章主題的鏈接
- 融合實體知識和篇章主題的鏈接
實體鏈接工具:Wikipedia Miner、DBpedia Spotlight等,大部分都是針對百科類的知識庫工作的,基本不支援中文的處理。
(2)語義描述層融合:Schema Mapping
- 概念上下位關係合併
- 概念的屬性定義合併
當然還有一些別的需要考慮,例如多源知識融合、衝突檢測與解決、跨語言融合、知識驗證等。
例如,通過人機交互介面對錯誤資訊進行人工糾正,並以此作為種子案例,通過強化學習加強模型的識別精度和魯棒性。
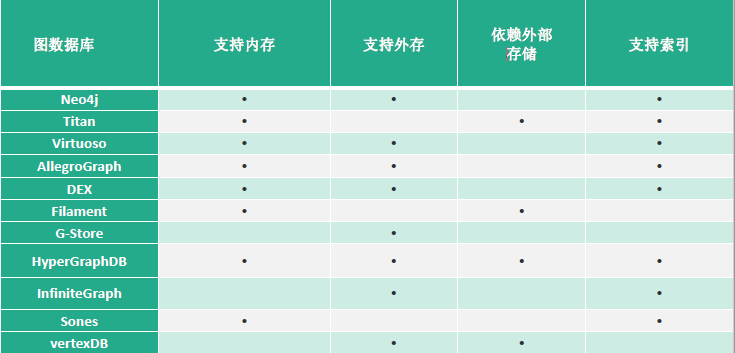
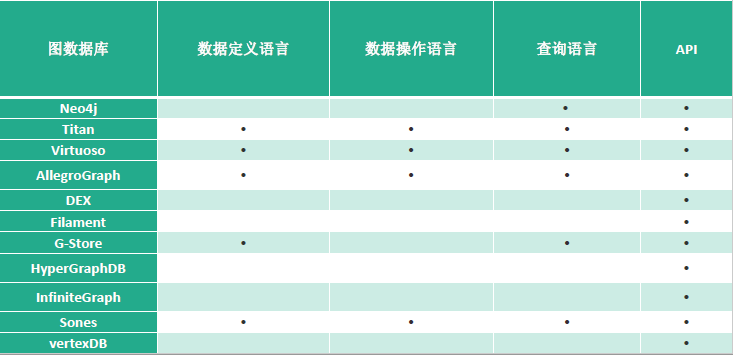
5. 知識存儲
知識圖譜是基於圖的數據結構,其存儲方式主要有兩種方式:RDF存儲和圖資料庫。
- 基於關係資料庫的存儲
- 基於原生圖的存儲
- 基於混合存儲
下面展示各大圖資料庫的對比:

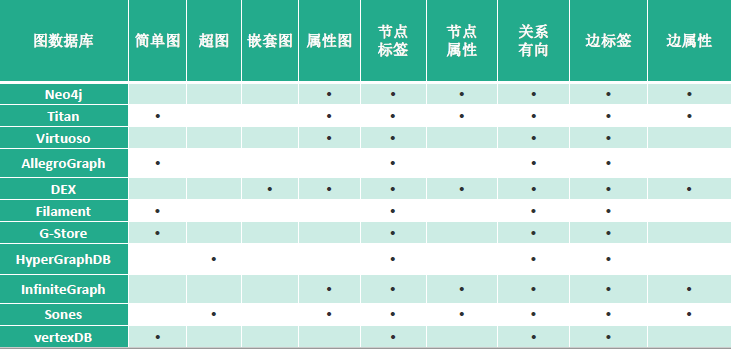


6. 知識計算
(1)基於圖論的相關演算法:
- 圖遍歷:廣度優先遍歷、深度優先遍歷
- 最短路徑查詢: Dijkstra(迪傑斯特拉演算法)、Floyd(弗洛伊德演算法)
- 路徑探尋:給定兩個或多個節點,發現它們之間的關聯關係
- 權威節點分析:PageRank演算法
- 族群發現:最大流演算法
- 相似節點發現:基於節點屬性、關係的相似度演算法
(2)本體推理:使用本體推理進行新知識發現或衝突檢測。
- 基於表運算及改進的方法:FaCT++、Racer、Pellet Hermit等
- 基於一階查詢重寫的方法(Ontology based data access,基於本體的數據訪問)
- 基於產生式規則的演算法(如rete):Jena 、Sesame、OWLIM等
- 基於Datalog轉換的方法:KAON、RDFox等
- 回答集程式Answer set programming
本體知識推理工具:RDFox。
(3)基於規則的推理:使用規則引擎,編寫相應的業務規則,通過推理輔助業務決策。
- 在知識圖譜基礎知識的基礎上,專家依據行業應用的業務特徵進行規則的定義。
- 引擎基於基礎知識與所定義的規則,執行推理過程給出推理結果。
基於規則推理工具:Drools 規則定義。
7. 知識應用
智慧問答(基於語義解析的方法+基於資訊檢索的方法)、語義搜索(基於實體鏈接)、可視化決策支援(D3.js、ECharts)等。
8. 知識圖譜的自動構建
可構建的圖譜:例如公司圖譜、產品圖譜、⼈物圖譜、智慧預警等。在行業應用中使用知識圖譜,大致有如下幾種方式:
- 可以使用現有的套裝工具,在現有套裝工具的基礎上進行擴充:LOD2、Stardog
- 可以使用各生命周期過程中的相應工具進行組合使用,針對性開發或擴展生命周期中特定工具
如果您對異常檢測感興趣,歡迎瀏覽我的另一篇部落格:異常檢測演算法演變及學習筆記
如果您對智慧推薦感興趣,歡迎瀏覽我的另一篇部落格:智慧推薦演算法演變及學習筆記 、CTR預估模型演變及學習筆記
如果您對時間序列分析感興趣,歡迎瀏覽我的另一篇部落格:時間序列分析中預測類問題下的建模方案 、深度學習中的序列模型演變及學習筆記
如果您對數據挖掘感興趣,歡迎瀏覽我的另一篇部落格:數據挖掘比賽/項目全流程介紹 、機器學習中的聚類演算法演變及學習筆記
如果您對人工智慧演算法感興趣,歡迎瀏覽我的另一篇部落格:人工智慧新手入門學習路線和學習資源合集(含AI綜述/python/機器學習/深度學習/tensorflow)、人工智慧領域常用的開源框架和庫(含機器學習/深度學習/強化學習/知識圖譜/圖神經網路)
如果你是電腦專業的應屆畢業生,歡迎瀏覽我的另外一篇部落格:如果你是一個電腦領域的應屆生,你如何準備求職面試?
如果你是電腦專業的本科生,歡迎瀏覽我的另外一篇部落格:如果你是一個電腦領域的本科生,你可以選擇學習什麼?
如果你是電腦專業的研究生,歡迎瀏覽我的另外一篇部落格:如果你是一個電腦領域的研究生,你可以選擇學習什麼?
如果你對金融科技感興趣,歡迎瀏覽我的另一篇部落格:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之後部落客將持續分享各大演算法的學習思路和學習筆記:hello world: 我的部落格寫作思路


