Hadoop 系列(一)—— 分散式文件系統 HDFS
- 2019 年 10 月 3 日
- 筆記
一、介紹
HDFS (Hadoop Distributed File System)是 Hadoop 下的分散式文件系統,具有高容錯、高吞吐量等特性,可以部署在低成本的硬體上。
二、HDFS 設計原理
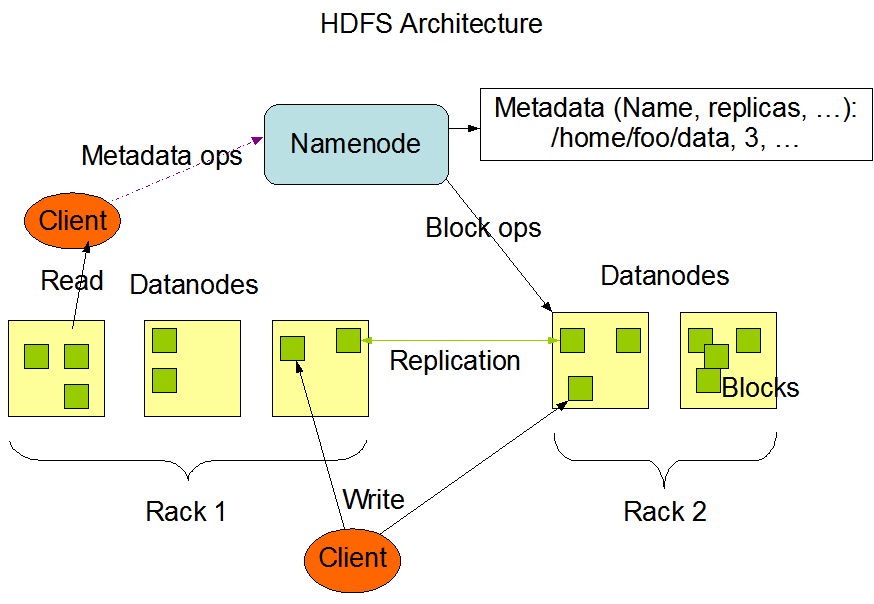
2.1 HDFS 架構
HDFS 遵循主/從架構,由單個 NameNode(NN) 和多個 DataNode(DN) 組成:
- NameNode : 負責執行有關
文件系統命名空間的操作,例如打開,關閉、重命名文件和目錄等。它同時還負責集群元數據的存儲,記錄著文件中各個數據塊的位置資訊。 - DataNode:負責提供來自文件系統客戶端的讀寫請求,執行塊的創建,刪除等操作。
2.2 文件系統命名空間
HDFS 的 文件系統命名空間 的層次結構與大多數文件系統類似 (如 Linux), 支援目錄和文件的創建、移動、刪除和重命名等操作,支援配置用戶和訪問許可權,但不支援硬鏈接和軟連接。NameNode 負責維護文件系統名稱空間,記錄對名稱空間或其屬性的任何更改。
2.3 數據複製
由於 Hadoop 被設計運行在廉價的機器上,這意味著硬體是不可靠的,為了保證容錯性,HDFS 提供了數據複製機制。HDFS 將每一個文件存儲為一系列塊,每個塊由多個副本來保證容錯,塊的大小和複製因子可以自行配置(默認情況下,塊大小是 128M,默認複製因子是 3)。
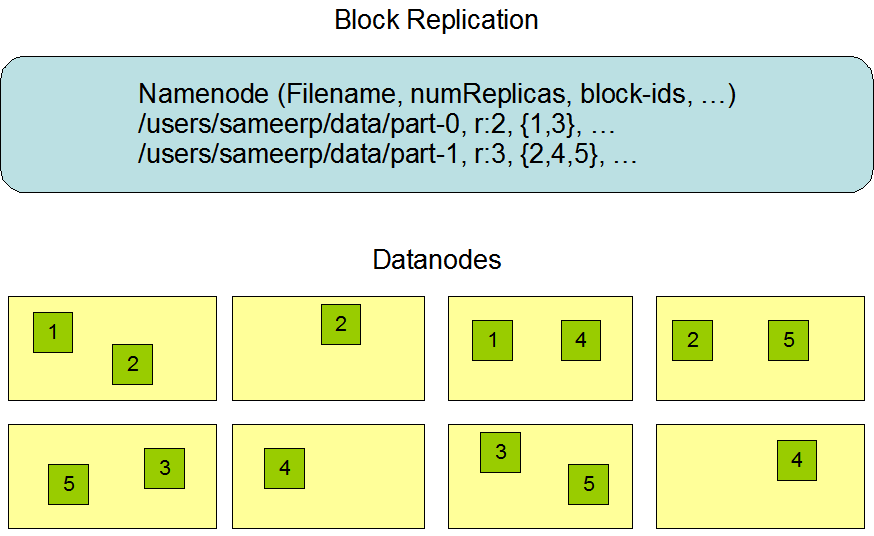
2.4 數據複製的實現原理
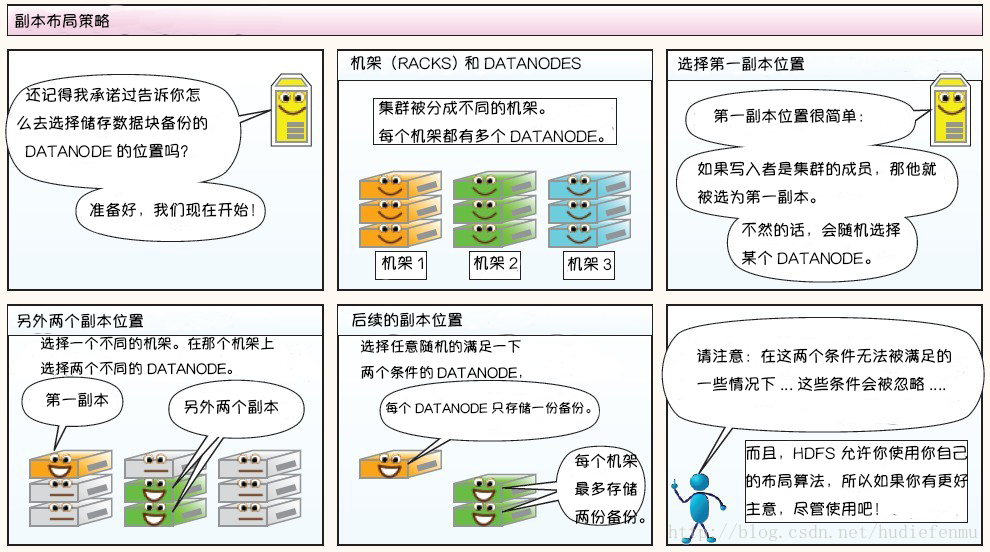
大型的 HDFS 實例在通常分布在多個機架的多台伺服器上,不同機架上的兩台伺服器之間通過交換機進行通訊。在大多數情況下,同一機架中的伺服器間的網路頻寬大於不同機架中的伺服器之間的頻寬。因此 HDFS 採用機架感知副本放置策略,對於常見情況,當複製因子為 3 時,HDFS 的放置策略是:
在寫入程式位於 datanode 上時,就優先將寫入文件的一個副本放置在該 datanode 上,否則放在隨機 datanode 上。之後在另一個遠程機架上的任意一個節點上放置另一個副本,並在該機架上的另一個節點上放置最後一個副本。此策略可以減少機架間的寫入流量,從而提高寫入性能。

如果複製因子大於 3,則隨機確定第 4 個和之後副本的放置位置,同時保持每個機架的副本數量低於上限,上限值通常為 (複製係數 - 1)/機架數量 + 2,需要注意的是不允許同一個 dataNode 上具有同一個塊的多個副本。
2.5 副本的選擇
為了最大限度地減少頻寬消耗和讀取延遲,HDFS 在執行讀取請求時,優先讀取距離讀取器最近的副本。如果在與讀取器節點相同的機架上存在副本,則優先選擇該副本。如果 HDFS 群集跨越多個數據中心,則優先選擇本地數據中心上的副本。
2.6 架構的穩定性
1. 心跳機制和重新複製
每個 DataNode 定期向 NameNode 發送心跳消息,如果超過指定時間沒有收到心跳消息,則將 DataNode 標記為死亡。NameNode 不會將任何新的 IO 請求轉發給標記為死亡的 DataNode,也不會再使用這些 DataNode 上的數據。 由於數據不再可用,可能會導致某些塊的複製因子小於其指定值,NameNode 會跟蹤這些塊,並在必要的時候進行重新複製。
2. 數據的完整性
由於存儲設備故障等原因,存儲在 DataNode 上的數據塊也會發生損壞。為了避免讀取到已經損壞的數據而導致錯誤,HDFS 提供了數據完整性校驗機制來保證數據的完整性,具體操作如下:
當客戶端創建 HDFS 文件時,它會計算文件的每個塊的 校驗和,並將 校驗和 存儲在同一 HDFS 命名空間下的單獨的隱藏文件中。當客戶端檢索文件內容時,它會驗證從每個 DataNode 接收的數據是否與存儲在關聯校驗和文件中的 校驗和 匹配。如果匹配失敗,則證明數據已經損壞,此時客戶端會選擇從其他 DataNode 獲取該塊的其他可用副本。
3.元數據的磁碟故障
FsImage 和 EditLog 是 HDFS 的核心數據,這些數據的意外丟失可能會導致整個 HDFS 服務不可用。為了避免這個問題,可以配置 NameNode 使其支援 FsImage 和 EditLog 多副本同步,這樣 FsImage 或 EditLog 的任何改變都會引起每個副本 FsImage 和 EditLog 的同步更新。
4.支援快照
快照支援在特定時刻存儲數據副本,在數據意外損壞時,可以通過回滾操作恢復到健康的數據狀態。
三、HDFS 的特點
3.1 高容錯
由於 HDFS 採用數據的多副本方案,所以部分硬體的損壞不會導致全部數據的丟失。
3.2 高吞吐量
HDFS 設計的重點是支援高吞吐量的數據訪問,而不是低延遲的數據訪問。
3.3 大文件支援
HDFS 適合於大文件的存儲,文檔的大小應該是是 GB 到 TB 級別的。
3.3 簡單一致性模型
HDFS 更適合於一次寫入多次讀取 (write-once-read-many) 的訪問模型。支援將內容追加到文件末尾,但不支援數據的隨機訪問,不能從文件任意位置新增數據。
3.4 跨平台移植性
HDFS 具有良好的跨平台移植性,這使得其他大數據計算框架都將其作為數據持久化存儲的首選方案。
附:圖解HDFS存儲原理
說明:以下圖片引用自部落格:翻譯經典 HDFS 原理講解漫畫
1. HDFS寫數據原理
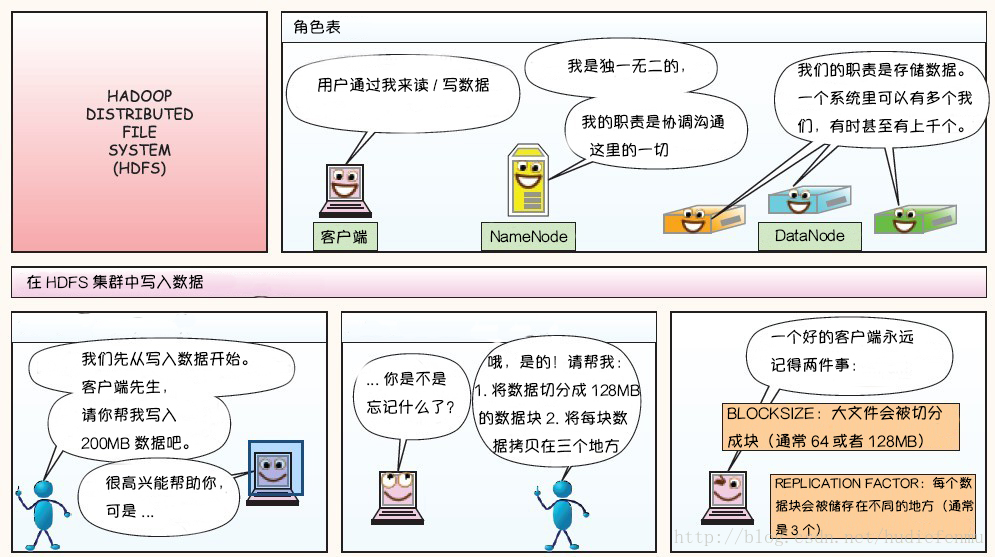
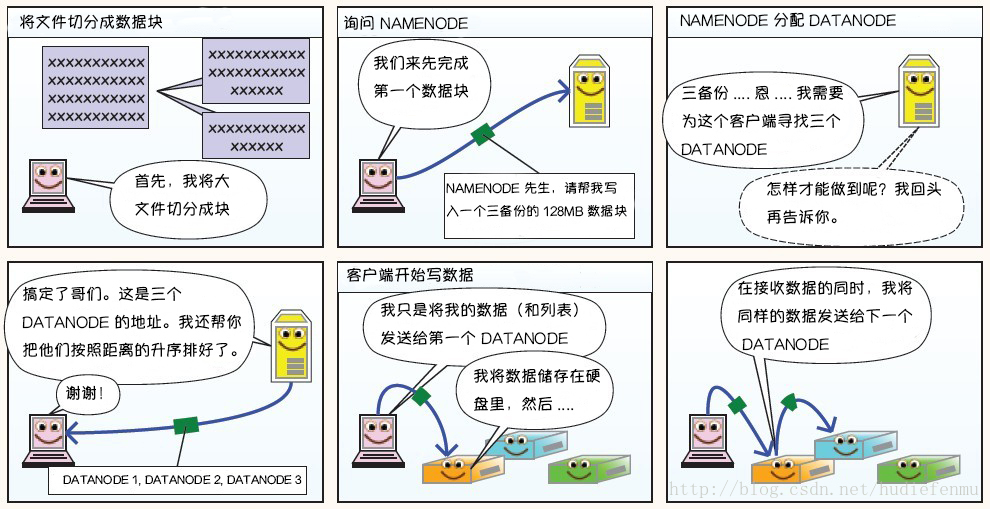
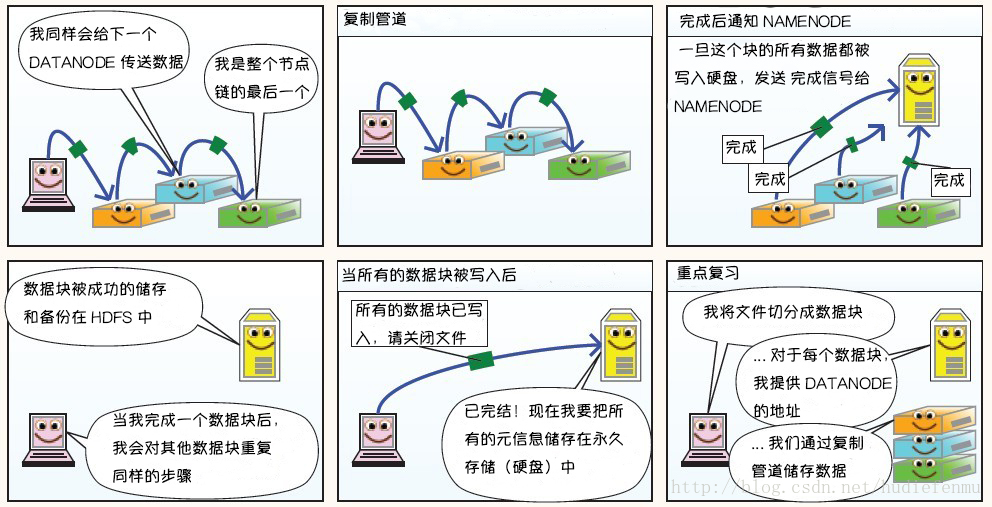
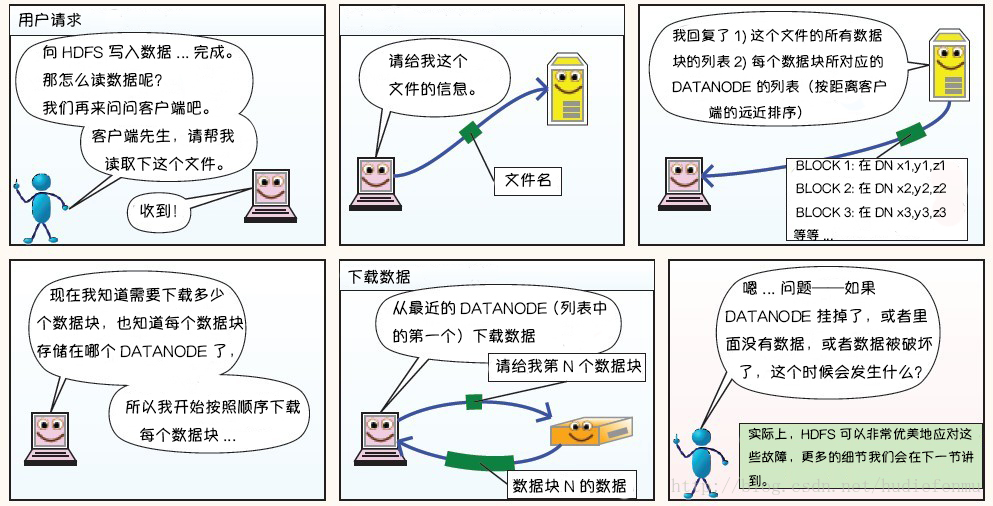
2. HDFS讀數據原理
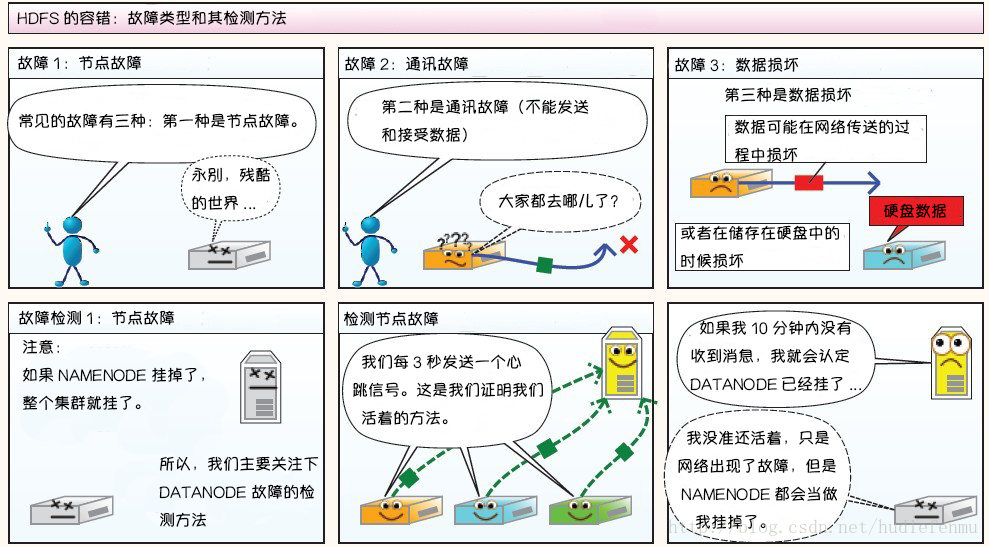
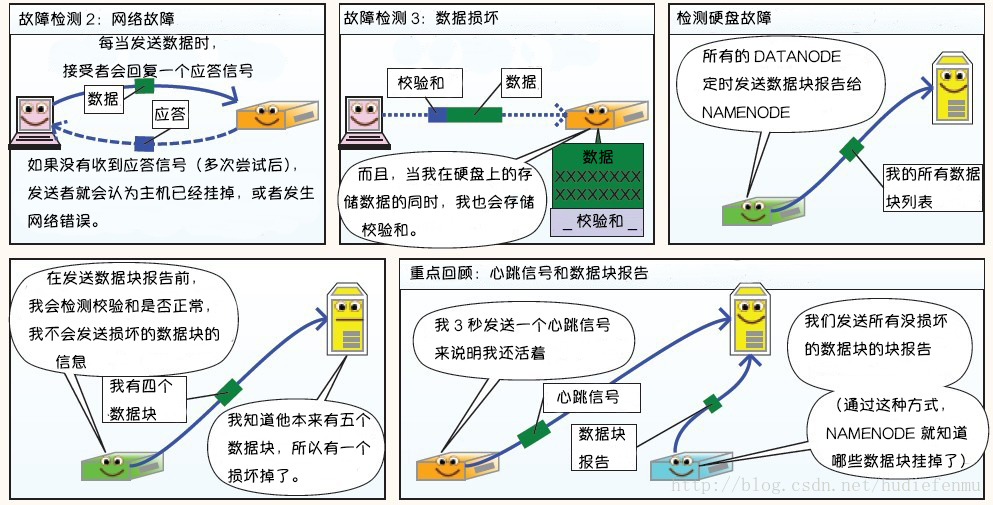
3. HDFS故障類型和其檢測方法
第二部分:讀寫故障的處理
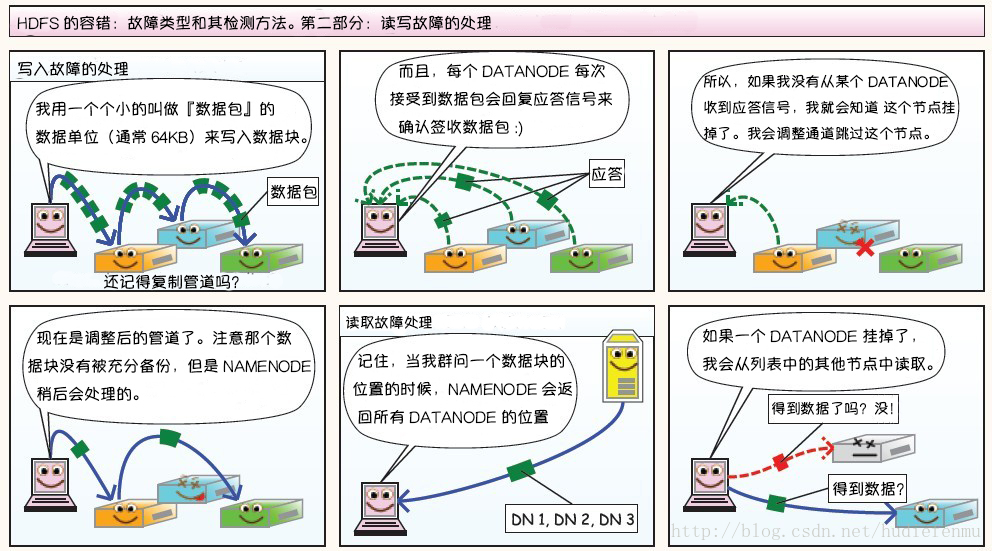
第三部分:DataNode 故障處理
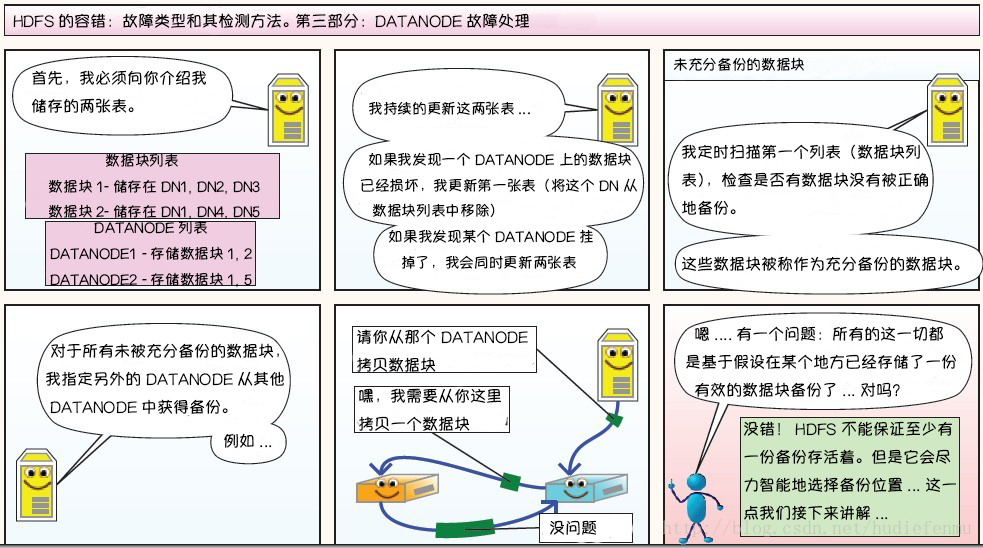
副本布局策略:
參考資料
- Apache Hadoop 2.9.2 > HDFS Architecture
- Tom White . hadoop 權威指南 [M] . 清華大學出版社 . 2017.
- 翻譯經典 HDFS 原理講解漫畫
更多大數據系列文章可以參見 GitHub 開源項目: 大數據入門指南
