利用Python科學計算處理物理問題(和物理告個別)
- 2020 年 5 月 21 日
- 筆記
背景:
- 2019年初由於尚未學習量子力學相關知識,所以處於自學階段。淺顯的學習了曾謹言的量子力學一卷和格里菲斯編寫的量子力學教材。注重將量子力學的一些基本概念了解並理解。同時老師向我們推薦了Quantum Computation and Quantum Information 這本教材,了解了量子資訊相關知識。
- 2019年暑假開始量子力學課程的學習,在導師的推薦下,從APS(美國物理學會)和AIP(美國物理聯合會)下載了與量子糾纏(Quantum Discord)相關的著名的文獻和會議報告,了解了量子資訊的發展歷程和一些傑出的理論。其中Unified View of Quantum and Classical Correlations 和Quantum Discord :A Measure of Quantumness of Correlations兩篇文章影響最為深刻。對量子資訊領域有了初步認識。
- 我也參加了相關的量子相關的報告,譬如12月18日陸朝陽教授的量子光學與量子計算背景和進程介紹,2019年10月9日郭光燦院士的《量子之問》,這些講座都激發了我對量子計算、量子通訊的興趣。
- 我也利用空閑時間自學了python,掌握了實驗編程所需要的基本技能,強化了自己在編程方面的知識,也學會部分LATEX進行論文編寫。
- 在參加項目過程中,雖然對投身於人類探索未知及其佩服,但終究自知窮極一生也極難在物理基礎領域做出傑出貢獻,就此轉向電腦,願盡綿薄之力,用技術為社會做一些有價值有意義之事。
科學計算,利用python進行相關影像整理。學會了基本的3d影像,numpy,matpolib繪圖工具。老實說一些底層的原理並不清楚,但還是可以總結一些經驗教訓的。
1. 繪製圓柱體,利用小技巧q/q,看似是1,實際上是生成了1的一個數組。

如上圖,我們希望將這樣的二維影像縱向拉伸變成類似於圓柱體一樣的三維影像,與另外的影像進行對比,但沒有找到相關方法,因為這是二維影像,想要實現三維立體圖就需要有兩個變數作為基底,而pAB是一個單變數函數,想要加入一個變數卻不改變它最終的函數值似乎是不可能實現的。
我嘗試用1去直接作為第二個變數,但執行無法通過,當時沒有想明白。(後面會說明)
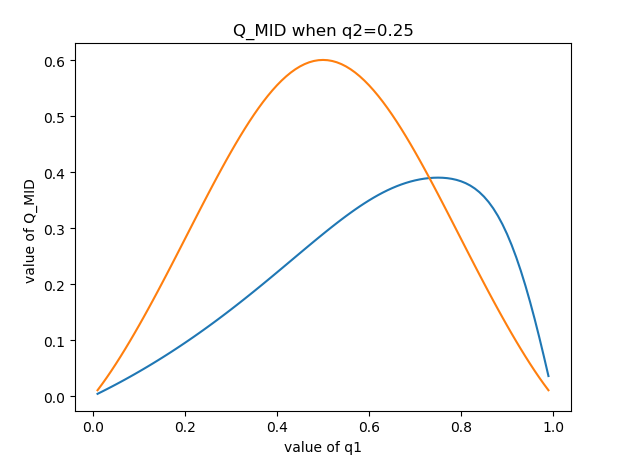
靈機一動,我嘗試用q2的具體函數值去代替q2取遍0-1之間所有常數,直接乘個q2試試?然後就有了下圖。但不行啊,想要q2取遍0-1所有值,又要q2在函數中顯示,不好搞。

那,要不再除個q2試試???然後就卧槽了,成功了。???。當時就很迷惑,這個和直接乘1有什麼區別? *q2/q2,不就是*1嗎?然後分析發現,發現通過*q2/q2操作,實際上是生成了一個全是1的數組,這樣就達到了形成二維基底的基本要求,從而畫出了三維影像。
import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D q1 = np.arange(0.01, 1, 0.01) q2 = np.arange(0.01, 1 , 0.01) //生成一位基底 q1, q2 = np.meshgrid(q1, q2) // 混合成二維數組,形成二維基底 pCDa = (1-q1) pCDb = (np.sqrt((1-q1)**2+q1**2)-q1) alpha = (pCDa + pCDb) / (pCDa + 4 * pCDb) beta = pCDb / (pCDa + 4 * pCDb) pCDp00 = ( q1* pCDa ** 2 ) / ( pCDa*pCDa +pCDb*pCDb) pCDp10 = ( q1* pCDb ** 2 ) / ( pCDa*pCDa +pCDb*pCDb) pCDp01 = ( (1-q1) / 2 ) * ( pCDa + pCDb ) ** 2 / ( pCDa*pCDa +pCDb*pCDb) pCDp11 = ( (1-q1) / 2 ) * ( pCDa - pCDb ) ** 2 / ( pCDa*pCDa +pCDb*pCDb) s_x_pCD= -pCDp00 * np.log2(pCDp00) - pCDp01 * np.log2(pCDp01) - pCDp10 * np.log2(pCDp10) - pCDp11 * np.log2(pCDp11) s_pCD = -q1* np.log2(q1) - (1-q1) * np.log2(1-q1) Q_MID1 = (s_x_pCD - s_pCD) *q2 /q2 #AB或CD的關聯值 fig = plt.figure() ax = Axes3D(fig) ax.plot_surface(q1,q2,Q_MID1) ax.set_xlabel('value of q2') ax.set_ylabel('value of q1') ax.set_zlabel('the value of Q_MID1(pCD)') plt.show()
2. 尋找影像交點,並沒有使用到複雜的方法,而是簡單的使用了精度為0.01周圍四個點函數值相加取平均值。但數值分析裡面一定說過相關的方法。
下面簡單介紹下數值分析基本內容。
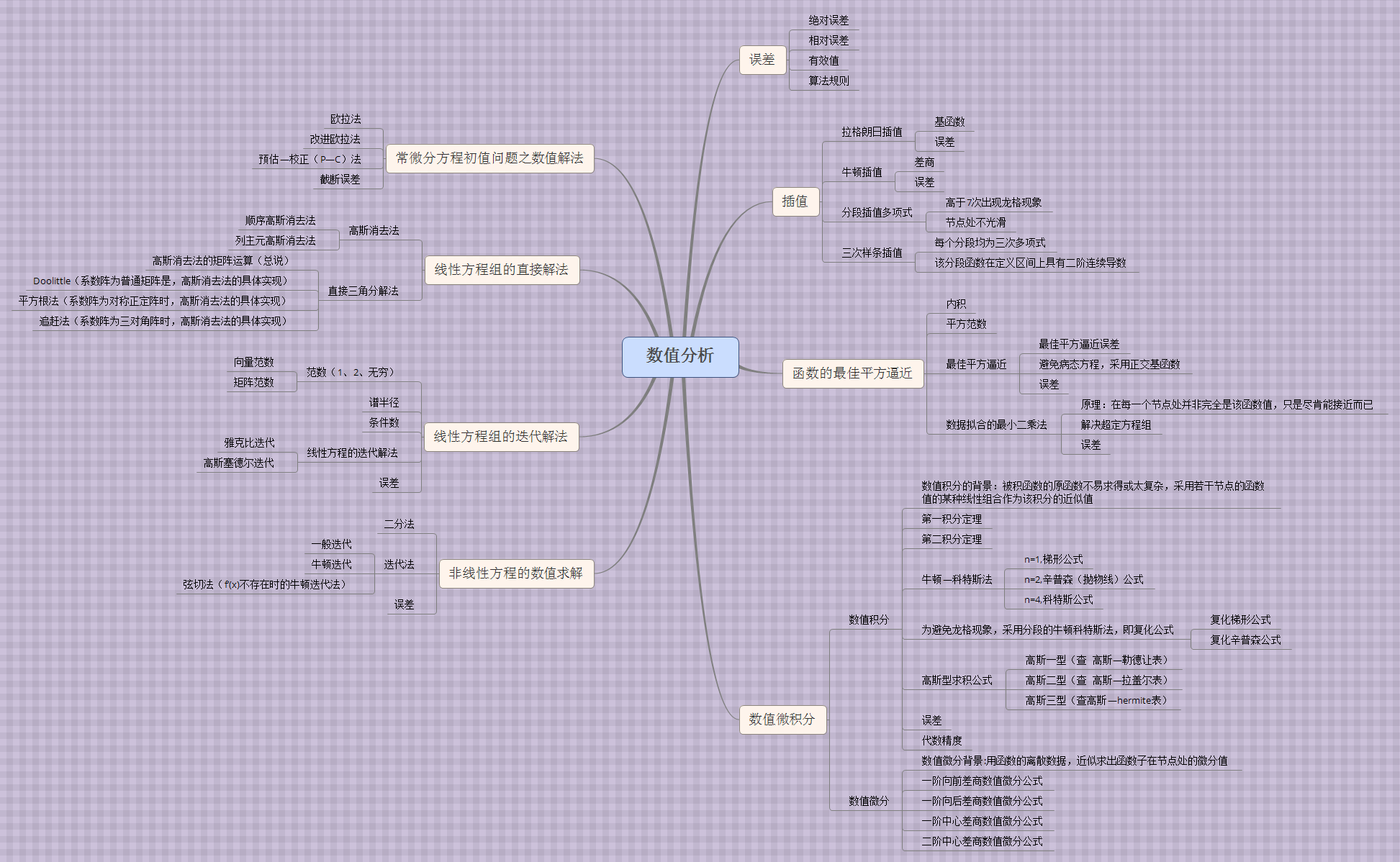
1、誤差分析
模型誤差(理論到模型,忽略次要因素必然帶來誤差)
觀測誤差
截斷誤差(無限到有限)
舍入誤差(無理數到有理數)
2、求非線性方程組 f(x)=0的解
x = g(x) 的迭代法(fixed point)
牛頓-拉夫森法(Newton-Raphson)和割線法(Secant Methods)
3、求線性方程組 AX=B 的數值解法
高斯消元法(LU分解)
迭代法
雅各比行列式
高斯賽德爾
4、插值和多項式逼近
拉格朗日逼近
牛頓多項式
切比雪夫多項式
帕德逼近
5、曲線擬合
最小二乘法擬合曲線
樣條函數插值
貝賽爾曲線
6、數值積分
組合梯形公式和辛普森公式
遞歸公式和龍貝格積分
高斯勒讓德積分
7、微分方程求解
歐拉方法
休恩方法
我們希望求這個交點,算是求解非線性方程 f(x) = 0。
嘗試用牛頓拉普森方法求解。(其實就是將試位法斜率用 f ‘ (x) 代替)

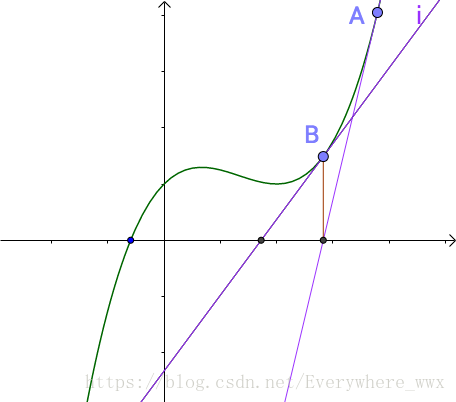

看起來還不錯,我們試著放到項目上
割線法

3. 一些細節處理,比如將影像內置邊框,影像標註等
plt.text(0,1,r'$max\ is\ 1.34$') //在0,1處標註最大值是1.34 plt.ylabel('value of Q_MID ') plt.xlabel('value of q1') //對x,y軸進行說明 plt.title('Q_MID when q1=q2') //標題名稱 # 設置xtick和ytick的方向:in、out plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' #設置橫縱坐標的名稱以及對應字體格式 font2 = {'family' : 'Times New Roman', 'weight' : 'normal', 'size' : 14, } plt.ylabel('MID ', font2)
4. 然後附上一些好的資源,官網和查找過程中找到的優質資源。
//matplotlib.org/gallery/index.html //matplotlib官網文檔,有著大量實例可以參考
然後附上搜來的許多Matplotlib圖的匯總
//mp.weixin.qq.com/s?__biz=MzU4NjIxODMyOQ==&mid=2247488568&idx=6&sn=f80d6f5c540058aa6c0d5de97e3a8f1d&chksm=fdfffa0eca887318bc426ef057707f7271624fb39a44595db8a042503a82ff638d707760ce02&mpshare=1&scene=23&srcid=&sharer_sharetime=1588477717826&sharer_shareid=aa22f4d6a3d78a43601dd5a37b40202c#rd
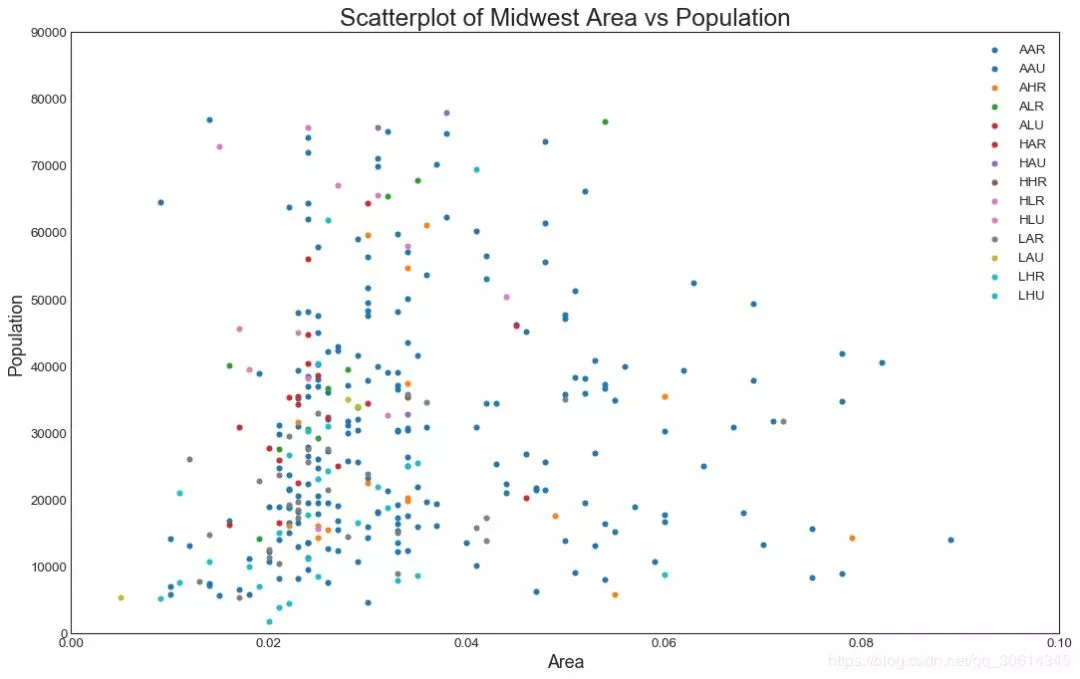
1. 散點圖 Scatteplot是用於研究兩個變數之間關係的經典和基本圖。如果數據中有多個組,則可能需要以不同顏色可視化每個組。在Matplotlib,你可以方便地使用。 # Import dataset midwest = pd.read_csv("//raw.githubusercontent.com/selva86/datasets/master/midwest_filter.csv") # Prepare Data # Create as many colors as there are unique midwest['category'] categories = np.unique(midwest['category']) colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))] # Draw Plot for Each Category plt.figure(figsize=(16, 10), dpi= 80, facecolor='w', edgecolor='k') for i, category in enumerate(categories): plt.scatter('area', 'poptotal', data=midwest.loc[midwest.category==category, :], s=20, c=colors[i], label=str(category)) # Decorations plt.gca().set(xlim=(0.0, 0.1), ylim=(0, 90000), xlabel='Area', ylabel='Population') plt.xticks(fontsize=12); plt.yticks(fontsize=12) plt.title("Scatterplot of Midwest Area vs Population", fontsize=22) plt.legend(fontsize=12) plt.show()
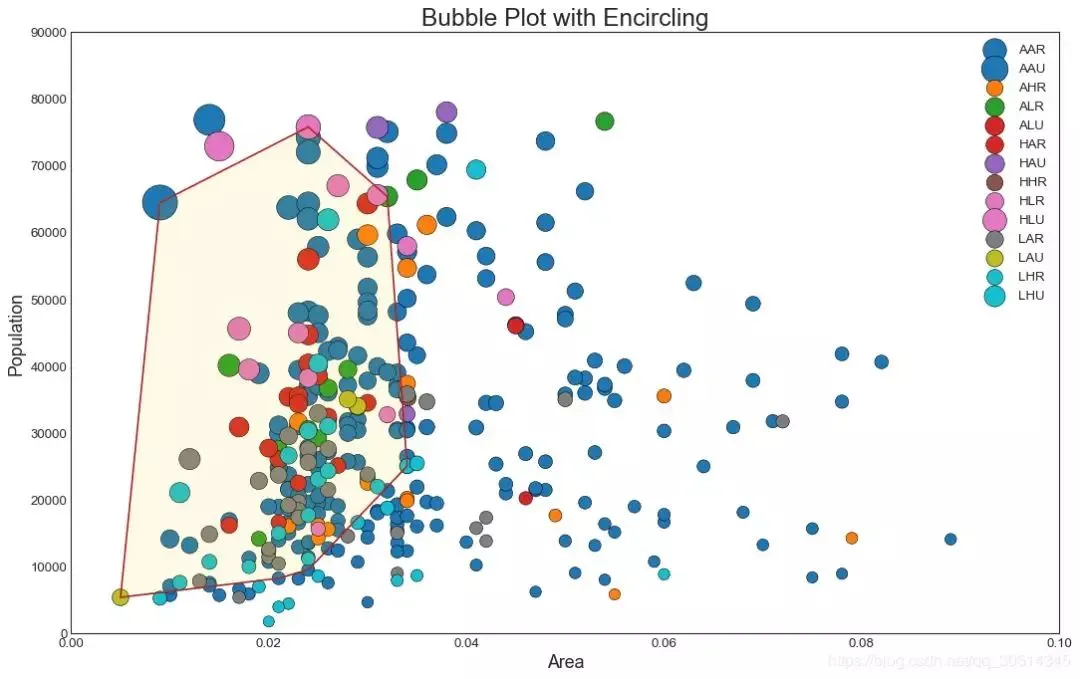
2. 帶邊界的氣泡圖 有時,您希望在邊界內顯示一組點以強調其重要性。在此示例中,您將從應該被環繞的數據幀中獲取記錄,並將其傳遞給下面的程式碼中描述的記錄。encircle() from matplotlib import patches from scipy.spatial import ConvexHull import warnings; warnings.simplefilter('ignore') sns.set_style("white") # Step 1: Prepare Data midwest = pd.read_csv("//raw.githubusercontent.com/selva86/datasets/master/midwest_filter.csv") # As many colors as there are unique midwest['category'] categories = np.unique(midwest['category']) colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))] # Step 2: Draw Scatterplot with unique color for each category fig = plt.figure(figsize=(16, 10), dpi= 80, facecolor='w', edgecolor='k') for i, category in enumerate(categories): plt.scatter('area', 'poptotal', data=midwest.loc[midwest.category==category, :], s='dot_size', c=colors[i], label=str(category), edgecolors='black', linewidths=.5) # Step 3: Encircling # //stackoverflow.com/questions/44575681/how-do-i-encircle-different-data-sets-in-scatter-plot def encircle(x,y, ax=None, **kw): if not ax: ax=plt.gca() p = np.c_[x,y] hull = ConvexHull(p) poly = plt.Polygon(p[hull.vertices,:], **kw) ax.add_patch(poly) # Select data to be encircled midwest_encircle_data = midwest.loc[midwest.state=='IN', :] # Draw polygon surrounding vertices encircle(midwest_encircle_data.area, midwest_encircle_data.poptotal, ec="k", fc="gold", alpha=0.1) encircle(midwest_encircle_data.area, midwest_encircle_data.poptotal, ec="firebrick", fc="none", linewidth=1.5) # Step 4: Decorations plt.gca().set(xlim=(0.0, 0.1), ylim=(0, 90000), xlabel='Area', ylabel='Population') plt.xticks(fontsize=12); plt.yticks(fontsize=12) plt.title("Bubble Plot with Encircling", fontsize=22) plt.legend(fontsize=12) plt.show()
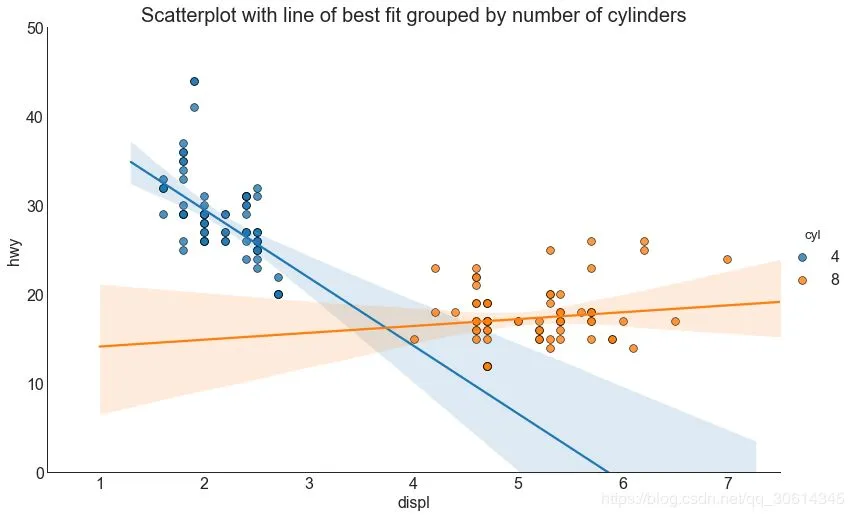
3. 帶線性回歸最佳擬合線的散點圖 如果你想了解兩個變數如何相互改變,那麼最合適的線就是要走的路。下圖顯示了數據中各組之間最佳擬合線的差異。要禁用分組並僅為整個數據集繪製一條最佳擬合線,請從下面的調用中刪除該參數。 # Import Data df = pd.read_csv("//raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv") df_select = df.loc[df.cyl.isin([4,8]), :] # Plot sns.set_style("white") gridobj = sns.lmplot(x="displ", y="hwy", hue="cyl", data=df_select, height=7, aspect=1.6, robust=True, palette='tab10', scatter_kws=dict(s=60, linewidths=.7, edgecolors='black')) # Decorations gridobj.set(xlim=(0.5, 7.5), ylim=(0, 50)) plt.title("Scatterplot with line of best fit grouped by number of cylinders",
每個回歸線都在自己的列中 或者,您可以在其自己的列中顯示每個組的最佳擬合線。你可以通過在裡面設置參數來實現這一點。 # Import Data df = pd.read_csv("//raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv") df_select = df.loc[df.cyl.isin([4,8]), :] # Each line in its own column sns.set_style("white") gridobj = sns.lmplot(x="displ", y="hwy", data=df_select, height=7, robust=True, palette='Set1', col="cyl", scatter_kws=dict(s=60, linewidths=.7, edgecolors='black')) # Decorations gridobj.set(xlim=(0.5, 7.5), ylim=(0, 50)) plt.show()
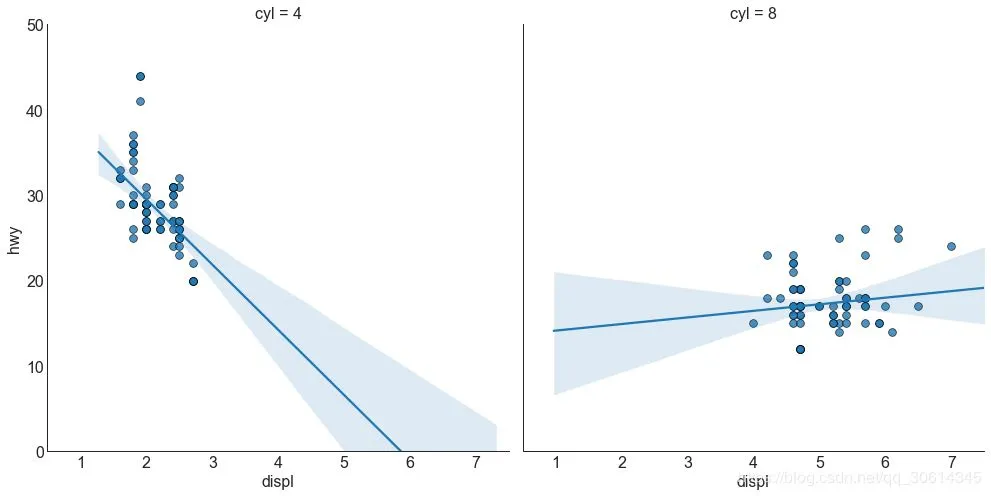
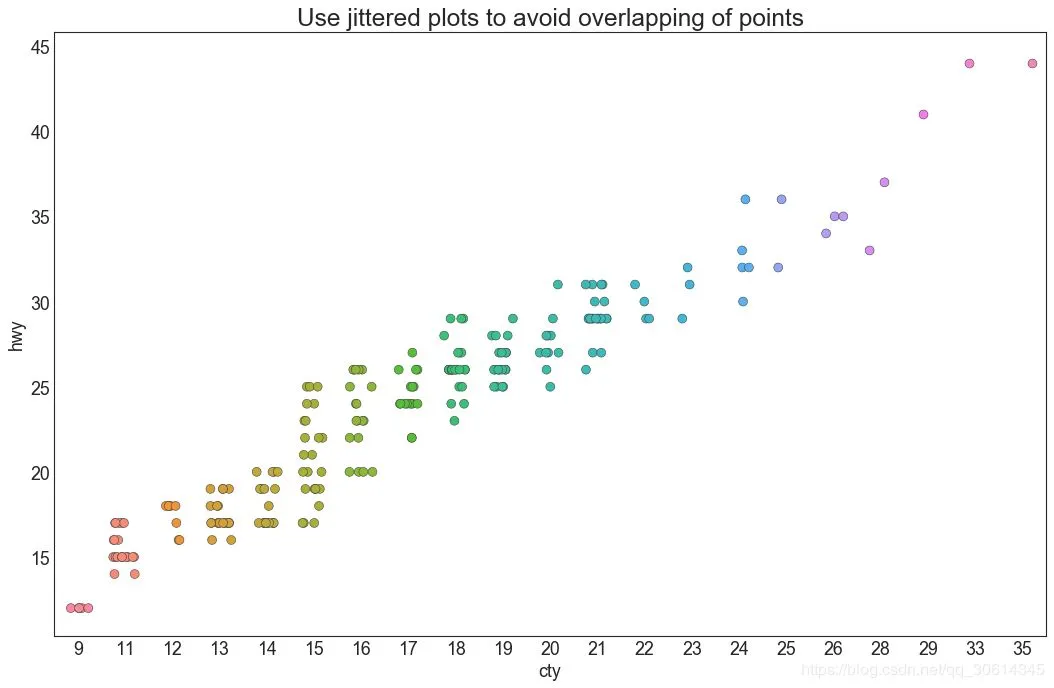
4. 抖動圖 通常,多個數據點具有完全相同的X和Y值。結果,多個點相互繪製並隱藏。為避免這種情況,請稍微抖動點,以便您可以直觀地看到它們。這很方便使用 # Import Data df = pd.read_csv("//raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv") # Draw Stripplot fig, ax = plt.subplots(figsize=(16,10), dpi= 80) sns.stripplot(df.cty, df.hwy, jitter=0.25, size=8, ax=ax, linewidth=.5) # Decorations plt.title('Use jittered plots to avoid overlapping of points', fontsize=22) plt.show()
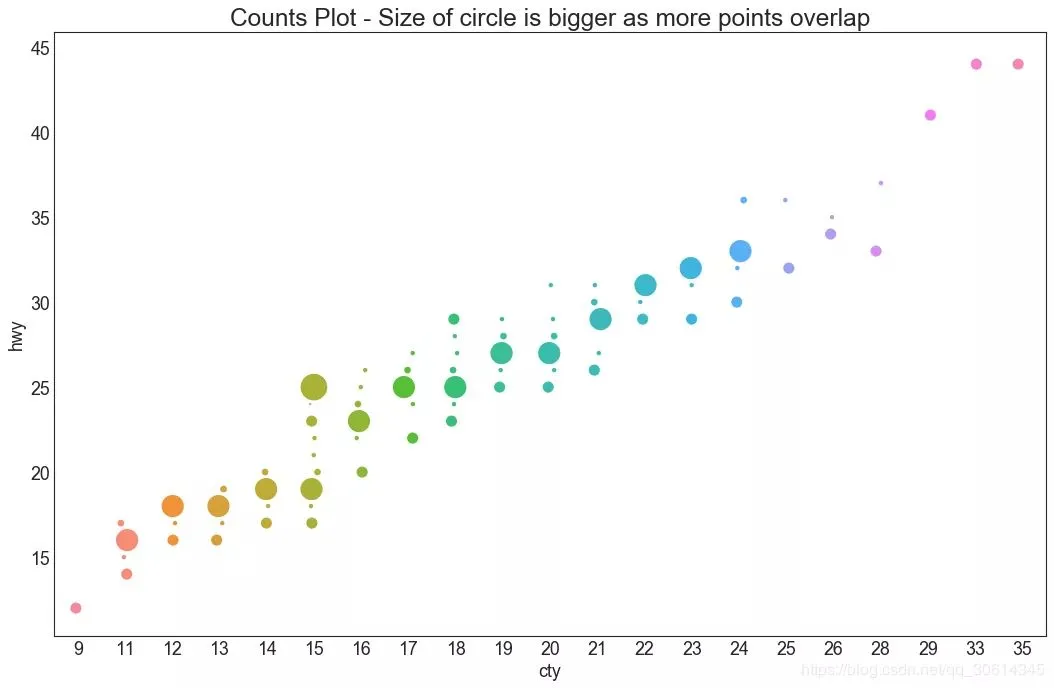
5. 計數圖 避免點重疊問題的另一個選擇是增加點的大小,這取決於該點中有多少點。因此,點的大小越大,周圍的點的集中度就越大。 # Import Data df = pd.read_csv("//raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv") df_counts = df.groupby(['hwy', 'cty']).size().reset_index(name='counts') # Draw Stripplot fig, ax = plt.subplots(figsize=(16,10), dpi= 80) sns.stripplot(df_counts.cty, df_counts.hwy, size=df_counts.counts*2, ax=ax) # Decorations plt.title('Counts Plot - Size of circle is bigger as more points overlap', fontsize=22) plt.show()
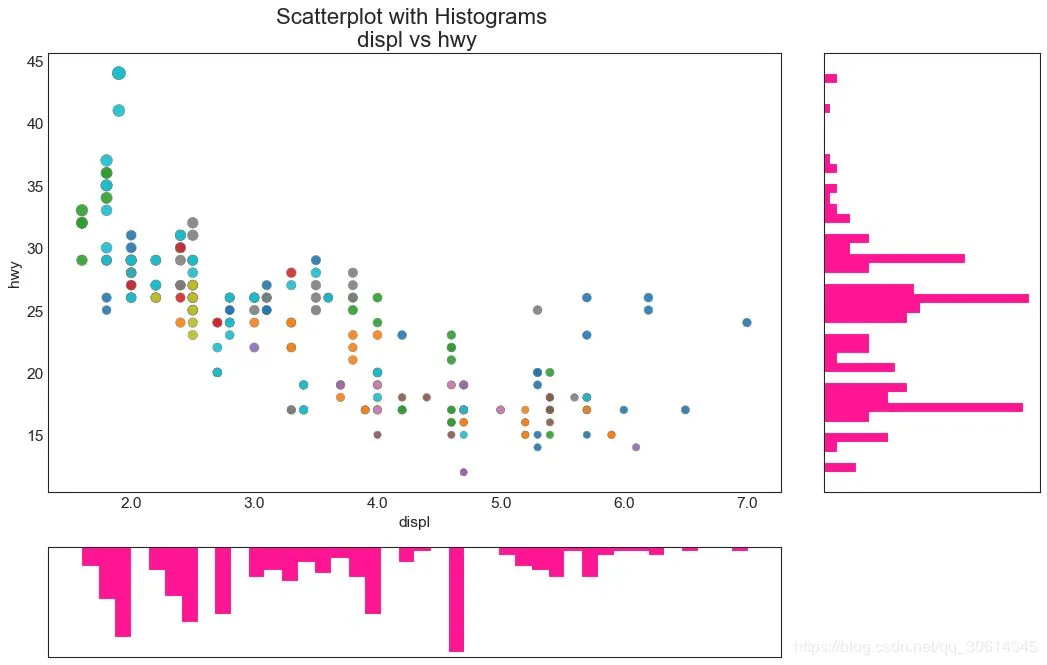
6. 邊緣直方圖 邊緣直方圖具有沿X和Y軸變數的直方圖。這用於可視化X和Y之間的關係以及單獨的X和Y的單變數分布。該圖如果經常用於探索性數據分析(EDA)。 # Import Data df = pd.read_csv("//raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv") # Create Fig and gridspec fig = plt.figure(figsize=(16, 10), dpi= 80) grid = plt.GridSpec(4, 4, hspace=0.5, wspace=0.2) # Define the axes ax_main = fig.add_subplot(grid[:-1, :-1]) ax_right = fig.add_subplot(grid[:-1, -1], xticklabels=[], yticklabels=[]) ax_bottom = fig.add_subplot(grid[-1, 0:-1], xticklabels=[], yticklabels=[]) # Scatterplot on main ax ax_main.scatter('displ', 'hwy', s=df.cty*4, c=df.manufacturer.astype('category').cat.codes, alpha=.9, data=df, cmap="tab10", edgecolors='gray', linewidths=.5) # histogram on the right ax_bottom.hist(df.displ, 40, histtype='stepfilled', orientation='vertical', color='deeppink') ax_bottom.invert_yaxis() # histogram in the bottom ax_right.hist(df.hwy, 40, histtype='stepfilled', orientation='horizontal', color='deeppink') # Decorations ax_main.set(title='Scatterplot with Histograms displ vs hwy', xlabel='displ', ylabel='hwy') ax_main.title.set_fontsize(20) for item in ([ax_main.xaxis.label, ax_main.yaxis.label] + ax_main.get_xticklabels() + ax_main.get_yticklabels()): item.set_fontsize(14) xlabels = ax_main.get_xticks().tolist() ax_main.set_xticklabels(xlabels) plt.show()
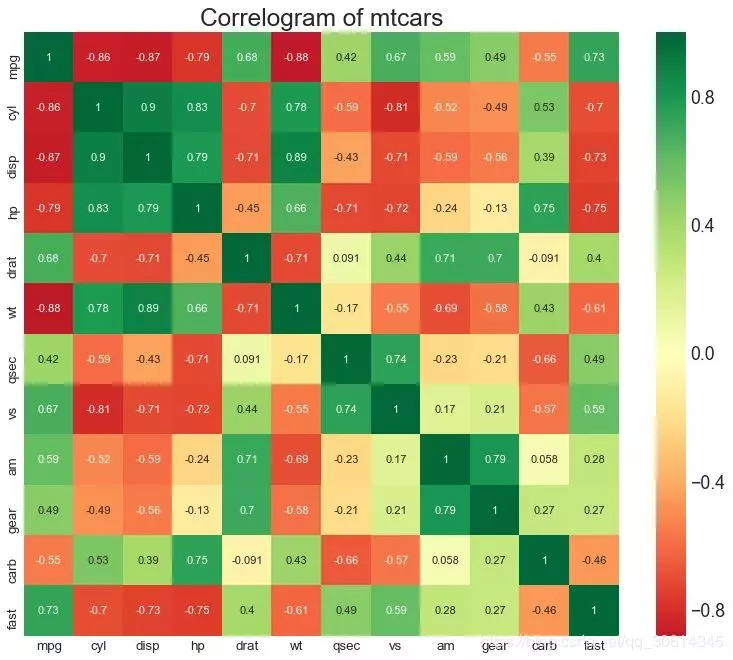
相關圖 Correlogram用於直觀地查看給定數據幀(或2D數組)中所有可能的數值變數對之間的相關度量。 # Import Dataset df = pd.read_csv("//github.com/selva86/datasets/raw/master/mtcars.csv") # Plot plt.figure(figsize=(12,10), dpi= 80) sns.heatmap(df.corr(), xticklabels=df.corr().columns, yticklabels=df.corr().columns, cmap='RdYlGn', center=0, annot=True) # Decorations plt.title('Correlogram of mtcars', fontsize=22) plt.xticks(fontsize=12) plt.yticks(fontsize=12) plt.show()
9. 矩陣圖 成對圖是探索性分析中的最愛,以理解所有可能的數字變數對之間的關係。它是雙變數分析的必備工具。 # Load Dataset df = sns.load_dataset('iris') # Plot plt.figure(figsize=(10,8), dpi= 80) sns.pairplot(df, kind="scatter", hue="species", plot_kws=dict(s=80, edgecolor="white", linewidth=2.5)) plt.show()

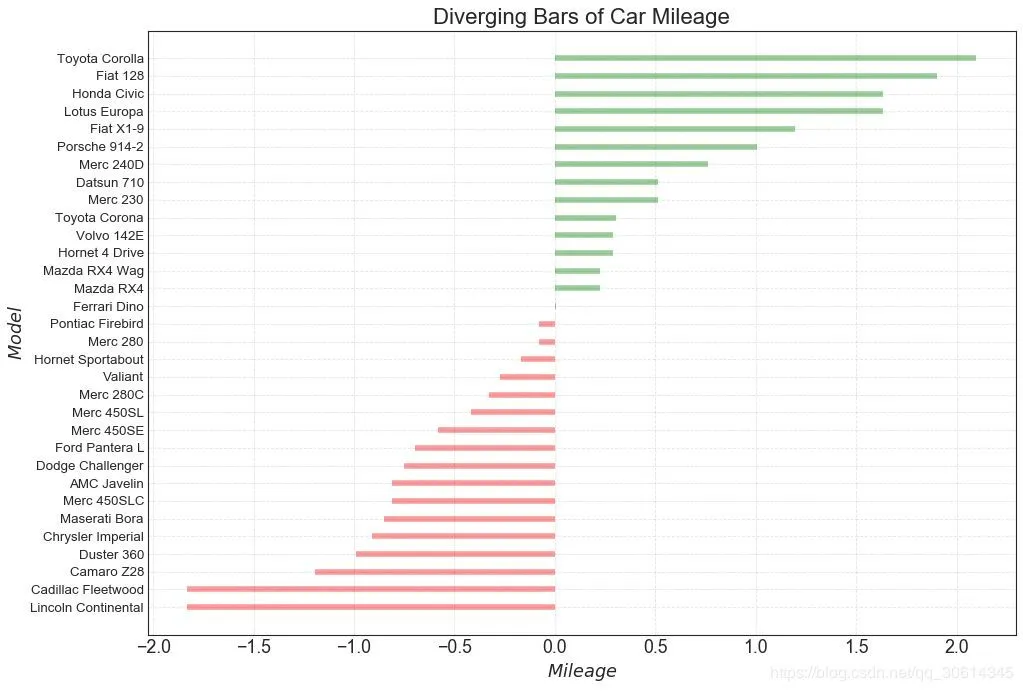
# Prepare Data df = pd.read_csv("//github.com/selva86/datasets/raw/master/mtcars.csv") x = df.loc[:, ['mpg']] df['mpg_z'] = (x - x.mean())/x.std() df['colors'] = ['red' if x < 0 else 'green' for x in df['mpg_z']] df.sort_values('mpg_z', inplace=True) df.reset_index(inplace=True) # Draw plot plt.figure(figsize=(14,10), dpi= 80) plt.hlines(y=df.index, xmin=0, xmax=df.mpg_z, color=df.colors, alpha=0.4, linewidth=5) # Decorations plt.gca().set(ylabel='$Model$', xlabel='$Mileage$') plt.yticks(df.index, df.cars, fontsize=12) plt.title('Diverging Bars of Car Mileage', fontdict={'size':20}) plt.grid(linestyle='--', alpha=0.5) plt.show()
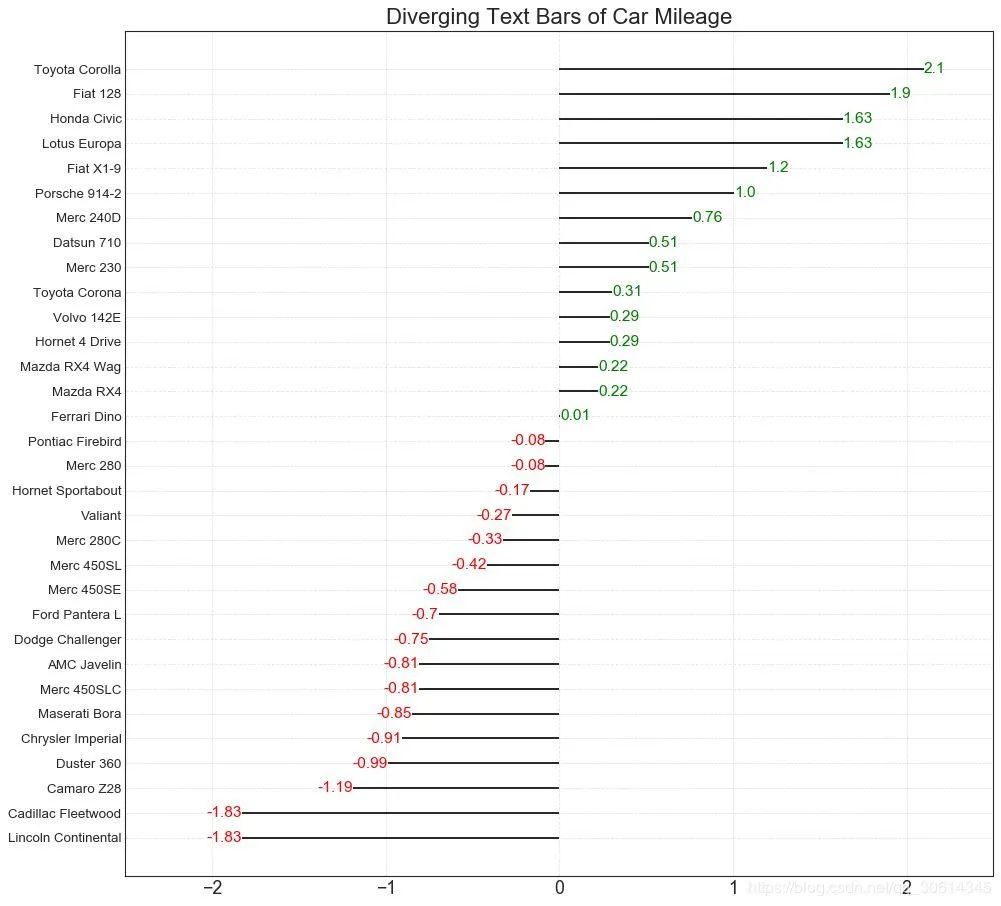
發散型文本 分散的文本類似於發散條,如果你想以一種漂亮和可呈現的方式顯示圖表中每個項目的價值,它更喜歡。 # Prepare Data df = pd.read_csv("//github.com/selva86/datasets/raw/master/mtcars.csv") x = df.loc[:, ['mpg']] df['mpg_z'] = (x - x.mean())/x.std() df['colors'] = ['red' if x < 0 else 'green' for x in df['mpg_z']] df.sort_values('mpg_z', inplace=True) df.reset_index(inplace=True) # Draw plot plt.figure(figsize=(14,14), dpi= 80) plt.hlines(y=df.index, xmin=0, xmax=df.mpg_z) for x, y, tex in zip(df.mpg_z, df.index, df.mpg_z): t = plt.text(x, y, round(tex, 2), horizontalalignment='right' if x < 0 else 'left', verticalalignment='center', fontdict={'color':'red' if x < 0 else 'green', 'size':14}) # Decorations plt.yticks(df.index, df.cars, fontsize=12) plt.title('Diverging Text Bars of Car Mileage', fontdict={'size':20}) plt.grid(linestyle='--', alpha=0.5) plt.xlim(-2.5, 2.5) plt.show()
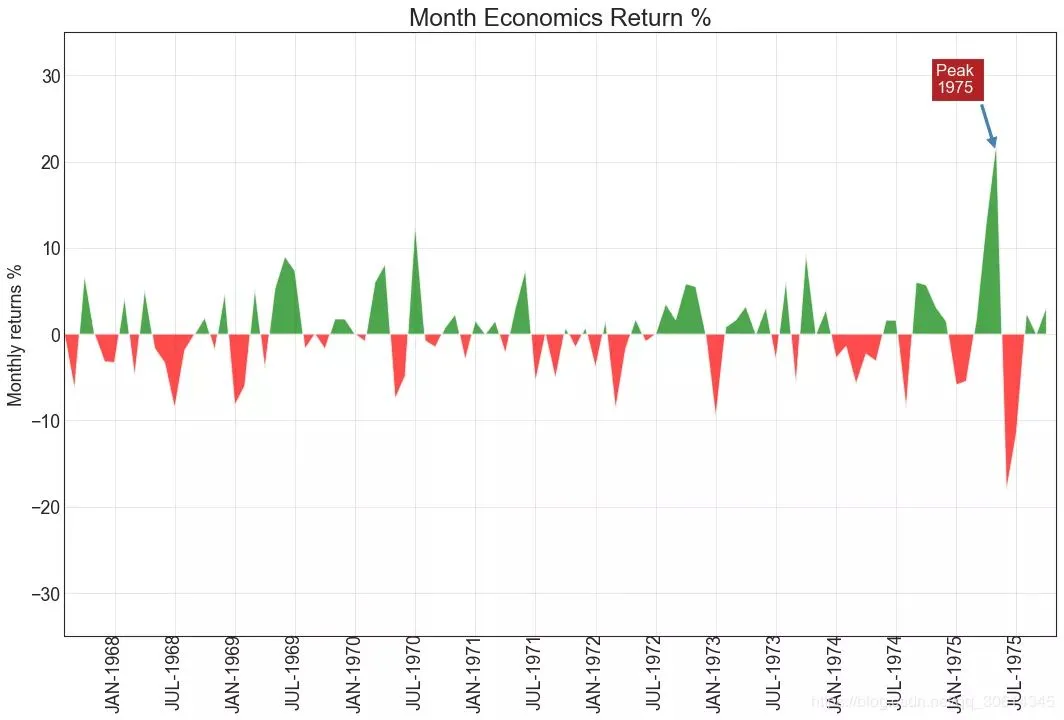
面積圖 通過對軸和線之間的區域進行著色,區域圖不僅強調峰值和低谷,而且還強調高點和低點的持續時間。高點持續時間越長,線下面積越大。 import numpy as np import pandas as pd # Prepare Data df = pd.read_csv("//github.com/selva86/datasets/raw/master/economics.csv", parse_dates=['date']).head(100) x = np.arange(df.shape[0]) y_returns = (df.psavert.diff().fillna(0)/df.psavert.shift(1)).fillna(0) * 100 # Plot plt.figure(figsize=(16,10), dpi= 80) plt.fill_between(x[1:], y_returns[1:], 0, where=y_returns[1:] >= 0, facecolor='green', interpolate=True, alpha=0.7) plt.fill_between(x[1:], y_returns[1:], 0, where=y_returns[1:] <= 0, facecolor='red', interpolate=True, alpha=0.7) # Annotate plt.annotate('Peak 1975', xy=(94.0, 21.0), xytext=(88.0, 28), bbox=dict(boxstyle='square', fc='firebrick'), arrowprops=dict(facecolor='steelblue', shrink=0.05), fontsize=15, color='white') # Decorations xtickvals = [str(m)[:3].upper()+"-"+str(y) for y,m in zip(df.date.dt.year, df.date.dt.month_name())] plt.gca().set_xticks(x[::6]) plt.gca().set_xticklabels(xtickvals[::6], rotation=90, fontdict={'horizontalalignment': 'center', 'verticalalignment': 'center_baseline'}) plt.ylim(-35,35) plt.xlim(1,100) plt.title("Month Economics Return %", fontsize=22) plt.ylabel('Monthly returns %') plt.grid(alpha=0.5) plt.show()
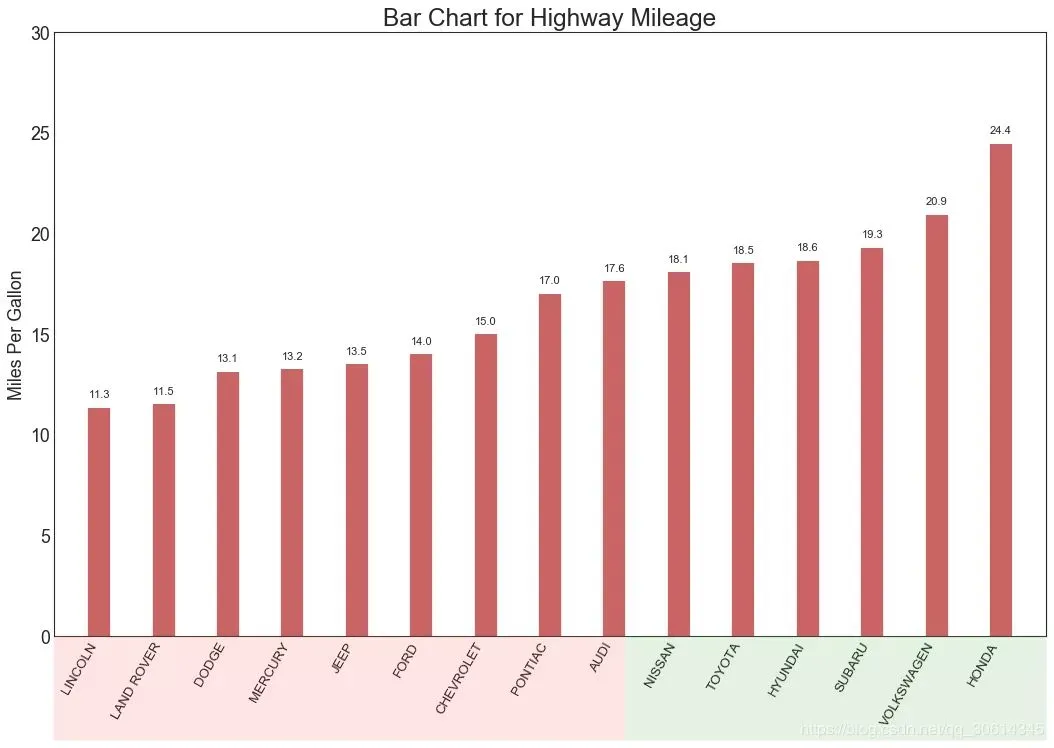
有序條形圖 有序條形圖有效地傳達了項目的排名順序。但是,在圖表上方添加度量標準的值,用戶可以從圖表本身獲取精確資訊。 # Prepare Data df_raw = pd.read_csv("//github.com/selva86/datasets/raw/master/mpg_ggplot2.csv") df = df_raw[['cty', 'manufacturer']].groupby('manufacturer').apply(lambda x: x.mean()) df.sort_values('cty', inplace=True) df.reset_index(inplace=True) # Draw plot import matplotlib.patches as patches fig, ax = plt.subplots(figsize=(16,10), facecolor='white', dpi= 80) ax.vlines(x=df.index, ymin=0, ymax=df.cty, color='firebrick', alpha=0.7, linewidth=20) # Annotate Text for i, cty in enumerate(df.cty): ax.text(i, cty+0.5, round(cty, 1), horizontalalignment='center') # Title, Label, Ticks and Ylim ax.set_title('Bar Chart for Highway Mileage', fontdict={'size':22}) ax.set(ylabel='Miles Per Gallon', ylim=(0, 30)) plt.xticks(df.index, df.manufacturer.str.upper(), rotation=60, horizontalalignment='right', fontsize=12) # Add patches to color the X axis labels p1 = patches.Rectangle((.57, -0.005), width=.33, height=.13, alpha=.1, facecolor='green', transform=fig.transFigure) p2 = patches.Rectangle((.124, -0.005), width=.446, height=.13, alpha=.1, facecolor='red', transform=fig.transFigure) fig.add_artist(p1) fig.add_artist(p2) plt.show()
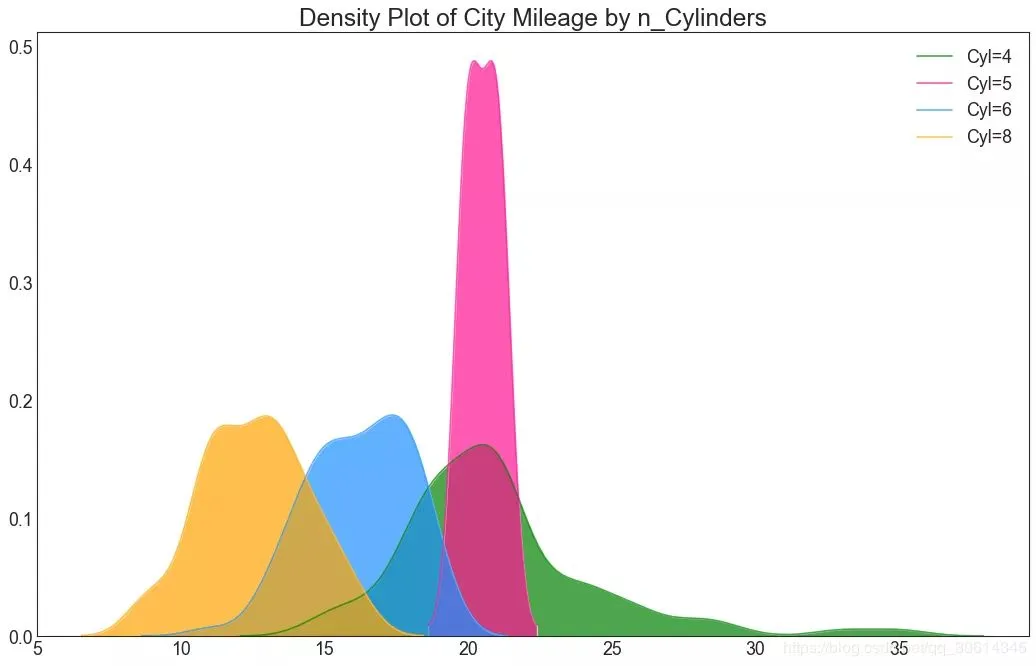
密度圖 密度圖是一種常用工具,可視化連續變數的分布。通過「響應」變數對它們進行分組,您可以檢查X和Y之間的關係。以下情況,如果出於代表性目的來描述城市裡程的分布如何隨著汽缸數的變化而變化。 # Import Data df = pd.read_csv("//github.com/selva86/datasets/raw/master/mpg_ggplot2.csv") # Draw Plot plt.figure(figsize=(16,10), dpi= 80) sns.kdeplot(df.loc[df['cyl'] == 4, "cty"], shade=True, color="g", label="Cyl=4", alpha=.7) sns.kdeplot(df.loc[df['cyl'] == 5, "cty"], shade=True, color="deeppink", label="Cyl=5", alpha=.7) sns.kdeplot(df.loc[df['cyl'] == 6, "cty"], shade=True, color="dodgerblue", label="Cyl=6", alpha=.7) sns.kdeplot(df.loc[df['cyl'] == 8, "cty"], shade=True, color="orange", label="Cyl=8", alpha=.7) # Decoration plt.title('Density Plot of City Mileage by n_Cylinders', fontsize=22) plt.legend()
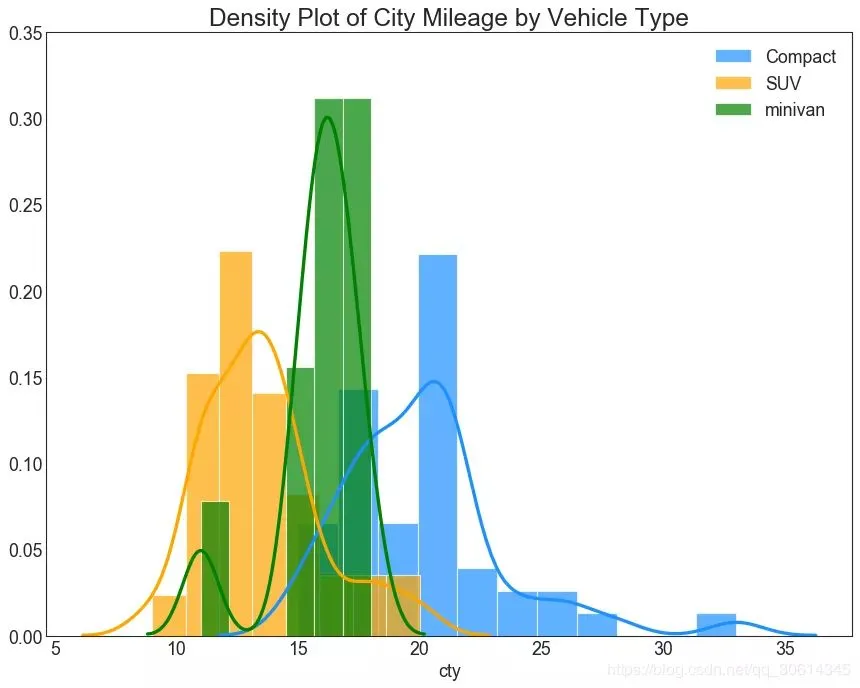
直方密度線圖 帶有直方圖的密度曲線將兩個圖表傳達的集體資訊彙集在一起,這樣您就可以將它們放在一個圖形而不是兩個圖形中。 # Import Data df = pd.read_csv("//github.com/selva86/datasets/raw/master/mpg_ggplot2.csv") # Draw Plot plt.figure(figsize=(13,10), dpi= 80) sns.distplot(df.loc[df['class'] == 'compact', "cty"], color="dodgerblue", label="Compact", hist_kws={'alpha':.7}, kde_kws={'linewidth':3}) sns.distplot(df.loc[df['class'] == 'suv', "cty"], color="orange", label="SUV", hist_kws={'alpha':.7}, kde_kws={'linewidth':3}) sns.distplot(df.loc[df['class'] == 'minivan', "cty"], color="g", label="minivan", hist_kws={'alpha':.7}, kde_kws={'linewidth':3}) plt.ylim(0, 0.35) # Decoration plt.title('Density Plot of City Mileage by Vehicle Type', fontsize=22) plt.legend() plt.show()