局部性原理——各類優化的基石
- 2019 年 10 月 3 日
- 筆記
學過電腦底層原理、了解過很多架構設計或者是做過優化的同學,應該很熟悉局部性原理。即便是非電腦行業的人,在做各種調優、提效時也不得不考慮到局部性,只不過他們不常用局部性一詞。如果抽象程度再高一些,甚至可以說地球、生命、萬事萬物都是局部性的產物,因為這些都是宇宙中熵分布布局、局部的熵低導致的,如果宇宙中處處熵一致,有的只有一篇混沌。
所以什麼是 局部性 ?這是一個常用的電腦術語,是指處理器在訪問某些數據時短時間記憶體在重複訪問,某些數據或者位置訪問的概率極大,大多數時間只訪問_局部_的數據。基於局部性原理,電腦處理器在設計時做了各種優化,比如現代CPU的多級Cache、分支預測…… 有良好局部性的程式比局部性差的程式運行得更快。雖然局部性一詞源於電腦設計,但在當今分散式系統、互聯網技術里也不乏局部性,比如像用redis這種memcache來減輕後端的壓力,CDN做素材分發減少頻寬佔用率……
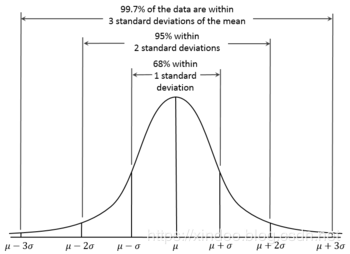
局部性的本質是什麼?其實就是概率的不均等,這個宇宙中,很多東西都不是平均分布的,平均分布是概率論中幾何分布的一種特殊形式,非常簡單,但世界就是沒這麼簡單。我們更長聽到的發布叫做高斯發布,同時也被稱為正態分布,因為它就是正常狀態下的概率發布,起概率圖如下,但這個也不是今天要說的。
其實有很多情況,很多事物有很強的頭部集中現象,可以用概率論中的泊松分布來刻畫,這就是局部性在概率學中的刻畫形式。
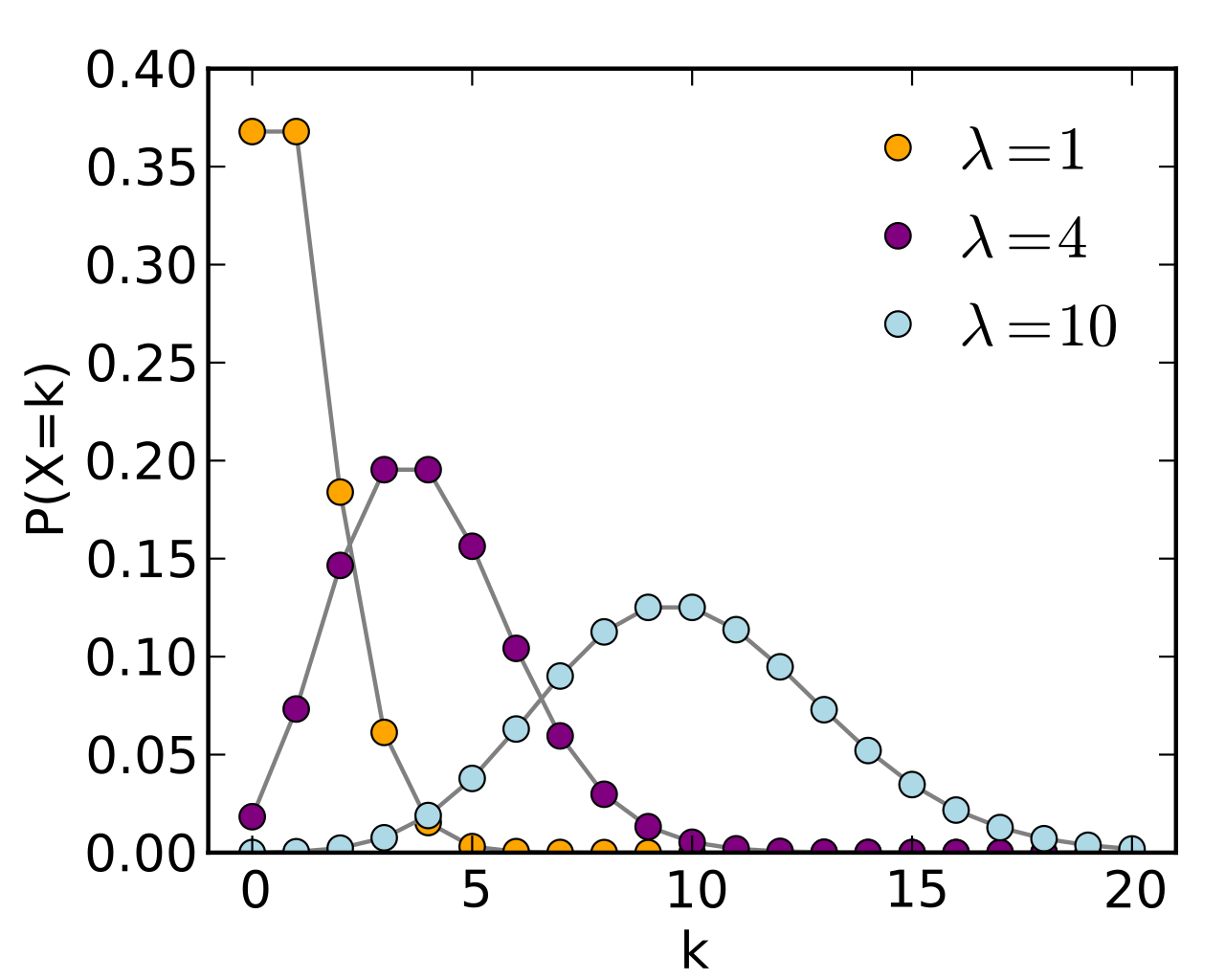
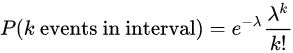
上面分別是泊松分布的示意圖和概率計算公式,$lambda$ 表示單位時間(或單位面積)內隨機事件的平均發生次數,$e$表示自然常數2.71828..,k表示事件發生的次數。要注意在刻畫局部性時$lambda$表示不命中高頻數據的頻度,$lambda$越小,頭部集中現象越明顯。
局部性分類
局部性有兩種基本的分類, 時間局部性 和 空間局部性 ,按Wikipedia的資料,可以分為以下五類,其實有些就是時間局部性和空間局部性的特殊情況。
時間局部性(Temporal locality):
如果某個資訊這次被訪問,那它有可能在不久的未來被多次訪問。時間局部性是空間局部性訪問地址一樣時的一種特殊情況。這種情況下,可以把常用的數據加cache來優化訪存。
空間局部性(Spatial locality):
如果某個位置的資訊被訪問,那和它相鄰的資訊也很有可能被訪問到。 這個也很好理解,我們大部分情況下程式碼都是順序執行,數據也是順序訪問的。
記憶體局部性(Memory locality):
訪問記憶體時,大概率會訪問連續的塊,而不是單一的記憶體地址,其實就是空間局部性在記憶體上的體現。目前電腦設計中,都是以塊/頁為單位管理調度存儲,其實就是在利用空間局部性來優化性能。
分支局部性(Branch locality)
這個又被稱為順序局部性,電腦中大部分指令是順序執行,順序執行和非順序執行的比例大致是5:1,即便有if這種選擇分支,其實大多數情況下某個分支都是被大概率選中的,於是就有了CPU的分支預測優化。
等距局部性(Equidistant locality)
等距局部性是指如果某個位置被訪問,那和它相鄰等距離的連續地址極有可能會被訪問到,它位於空間局部性和分支局部性之間。 舉個例子,比如多個相同格式的數據數組,你只取其中每個數據的一部分欄位,那麼他們可能在記憶體中地址距離是等距的,這個可以通過簡單的線性預測就預測是未來訪問的位置。
實際應用
電腦領域關於局部性非常多的利用,有很多你每天都會用到,但可能並沒有察覺,另外一些可能離你會稍微遠一些,接下來我們舉幾個例子來深入了解下局部性的應用。
電腦存儲層級結構
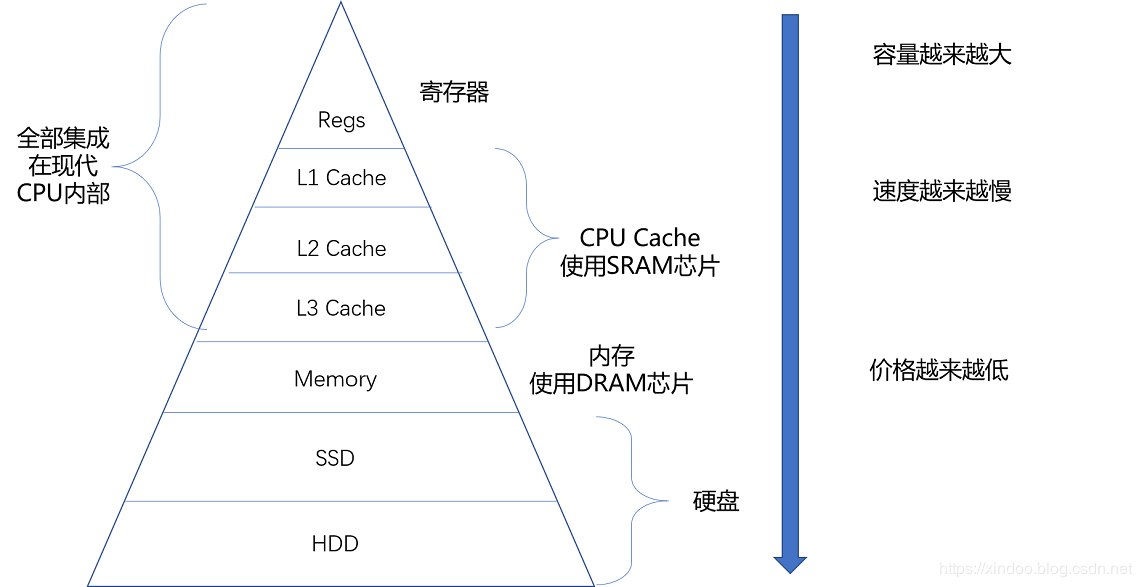
上圖來自極客時間徐文浩的《深入淺出電腦組成原理》,我們以目前常見的普通家用電腦為例 ,分別說下上圖各級存儲的大小和訪問速度,數據來源於https://people.eecs.berkeley.edu/~rcs/research/interactive_latency.html。

從最快的L1 Cache到最慢的HDD,其兩者的訪存時間差距達到了6個數量級,即便是和記憶體比較,也有幾百倍的差距。舉個例子,如果CPU在運算是直接從記憶體中讀取指令和數據,執行一條指令0.3ns,然後從記憶體讀下一條指令,等120ns,這樣CPU 99%計算時間都會被浪費掉。但就是因為有局部性的存在,每一層都只有少部分數據會被頻繁訪問,我們可以把這部分數據從底層存儲挪到高層存儲,可以降低大部分的數據讀取時間。
可能有些人好奇,為什麼不把L1 快取做的大點,像記憶體那麼大,直接替代掉記憶體,不是性能更好嗎?雖然是這樣,但是L1 Cache單位價格要比記憶體單位的價格貴好多(大概差200倍),有興趣可以了解下DRAM和SRAM。
我們可以通過編寫高速快取友好的程式碼邏輯來提升我們的程式碼性能,有兩個基本方法 。
- 讓最常見的情況運行的快,程式大部分的運行實際都花在少了核心函數上,而這些函數把大部分時間都花在少量循環上,把注意力放在這些程式碼上。
- 讓每個循環內快取不命中率最小。比如盡量不要列遍歷二維數組。
MemCache

MemCache在大型網站架構中經常看到。DB一般公司都會用mysql,即便是做了分庫分表,數據資料庫單機的壓力還是非常大的,這時候因為局部性的存在,可能很多數據會被頻繁訪問,這些數據就可以被cache到像redis這種memcache中,當redis查不到數據,再去查db,並寫入redis。
因為redis的水平擴展能力和簡單查詢能力要比mysql強多了,查起來也快。所以這種架構設計有幾個好處:
- 加快了數據查詢的平均速度。
-
大幅度減少DB的壓力。
CDN
CDN的全稱是Content Delivery Network,即內容分發網路(圖片來自百度百科) 。CDN常用於大的素材下發,比如圖片和影片,你在淘寶上打開一個圖片,這個圖片其實會就近從CDN機房拉去數據,而不是到阿里的機房拉數據,可以減少阿里機房的出口頻寬佔用,也可以減少用戶載入素材的等待時間。
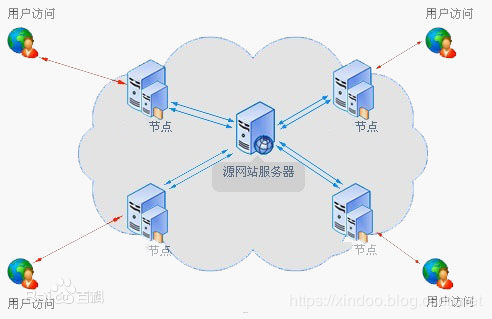
CDN在互聯網中被大規模使用,像影片、直播網站,電商網站,甚至是12306都在使用,這種設計對公司可以節省頻寬成本,對用戶可以減少素材載入時間,提升用戶體驗。看到這,有沒有發現,CDN的邏輯和Memcache的使用很類似,你可以直接當他是一個互聯網版的cache優化。Java JIT
JIT全稱是Just-in-time Compiler,中文名為即時編譯器,是一種Java運行時的優化。Java的運行方式和C++不太一樣,因為為了實現write once, run anywhere的跨平台需求,Java實現了一套位元組碼機制,所有的平台都可以執行同樣的位元組碼,執行時有該平台的JVM將位元組碼實時翻譯成該平台的機器碼再執行。問題在於位元組碼每次執行都要翻譯一次,會很耗時。
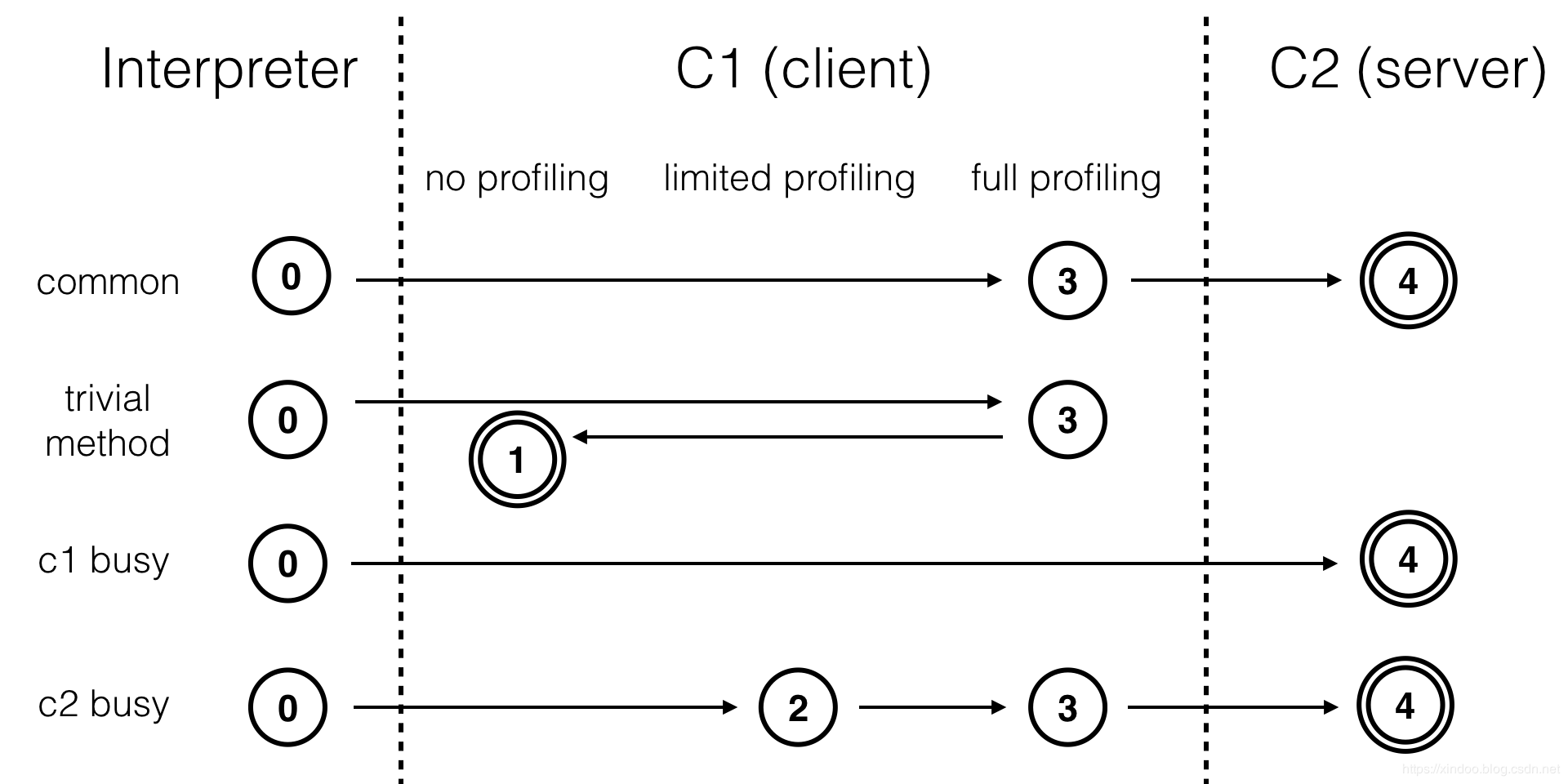
圖片來自鄭雨迪Introduction to Graal ,Java 7引入了tiered compilation的概念,綜合了C1的高啟動性能及C2的高峰值性能。這兩個JIT compiler以及interpreter將HotSpot的執行方式劃分為五個級別:
- level 0:interpreter解釋執行
- level 1:C1編譯,無profiling
- level 2:C1編譯,僅方法及循環back-edge執行次數的profiling
- level 3:C1編譯,除level 2中的profiling外還包括branch(針對分支跳轉位元組碼)及receiver type(針對成員方法調用或類檢測,如checkcast,instnaceof,aastore位元組碼)的profiling
- level 4:C2編譯
通常情況下,一個方法先被解釋執行(level 0),然後被C1編譯(level 3),再然後被得到profile數據的C2編譯(level 4)。如果編譯對象非常簡單,虛擬機認為通過C1編譯或通過C2編譯並無區別,便會直接由C1編譯且不插入profiling程式碼(level 1)。在C1忙碌的情況下,interpreter會觸發profiling,而後方法會直接被C2編譯;在C2忙碌的情況下,方法則會先由C1編譯並保持較少的profiling(level 2),以獲取較高的執行效率(與3級相比高30%)。
這裡將少部分位元組碼實時編譯成機器碼的方式,可以提升java的運行效率。可能有人會問,為什麼不預先將所有的位元組碼編譯成機器碼,執行的時候不是更快更省事嗎?首先機器碼是和平台強相關的,linux和unix就可能有很大的不同,何況是windows,預編譯會讓java失去誇平台這種優勢。 其次,即時編譯可以讓jvm拿到更多的運行時數據,根據這些數據可以對位元組碼做更深層次的優化,這些是C++這種預編譯語言做不到的,所以有時候你寫出的java程式碼執行效率會比C++的高。
CopyOnWrite
CopyOnWrite寫時複製,最早應該是源自linux系統,linux中在調用fork() 生成子進程時,子進程應該擁有和父進程一樣的指令和數據,可能子進程會修改一些數據,為了避免污染父進程的數據,所以要給子進程單獨拷貝一份。出於效率考慮,fork時並不會直接複製,而是等到子進程的各段數據需要寫入才會複製一份給子進程,故此得名 寫時複製 。
在電腦的世界裡,讀寫的分布也是有很大的局部性的,大多數情況下寫遠大於讀, 寫時複製 的方式,可以減少大量不必要的複製,提升性能。 另外這種方式也不僅僅是用在linux內核中,java的concurrent包中也提供了CopyOnWriteArrayList CopyOnWriteArraySet。像Spark中的RDD也是用CopyOnWrite來減少不必要的RDD生成。
處理
上面列舉了那麼多局部性的應用,其實還有很多很多,我只是列舉出了幾個我所熟知的應用,雖然上面這些例子,我們都利用局部性得到了能效、成本上的提升。但有些時候它也會給我們帶來一些不好的體驗,更多的時候它其實就是一把雙刃劍,我們如何識別局部性,利用它好的一面,避免它壞的一面?
識別
文章開頭也說過,局部性其實就是一種概率的不均等性,所以只要概率不均等就一定存在局部性,因為很多時候這種概率不均太明顯了,非常好識別出來,然後我們對大頭做相應的優化就行了。但可能有些時候這種概率不均需要做很詳細的計算才能發現,最後還得核對成本才能考慮是否值得去做,這種需要具體問題具體分析了。
如何識別局部性,很簡單,看概率分布曲線,只要不是一條水平的直線,就一定存在局部性。
利用
發現局部性之後對我們而言是如何利用好這些局部性,用得好提升性能、節約資源,用不好局部性就會變成阻礙。而且不光是在電腦領域,局部性在非電腦領域也可以利用。
##### 性能優化
上面列舉到的很多應用其實就是通過局部性做一些優化,雖然這些都是別人已經做好的,但是我們也可以參考其設計思路。
恰巧最近我也在做我們一個java服務的性能優化,利用jstack、jmap這些java自帶的分析工具,找出其中最吃cpu的執行緒,找出最占記憶體的對象。我發現有個redis數據查詢有問題,因為每次需要將一個大字元串解析很多個鍵值對,中間會產生上千個臨時字元串,還需要將字元串parse成long和double。redis數據太多,不可能完全放的記憶體里,但是這裡的key有明顯的局部性,大量的查詢只會集中在頭部的一些key上,我用一個LRU Cache快取頭部數據的解析結果,就可以減少大量的查redis+解析字元串的過程了。
另外也發現有個程式碼邏輯,每次請求會被重複執行幾千次,耗費大量cpu,這種熱點程式碼,簡單幾行改動減少了不必要的調用,最終減少了近50%的CPU使用。
##### 非電腦領域
《高能人士的七個習慣》里提到了一種工作方式,將任務劃分為重要緊急、不重要但緊急、重要但不緊急、不重要不緊急四種,這種劃分方式其實就是按單位時間的重要度排序的,按單位時間的重要度越高收益越大。《The Effective Engineer》里直接用leverage(槓桿率)來衡量每個任務的重要性。這兩種方法差不多是類似的,都是優先做高收益率的事情,可以明顯提升你的工作效率。
這就是工作中收益率的局部性導致的,只要少數事情有比較大的收益,才值得去做。還有一個很著名的法則__82法則__,在很多行業、很多領域都可以套用,80%的xxx來源於20%的xxx ,80%的工作收益來源於20%的工作任務,局部性給我們的啟示「永遠關注最重要的20%」 。
避免
上面我們一直在講如何通過局部性來提升性能,但有時候我們需要避免局部性的產生。 比如在大數據運算時,時常會遇到數據傾斜、數據熱點的問題,這就是數據分布的局部性導致的,數據傾斜往往會導致我們的數據計算任務耗時非常長,數據熱點會導致某些單節點成為整個集群的性能瓶頸,但大部分節點卻很閑,這些都是我們需要極力避免的。
一般我們解決熱點和數據切斜的方式都是提供過重新hash打亂整個數據讓數據達到均勻分布,當然有些業務邏輯可能不會讓你隨意打亂數據,這時候就得具體問題具體分析了。感覺在大數據領域,局部性極力避免,當然如果沒法避免你就得通過其他方式來解決了,比如HDFS中小文件單節點讀的熱點,可以通過減少加副本緩解。其本質上沒有避免局部性,只增加資源緩解熱點了,據說微博為應對明星出軌Redis集群也是採取這種加資源的方式。
參考資料
- 維基百科局部性原理
- 《電腦組成與設計》 David A.Patterson / John L.Hennessy
- 《深入淺出電腦組成原理》 極客時間 徐文浩
- 《深入理解電腦系統》 Randal E.Bryant / David O’Hallaron 龔奕利 / 雷迎春(譯)
- Interactive latencies
- Introduction to Graal 鄭雨迪
