記一次詳細的的SQL查詢經歷,group by慢查詢優化
- 2019 年 10 月 7 日
- 筆記
一、問題背景
現網出現慢查詢,在500萬數量級的情況下,單表查詢速度在30多秒,需要對sql進行優化,sql如下:
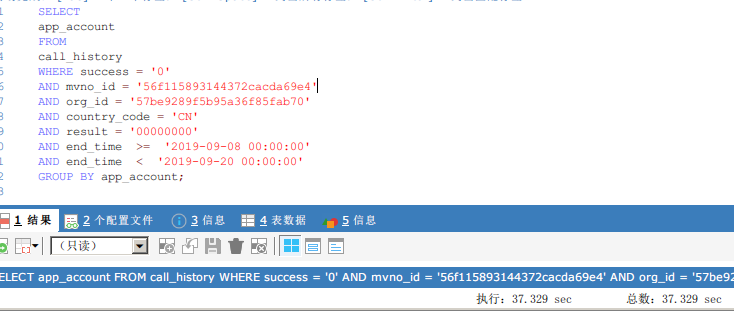
這裡測試環境構造了500萬條數據,模擬了這個慢查詢。
簡單來說,就是查詢一定條件下,都有哪些用戶的。很簡單的sql,可以看到,查詢耗時為37秒。
說一下app_account欄位的分布情況,隨機生成了5000個不同的隨機數,然後分布到了這500萬條數據里,平均來說,每個app_account都會有1000個是重複的值,種類共有5000個。
二、看執行計劃

可以看到,group by欄位上是加了索引的,也用到了。
三、優化
優化思路:
思路一:
後面應該加上 order by null;避免無用排序,但其實對結果耗時影響不大,還是很慢。

思路二:
where條件太複雜,沒索引,導致查詢慢,但給where條件的所有欄位加上了組合索引,沒起作用。


思路三:
既然group by慢,換distinct試試

瞬間就加快了。
雖然知道group by和distinct有很小的性能差距,但是沒想到,差距居然這麼大。
四、你以為這就結束了嗎
這個bug轉給測試後,測試一測,居然還是30多秒。再測試電腦上執行sql,依舊是30多秒。
又回本人的電腦上,連接同一個資料庫,一執行sql,0.8秒。
同一個庫,同一個sql,怎麼在兩台電腦執行的差距這麼大。
後來直接在伺服器上執行:

還是30多秒。那看來就是本人的電腦問題。
後來又實驗多個同事的電腦,最後得出的結論是:是因為之前用的SQLyog。
最後發現,只有用sqlyog執行這個「優化後」的sql會是0.8秒,在navcat和伺服器上直接執行,都是30多秒。
那就是sqlyog的問題了,現在也不清楚sqlyog是不是做什麼優化了,這個慢查詢的問題還在解決中(問題可能是出在mysql自身的參數上)。
這裡只是記錄下這個問題,sqlyog執行sql速度,和伺服器執行sql速度,在有的sql中差異巨大,並不可靠。
五、後續(還未解決)
感謝大家在評論里出謀劃策,本人來回復下問題進展:
1.所謂的sqlyog查詢快,命令行查詢慢的現象,已經找到原因了。是因為sqlyog會在查詢語句後默認加上limit 1000,所以導致很快。這個問題不再糾結。
2.已經試驗過的方法(都沒有用):
①給app_account欄位加索引。
②給sql語句後面加order by null。
③調整where條件里欄位的查詢順序,有索引的放前面。
④給所有where條件的欄位加組合索引。
⑤用子查詢的方式,先查where條件里的內容,再去重。
測試環境和現網環境數據還是有點不一樣的,這裡貼一張現網執行sql的圖(1分鐘):

六、最終解決方案
經過網友的提醒,發現explain執行計劃里,索引好像並沒有用到創建的idx_end_time。
然後果斷在現網試了下,強制指定使用idx_end_time索引,結果只要0.19秒。

至此問題解決,其實同事昨天也在懷疑,是不是這個表索引建的太多了,導致用的不對,原本用的是idx_org_id和idx_mvno_id。
現在強制指定idx_end_time就ok了!
最後再對比下改前後的執行計劃:
改之前(查詢要1分鐘左右):

改之後(查詢只要幾百毫秒):

出處:https://www.cnblogs.com/dijia478/p/11550902.html(複製到瀏覽器中打開)
