一、HDFS 原理分析
- 2020 年 5 月 18 日
- 筆記
- 大數據之hadoop
HDFS 全稱 Hadoop Distribute File System,是 Hadoop 的一個分散式文件系統
一、HDFS 的系統結構
1.1 數據塊 —— block
- 文件在 HDFS 上分塊存儲。
- 一個文件分多少塊,是按照你設置的存儲單位大小算的。
- 設置存儲單位時,不能太大,也不能太小。
- 太大:處理數據時,需要教高的配置。
- 太小:數據塊的映射資訊是存在 NameNode 的記憶體中(一個快佔用 150 位元組),記憶體也是受限的,如果塊太小,會佔用較多 namenode 的存儲空間。
80M 文件,1M一個塊,就會分成80塊數據。佔用 NameNode 記憶體 80 * 150 位元組
80M 文件,64M一個塊,分2塊一塊:64M,一塊:16M(如果小於塊大小,就按照實際存儲)。佔用 NameNode 記憶體 2 * 150 位元組
總結如下:
- 數據塊是 HDFS 中基本的數據存儲單位,一般大小為64M/128M/256M,一個大文件根據數據塊的大小,將文件分為若干個塊。
- NameNode 存儲的文件對應的 block 映射資訊;而 datanode 存儲塊資訊對應的數據。
- 塊越小讀取的速度就越快,但是整體佔用 NameNode 的空間就越大,因為不管塊大小一個塊所佔用的 NameNode 記憶體存儲空間為一般為150位元組。
- 一個大文件會被拆分成一個個的塊,然後存儲於不同的機器。對於大規模的集群會存儲在不同的機架上,如果一個文件少於 Block 大小,那麼實際佔用的空間為其文件的大小。
- 數據塊也是基本的讀寫單位,類似於磁碟的扇區,每次都是讀寫一個塊。讀寫多個塊就合成了一個文件。
- 為了容錯,文件的所有數據塊都會有副本,也就是說複製的是數據塊而不是單獨的一個文件被複制了,默認複製3份,可以在 hdft-site.xml 里進行配置。
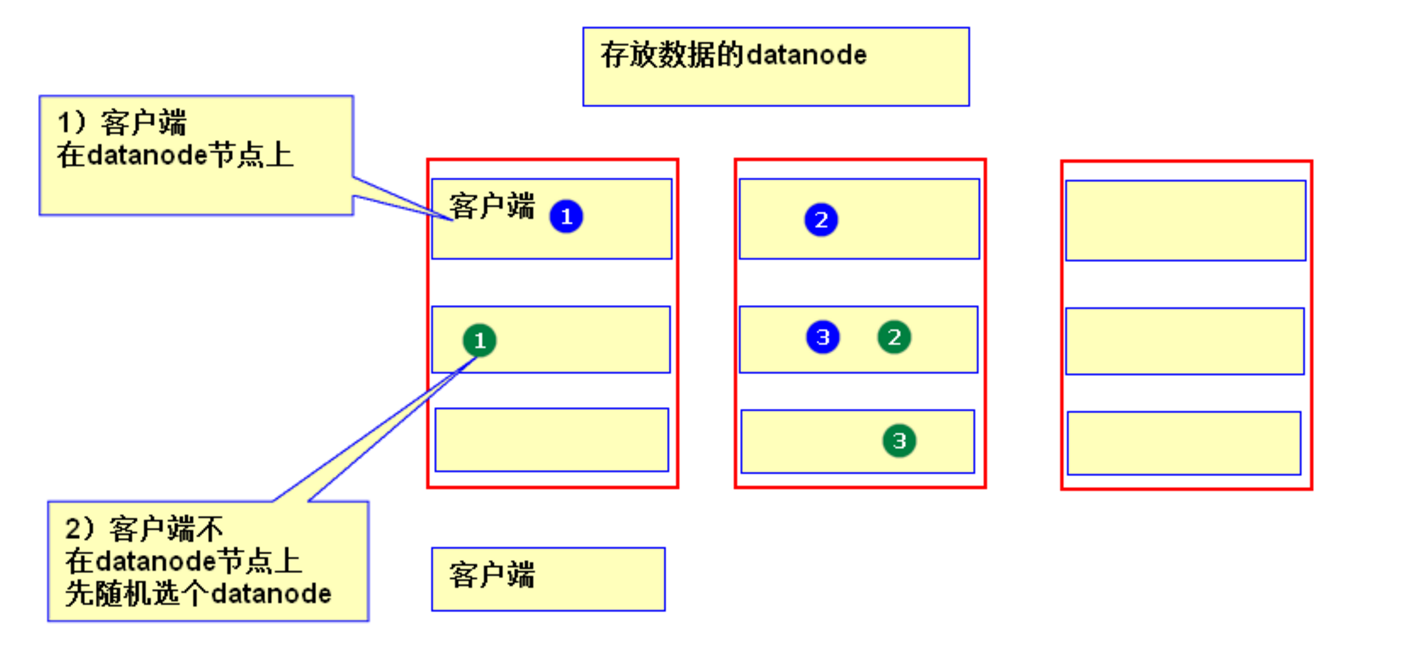
- 副本的數據的存儲規則:
- 若client為DataNode節點,那存儲block時,規則為:副本1,同client的節點上;副本2,不同機架節點上;副本3,同第二個副本機架的另一個節點上;其他副本隨機挑選。
- 若client不為DataNode節點,那存儲block時,規則為:副本1,隨機選擇一個節點上;副本2,不同機架節點上;副本3,同第二個副本機架的另一個節點上;其他副本隨機挑選。

1.2 各組件介紹
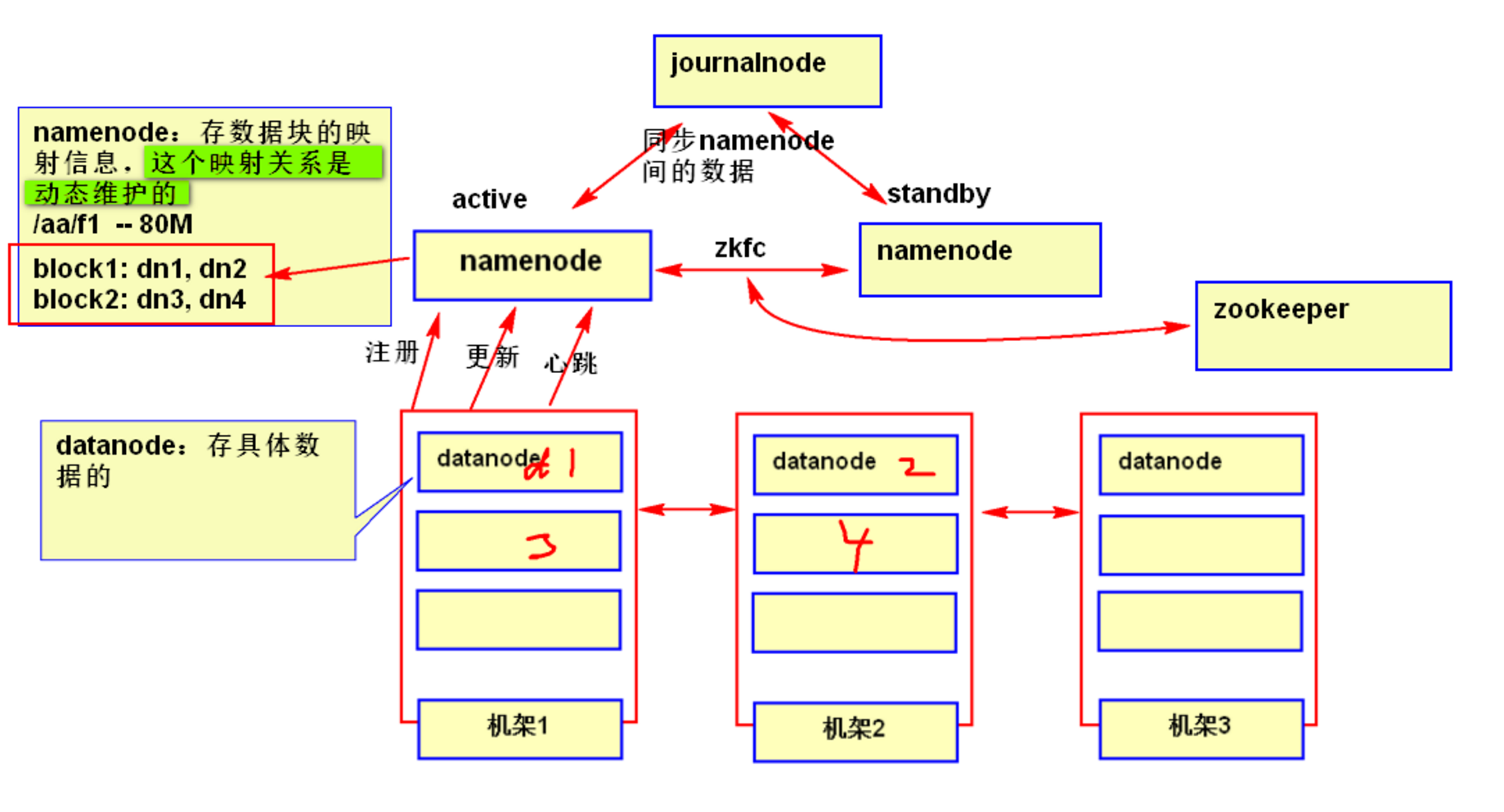
NameNode:
- 是整個集群的中心,負責安排管理集群中數據的存儲並記錄存儲文件的元數據和負責客戶端對文件的訪問。
- HA 模式下,一般有一個 active 狀態的 NameNode,若干個 standby 狀態的 NameNode,其中,active 狀態的 NameNode 負責所有的客戶端操作,standby 狀態的 NameNode 處於從屬地位,維護著數據狀態,隨時準備切換。
- 存儲文件的元數據(metadata),主要包括整個文件系統的目錄樹、文件名與 blockid 的映射關係、blockid 在哪個 datanode 上等。
- 在運行時把所有的元數據都保存到 NameNode 機器的記憶體中,所以整個 HDFS 可存儲的文件數受限於 NameNode 的記憶體大小。
- 一個 block 在 NameNode 中對應一條記錄。
- NameNode 的元數據的鏡像文件會保存到本地磁碟,但不保存 block 具體的位置資訊,而是由 DataNode 註冊和運行時進行上報維護。
- NameNode 完蛋了,那整個 HDFS 也就完蛋了,所以要採用冗餘的方案來保證 NameNode 的高可用性。
DataNode:
- 保存 block 塊對應的具體數據。
- 負責數據的讀寫和複製操作。
- DataNode 啟動時會向 NameNode 報告當前存儲的數據塊資訊,也會持續的報告數據塊的修改資訊。
- DataNode 之間會進行互相通訊,來完成複製數據塊的動作,以保證數據的冗餘性。
- DataNode 啟動時要在 NameNode 上註冊,當 DataNode 改變時,也要通知 NameNode 。DataNode 會定期向 NameNode 發送心跳,告知 NameNode 該節點的 DataNode 是可用的。
JournalNode:
- 負責兩個狀態的 NameNode 進行數據同步,保持數據一致
ZKFC:
- 作用是 HA 自動切換。會將 NameNode 的 active 狀態資訊保存到 zookeeper。
二、數據的讀取和寫入過程
2.1 HDFS 的數據寫入過程
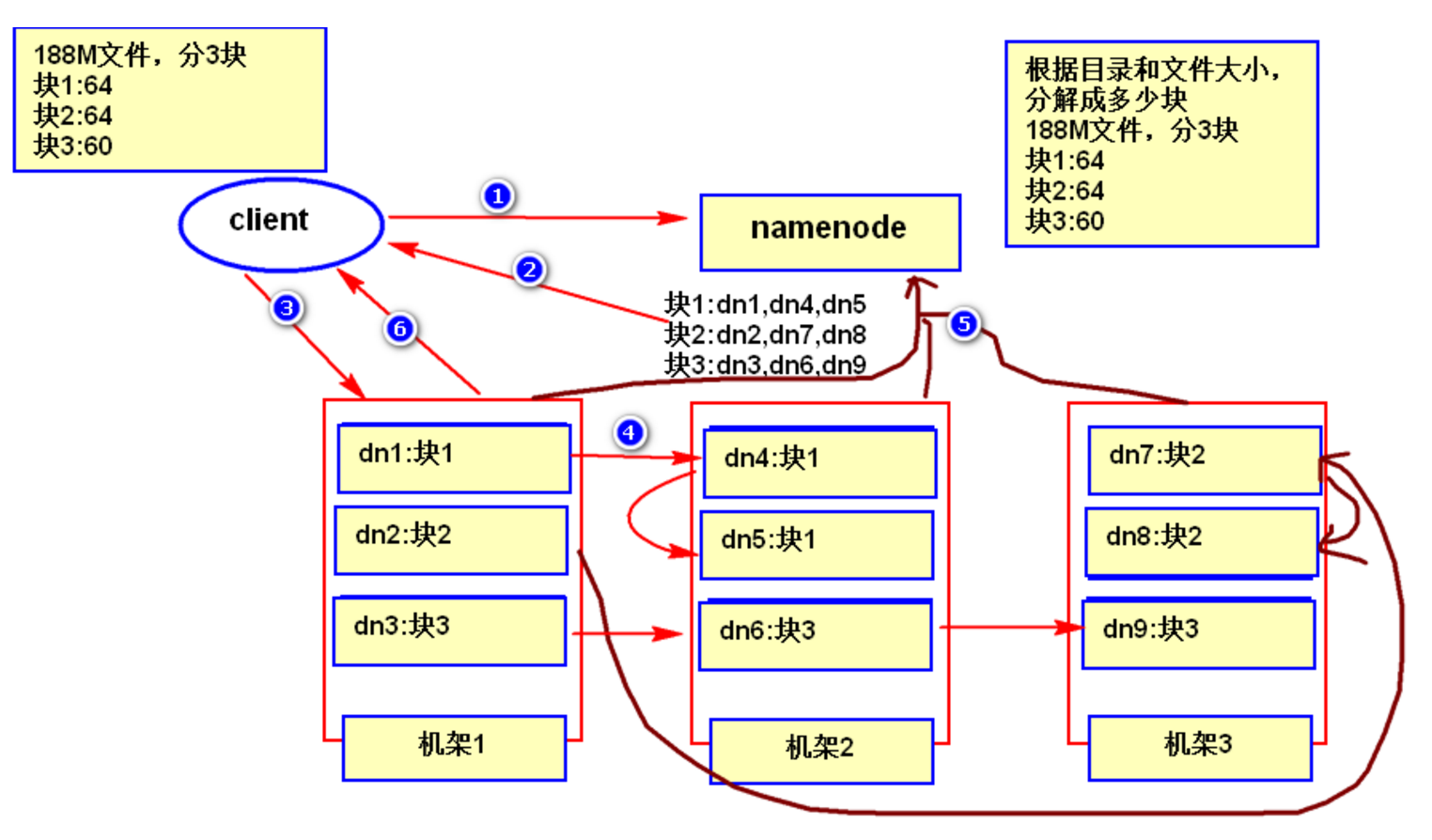
- 客戶端發起數據寫入請求,告訴 NameNode 要寫入的文件資訊;
- NameNode 根據你的情況(client端所在位置、文件大小)分配給你分配寫入數據的位置也就是寫到那幾個機器上;
- 客戶端根據 NameNode 回饋的資訊向 DataNode 寫入數據;
- DataNode 之前感覺副本數複製數據;
- 複製完成之後,各數據節點向 NameNode 上報 block 資訊;
- DataNode 通知客戶端已完成;
2.2 HDFS 的數據讀取過程
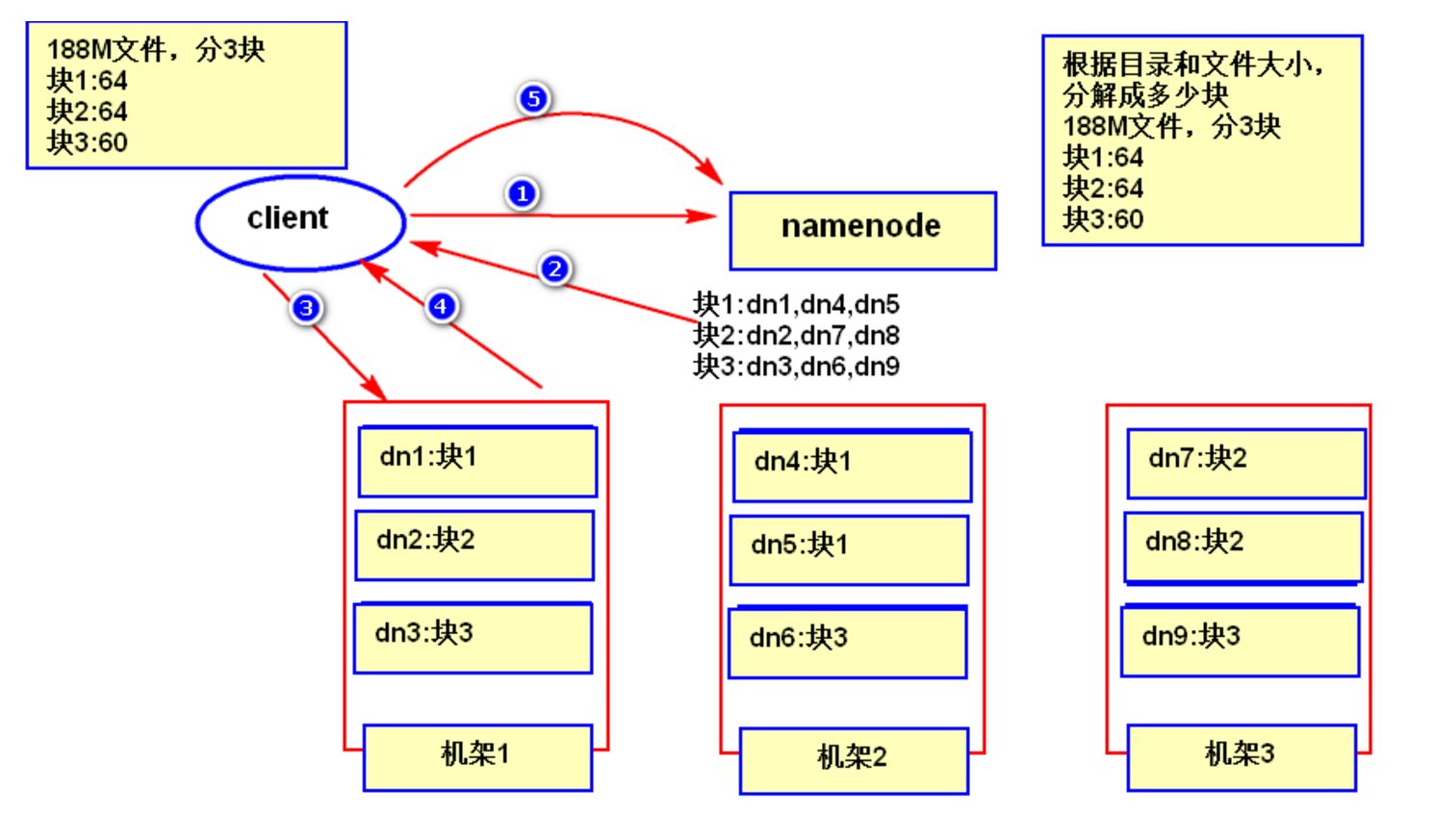
- 客戶端發起讀數據的請求;
- 告訴 NameNode 要讀那個文件;
- NameNode 返回 block 資訊列表(包括要讀取的數據在那個機器上);
- 到指定的機器上讀取具體的數據;
- DataNode 根據 block 資訊找到數據的存儲位置並返回數據給客戶端;
- 客戶端讀完數據之後告訴 NameNode 已經讀取完成;
三、HDFS 常用配置文件
3.1 hdfs-site.xml
| name | value | description |
|---|---|---|
| dfs.datanode.data.dir | /data1/dfs,/data2/dfs,/data3/dfs,/data4/dfs,/data5/dfs,/data6/dfs | datanode本地文件存放地址 |
| dfs.replication | 3 | 副本數 |
| dfs.namenode.name.dir | /data1/dfsname,/data2/dfsname,/data3/dfsname | namenode本地文件存放地址 |
| dfs.support.append | TRUE | 是否支援追加,但不支援並發執行緒往裡追加 |
| dfs.permissions.enabled | FALSE | 是否開啟目錄許可權 |
| dfs.nameservices | ns1 | 提供服務的NS邏輯名稱,與core-site.xml里的對應,可以配置多個命名空間的名稱,使用逗號分開即可。 |
| dfs.ha.namenodes.[nameservice ID] | nn1,nn2 | 命名空間中所有NameNode的唯一標示名稱。可以配置多個,使用逗號分隔。該名稱是可以讓DataNode知道每個集群的所有NameNode。 |
| dfs.namenode.rpc-address.ns1.nn1 | nn1.hadoop:9000 | 指定NameNode的RPC位置 |
| dfs.namenode.http-address.ns1.nn1 | nn1.hadoop:50070 | 指定NameNode的Web Server位置 |
| dfs.namenode.rpc-address.ns1.nn2 | nn2.hadoop:9000 | 指定NameNode的RPC位置 |
| dfs.namenode.http-address.ns1.nn2 | nn2.hadoop:50070 | 指定NameNode的Web Server位置 |
| dfs.namenode.shared.edits.dir | qjournal://nn1.hadoop:8485;nn2.hadoop:8485/ns1 | 指定用於HA存放edits的共享存儲,通常是namenode的所在機器 |
| dfs.journalnode.edits.dir | /data/journaldata/ | journaldata服務存放文件的地址 |
| fs.trash.interval | 2880 | 垃圾回收周期,單位分鐘 |
| dfs.blocksize | 134217728 | 塊的大小 |
| dfs.datanode.du.reserved | 2147483648 | 每個存儲卷保留用作其他用途的磁碟大小 |
| dfs.datanode.fsdataset.volume.choosing.policy | org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy | datanode數據副本存放的磁碟選擇策略,、有2種方式一種是輪詢方式 (org.apache.hadoop.hdfs.server.datanode.fsdataset.RoundRobinVolumeChoosingPolicy,為默認方式),另一種為選擇可用空間足夠多的磁碟存儲方式 (org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy)。 |
| dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold | 2147483648 | 當選擇可用空間足夠多的磁碟存儲方式才生效,hdfs計算最大可用空間-最小可用空間的差值,如果差值小於此配置,則選擇輪詢方式存儲 |
3.2 core-site.xml
| name | value | description |
|---|---|---|
| io.native.lib.available | true | 開啟本地庫支援 |
| fs.defaultFS | hdfs://ns1 | 客戶端連接HDFS時,默認的路徑前綴。默認文件服務的協議和NS(nameservices)邏輯名稱,和hdfs-site里的對應此配置替代了1.0里的fs.default.name |
| io.compression.codecs | org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec | 相應編碼的操作類,用逗號分隔 |
| ha.zookeeper.quorum | nn1.hadoop:2181,nn2.hadoop:2181,s1:2181 | HA使用的zookeeper地址 |
3.3 slaves
- slaves文件裡面記錄的是集群里所有DataNode的主機名
3.4 hadoop-env.sh
- HADOOP_CLASSPATH:hadoop的classpath
- JAVA_LIBRARY_PATH:java載入本地庫的地址
- HADOOP_HEAPSIZE:java虛擬機使用的最大記憶體
- HADOOP_OPTS:hadoop啟動公用參數
- HADOOP_NAMENODE_OPTS:namenode專用參數
- HADOOP_DATANODE_OPTS:datanode專用參數
- HADOOP_CLIENT_OPTS:hadoop client專用參數


