XLNet看這篇文章就足以!
- 2020 年 5 月 18 日
- 筆記
文章鏈接://arxiv.org/pdf/1906.08237.pdf
程式碼鏈接:英文–//github.com/zihangdai/xlnet 中文–//github.com/ymcui/Chinese-XLNet
一、什麼是XLNet?
XLNet是一個類似於BERT的模型,不算是一個全新的模型。它是CMU和Google Brain團隊在2019年6月發布的模型,其在20個任務上超過BERT,並且在18個任務上取得了SOTA的效果,包括機器問答、自然語言推斷、情感分析和文檔排序。作者表示,BERT 這樣基於去噪自編碼器的預訓練模型可以很好地建模雙向語境資訊,性能優於基於自回歸語言模型的預訓練方法。然而,由於需要 mask 一部分輸入,BERT 忽略了被 mask 位置之間的依賴關係,因此出現預訓練和微調效果的差異(pretrain-finetune discrepancy)。這篇新論文中,作者從自回歸(autoregressive)和自編碼(autoencoding)兩大範式分析了當前的預訓練語言模型,並發現它們雖然各自都有優勢,但也都有難以解決的困難。為此,研究者提出XLNet,並希望結合大陣營的優秀屬性。
二、自回歸(autoregressive)和自編碼(autoencoding)
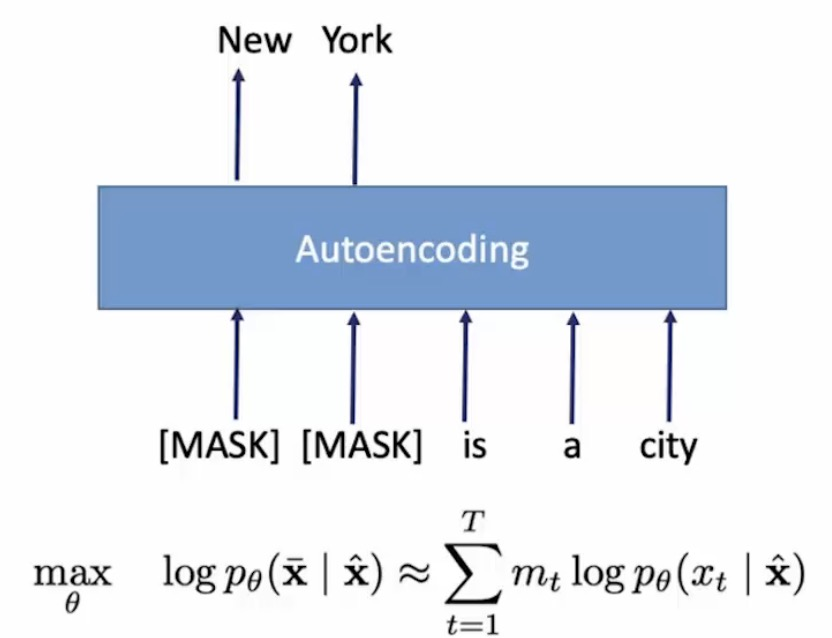
自回歸的模型(AutoRegressive LM),是一種使用上下文詞來預測下一個詞的模型。但是在這裡,上下文單詞被限制在兩個方向,前向或後向。如下圖,如果從左到右的話,輸入New來預測York,然後用New York來預測 is,預測 is 的時候只能根據其前面的詞來進行預測,而不能根據 a , city 這兩個詞來進行預測。
AutoRegressive LM的代表有:
- 傳統的語言模型,根據上文預測下一個詞。
- ELMo擴展了語言模型,增加了雙向詞的預測,上文預測下一個詞和下文預測上一個詞,但是本質上還是AutoRegressive LM的原理。
- GPT是把AutoRegressive LM發揮到極致的做法,在AutoRegressive LM的基礎上,提升預料的品質,加大訓練的資源,最終訓練出相當不錯的效果。
AutoRegressive LM的優點和缺點:
缺點:是只能利用上文或者下文的資訊,不能同時利用上文和下文的資訊。當然,看似ELMO這種用BiLSTM雙向都可以做(這其實算是偽雙向模型),然後拼接看上去能夠解決這個問題,因為融合模式過於簡單,所以效果其實並不會太好。
優點:是符合下游NLP任務語言環境,比如生成類NLP任務,比如文本摘要,機器翻譯等,在實際生成內容的時候,就是從左向右的,自回歸語言模型天然匹配這個過程,考慮被預測詞之間的依賴關係。相比Bert這種DAE模式,在生成類NLP任務中,就面臨訓練過程和應用過程不一致的問題(訓練的時候有Mask,應用的時候沒有),導致生成類的NLP任務到目前為止都做不太好

自編碼語言模型(AutoEncoder LM),它能比較自然地融入雙向語言模型,同時看到被預測單詞的上文和下文。自回歸語言模型只能根據上文預測下一個單詞,或者反過來,只能根據下文預測前面一個單詞。相比而言,Bert通過在輸入X中隨機Mask掉一部分單詞,然後預訓練過程的主要任務之一是根據上下文單詞來預測這些被Mask掉的單詞,如果你對Denoising Autoencoder比較熟悉的話,會看出,這確實是典型的DAE的思路。那些被Mask掉的單詞就是在輸入側加入的所謂噪音。類似Bert這種預訓練模式,被稱為DAE LM。Bert通過在輸入X中隨機Mask掉一部分單詞,然後預訓練過程的主要任務之一是根據上下文單詞來預測這些被Mask掉的單詞,如果你對Denoising Autoencoder比較熟悉的話,會看出,這確實是典型的DAE的思路。那些被Mask掉的單詞就是在輸入側加入的所謂噪音。類似Bert這種預訓練模式,被稱為DAE LM。
AutoEncoder LM的優點和缺點:
優點:是能比較自然地融入雙向語言模型,同時看到被預測單詞的上文和下文。
缺點:是在訓練的輸入端引入[Mask]標記,導致預訓練階段和Fine-tuning階段不一致的問題;沒有考慮被預測單詞之間的相關性。
三、The XLNet model
XLNet的作者通過把之前的優秀的模型分為AR和AE兩類,並且清楚了各自的優勢和缺點。在XLNet中,想要結合兩邊的優勢,來提升XLNet的整體的模型的效果。那我們通過上文知道了,AR的優勢是預訓練和Fine-tuning的數據形式一致,而AE的優勢是在預測詞的時候,能夠很好的融入上下文。
1、排列語言建模(Permutation Language Modeling)
其實作者主要想解決的一個問題就是:我們如何使autoregressive可以雙向,也就是同時考慮上下文。下面這張圖就是答案,簡單來講就是考慮輸入的句子的不同排序,例如:「New York is a city」這句話有五個單詞,那麼它的排列組合就有5!種。你可能會想如果句子很長呢?比如30個片語成的句子,那我們難道要考慮30!種輸入嗎,這樣計算複雜度就會太大了,在實際訓練中使用取樣的方法選取其中一部分序列。(註:輸入是不會變的,比如上面那句話的輸入只會是「New York is a city」,那是如何在訓練過程中考慮不同的序列呢?作者的方法就是使用所謂的Attention Mask)


給定長度為T的序列xx,總共有T!種排列方法,也就對應T!種鏈式分解方法。比如假設x=x1x2x3,那麼總共用3!=6種分解方法:
注意p(x2|x1x3)指的是第一個詞是x1並且第三個詞是x3的條件下第二個詞是x2的概率,也就是說原來詞的順序是保持的。如果理解為第一個詞是x1並且第二個詞是x3的條件下第三個詞是x2,那麼就不對了。
如果我們的語言模型遍歷T!種分解方法,並且這個模型的參數是共享的,那麼這個模型應該就能(必須)學習到各種上下文。普通的從左到右或者從右往左的語言模型只能學習一種方向的依賴關係,比如先」猜」一個詞,然後根據第一個詞」猜」第二個詞,根據前兩個詞」猜」第三個詞,……。而排列語言模型會學習各種順序的猜測方法,比如上面的最後一個式子對應的順序3→1→2,它是先」猜」第三個詞,然後根據第三個詞猜測第一個詞,最後根據第一個和第三個詞猜測第二個詞。
因此我們可以遍歷T!種路徑,然後學習語言模型的參數,但是這個計算量非常大(10!=3628800,10個詞的句子就有這麼多種組合)。因此實際我們只能隨機的取樣T!里的部分排列。
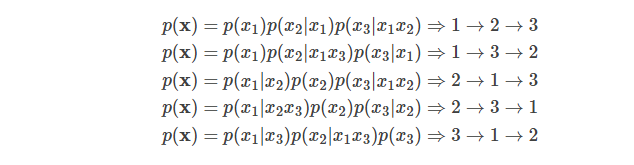
2、雙流自注意力機制(Tow-stream Attention)和Attention Mask
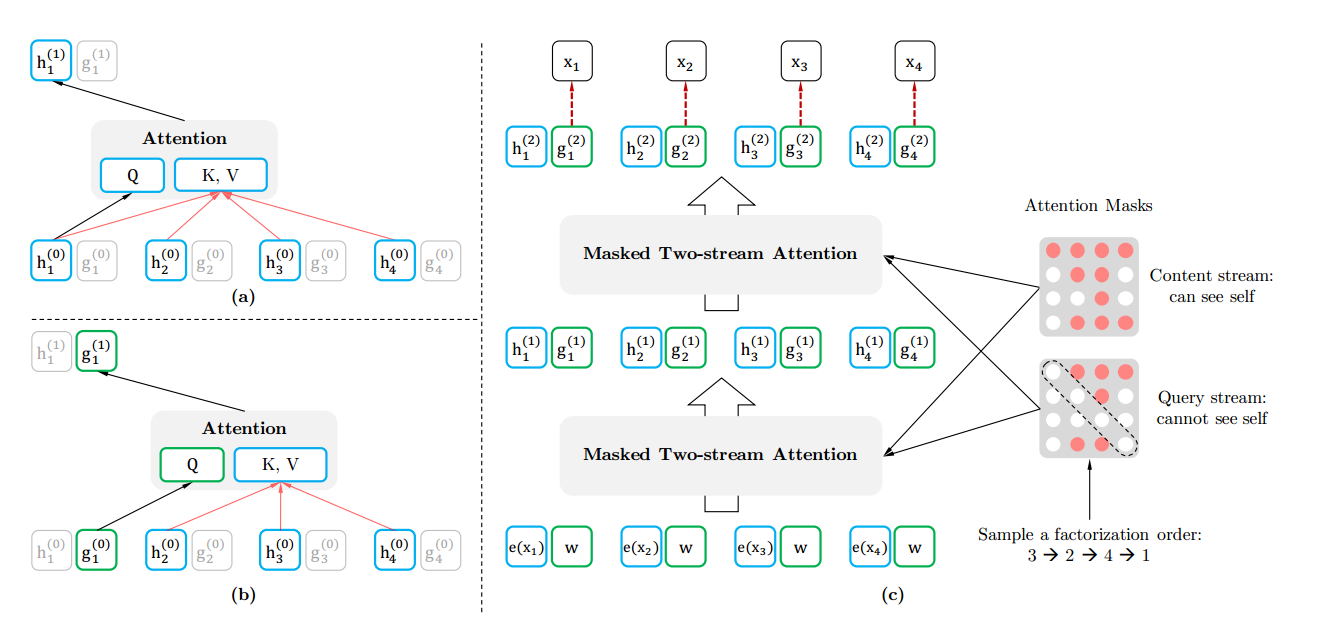
XLNet把Bert的[Mask]的過程搬到Attention Mask來完成。這樣從輸入端看去預訓練和Fine-tuning是一致的。Attention Mask的原理是,假設輸入的詞是x1−>x2−>x3−>x4x1−>x2−>x3−>x4,我們在Attention Mask中改成隨機排列組合的另外一個順序x3−>x2−>x4−>x1x3−>x2−>x4−>x1了,然後預測x3x3的時候上文為空,預測x2x2的時候上文是x3x3,預測x4x4的時候上文是x3,x2x3,x2,預測x1x1的時候上文是x3,x2,x4x3,x2,x4,這樣就達到了預測一個詞使用到了上下文的內容。
在Attention Mask中實現的原理路下圖:其實真是的詞的順序沒有變,只是通過mask的操作達到了類似隨機排序的效果。
Tow-stream Attention 是什麼意思呢?首先我們可以想為什麼要用Tow-stream Attention?那當然是為了解決什麼問題,比如句子序列是「New York is a city」, 我們現在預測「York」,那我們需要單詞」New「的內容資訊和位置資訊,和」York「本身的位置資訊;預測「is」,那我們需要單詞」New「和”York”的內容資訊和位置資訊,和」is「本身的位置資訊。也就是對於每個詞我們有時候只要位置資訊,有時候位置資訊和內容資訊都要。作者為了解決這個問題就提出了Tow-stream Attention,為每個單詞都定義兩個輸出 h(包含內容和位置資訊)和 g(只包含位置資訊),然後用兩個不同的Attention Mask,如下圖所示,一個考慮詞本身一個不考慮詞本身。
四、XLNet與BERT對比
XLNet和BERT都是預測一個句子的部分詞,但是背後的原因是不同的。BERT使用的是Mask語言模型,因此只能預測部分詞(總不能把所有詞都Mask了然後預測?)。而XLNet預測部分詞是出於性能考慮,而BERT是隨機的選擇一些詞來預測。
除此之外,它們最大的區別其實就是BERT是約等號,也就是條件獨立的假設——那些被MASK的詞在給定非MASK的詞的條件下是獨立的。但是我們前面分析過,這個假設並不(總是)成立。下面我們通過一個例子來說明(其實前面已經說過了,理解的讀者跳過本節即可)。
假設輸入是[New, York, is, a, city],並且假設恰巧XLNet和BERT都選擇使用[is, a, city]來預測New和York。同時我們假設XLNet的排列順序為[is, a, city, New, York]。那麼它們優化的目標函數分別為:
從上面可以發現,XLNet可以在預測York的使用利用New的資訊,因此它能學到」New York」經常出現在一起而且它們出現在一起的語義和單獨出現是完全不同的。
五、總結
XLNet 的成功來自於三點:
分散式語義假設的有效性,即我們確實可以從語料的統計規律中習得常識及語言的結構。
對語境更加精細的建模:從”單向”語境到”雙向”語境,從”短程”依賴到”長程”依賴,XLNet 是目前對語境建模最精細的模型。
在模型容量足夠大時,數據量的對數和性能提升在一定範圍內接近正比,XLNet 使用的預訓練數據量可能是公開模型裡面最大的。