xpath beautiful pyquery三種解析庫
- 2019 年 10 月 3 日
- 筆記
這兩天看了一下python常用的三種解析庫,寫篇隨筆,整理一下思路。太菜了,若有錯誤的地方,歡迎大家隨時指正。。。。。。。(come on…….)
爬取網頁數據一般會經過 獲取資訊->提取資訊->保存資訊 這三個步驟。而解析庫的使用,則可以幫助我們快速的提取出我們需要的那被部分資訊,免去了寫複雜的正則表達式的麻煩。在使用解析庫的時候,個人理解也會有三個步驟 建立文檔樹->搜索文檔樹->獲取屬性和文本 。
建立文檔樹:就是把我們獲取到的網頁源碼利用解析庫進行解析,只有這樣,後面才能使用這個解析庫的方法。
搜索文檔樹:就是在已經建立的文檔樹裡面,利用標籤的屬性,搜索出我們需要的那部分資訊,比如一個包含一部分網頁內容的div標籤,一個ul標籤等。
獲取索性和文本:在上一步的基礎上,進一步獲取到具體某個標籤的文本或屬性,比如一個a標籤的href屬性,title屬性,或它的文本。
首先,定義一個html的字元串,用它來模擬已經獲取到的網頁源碼


html = ''' <div id="container"> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> '''
View Code
xpath解析庫:XPath,全稱XML Path Language,即XML路徑語言,它是一門在XML文檔中查找資訊的語言。它最初是用來搜尋XML文檔的,但是它同樣適用於HTML文檔的搜索。
1.建立文檔樹:在獲取到網頁源碼後,只需要使用etree的HTML方法,就可以把複雜的html建立成 一棵文檔樹了
from lxml import etree xpath_tree = etree.HTML(html)
這裡首先導入lxml庫的etree模組,然後聲明了一段HTML文本,調用HTML類進行初始化,這樣就成功構造了一個XPath解析對象。可以使用type查看一下xpath_tree的類型,是這樣的 <class ‘lxml.etree._Element’>
2.搜索文檔樹:先看一下xpath幾個常用的規則
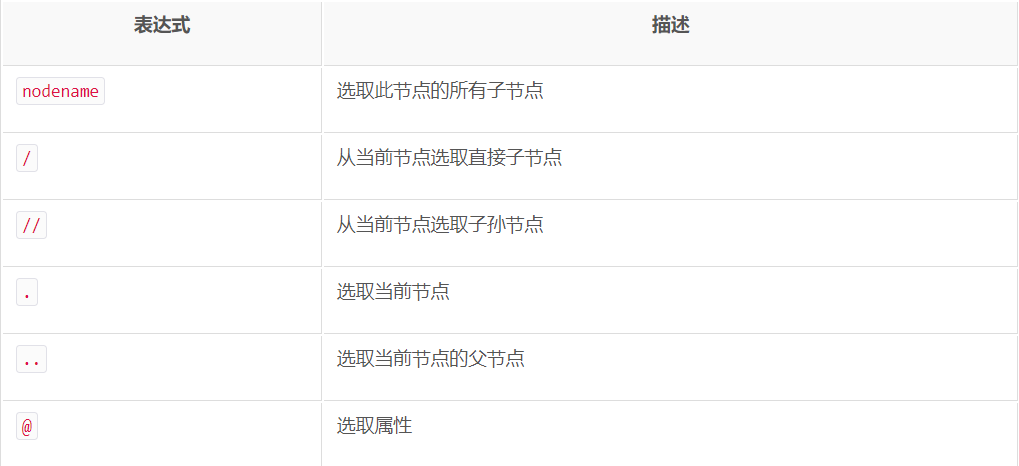
(1)從整個文檔樹中搜索標籤:一般會用//開頭的XPath規則來選取所有符合要求的節點。這裡以前面的HTML文本為例。例如搜索 ul 標籤
1 xpath_tree = etree.HTML(html) 2 result = xpath_tree.xpath('ul') 3 print(result) 4 print(type(result)) 5 print(type(result[0]))
輸出結果如下:
[<Element ul at 0x2322b7e8608>, <Element ul at 0x2322b7e8648>]
<class 'list'>
<class 'lxml.etree._Element'>
上面第二行程式碼表示從整個文檔樹中搜索出所有的ul標籤,可以看到,返回結果是一個列表,裡面的每個元素都是lxml.etree._Element類型,當然,也可以對這個列表進行一個遍歷,然後對每個lxml.etree._Element對象進行操作。
(2)搜索當前節點的子節點:比如,找到每一個ul標籤裡面的 li 標籤:
1 xpath_tree = etree.HTML(html) 2 result = xpath_tree.xpath('//ul') 3 for r in result: 4 li_list = r.xpath('./li') 5 print(li_list)
輸出結果如下:
[<Element li at 0x23433127748>, <Element li at 0x23433127788>, <Element li at 0x23433127a88>, <Element li at 0x23433127988>, <Element li at 0x23433127ac8>]
[<Element li at 0x23433127cc8>, <Element li at 0x23433127d08>, <Element li at 0x23433127d48>, <Element li at 0x23433127d88>, <Element li at 0x23433127dc8>]
第四行程式碼表示,選取當前的這個ul標籤,並獲取到它裡面的所有li標籤。
(3)根據屬性過濾:如果你需要根據標籤的屬性進行一個過濾,則可以這樣來做
1 xpath_tree = etree.HTML(html) 2 result = xpath_tree.xpath('//ul') 3 for r in result: 4 li_list = r.xpath('./li[@class="item-0"]') 5 print(li_list)
輸出結果如下:
[<Element li at 0x15c436695c8>, <Element li at 0x15c436698c8>]
[<Element li at 0x15c43669988>, <Element li at 0x15c436699c8>]
與之前的程式碼相比,旨在第四行的後面加了 [@class=”item-0″] ,它表示找到當前ul標籤下所有class屬性值為item-0的li標籤,當然,也可以在整個文檔樹搜索某個標籤時,在標籤後面加上某個屬性,進行過濾,下面例子中有用到
(4)獲取文本:獲取具體某個標籤的文本內容
1 xpath_tree = etree.HTML(html) 2 result = xpath_tree.xpath('//ul[@class="list"]') 3 for r in result: 4 li_list = r.xpath('./li[@class="item-0"]') 5 for li in li_list: 6 print(li.xpath('./text()'))
輸出結果如下:
['first item']
[]
['first item']
[]
首先,在第二行的ul標籤後面加了屬性過濾,但因為兩個ul標籤的class屬性值都是list,所以結果沒加之前是一樣的。然後又加了一個for循環,用來獲取列表裡面每一個元素的文本,因為第二個li標籤裡面沒有文本內容,所以是空
(5)獲取屬性:獲取具體某個標籤的某個屬性內容
1 xpath_tree = etree.HTML(html) 2 result = xpath_tree.xpath('//ul[@class="list"]') 3 for r in result: 4 li_list = r.xpath('./li[@class="item-0"]') 5 for li in li_list: 6 print(li.xpath('./@class'))
輸出結果如下:
['item-0']
['item-0']
['item-0']
['item-0']
把第六行的text()方法換成@符號,並在後面加上想要的屬性,就獲取到了該屬性的屬性值。
這是xpath這個解析庫基本的使用方法,也有一些沒說到的地方,大家可以看一下靜謐大佬的文章。https://cuiqingcai.com/5545.html
另外兩個解析庫,放在後面兩篇隨筆裡面
beautifulsoup解析庫:https://www.cnblogs.com/liangxiyang/p/11302525.html
pyquery解析庫:https://www.cnblogs.com/liangxiyang/p/11303142.html
*************************不積跬步,無以至千里。*************************
