Flink 入門
Apache Flink是一個框架和分散式處理引擎,用於在無界和有界數據流上進行有狀態的計算。Flink被設計為在所有常見的集群環境中運行,以記憶體中的速度和任何規模執行計算。
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
1. 什麼是Flink
1.1. 處理無界和有界數據
數據可以作為無界流或有界流被處理
- Unbounded streams(無界流)有一個起點,但沒有定義的終點。它們不會終止,而且會源源不斷的提供數據。無邊界的流必須被連續地處理,即事件達到後必須被立即處理。等待所有輸入數據到達是不可能的,因為輸入是無界的,並且在任何時間點都不會完成。處理無邊界的數據通常要求以特定順序(例如,事件發生的順序)接收事件,以便能夠推斷出結果的完整性。
- Bounded streams(有界流)有一個定義的開始和結束。在執行任何計算之前,可以通過攝取(提取)所有數據來處理有界流。處理有界流不需要有序攝取,因為有界數據集總是可以排序的。有界流的處理也稱為批處理。

Apache Flink擅長處理無界和有界數據集。對時間和狀態的精確控制使Flink的運行時能夠在無邊界的流上運行任何類型的應用程式。有界流由專門為固定大小的數據集設計的演算法和數據結構在內部處理,從而產生出色的性能。
1.2. 部署應用程式在任何地方
Flink是一個分散式系統,需要計算資源才能執行應用程式。Flink可以與所有常見的群集資源管理器(如Hadoop YARN,Apache Mesos和Kubernetes)集成,但也可以設置為作為獨立群集運行。
Flink被設計為能夠很好地工作於前面列出的每個資源管理器。這是通過特定於資源管理器的部署模式實現的,該模式允許Flink以慣用的方式與每個資源管理器進行交互。
部署Flink應用程式時,Flink會根據該應用程式配置自動識別所需的資源,並向資源管理器請求。如果發生故障,Flink會通過請求新資源來替換髮生故障的容器。提交或控制應用程式的所有通訊均通過REST調用進行。這簡化了Flink在許多環境中的集成。
1.3. 部署應用程式在任何地方
Flink的設計目的是在任何規模上運行有狀態流應用程式。應用程式可能被並行化為數千個任務,這些任務分布在集群中並同時執行。因此,一個應用程式可以利用幾乎無限數量的cpu、主記憶體、磁碟和網路IO。而且,Flink很容易維護非常大的應用程式狀態。它的非同步和增量檢查點演算法確保對處理延遲的影響最小,同時保證精確一次(exactly-once)狀態一致性。
1.4. 利用記憶體性能
有狀態的Flink應用程式針對本地狀態訪問進行了優化。任務狀態始終在記憶體中維護,如果狀態大小超過可用記憶體,則在訪問高效的磁碟數據結構中維護。因此,任務通過訪問本地(通常在記憶體中)狀態來執行所有計算,從而產生非常低的處理延遲。通過定期非同步將本地狀態檢查點指向持久存儲,Flink確保了故障發生時的一次狀態一致性。
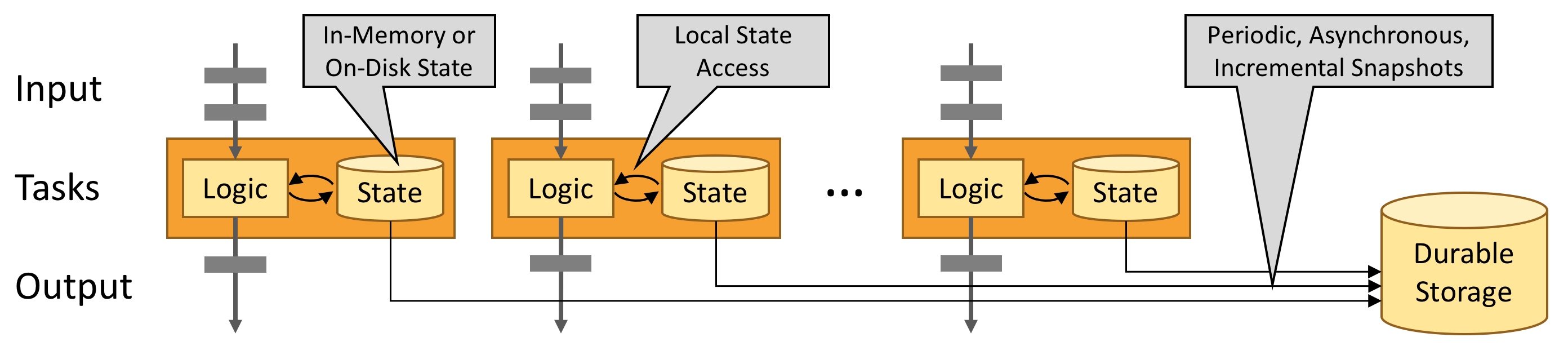
1.5. 流應用程式的構建塊
流應用程式的類型由框架控制流、狀態和時間的能力來定義
Streams(流)
Flink是一個通用的處理框架,可以處理任何類型的流。
- Bounded and unbounded streams : 流可以是無邊界的,也可以是有邊界的。Flink具有複雜的特性來處理無界流,但也有專門的操作符來高效地處理有界流。
- Real-time and recorded streams : 所有數據都以流的形式生成。有兩種處理數據的方法。在生成流時對其進行實時處理,或將流持久化到存儲系統,並在以後進行處理。Flink應用程式可以處理記錄的流和實時流。
State(狀態)
每個重要的流應用程式都是有狀態的,只有在個別事件上應用轉換的應用程式才不需要狀態。任何運行基本業務邏輯的應用程式都需要記住事件或中間結果,以便在稍後的時間點訪問它們,例如在接收下一個事件時或在特定的持續時間之後。
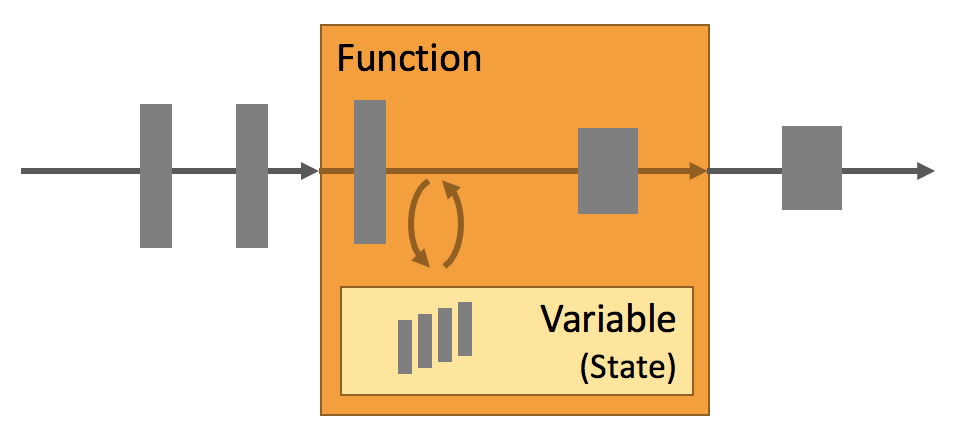
在Flink中,應用程式狀態是非常重要的。這一點在很多地方都有體現:
- Multiple State Primitives : Flink為不同的數據結構(例如,原子值、list、map等)提供狀態原語
- Pluggable State Backends : 應用程式狀態由可插入狀態後端管理並進行檢查點
- Exactly-once state consistency : Flink的檢查點和恢復演算法保證了故障情況下應用狀態的一致性
- Very Large State : 由於其非同步和增量檢查點演算法,Flink能夠維護幾個tb大小的應用程式狀態
- Scalable Applications : 通過將狀態重新分配給更多或更少的worker,Flink支援有狀態應用程式的伸縮
Time(時間)
時間是流應用程式的另一個重要組成部分。大多數事件流具有固有的時間語義,因為每個事件都是在特定的時間點產生的。此外,許多常見的流計算都是基於時間的,比如窗口聚合、會話、模式檢測和基於時間的連接。流處理的一個重要方面是應用程式如何度量時間,即事件時間和處理時間的差異。
Flink提供了一組豐富的與時間相關的特性:
- Event-time Mode : 使用事event-time語義處理流的應用程式根據事件的時間戳計算結果。因此,無論是處理記錄的事件還是實時事件,事件時間處理都可以提供準確一致的結果。
- Watermark Support : Flink在事件時間應用程式中使用水印來推斷時間。 水印還是權衡結果的延遲和完整性的靈活機制。
- Late Data Handling : 在帶有水印的事件時間模式下處理流時,可能會發生所有相關事件到達之前已經完成計算的情況。這種事件稱為遲發事件。Flink具有多個選項來處理較晚的事件,例如通過側面輸出重新路由它們並更新先前完成的結果。
- Processing-time Mode : 除了event-time模式外,Flink還支援processing-time語義。處理時間模式可能適合具有嚴格的低延遲要求的某些應用程式,這些應用程式可以忍受近似結果。
1.6. 分層API
Flink提供了三層API。每個API在簡潔性和表達性之間提供了不同的權衡,並且針對不同的使用場景
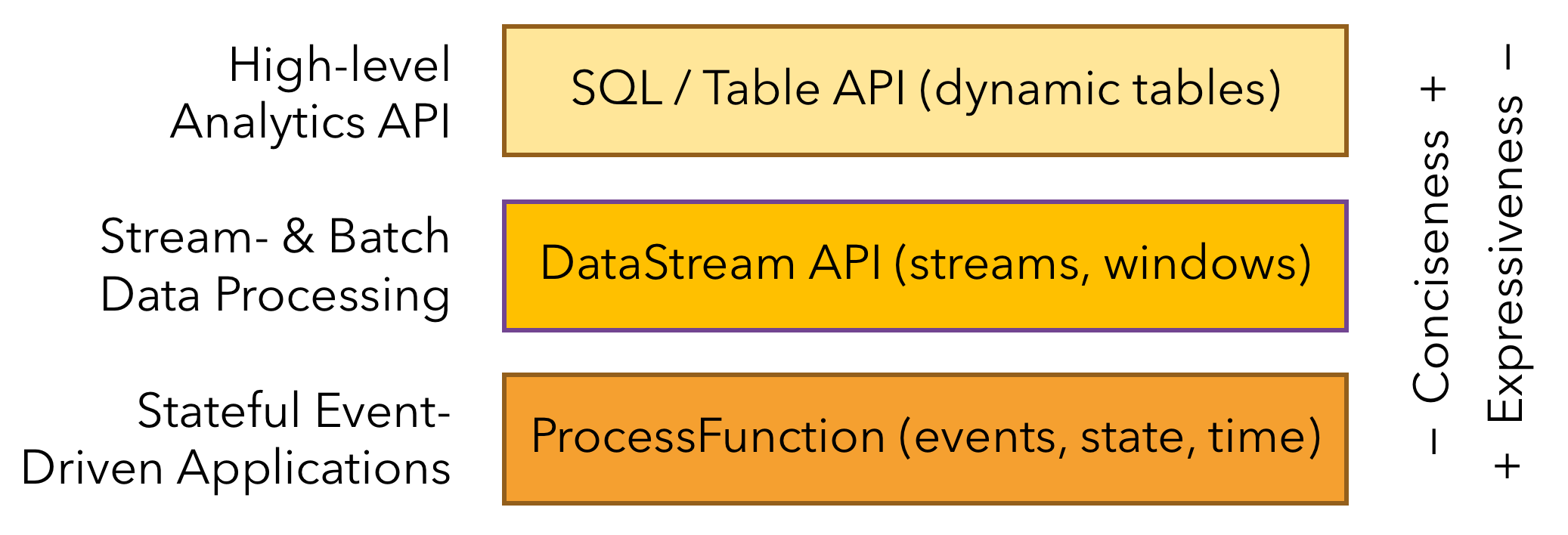
1.7. Stateful Functions
Stateful Functions 是一個API,它簡化了分散式有狀態應用程式的構建。
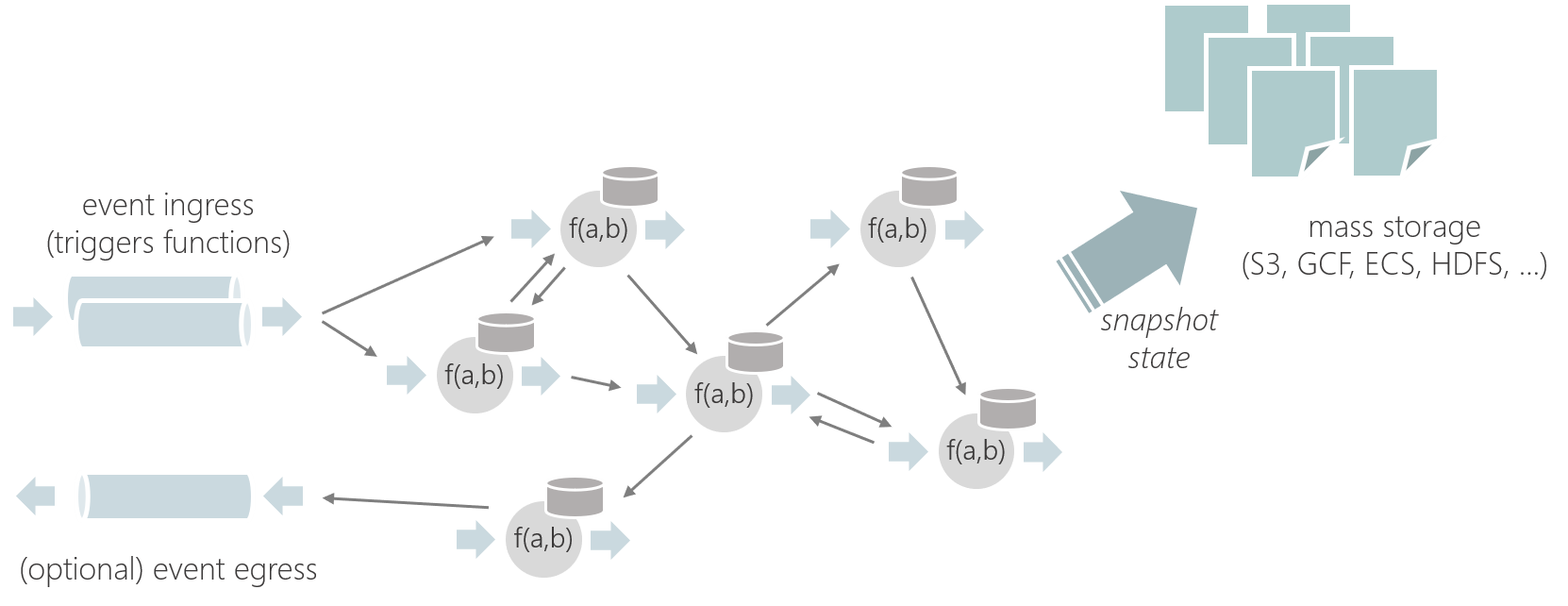
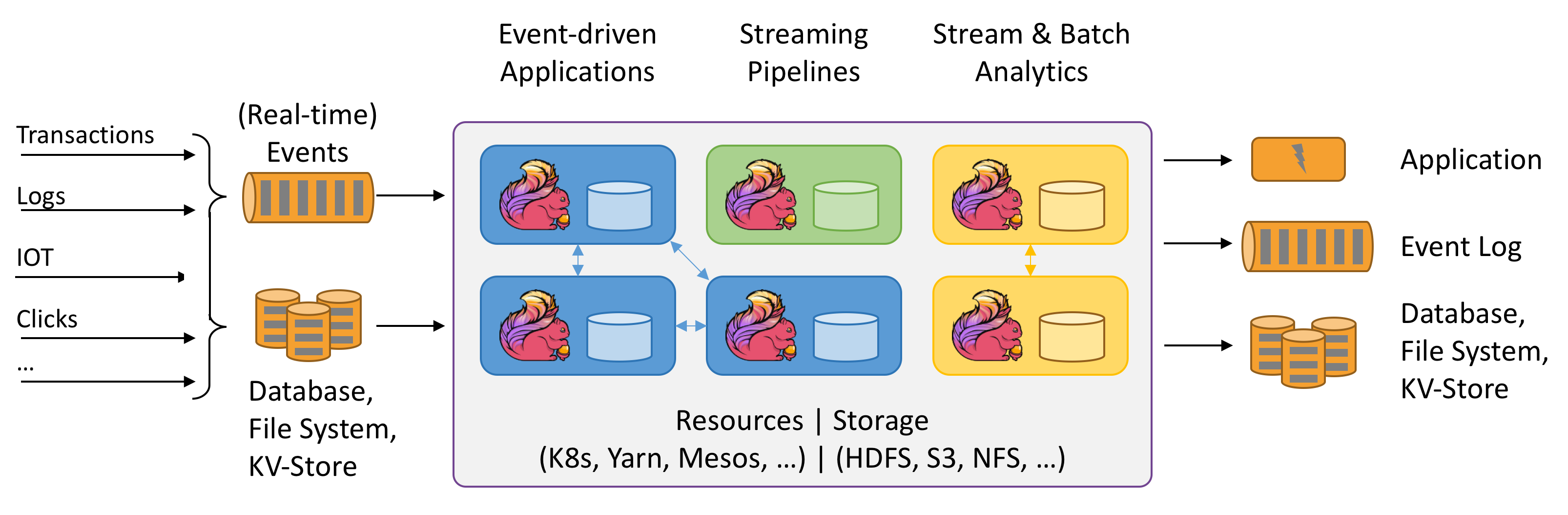
2. 應用場景
Apache Flink是開發和運行許多不同類型應用程式的最佳選擇,因為它具有豐富的特性。Flink的特性包括支援流和批處理、複雜的狀態管理、事件處理語義以及確保狀態的一致性。此外,Flink可以部署在各種資源提供程式上,例如YARN、Apache Mesos和Kubernetes,也可以作為裸機硬體上的獨立集群進行部署。配置為高可用性,Flink沒有單點故障。Flink已經被證明可以擴展到數千個內核和TB級的應用程式狀態,提供高吞吐量和低延遲,並支援世界上一些最苛刻的流處理應用程式。
下面是Flink支援的最常見的應用程式類型:
- Event-driven Applications(事件驅動的應用程式)
- Data Analytics Applications(數據分析應用程式)
- Data Pipeline Applications(數據管道應用程式)
2.1. Event-driven Applications
事件驅動的應用程式是一個有狀態的應用程式,它從一個或多個事件流中獲取事件,並通過觸發計算、狀態更新或外部操作對傳入的事件作出反應。
事件驅動的應用程式基於有狀態的流處理應用程式。在這種設計中,數據和計算被放在一起,從而可以進行本地(記憶體或磁碟)數據訪問。通過定期將檢查點寫入遠程持久存儲,可以實現容錯。下圖描述了傳統應用程式體系結構和事件驅動應用程式之間的區別。
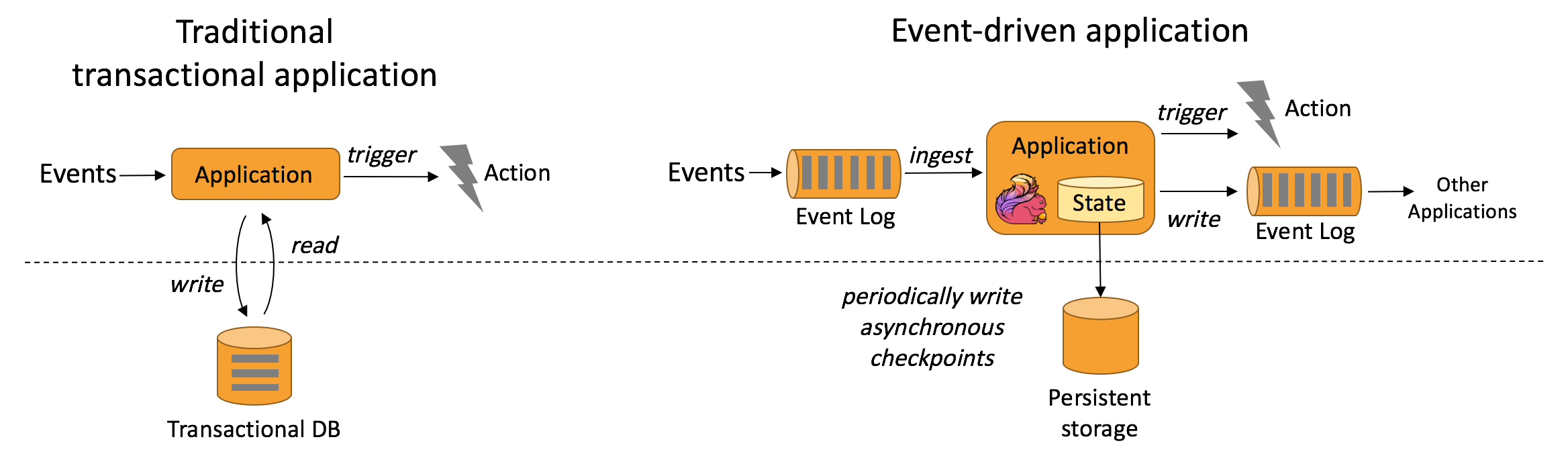
代替查詢遠程資料庫,事件驅動的應用程式在本地訪問其數據,從而在吞吐量和延遲方面獲得更好的性能。可以定期非同步地將檢查點同步到遠程持久存,而且支援增量同步。不僅如此,在分層架構中,多個應用程式共享同一個資料庫是很常見的。因此,資料庫的任何更改都需要協調,由於每個事件驅動的應用程式都負責自己的數據,因此更改數據表示或擴展應用程式所需的協調較少。
對於事件驅動的應用程式,Flink的突出特性是savepoint。保存點是一個一致的狀態鏡像,可以用作兼容應用程式的起點。給定一個保存點,就可以更新或調整應用程式的規模,或者可以啟動應用程式的多個版本進行A/B測試。
典型的事件驅動的應用程式有:
- 欺詐檢測
- 異常檢測
- 基於規則的提醒
- 業務流程監控
- Web應用(社交網路)
2.2. Data Analytics Applications
傳統上的分析是作為批處理查詢或應用程式對已記錄事件的有限數據集執行的。為了將最新數據合併到分析結果中,必須將其添加到分析數據集中,然後重新運行查詢或應用程式,結果被寫入存儲系統或作為報告發出。
有了複雜的流處理引擎,分析也可以以實時方式執行。流查詢或應用程式不是讀取有限的數據集,而是接收實時事件流,並在使用事件時不斷地生成和更新結果。結果要麼寫入外部資料庫,要麼作為內部狀態進行維護。Dashboard應用程式可以從外部資料庫讀取最新的結果,也可以直接查詢應用程式的內部狀態。
Apache Flink支援流以及批處理分析應用程式,如下圖所示:
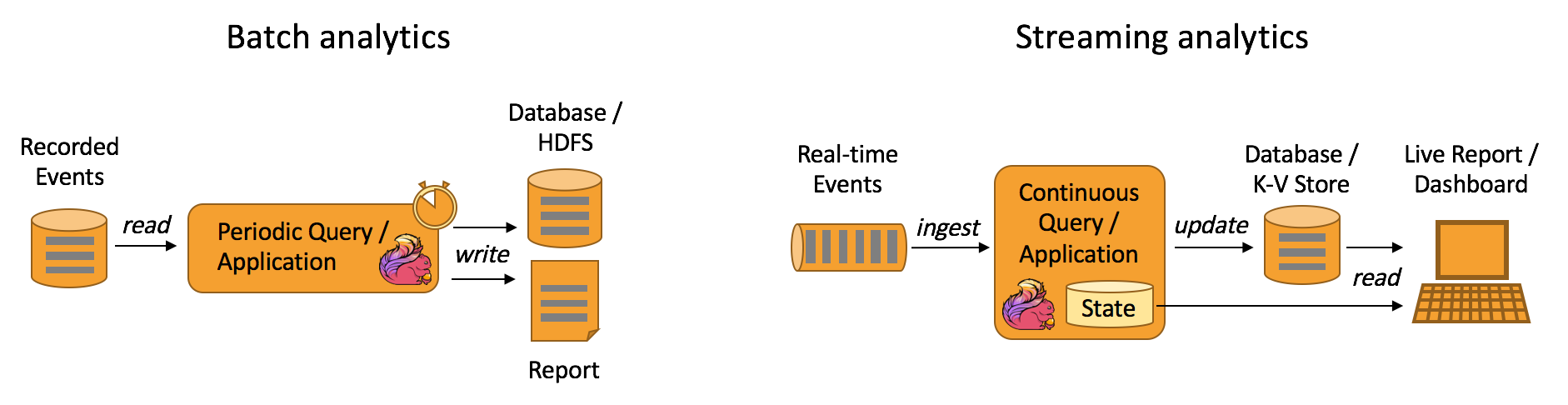
典型的數據分析應用程式有:
- 電信網路品質監控
- 產品更新分析及移動應用實驗評估
- 消費者技術中實時數據的特別分析
- 大規模圖分析
2.2. Data Pipeline Applications
提取-轉換-載入(ETL)是在存儲系統之間轉換和移動數據的常用方法。通常,會定期觸發ETL作業,以便將數據從事務性資料庫系統複製到分析資料庫或數據倉庫。
數據管道的作用類似於ETL作業。它們轉換和豐富數據,並可以將數據從一個存儲系統移動到另一個存儲系統。但是,它們以連續流模式運行,而不是周期性地觸發。因此,它們能夠從不斷產生數據的源讀取記錄,並以低延遲將其移動到目的地。例如,數據管道可以監視文件系統目錄中的新文件,並將它們的數據寫入事件日誌。另一個應用程式可能將事件流物化到資料庫,或者增量地構建和完善搜索索引。
下圖描述了周期性ETL作業和連續數據管道之間的差異: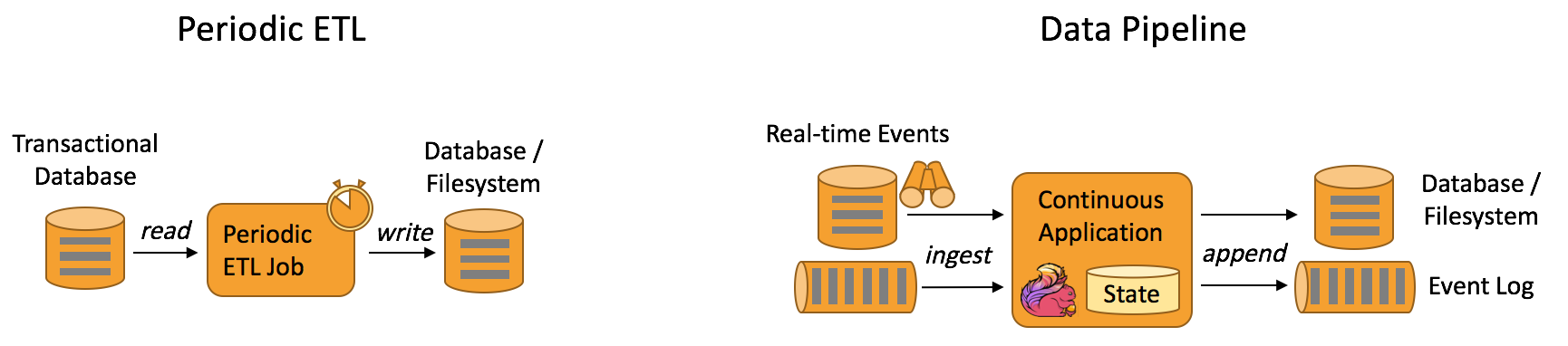
與周期性ETL作業相比,連續數據管道的明顯優勢是減少了將數據移至其目的地的等待時間。此外,數據管道更通用,可用於更多場景,因為它們能夠連續消費和產生數據。
典型的數據管道應用程式有:
- 電商中實時搜索索引的建立
- 電商中的持續ETL
3. 安裝Flink
//flink.apache.org/downloads.html
下載安裝包,這裡下載的是 flink-1.10.1-bin-scala_2.11.tgz
安裝過程參考 //ci.apache.org/projects/flink/flink-docs-release-1.10/getting-started/tutorials/local_setup.html
./bin/start-cluster.sh # Start Flink
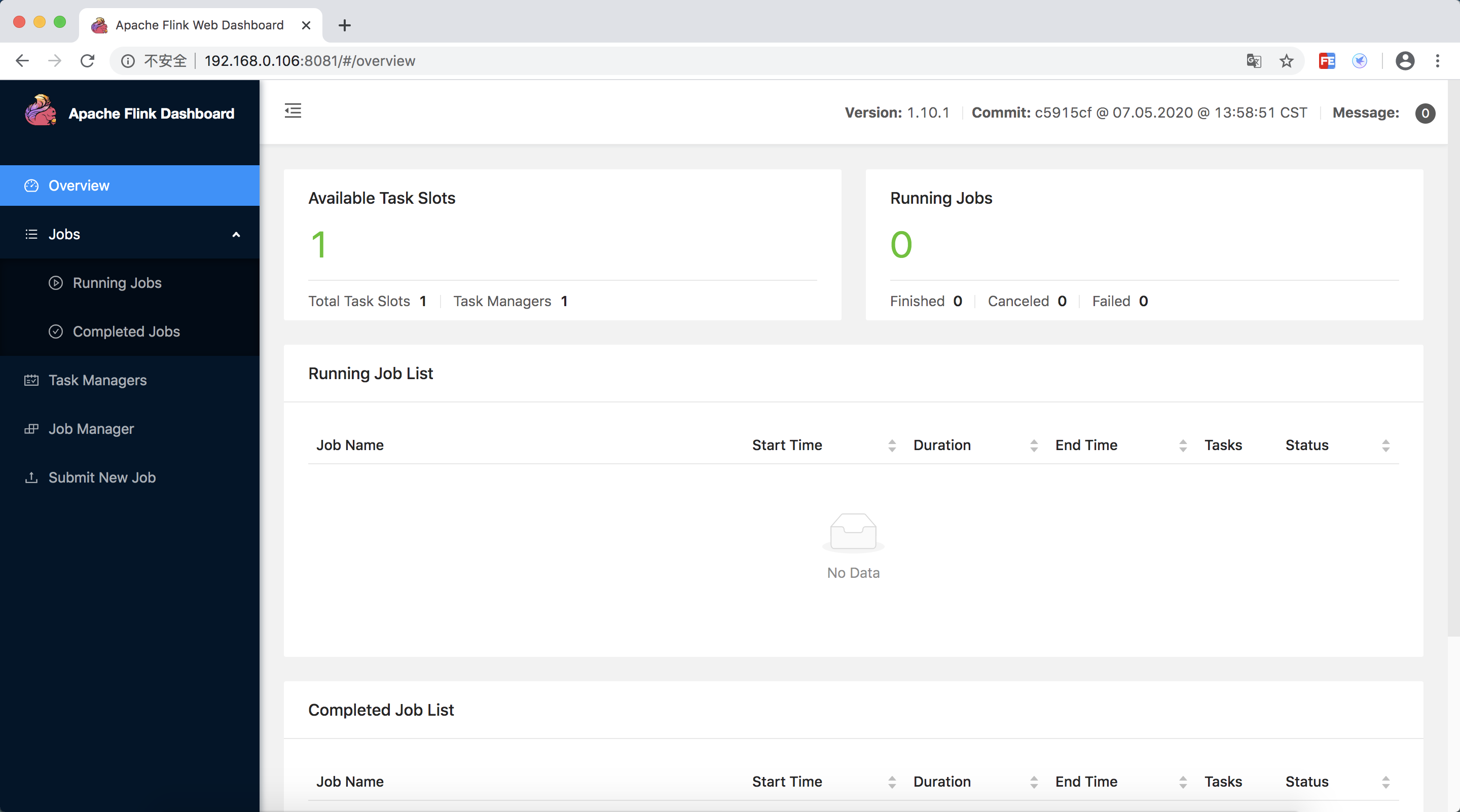
訪問 //localhost:8081
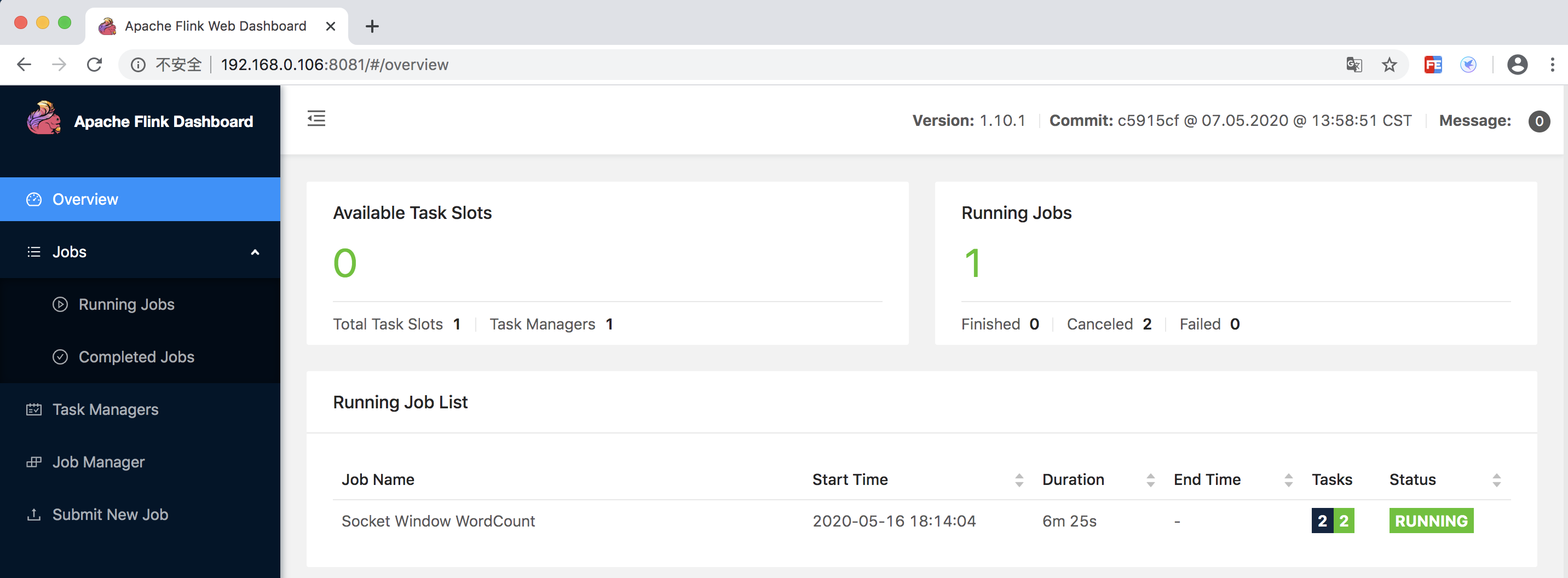
運行 WordCount 示例


文檔
//ci.apache.org/projects/flink/flink-docs-release-1.10/getting-started/


