今天,你遇到redis線上連接超時了嗎?
一封報警郵件,大量服務節點 redis 響應超時。
又來,好煩。
redis 響應變慢,查看日誌,發現大量 TimeoutException。
大量TimeoutException,說明當前redis服務節點上已經堆積了大量的連接查詢,超出redis服務能力,再次嘗試連接的客戶端,redis 服務節點直接拒絕,拋出錯誤。
那到底是什麼導致了這種情況的發生呢?
總結起來,我們可以從以下幾方面進行關註:
一、redis 服務節點受到外部關聯影響
redis服務所在伺服器,物理機的資源競爭及網路狀況等。同一台伺服器上的服務必然面對著服務資源的競爭,CPU,記憶體,固存等。
1、CPU資源競爭
redis屬於CPU密集型服務,對CPU資源依賴尤為緊密,當所在伺服器存在其它CPU密集型應用時,必然會影響redis的服務能力,尤其是在其它服務對CPU資源消耗不穩定的情況下。
因此,在實際規劃redis這種基礎性數據服務時應該注意一下幾點:
1)一般不要和其它類型的服務進行混部。
2)同類型的redis服務,也應該針對所服務的不同上層應用進行資源隔離。
說到CPU關聯性,可能有人會問是否應該對redis服務進行CPU綁定,以降低由CPU上下文切換帶來的性能消耗及關聯影響?
簡單來說,是可以的,這種優化可以針對任何CPU親和性要求比較高的服務,但是在此處,有一點我們也應該特別注意:我們在 關於redis記憶體分析,記憶體優化 中介紹記憶體時,曾經提到過子進程記憶體消耗,也就是redis持久化時會fork出子進程進行AOF/RDB持久化任務。對於開啟了持久化配置的redis服務(一般情況下都會開啟),假如我們做了CPU親和性處理,那麼redis fork出的子進程則會和父進程共享同一個CPU資源,我們知道,redis持久化進程是一個非常耗資源的過程,這種自競爭必然會引發redis服務的極大不穩定。
2、記憶體不在記憶體了
關於redis記憶體分析,記憶體優化 開篇就講過,redis最重要的東西,記憶體。
記憶體穩定性是redis提供穩定,低延遲服務的最基本的要求。
然而,我們也知道作業系統有一個 swap 的東西,也就將記憶體交換到硬碟。假如發生了redis記憶體被交換到硬碟的情景發生,那麼必然,redis服務能力會驟然下降。
swap發現及避免:
1)info memory:
關於redis記憶體分析,記憶體優化 中我們也講過,swap這種情景,此時,查看redis的記憶體資訊,可以觀察到碎片率會小於1。這也可以作為監控redis服務穩定性的一個指標。
2)通過redis進程查看。
首先通過 info server 獲取進程id:
查看 redis 進程 swap 情況:cat /proc/1686/smaps
![]()
確定交換量都為0KB或者4KB。
3)redis服務maxmemory配置。
關於redis記憶體分析,記憶體優化 中我們提到過,對redis服務必要的記憶體上限配置,這是記憶體隔離的一種必要。需要確定的是所有redis實例的分配記憶體總額小於總的可用物理記憶體。
4)系統優化:
另外,在最初的基礎服務作業系統安裝部署時,也需要做一些必要的前置優化,如關閉swap或配置系統盡量避免使用。
3、網路問題
網路問題,是一個普遍的影響因素。
1)網路資源耗盡
簡單來說,就是頻寬不夠了,整個屬於基礎資源架構的問題了,對網路資源的預估不足,跨機房,異地部署等都會成為誘因。
2)連接數用完了
一個客戶端連接對應著一個TCP連接,一個TCP連接在LINUX系統內對應著一個文件句柄,系統級別連接句柄用完了,也就無法再進行連接了。
查看當前系統限制:ulimit -n
設置:ulimit -n {num}
3)埠TCP backlog隊列滿了
linux系統對於每個埠使用backlog保存每一個TCP連接。
redis配置:tcp_backlog 默認511

高並發情境下,可以適當調整此配置,但需要注意的是,同時要調整系統相關設置。
系統修改命令:echo {num}>/proc/sys/net/core/somaxconn
查看因為隊列溢出導致的連接絕句:netstat -s | grep overflowed
![]()
4)網路延遲
網路品質問題,可以使用 redis-cli 進行網路狀況的測試:
延遲測試:redis-cli -h {host} -p {port} –latency
![]()
取樣延遲測試:redis-cli -h {host} -p {port} –latency-history 默認15s一次
![]()
圖形線上測試結果:redis-cli -h {host} -p {port} –latency-dist
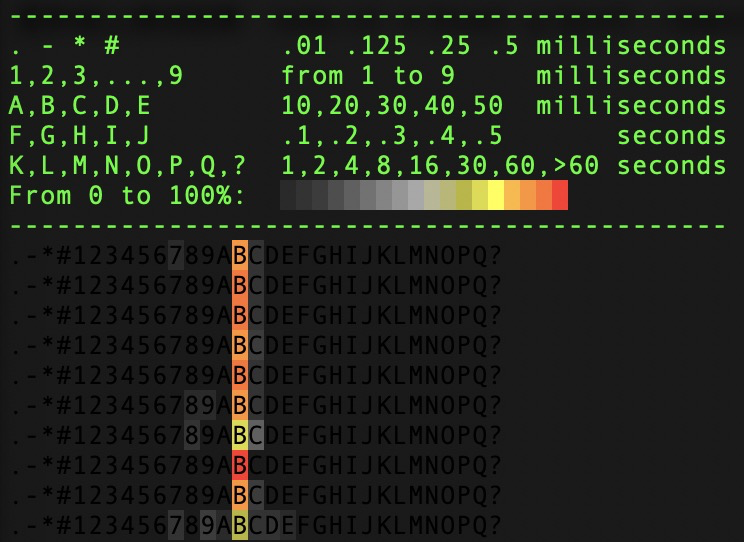
4)網卡軟中斷
單個網卡隊列只能使用單個CPU資源問題。
二、redis 服務使用問題
1、慢查詢
如果你的查詢總是慢查詢,那麼必然你的使用存在不合理。
1)你的key規劃是否合理
太長或太短都是不建議的,key需要設置的簡短而有意義。
2)值類型選擇是否合理。
hash還是string,set還是zset,避免大對象存儲。
線上可以通過scan命令進行大對象發現治理。
3)是否能夠批查詢
get 還是 mget;是否應該使用pipeline。
4)禁止線上大數據量操作
2、redis 服務運行狀況
查看redis服務運行狀況:redis-cli -h {host} -p {port} –stat

keys:當前key總數;mem:記憶體使用;clients:當前連接client數;blocked:阻塞數;requests:累計請求數;connections:累計連接數
3、持久化操作影響
1)fork子進程影響
redis 進行持久化操作需要fork出子進程。fork子進程本身如果時間過長,則會產生一定的影響。
查看命令最近一次fork耗時:info stats

單位微妙,確保不要超過1s。
2)AOF刷盤阻塞
AOF持久化開啟,後台每秒進行AOF文件刷盤操作,系統fsync操作將AOF文件同步到硬碟,如果主執行緒發現距離上一次成功fsync超過2s,則會阻塞後台執行緒等待fsync完成以保障數據安全性。
3)THP問題
關於redis記憶體分析,記憶體優化 中我們講過透明大頁問題,linux系統的寫時複製機制會使得每次寫操作引起的頁複製由4KB提升至2M從而導致寫慢查詢。如果慢查詢堆積必然導致後續連接問題。


