騰訊優圖:帶噪學習和協作學習,不完美場景下的神經網路優化策略
神經網路的成功建立在大量的乾淨數據和很深的網路模型基礎上。但是在現實場景中數據和模型往往不會特別理想,比如數據層面有誤標記的情況,像小狗被標註成狼,而且實際的業務場景講究時效性,神經網路的層數不能特別深。
騰訊優圖不斷迭代數據和模型缺陷情況下神經網路的有效訓練方法,通過noisy label learning和collaborative learning技術,實現用比較淺的網路解決noisy dataset問題。相關技術已經在騰訊的眾多業務場景上(行人重識別,內容審核等)落地。本文整理自騰訊優圖和機器之心聯合主辦的「CVPR2020線上分享」,分享嘉賓為騰訊優圖實驗室高級研究員Louis。
刻畫noisy label與任務目標
一般來講,noisy label是可以通過一個噪音轉移矩陣T來刻畫,也就是noise transition matrix T。人為設計一個噪音轉移矩陣T,之後如果我們知道這個數據集中 clean label的分布,將這個分布乘以T就可以得到noisy label的分布。有了noisy label分布和對應的數據集之後,就可以進行很多帶噪方法的驗證。
接下來用數學描述來刻畫一下我們帶噪學習的目標。對於一個分類任務,我們的目標可以寫成下面的形式,x和y代表樣本和對應的label, 在今天的語境下F是神經網路。我們的任務目標是在數據集下優化一個loss function,使得在noisy label下訓練得到的解,在性能上接近在clean label下訓練得到的解,那麼數學表達就是,f ̃是f的一個子集。

各顯神通,主要帶噪學習方法探索
關於帶噪學習,近些年有一些重要論文。
NeurlPS 2018上的一篇論文(Generalized Cross Entropy Loss Training Deep Neural Networks with Noisy Labels)提出GCE loss(Generalized Cross Entropy loss)。它的背景是,MAE以均等分配的方式處理各個sample,而CE(cross entropy)會向識別困難的sample傾斜,因此針對noisy label,MAE比CE更加魯棒,但是CE的準確度更高,擬合也更快。於是這篇文章提出GCE loss,結合MAE與CE二者的優勢。
還有的論文(LDMI: A Novel Information-theoretic Loss Function for Training Deep Nets Robust to Label Noise, NeurlPS 2019)是基於資訊理論設計的loss function,Deterministic information loss。它的Motivation是想尋找一個資訊測度(information measure)I。假設在I下任意存在兩個分類器f、f』,如果在噪音數據集下,通過I, f比f』表現得更好,那麼在乾淨數據集下,f比f』表現得也好,也就是說它在噪音數據集和乾淨數據集上滿足一致性。如果在噪音數據集下它表現得好,通過一致性,在乾淨數據集下表現得也一定很好。
把時間往前推進一下,講一些目前正在審稿中的文章(Peer Loss Functions: Learning from Noisy Labels without Knowing Noise Rates (under review)
;Loss with Paired Samples: A Robust Learning Approach that Adapts to Label Noise (under review),關於Peer loss。Peer loss是由兩個loss function的加權得到的,比如l1, l2。α是一個超參數,衡量兩個loss的權重大小。l1、l2可以是任何分類導向的loss function,比如CE、MSE、MAE都行。Loss的構造主要是在於樣本的構造上,我們看l1的樣本,Xi對應就是數據集中原始的樣本和對應的label。

為什麼peer loss可以很好地解決noisy label問題?為了方便,這裡先把l1、l2都定義成CE loss,那麼在第一項,它表現的像positive learning,因為它就是一個傳統的CE function,而在第二項,它像 negative learning,也就是在標記錯的時候,比如把狗標成汽車,如果用positive learning進行學習的話那就出現問題了,它是隨機從一個label中進行抽取,希望讓模型學到它不是一個鳥,狗不是一個鳥,它的語義關係首先是成立的,是正確的,這樣一來,第二項對模型也能起到一個積極的導向作用。
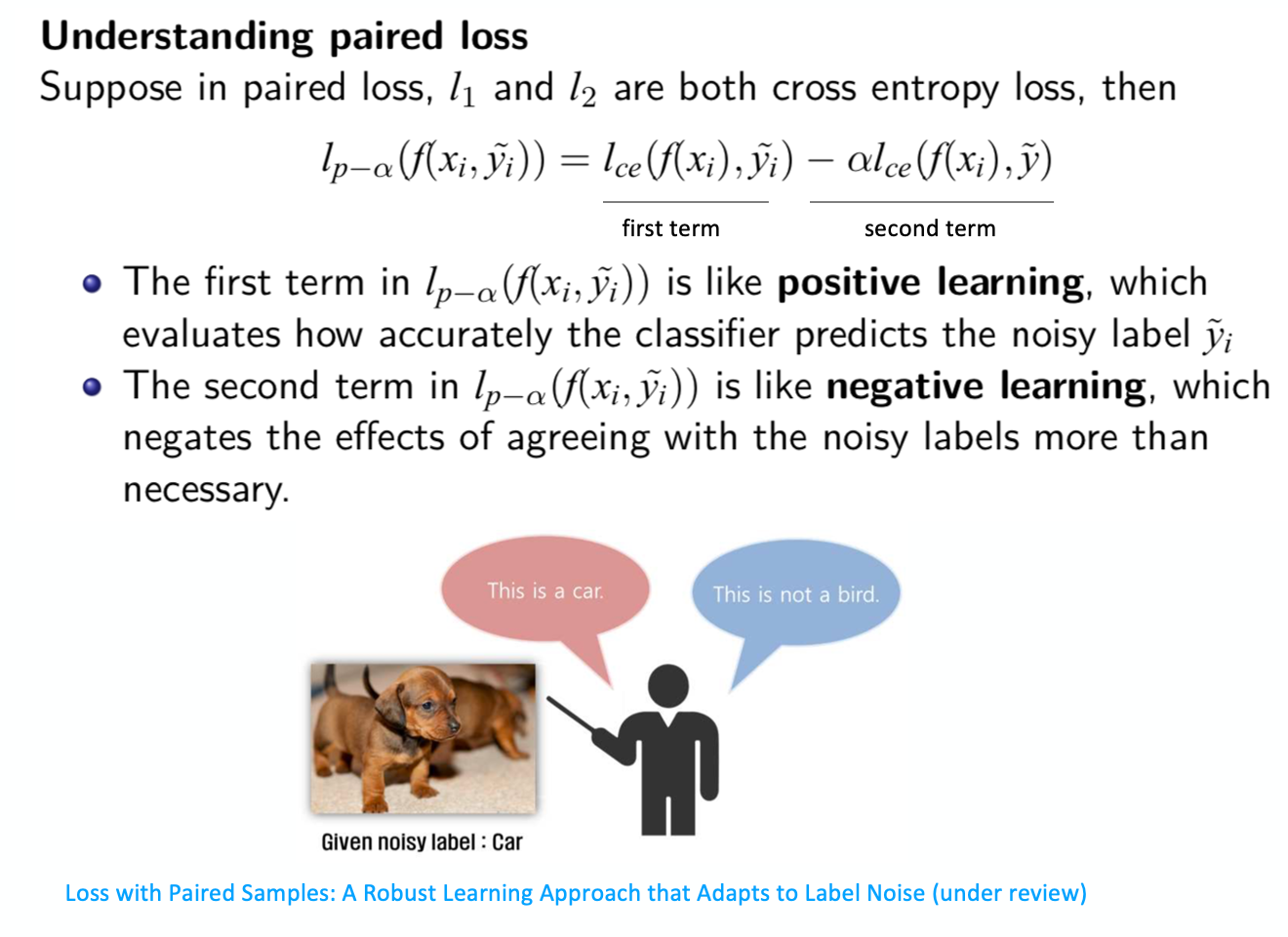
更加有意思的是,單獨訓練第一項和單獨訓練第二項都不可能使模型達到理論上的最優,因為模型存在noisy label。但是我們證明了它們兩項聯合訓練,在統計上是可以讓模型達到最優。
文章提出了一個主要定理,就是noise魯棒性,我們證明了存在一個最優的超參數α,用peer loss在noisy label下進行優化,它得出的神經網路的解等價於用l1在clean label下進行優化,可以把l1理解成CE loss。所以我們理論證明了peer loss的最優性。
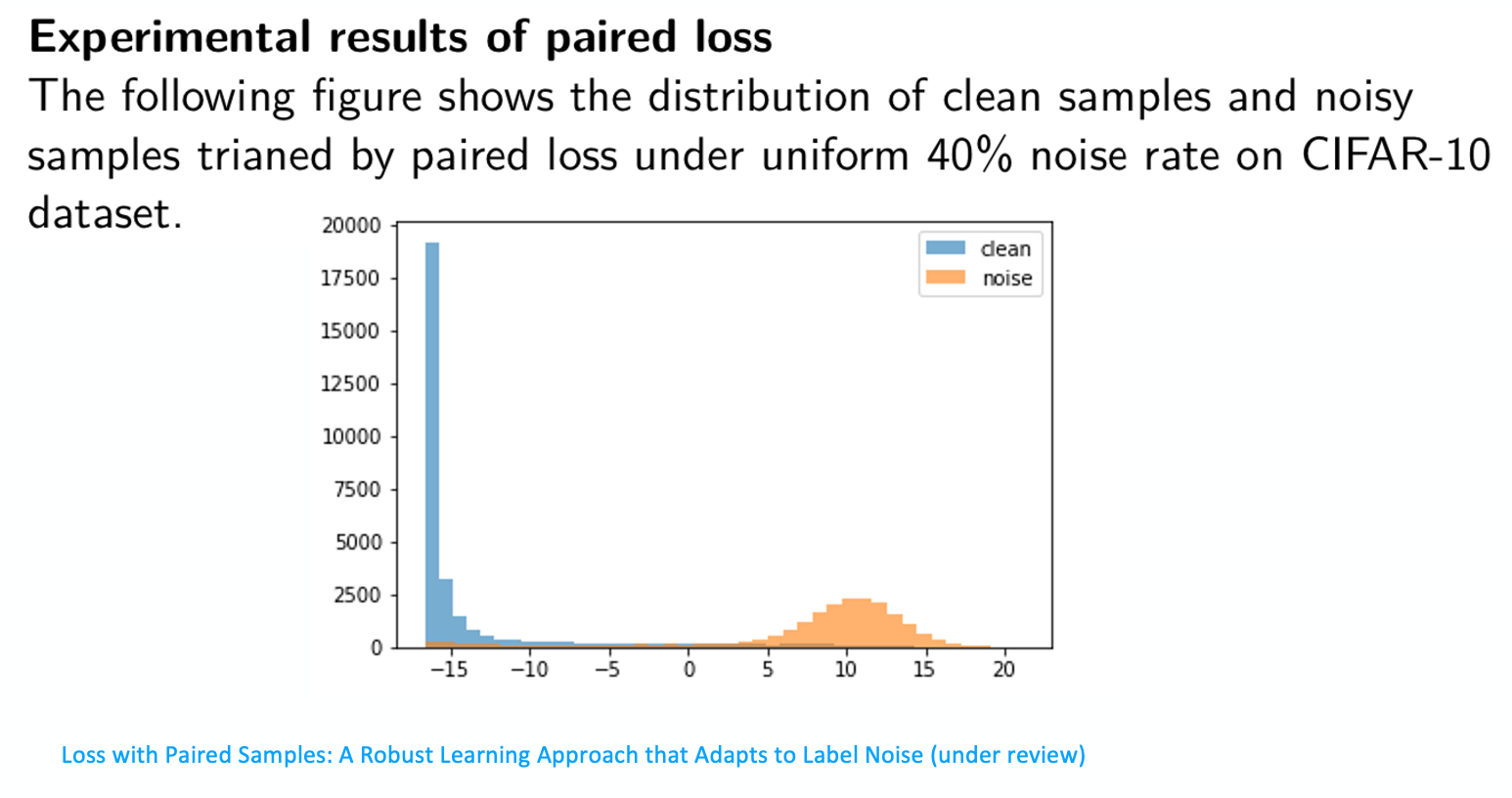
看一下peer loss在數值方面的結果,這裡使用的數據集是CIFAR-10,存在著40%的uniform noise,就是symmetric noise。圖中的藍色代表clean label分布,橘黃色代表noisy label分布。通過peer loss優化後,我們畫一下clean label和noisy label的分布,可以看到我們的網路把這兩個完全分開了,證明peer loss是非常有效的。
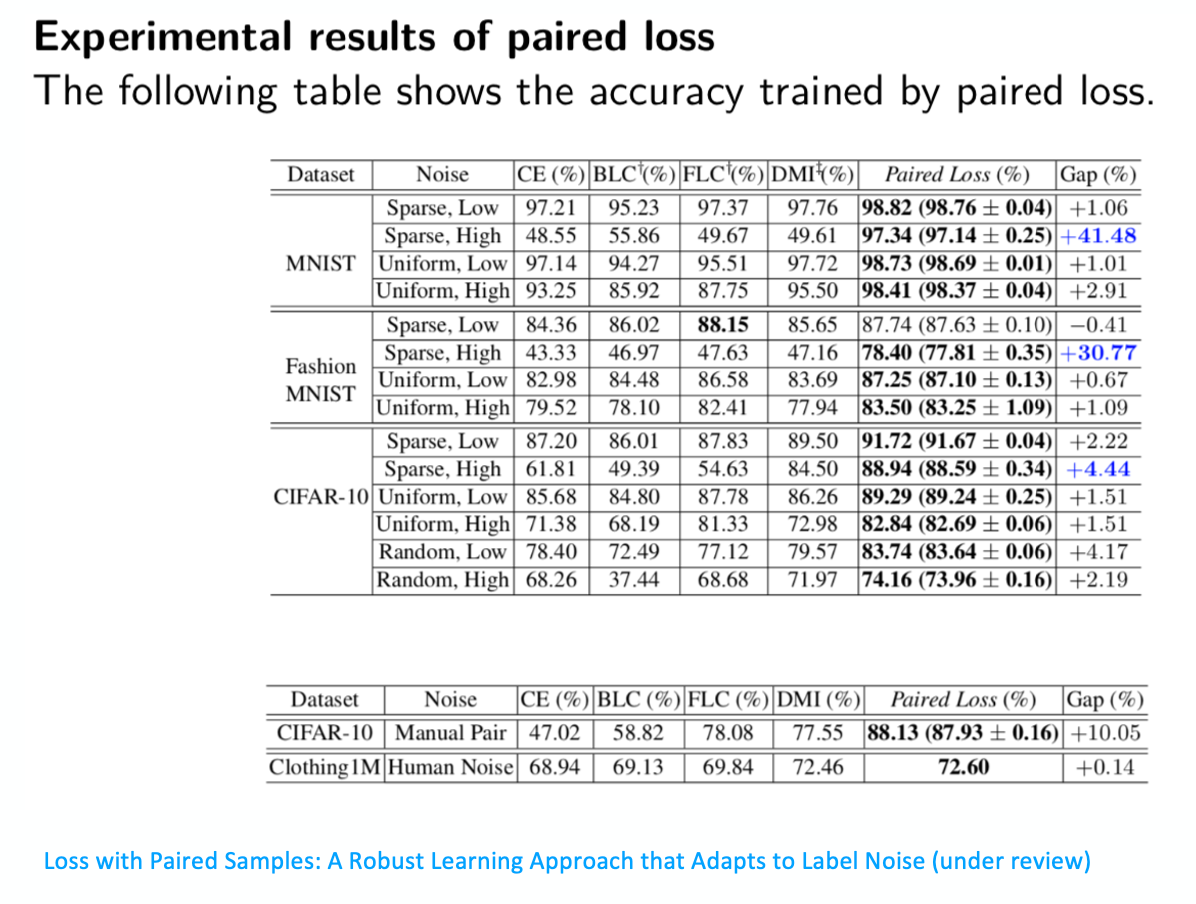
接下來,在各個數據集上衡量peer loss的表現,我們在MNIST、Fashion MNIST、CIFAR-10上進行了實驗,可以看到MNIST和Fashion MNIST上,用peer loss優化的結果超過了一些其他的結果,包括DMI的結果三四十個點,這是非常大的進步。在CIFAR-10上也超過將近5個點,四個多點左右這樣的一個結果。而且,我們發現peer loss尤其對Sparse,High這種noise type表現得特別明顯。
以上講的方法主要是設計loss function的思路,讓網路能夠抵抗noisy label。但其實還有很多其他方法,比如samples selection和label correction,這兩個方法是通過選擇樣本和對樣本進行糾正來進行帶噪學習訓練。發表在NeurlPS 2018上的這篇論文(Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy Labels)就是關於Co-teaching的。它的基本假設是認為noisy label的loss要比clean label的要大,於是它並行地訓練了兩個神經網路A和B,在每一個Mini-batch訓練的過程中,每一個神經網路把它認為loss比較小的樣本,送給它其另外一個網路,這樣不斷進行迭代訓練。
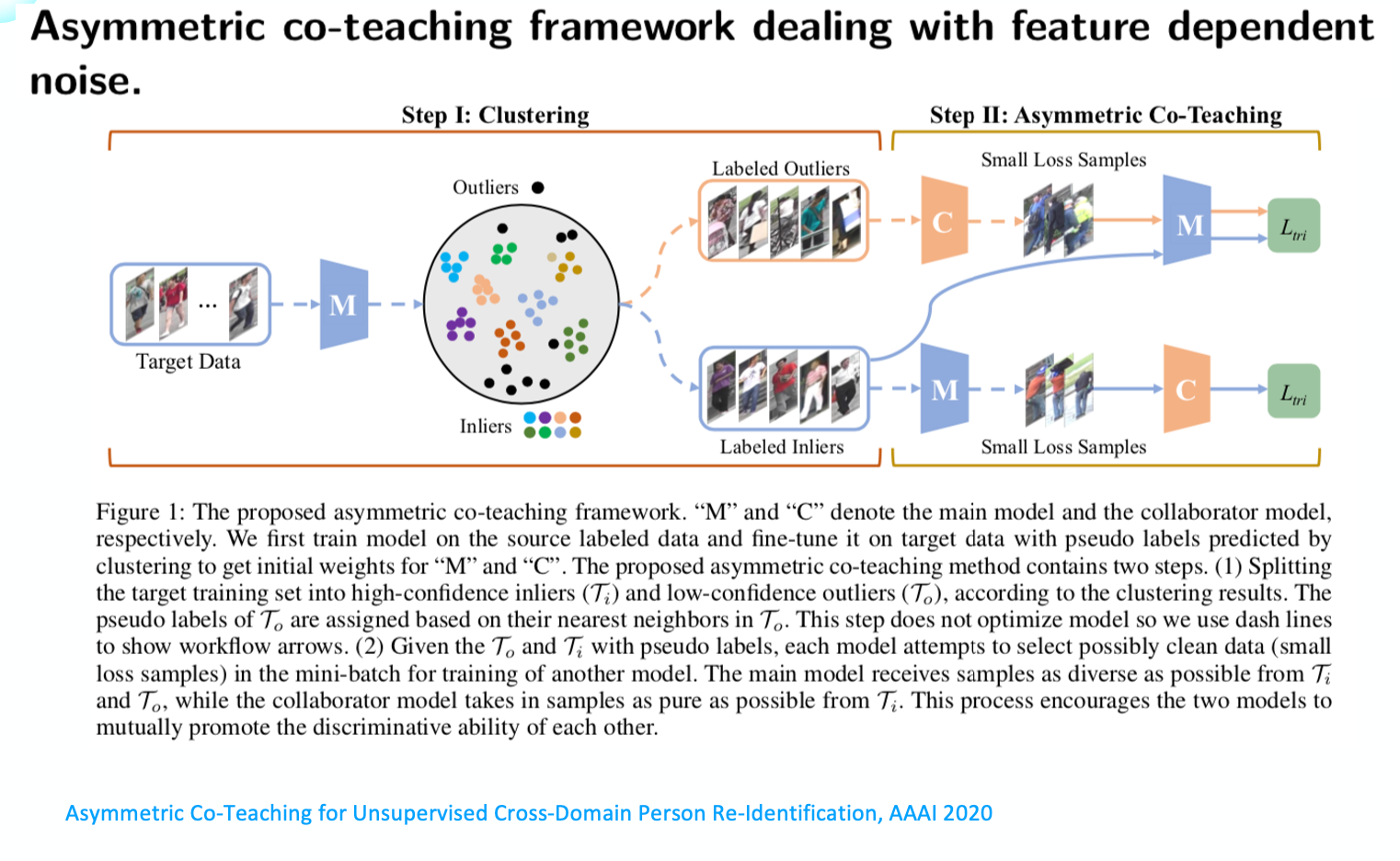
接下來介紹騰訊優圖在2019年底發表的一篇文章(Asymmetric Co-Teaching for Unsupervised Cross-Domain Person Re-Identification),解決一類特殊的label noise。這類label noise不是人為標註產生的,而是在訓練中產生,在模型的聚類過程中產生的。比如說有這樣一批沒有標記的樣本,然後通過一個聚類演算法得到inliers和outliers,outliers是聚類演算法中認為這一點是孤立點或者是噪音點,它沒法歸到聚類演算法的ID裡面,就叫做outliers,inliers是聚類演算法對這些樣本進行聚類後得到一個個cluster,但每一個cluster裡面可能存在noise。
騰訊優圖提出了一個框架,叫Asymmetric Co-teaching。因為聚類中存在inlier和outliers,這兩個不同源,所以用非對稱的思想去解決noise label的問題。
具體來說,首先有很多 Target Data,經過模型聚類得到Inliers和Outliers。然後通過k近鄰將outliers進行label。下面一步是比較關鍵的,和Co-teaching一樣,我們也並行訓練兩個神經網路C和M,但是我們往C和M送到的樣本是非同源的,一個inlier一個outliers。然後C和M互相發送他們認為loss比較小的樣本進行迭代訓練。每次訓練之後,再進行聚類。不斷重複這種迭代過程,最後我們發現outliers越來越少,Inlier也是越來越多,Inlier每個ID的noise也是越來越少。
Asymmetric Co-teaching的結果不錯,我們主要是在行人重識別這個問題上衡量方法的有效性,也就是ReID。可以看我們這個clustering-based的方法在Market和Duke數據集中有不錯的表現,比之前的一些方法也多了五六個點。
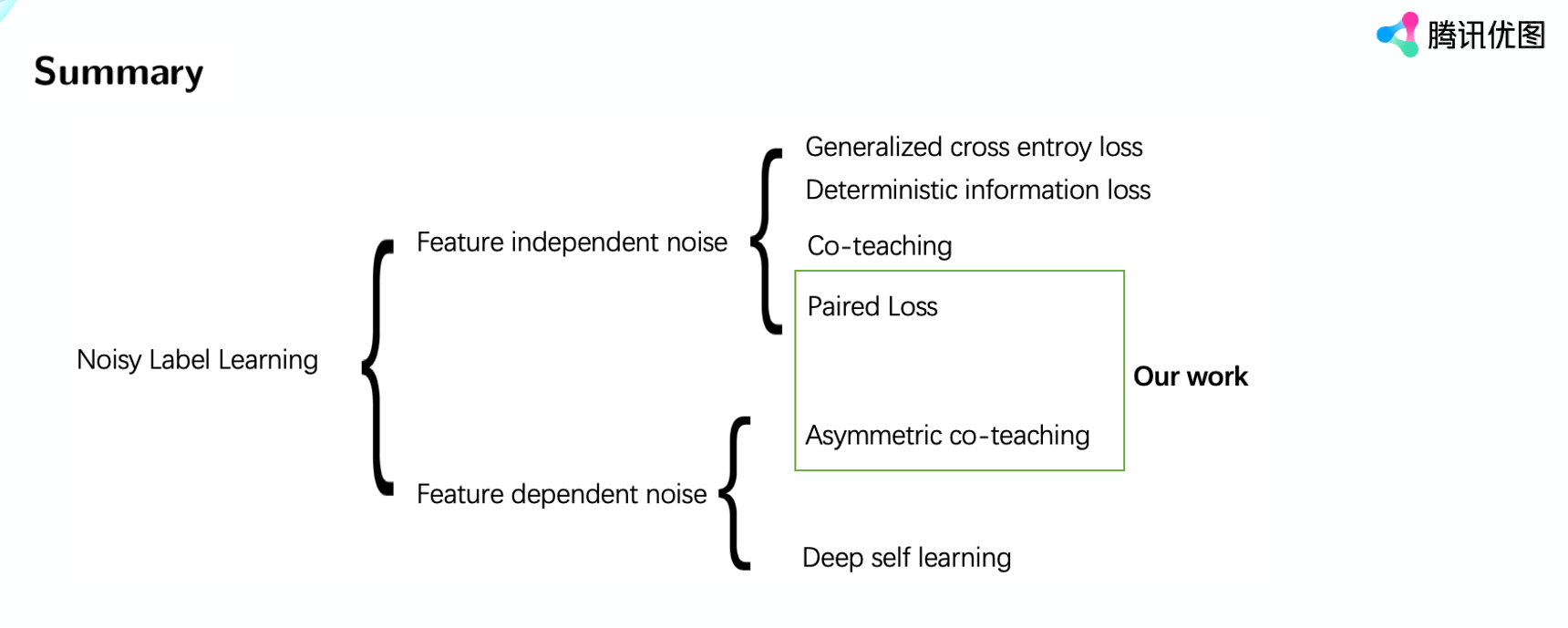
總結一下,關於noise label前面主要介紹了七個方法,這些方法可以歸為Feature independent noise和Feature dependent noise。值得注意的是,並不是一個方法去解決Feature independent noise就無法解決Feature dependent noise,只是說一個方法它更適用於解決哪個問題。標線框的這兩個是我們騰訊優圖的工作。
我的介紹非常有限,如果你感興趣希望讀更多的研究,可以訪問這個網址,裡面有更多關於noisy label learining的文章:
//github.com/subeeshvasu/Awesome-Learning-with-Label-Noise
激活無效濾波器,提升神經網路性能
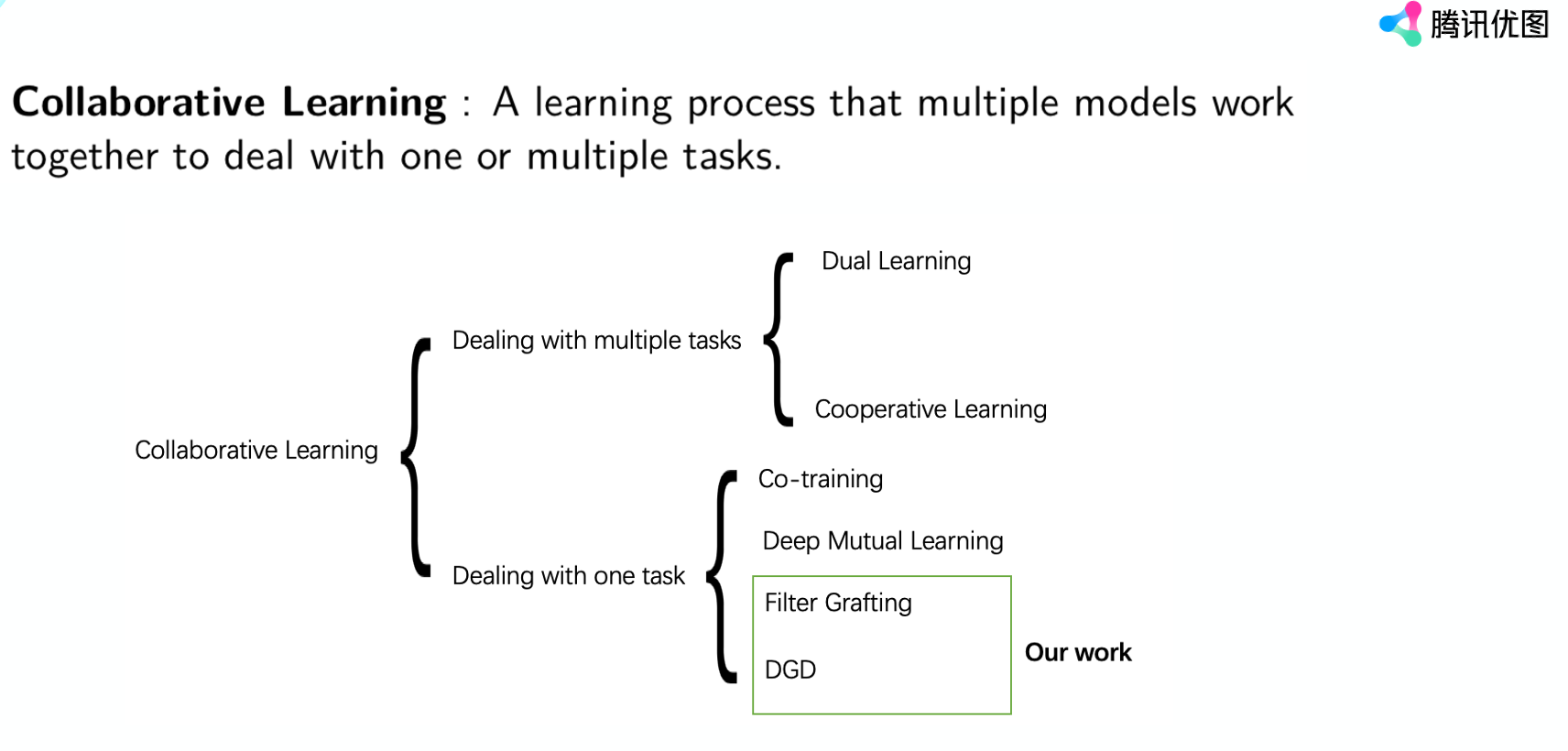
關於協作學習其實學術界沒有統一的定義,一般來講只要是多個模型互相協作,去解決一個或者多個任務,那就可以把這種學習範式叫做協作學習。
按照任務分,協作學習可以分成兩個:一個是解決多個任務,有dual learning和cooperative learning;一個是多個模型一起協作解決一個任務。因為dual learning和cooperative learning主要是解決自然語言處理的問題,自然語言處理涉及到比如說中文翻譯成英文,英文翻譯成中文,這是一個兩個任務,是多個任務。我們這裡主要是講CV方面,所以說我們主要講解決一個任務,接下來會介紹co-training、deep mutual learning、filter grafting和DGD這幾個工作。
關於 Co-training的這篇文章Combining labeled and unlabeled data with co-training,非常古老,是1998年的,但是它的引用量已經好幾千,它其實是解決了半監督的問題。
發表在CVPR 2018年的一篇論文deep mutual learning。它的思想極其簡單,我們都知道蒸餾的時候teacher是fixed,然後對於學生進行監督,這篇文章的思想就是在蒸餾的過程中老師並不保持fixed,也進行迭代的訓練操作,也就是說老師教學生,學生也教老師。
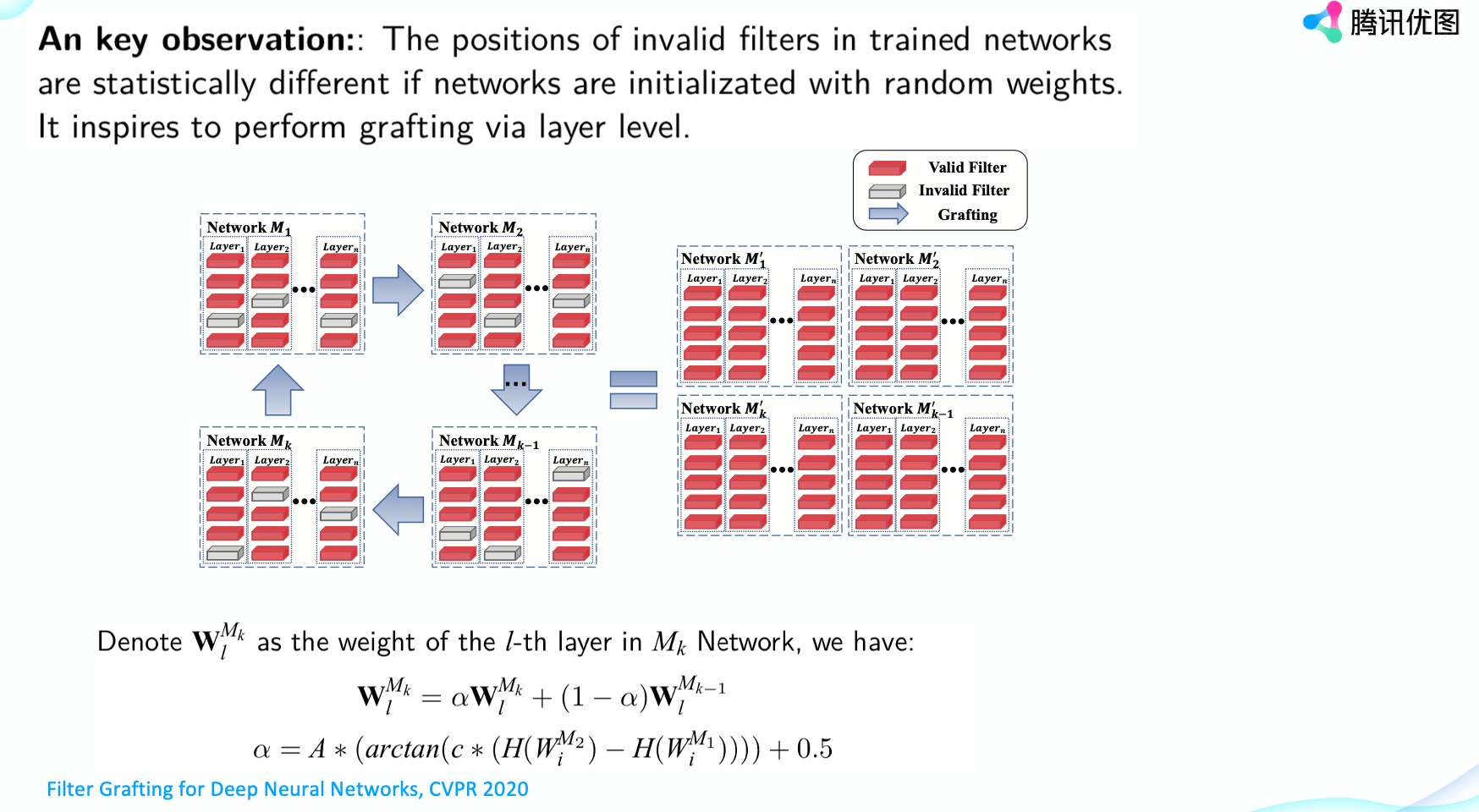
時間再拉近一點,這是今年騰訊優圖中稿CVPR 2020年的一篇文章(Filter Grafting for Deep Neural Networks)。這篇文章的motivation是什麼呢?我們知道訓練好的神經網路存在很多無效的filter, filter pruning技術主要對無效的濾波器進行移除使網路的推理速度增加。
與pruning相反,在這篇文章中,我們提出濾波器嫁接(filter grafting)技術。我們並不是移除網路的無效濾波器,而是將其他網路的有效濾波器的參數嫁接到無效濾波器上,通過引入外部資訊的方法來激活無效濾波器,讓它們重新變得有價值起來,來進一步提高網路的表達能力。
這篇文章有一個非常重要的發現是什麼呢?我們訓練的神經網路如果在初始化的時候不一樣,在訓練完之後,無效filter的位置是統計無關的。整個我們可以並行訓練多個網路,多個網路之間互相進行這種操作,結束訓練之後每個神經網路都會有更好的特徵表達,而且測試的時候準確率性能也會更好。
可以看一下這個結果,對於在CIFAR-10、CIFAR-100上進行的實驗,與mutual learning、傳統的distillation、還有RePr相比較,Filter Grafting效果還是不錯的,對於一些大網路,特別是對於CIFAR-100有兩個點的提升。

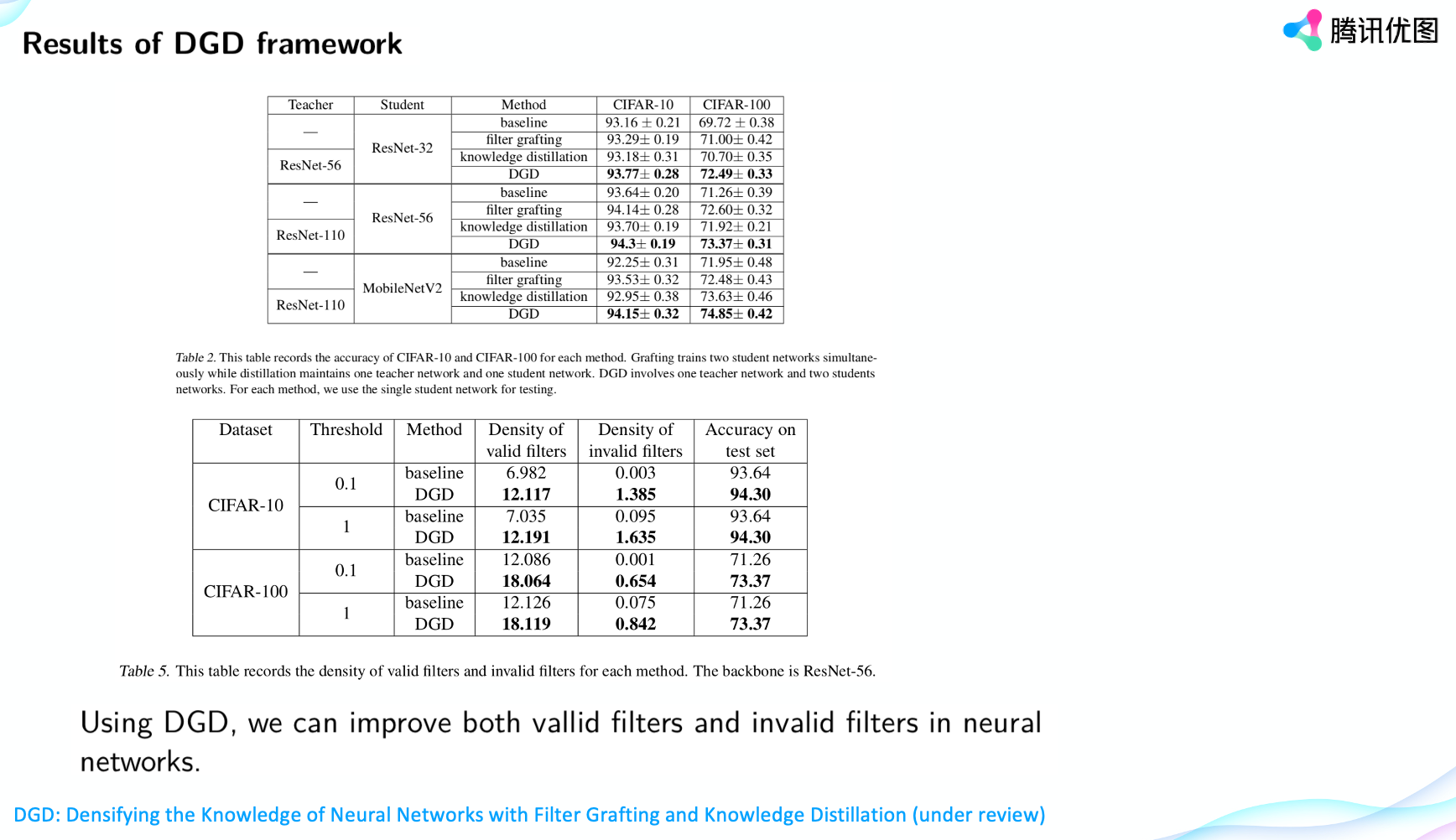
Grafting是可以有效提高無效filter,但是可能有效filter的資訊量會減少。這篇還在審稿中的文章DGD: Densifying the Knowledge of Neural Networks with Filter Grafting and Knowledge Distillation是關於我們的新發現,就是傳統的蒸餾可以解決這個問題,這是這篇文章的貢獻。
我們在做grafting加權的時候,比如說M1和M2進行加權,M1的layer1加到M2的layer1上面,雖然填補了M2中無效filter的空虛,但是M2有效filter可能也會受到影響。因為M1它本身也有無效filter,它直接加到M2上,M2的有效filter的資訊量可能會減少,所以說我們就做了這樣一個DGD framework。

看一下DGD framework的結果。我們對比了傳統的filter grafting,還有knowledge distillation,發現比grafting distillation都有不錯的提升,比如在CIFAR-100上,各個網路基本都會比baseline提升兩到三個點。
待解難題:如何進行更有效的濾波器嫁接
前面講的是noise label learning和collaborative leaning,那麼基於這兩個可以做什麼呢?
第一個是設計一些feature dependent noise的loss形式。 因為我認為現在對於noisy label learning領域,feature independent noise可能解決得差不多了,準確率都很高了,接下來一個主要的點就是設計一些loss方式來解決feature dependent問題。而且,這個問題是真實的業務場景、真實的數據集上的noise type形式。
第二個是,我們知道grafting的motivation是來自於pruning,那麼我們是否可以用grafting的一些思想去指導神經網路來進行更有效的pruning,這是一些未來大家有興趣可以探索的一個點。
Q&A
Q:主動學習和noisy label learning都涉及到選擇數據,兩者的區別是什麼?
A:的確兩者都涉及選擇數據,但是關鍵在於要選擇什麼樣的數據,選擇數據的評價標準可能不太一樣。noisy label learning想選擇乾淨的數據,而主動學習是想選擇對解決的問題有效的數據。
這些選擇方式和數據的分布息息相關的,也就是說我們講各種演算法的同時要了解數據的分布,拋開數據的分布去研究演算法有時候是沒有任何價值的。對於主動學習來講,在數據集的分布不均勻的時候,要選擇loss比較大的樣本,這和noisy label learning有點相反,noisy label learning是要選擇loss比較小的樣本。
Q: noisy label對自動標註數據有用嗎?
A:這個是有用的,包括現在一些業務場景,我們用一些方法篩選出來哪些數據是值得標的,或者說我們通過noisy label的一些方法將noisy label的樣本先檢測出來,之後再進行有效的中心標註,所以noisy label對自動標註數據還是有業務價值的。
Q:grafting對於小型network的效果如何?
A:其實我們在做很多實驗的過程中發現,grafting對小型網路的提升是沒有對於大型網路的提升高。因為無效filter的數量很可能出現在大型網路上的比較多,小型網路無效filter的數量比較少,我們的實驗結果可以看到grafting是在大的數據網路上效果是比較明顯的。

